
1. 协程简介
线程有两种实现方式:内核态线程和用户态线程。早期,内核态线程由于概念清晰,对开发者友好,在与用户态线程的竞争中胜出。但随着互联网的发展,用户态线程凭借其线程切换成本低、竞态少等特点重新回归开发者视野,并逐步发展成最新的并发模型--协程。下面我们从线程切换和竞态两个方面介绍一下内核态线程和用户态线程。
从线程切换的角度来讲,进程与线程基本原理是一样的。下图展示了内核态线程切换的一个大概的过程:
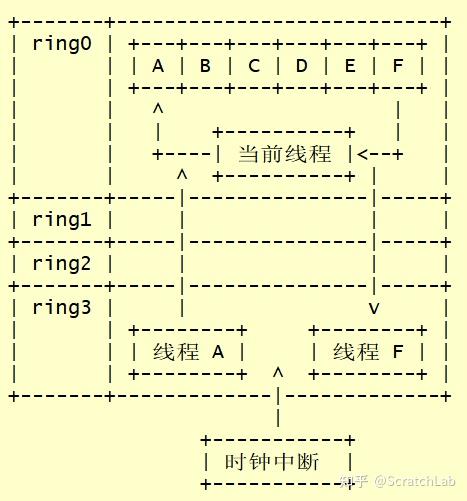
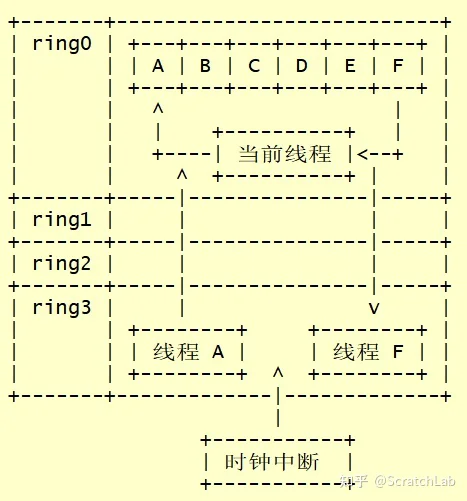
当前时刻,线程A正在运行。此时,来了一个时钟中断,系统由ring3的线程A跳转到ring0的时钟中断handler中。当handler认为需要切换线程时,会将线程A的上下文保存到线程A的控制块中。
然后,handler根据调度算法从就绪线程中选择一个来运行,假设handler选择了线程F来运行。handler会将线程F的上下文从其控制块中载入到当前线程。
完成上下文保存/载入工作后,handler退出,并跳转到ring3。此时,ring3中运行的就是线程F了。
从上述流程我们可以发现,内核态线程有以下特点:
- 线程切换的时机由操作系统决定(抢占式),线程无法对切换时机做任何假设。因此,多线程程序开发时必须考虑竞态
- 线程切换时涉及到特权级的跳转和线程上下文的保存/载入
这就造成了内核态线程切换时的成本非常高,线程数量多时,线程切换的开销甚至能超过业务代码。
下面,我们看一下用户态线程的切换过程。下图展示了用户态线程切换的一个大致过程:
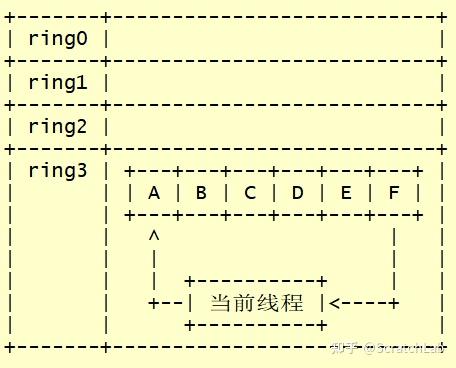
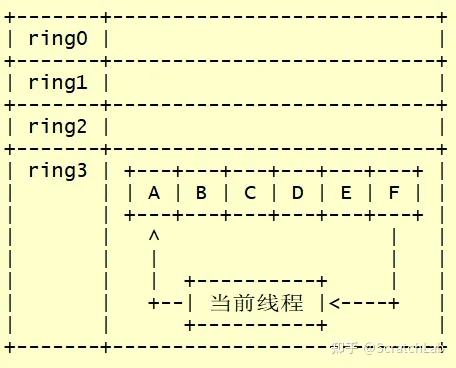
当前时刻,线程A正在运行。线程A运行一段时间后主动退出,将其上下文保存到线程A的控制块中。
然后,线程A根据用户代码从其他线程中选择一个来运行。假设用户代码要求线程A退出后线程F继续运行。线程A会将的线程F的上下文载入到当前线程中,并跳转到线程F的代码中运行。
各用户态线程不断的运行、退出,形成这样一个序列:
- A线程运行
- A线程退出,选择F来运行
- F线程运行
- F线程退出,选择D来运行
- D线程运行
- D线程退出,选择E来运行
- ...
