
前言
Go运行时的调度器其实可以看成OS调度器的某种简化版 本,一个goroutine在其生命周期之中,同样包含了各种状态的变换。弄清了这些状态及状态间切换的原理,对搞清整个Go调度器会非常有帮助。
以面是一张goroutine的状态迁移图,圆形框表示状态,箭头及文字信息表示切换的方向和条件:
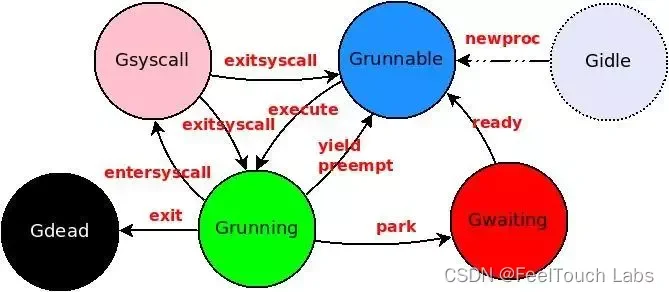
状态
下面来简单分析一下, 其中状态 Gidle 在Go调度器代码中并没有被真正被使用到,所以直接忽略。 事实上,一旦runtime新建了一个goroutine结构,就会将其状态置为Grunnable并加入到任务队列中,
Grunnable
Golang中,一个协程在以下几种情况下会被设置为 Grunnable状态:
1. 创建
Go 语言中,包括用户入口函数main·main的执行goroutine在内的所有任务,都是通过runtime·newproc -> runtime·newproc1 这两个函数创建的,前者其实就是对后者的一层封装,提供可变参数支持,Go语言的go关键字最终会被编译器映射为对runtime·newproc的调用。当runtime·newproc1完成了资源的分配及初始化后,新任务的状态会被置为Grunnable,然后被添加到当前 P 的私有任务队列中,等待调度执行。相关初始化代码如下:
G* runtime·newproc1(FuncVal *fn, byte *argp, int32 narg, int32 nret, void *callerpc)
{
G *newg;
P *p;
int32 siz;
......
// 获取当前g所在的p,从p中创建一个新g(newg)
p = g->m->p;
if((newg = gfget(p)) == nil) {
......
}
......
// 设置Goroutine状态为Grunnable
runtime·casgstatus(newg, Gdead,
Grunnable);
.....
// 新创建的g添加到run队列中
runqput(p, newg);
......
}2. 阻塞任务唤醒
当某个阻塞任务(状态为Gwaiting)的等待条件满足而被唤醒时—如一个任务G#1向某个channel写入数据将唤醒之前等待读取该channel数据的任务G#2——G#1通过调用runtime·ready将G#2状态重新置为Grunnable并添加到任务队列中。
// Mark gp ready to run.
void
runtime·ready(G *gp)
{
uint32 status;
status = runtime·readgstatus(gp);
// Mark runnable.
g->m->locks++;
if((status&~Gscan) != Gwaiting){
dumpgstatus(gp);
runtime·throw("bad g->status in ready");
}
// 设置被唤醒的g状态从Gwaiting转变至Grunnable
runtime·casgstatus(gp, Gwaiting, Grunnable);
// 添加到运行队列中
runqput(g->m->p, gp);
if(runtime·atomicload(&runtime·sched.npidle) != 0 && runtime·atomicload(&runtime·sched.nmspinning) == 0)
// 看起来这是个比较重要的函数,但还不是很理解
wakep();
g->m->locks--;
if(g->m->locks == 0 && g->preempt)
g->stackguard0 = StackPreempt;
}
其他
另外的路径是从Grunning和Gsyscall状态变换到Grunnable,我们也都合并到后面介绍。 总之,处于Grunnable的任务一定在某个任务队列中,随时等待被调度执行。
Gwaiting
当一个任务需要的资源或运行条件不能被满足时,需要调用runtime·park函数进入该状态,之后除非等待条件满足,否则任务将一直处于等待状态不能执行。channel,Go语言的定时器、网络IO操作都可能引起任务的阻塞。
// runtime·park continuation on g0.
void
runtime·park_m(G *gp)
{
bool ok;
runtime·casgstatus(gp, Grunning, Gwaiting);
dropg();
if(g->m->waitunlockf) {
ok = g->m->waitunlockf(gp, g->m->waitlock);
g->m->waitunlockf = nil;
g->m->waitlock = nil;
if(!ok) {
runtime·casgstatus(gp, Gwaiting, Grunnable);
execute(gp); // Schedule it back, never returns.
