
此文来自简书好友 ,作者dandyhzh,如看原文,请点击文末阅读原文。
协程池
提到协程,大家可能会觉得协程已经够轻量了,为什么还需要在引入协程池呢。有些小伙伴可能会觉得多此一举。其实不然,每次创建一个goroutine大小大概在2k左右,如果服务器并非很高,goroutine占用几十万个。那其实协程的资源占用也会相当高的。有些可能还会因为没有处理逻辑带来goroutine的泄漏。这些情况都会不仅没有给服务器带来性能提升,返而带来服务可用性下降。所以,不同场景,我们还是需要使用一些协程池来进行管控的
ants使用
func main() {
pool, _ := ants.NewPool(2)
runTimes := 10
var wg sync.WaitGroup
syncCalculateSum := func() {
func() {
time.Sleep(10 * time.Millisecond)
fmt.Println("Hello World!")
}()
wg.Done()
}
for i := 0; i < runTimes; i++ {
wg.Add(1)
_ = pool.Submit(syncCalculateSum)
}
wg.Wait()
pool.Release()
}
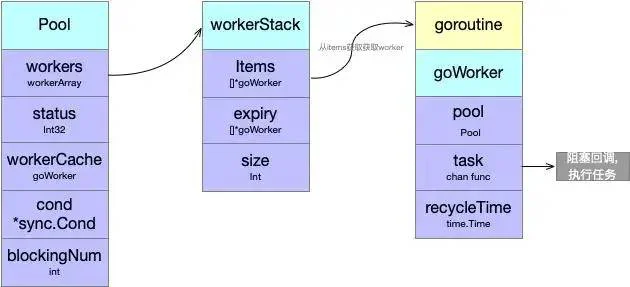
Pool结构
// 不要嵌套使用Pool
type Pool struct {
// 容量设置
capacity int32
// 当前正在执行的g有多少个
running int32
// locker queue
lock sync.Locker
// 存储workers
workers workerArray
// 池的状态
state int32
// 条件变量
cond *sync.Cond
// worker缓存
workerCache sync.Pool
// 阻塞的数量
blockingNum int
// 参数设置
options *Options
}
Pool结构还是很清晰简单,这里提醒了我们,pool不要嵌套使用
NewPool初始化协程池
func NewPool(size int, options ...Option) (*Pool, error) {
// 常用的Functional Options模式设置一些基本配置
opts := loadOptions(options...)
// 边界判断
if size <= 0 {
size = -1
}
// 过期时间检测
if expiry := opts.ExpiryDuration; expiry < 0 {
return nil, ErrInvalidPoolExpiry
} else if expiry == 0 {
opts.ExpiryDuration = DefaultCleanIntervalTime
}
// 没有设置logger就是用默认的
if opts.Logger == nil {
opts.Logger = defaultLogger
}
// 设置容量,并且自己实现了一个自旋锁
p := &Pool{
capacity: int32(size),
lock: internal.NewSpinLock(),
options: opts,
}
// sync.pool缓存池
p.workerCache.New = func() interface{} {
return &goWorker{
pool: p,
task: make(chan func(), workerChanCap),
}
}
// 栈存储或者队列存储
if p.options.PreAlloc {
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
p.workers = newWorkerArray(loopQueueType, size)
} else {
p.workers = newWorkerArray(stackType, 0)
}
// 初始化条件变量
p.cond = sync.NewCond(p.lock)
// 定时清理过期的workers(后面分析)
go p.purgePeriodically()
return p, nil
}
Submit
func (p *Pool) Submit(task func()) error {
// 判断池是否关闭
if p.IsClosed() {
return ErrPoolClosed
}
var w *goWorker
// 获取worker
if w = p.retrieveWorker(); w == nil {
return ErrPoolOverload
}
// 将task存到channel中
w.task <- task
return nil
}
// 获取worker
func (p *Pool) retrieveWorker() (w *goWorker) {
spawnWorker := func() {
// 第一次获取不到,创建一个
w = p.workerCache.Get().(*goWorker)
// goworker执行任务
w.run()
}
// 上锁不成功让出G调度的时间片
p.lock.Lock()
// 从栈或者队列中获取goWorker
w = p.workers.detach()
if w != nil { // first try to fetch the worker from the queue
p.lock.Unlock()
} else if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {
// 队列没有获取到,并且还没有超过容量,在获取一个
p.lock.Unlock()
spawnWorker()
} else { // otherwise, we'll have to keep them blocked and wait for at least one worker to be put back into pool.