- A线程运行
- A线程退出,选择B来运行
从以上介绍中我们可以看到,没有了时钟中断,某个线程运行时无法被强制退出,只有主动退出,其他线程才有运行机会。用户态线程的调度就依靠各线程在合适的时机主动退出,让其他线程获得运行机会来进行。各用户态线程彼此协作,推动程序的运行,因此,用户态线程又称作协程。
从上述流程我们可以看出,用户态线程有以下特点:
- 各用户态线程本质上是在一个单线程进程上执行的,线程调度的时机由用户代码完全控制,因此不用考虑竞态
- 线程切换过程不涉及特权级的跳转
- 线程切换时也涉及到上下文的保存/载入,但是各用户态线程是在一个单线程进程上运行的,可以共享许多数据,因此用户态线程上下文的数据量远远小于内核态线程上下文
从以上特点我们可以看到,用户态线程切换的开销非常低,且系统不会限制用户态线程的数量,非常适合高并发。
2. ucontext
linux提供了ucontext库用于实现用户态线程,ucontext的意思为user context。ucontext库定义的数据结构与声明的函数在ucontext.h头文件中。
ucontext库使用结构体ucontext_t表示用户上下文,ucontext_t的定义如下:
我们不考虑ucontext_t各字段的具体含义,只从应用的角度考虑其包含了哪些信息。ucontext_t包含了如下信息:
- 用户态线程运行时各寄存器的值,其中就包括eip和esp,eip指向代码运行到何处,esp指向栈指针指向何处
- 用户态线程使用的栈信息,当某个进程中有多个用户态线程时,各线程使用独立的栈,以使彼此互不影响
寄存器与栈信息构成了一个基本的用户态线程上下文。ucontext.h同时声明了操作用户上下文的函数,声明如下:
各函数的用途如下:
- getcontext用于获取当前的用户上下文,并保存进ucp中
- setcontext用于将ucp设置为当前上下文
- makecontext用于修改getcontext获得的用户上下文ucp
- swapcontext将当前的用户上下文保存到oucp,将ucp指向的用户上下文设置为当前上下文
下面,我们通过一个程序演示一下ucontext的基本用法。代码如下:
可能会有些困惑,但是我们依然可以猜测这段程序的输出。没错,这段程序输出了一下内容:
getcontext(&uc)调用时将当前用户上下文保存进uc变量。当前用户上下文的eip指向了紧跟着getcontext的语句,也就是printf行。当然了,此时printf行还没运行。
程序继续执行,当运行到setcontext(&uc)时,程序的运行环境都恢复到了调用printf行之前的那一刻。于是我们的程序又继续从printf行开始运行了。

这里有个问题,当我们调用setcontext(&uc)恢复到调用printf行前的那一刻时,栈变量i会不会恢复成0。
答案是不会的,因为我们的示例比较简单,不是多线程的,所有的代码共享同一个栈,没有切换栈,栈中的内容自然不会被改变了。
3. 使用ucontext实现用户态线程
本文中我们将用ucontext实现一个多线程的生产者-消费者模型,以此来演示用户态线程的用法。程序的仓库地址如下:
该程序分为三部分:主程序、生产者、消费者。主程序准备生产者和消费者的用户上下文,然切换到生产者中运行。主程序代码如下:
我们创建一个用户上下文时,只能通过修改已有用户上下文的方式来进行,无法从零开始创建。因此,首先用getcontext获取了当前的用户上下文并将其赋值给生产者的上下文变量uc_producer。代码如下:
因为生产者需要在一个单独的线程中运行,所以生产者需要一个独立的栈。下面的代码将为生产者线程设置一个独立的栈:
uc_producer包含的信息大多是主程序的用户上下文,除了修改uc_producer的栈之外,还需要修改当前运行到何处的信息(可以简单地认为该信息存储在eip寄存器)。此时,生产者还没有运行,所以只需要将生产者的入口函数设置到eip寄存器即可。设置eip寄存器的代码如下:
然后,我们用同样的方法为消费者配置用户上下文。代码如下:
最后,我们调用swapcontext将当前(主程序线程)用户上下文保存到uc_main中,然后切换到生产者的用户上下文中。代码如下:
调用swapcontext后,程序将进入生产者中运行。
生产者用一个递增的变量为product赋值,每赋值一次,相当于生产了一个数据。生产者线程每生产一个数据将切换到消费者。生产者代码如下:
生产者的关键代码如下,该行代码将当前(生产者线程)用户上下文保存到uc_producer变量,然后切换到消费者的用户上下文中。
生产者是一个函数,当调用swapcontext时,该函数还没有结束,函数在没有运行完的情况下就切换到其他函数中运行了。这是关键所在,大部分的程序(单内核态线程的程序),函数在返回之前是不会切换到其他函数中运行的。
当调用swapcontext行后,程序将进入消费者中运行。
消费者在一个循环中输出product变量,每输出一次,相当于消费了一个数据。消费者线程每消费一个数据将切换到生产者。消费者代码如下:
消费者的关键代码如下,该行代码将当前(消费者线程)用户上下文保存到uc_consumer变量,然后切换到生产者的用户上下文中。
当调用swapcontext行后,程序将进入生产者中运行。
生产者和消费者通过主动让出执行权并让对方来运行的方式实现了用户态多线程。程序的输出如下:
4. golang中的协程
Golang的语法和运行时直接内置了对协程的支持,其底层是使用ucontext库实现的,在Golang中,协程被称作goroutine。
Golang运行时有一个复杂的调度器,能管理所有goroutine并为其分配执行时间。这个调度器在操作系统之上,将操作系统的线程与语言运行时的逻辑处理器绑定,并在逻辑处理器上运行goroutine。调度器在任何给定的时间,都会全面控制哪个goroutine要在哪个逻辑处理器上运行。
Golang运行时抽象出了三个概念用于描述其调度原理:
- M内核态线程
- P逻辑处理器
- G goroutine
G为goroutine,也就是用户上下文,包含代码、寄存器、栈等信息。
M为内核态线程,G中的代码就是在M上运行的。
P为逻辑处理器,是一个联通M与G的桥梁。M只有在关联了P时才可以运行,因此我们可以认为G是在P中运行的。P中包含了一些G的信息,这些G在该P中被调度运行。
P、G、M的关系示意图如下:
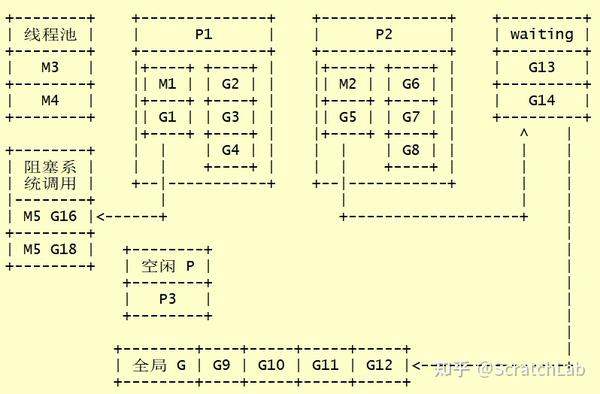
系统中有GOMAXPROCS(该值通常与CPU核心数相同)个P。