// 非阻塞直接返回
if p.options.Nonblocking {
p.lock.Unlock()
return
}
retry:
// 最大阻塞的任务数
if p.options.MaxBlockingTasks != 0 && p.blockingNum >= p.options.MaxBlockingTasks {
p.lock.Unlock()
return
}
p.blockingNum++
// 等待可用的worker,并释放锁,和c艹一样的
p.cond.Wait() // block and wait for an available worker
p.blockingNum--
var nw int
// 唤醒后,如果池中已经被清除,就在创建一个goroutine
if nw = p.Running(); nw == 0 { // awakened by the scavenger
p.lock.Unlock()
if !p.IsClosed() {
spawnWorker()
}
return
}
// 获取到goWoker并且为空,说明被情况,就在创建一个goroutine
if w = p.workers.detach(); w == nil {
if nw < capacity {
p.lock.Unlock()
spawnWorker()
return
}
goto retry
}
// 解锁
p.lock.Unlock()
}
return
}
从队列中获取goWorker,开始没有,所以调用spawnWorker,调用goworker.run(),启动goroutine执行方法。这时候task为空,阻塞等待队列
如果detach获取到队列,则直接返回,并把task放到w.task中,task获取任务执行回调
如果超过容量,如果是阻塞判断最大阻塞数量,并wait等待其他队列处理完毕,如果池子没有被过期清楚,那么继续时候。
这里将w放到sync.pool里头,还是挺好的ideal
goWorker执行任务
func (w *goWorker) run() {
// 增加running的个数
w.pool.incRunning()
go func() {
defer func() {
// 减少running数
w.pool.decRunning()
// 讲w放到sync.pool中
w.pool.workerCache.Put(w)
// 如果处理的任务panic了,捕获一下
if p := recover(); p != nil {
if ph := w.pool.options.PanicHandler; ph != nil {
// 如果有设置panihandle就调用
ph(p)
} else {
w.pool.options.Logger.Printf("worker exits from a panic: %v\n", p)
var buf [4096]byte
n := runtime.Stack(buf[:], false)
// 没有输出堆栈信息
w.pool.options.Logger.Printf("worker exits from panic: %s\n", string(buf[:n]))
}
}
// 条件变量通知其他等待的g
w.pool.cond.Signal()
}()
// 阻塞等待task
for f := range w.task {
// task被过期清空或者释放
if f == nil {
return
}
f()
// 将w存到pool.workers中下次可以再次获取
if ok := w.pool.revertWorker(w); !ok {
return
}
}
}()
}
等待获取task,并将w存放到pool.wokers中
退出后,讲w放到pool.wokercache中,如果task panic,那么recover住。之后signal其他队列
存储worker
func (p *Pool) revertWorker(worker *goWorker) bool {
//判断running和close等问题
if capacity := p.Cap(); (capacity > 0 && p.Running() > capacity) || p.IsClosed() {
return false
}
// 设置清理时间
worker.recycleTime = time.Now()
p.lock.Lock()
// release状态变更,所以需要在判断一次
if p.IsClosed() {
p.lock.Unlock()
return false
}
// 存入workers中
err := p.workers.insert(worker)
if err != nil {
p.lock.Unlock()
return false
}
// 唤醒通知等待的worker
p.cond.Signal()
p.lock.Unlock()
return true
}
定期清除
func (p *Pool) purgePeriodically() {
// 定时器
heartbeat := time.NewTicker(p.options.ExpiryDuration)
defer heartbeat.Stop()
for range heartbeat.C {
if p.IsClosed() {
break
}
p.lock.Lock()
// 删除workers中过期的数据,队列是后进先出
expiredWorkers := p.workers.retrieveExpiry(p.options.ExpiryDuration)
p.lock.Unlock()
// 这里是否会有worker被清空了。但是还在执行的
for i := range expiredWorkers {
expiredWorkers[i].task <- nil
expiredWorkers[i] = nil
}
// 在广播一次,如果当前没有在running的数据
if p.Running() == 0 {
p.cond.Broadcast()
}
}
}
唤醒的时候,这时候清空数据,应该还会有任务被执行的。
Release
func (p *Pool) Release() {
// 设置状态
atomic.StoreInt32(&p.state, CLOSED)
p.lock.Lock()
// 清空队列
p.workers.reset()
p.lock.Unlock()
// 因为还有可能一部分worker还在等待被唤醒,全局广播
p.cond.Broadcast()
}
总结
整理思路还是很清晰的,submit从队列中获取goworker,并启动goroutine,等待任务插入。
这里过期的时候,将w放到了sync.pool中,避免每次过期,都需要重新创建Pool。
其余就是比较正常的,goroutine检测task任务,队列的存储等。