M从P中取出一个G,并运行该G。若P中的G空了,M尝试从全局G队列中取出一个G来运行。若全局G队列中也没有G可用,则从其他P中偷取一半G来运行。若其他P中也没有G了,M将其P置为空闲状态,M进入线程池睡眠。
若M发现其有很多G需要运行,处理不过来,而且有闲置的P。此时M将创建或者唤醒(从线程池)一个M,并将该M与闲置的P绑定运行G。
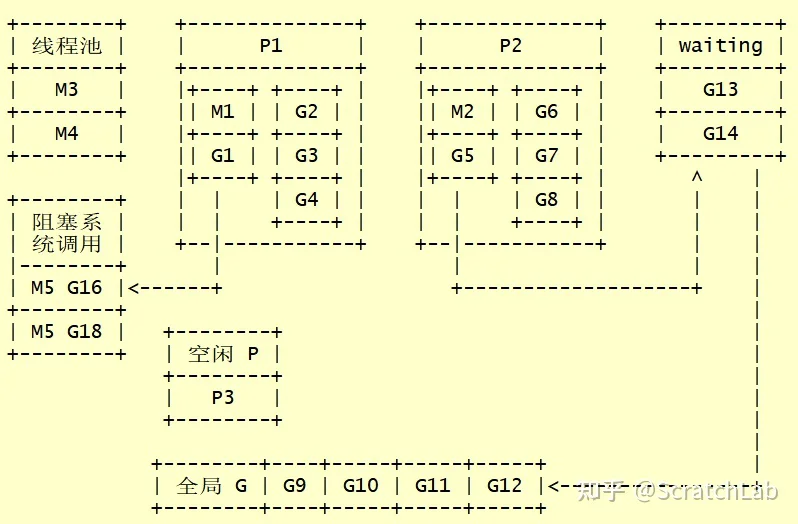
当G执行channel读写、网络poll、定时器等操作会触发调度,将当前G置为waiting状态,不再运行,P继续执行其他的G。当channel读写、网络poll、定时器等操作有结果时,对应的G会被放入全局G队列,等待调度。
当G执行阻塞系统调用时,当前M会与P脱离关系。P与其他的M关联继续执行G,当前M等待系统调用返回。
4.1. 网络poll操作
Golang提供的网络接口,在用户层是阻塞的,这样符合开发者的思维。在运行时层面,是用epoll实现的非阻塞IO,为性能提供了保障。例如,下面的代码演示了一个网络操作,代码如下:
这段代码从某个socket读取数据,conn.Read在返回之前,Something不会被调用,这种同步的代码符合开发者的思维。同时,该读取操作的底层使用epoll实现,不会引起当前线程的阻塞。
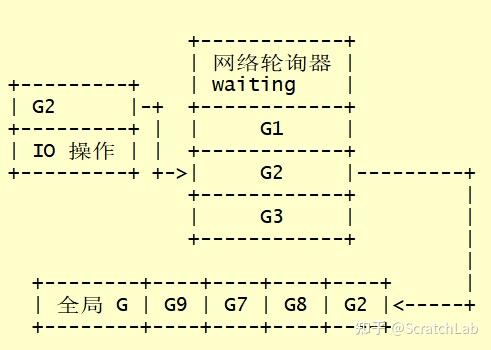
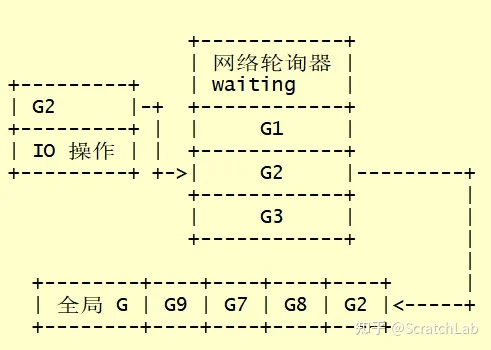
网络操作中,所有文件描述符都被设置成非阻塞的。当进行IO操作时,如果IO还没准备好,则对应的G将被置waiting状态,并被移到网络轮询器。以一旦某个网络IO操作完成,对应的G将放入全局G队列,等待调度。示意图如下:
4.2. 阻塞系统调用
如果goroutine执行时进入到一个阻塞的系统调用,这样M就会阻塞。阻塞的系统调用返回时无法像poll操作或读写channel那样通知调度器,因此只能等待其返回。等待系统调用返回的过程中,与该M关联的G将无法运行。
为了保证并发,Golang完全封装了系统调用,保证进/出系统调用时会触发调度。当进入系统调用时会执行以下操作:
- 会创建或唤醒(从线程池中)一个新的M
- 解除P与当前M的绑定关系
- P与新的M绑定
通过以上操作,P中的其他G就可以绕过系统调用的等待继续执行了。而老的M与G将等待系统调用的返回。
当系统调用返回时,老M发现自己没有P了,无法继续工作,于是执行如下操作:
- 将G放回全局G队列
- 进入线程池睡眠
下图演示了当执行G3进入阻塞系统调用时调度器的执行的操作。如下所示:
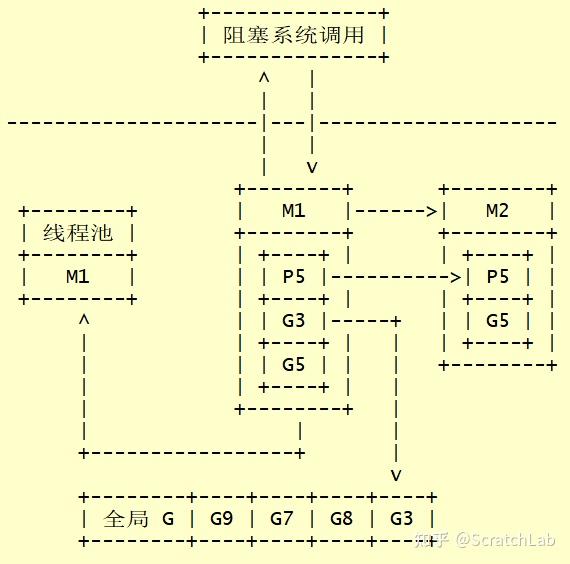
上图中,当执行G3中的代码时进入了阻塞系统调用。此时,会新建或唤醒(从线程池)一个新的M2,M2将 与P5绑定,继续执行P5中的其他G。M1将阻塞以等待系统调用的返回,当系统调用返回时,M1将进入线程池进行休眠,G3将进入全局G队列,等待被调度。
4.3. 抢占式调度
Golang运行时能够监测各个G的运行时间,当发现某个G运行时间过长时,会给该G打上一个标记。当G执行函数调用时会检查是否有这个标记,如果有,则触发调度,让出执行权。
从原理上看,Golang的抢占式调度还很初级。如果一个G长时间运行且没有调用函数的操作,则该G不会被剥夺执行权。当然了,一个运行很久却不调用函数的代码很少见。