}
}
schedule();
}
runtime·park函数包含3个参数,第一个是解锁函数指针,第二个是一个Lock指针,最后是一个字符串用以描述阻塞的原因。 很明显,前两个参数是配对的结构——由于任务阻塞前可能获得了某些Lock,这些Lock必须在任务状态保存完成后才能释放,以避免数据竞争。我们知道channel必须通过Lock确保互斥访问,一个阻塞的任务G#1需要将自己放到channel的等待队列中,如果在完成上下文保存前就释放了Lock,则可能导致G#2将未知状态的G#1置为Grunnable,因此释放Lock必须在runtime·park内完成。 由于阻塞时任务持有的Lock类型不尽相同——如Select操作的锁实际上是一组Lock的集合——因此需要特别指出Unlock的具体方式。 最后一个参数主要是在gdb调试的时候方便发现任务阻塞的原因。 顺便说一下,当所有的任务都处于Gwaiting状态时,也就表示当前程序进入了死锁态,不可能继续执行了,那么runtime会检测到这种情况,并输出所有Gwaiting任务的backtrace信息。
Grunning
所有状态为Grunnable的任务都可能通过findrunnable函数被调度器(P&M)获取,进而通过execute函数将其状态切换到Grunning, 最后调用runtime·gogo加载其上下文并执行。
// One round of scheduler: find a runnable goroutine and execute it. Never returns.
static void
schedule(void)
{
G *gp;
uint32 tick;
if(g->m->locks)
runtime·throw("schedule: holding locks");
if(g->m->lockedg) {
stoplockedm();
execute(g->m->lockedg); // Never returns.
}
top:
if(runtime·sched.gcwaiting) {
gcstopm();
goto top;
}
gp = nil;
// 挑一个可运行的g,并执行
......
if(gp == nil) {
gp = findrunnable(); // blocks until work is available
resetspinning();
}
......
execute(gp);
}
// Schedules gp to run on the current M.
// Never returns.
static void
execute(G *gp)
{
int32 hz;
// 状态从Grunnable转变为Grunning
runtime·casgstatus(gp, Grunnable, Grunning);
gp->waitsince = 0;
gp->preempt = false;
gp->stackguard0 = gp->stack.lo + StackGuard;
g->m->p->schedtick++;
g->m->curg = gp;
gp->m = g->m;
// Check whether the profiler needs to be turned on or off.
hz = runtime·sched.profilehz;
if(g->m->profilehz != hz)
runtime·resetcpuprofiler(hz);
// 真正执行g
runtime·gogo(&gp->sched);
}
Go本质采用一种协作式调度方案,一个正在运行的任务,需要通过调用yield的方式显式让出处理器;在Go1.2之后,运行时也开始支持一定程度的任务抢占——当系统线程sysmon发现某个任务执行时间过长或者runtime判断需要进行垃圾收集时,会将任务置为”可被抢占“的,当该任务下一次函数调用时, 就会让出处理器并重新切会到Grunnable状态。
Gsyscall
Go运行时为了保证高的并发性能,都会在任务执行OS系统调用前,先调用runtime·entersyscall函数将自己的状态置为Gsyscall——如果系统调用是阻塞式的或者执行过久,则将当前M与P分离——当系统调用返回后,执行线程调用runtime·exitsyscall尝试重新获取P,如果成功且当前任务没有被抢占,则将状态切回Grunning并继续执行;否则将状态置为Grunnable,等待再次被调度执行。
// Puts the current goroutine into a waiting state and calls unlockf.
// If unlockf returns false, the goroutine is resumed.
void
runtime·park(bool(*unlockf)(G*, void*), void *lock, String reason)
{
void (*fn)(G*);
g->m->waitlock = lock;
g->m->waitunlockf = unlockf;
g->waitreason = reason;
fn = runtime·park_m;
runtime·mcall(&fn);
}
// runtime·park continuation on g0.
void
runtime·park_m(G *gp)
{
bool ok;
// 设置当前状态从Grunning-->Gwaiting
runtime·casgstatus(gp, Grunning, Gwaiting);
// 当前g放弃m
dropg();
if(g->m->waitunlockf) {
ok = g->m->waitunlockf(gp, g->m->waitlock);
g->m->waitunlockf = nil;
g->m->waitlock = nil;
if(!ok) {
runtime·casgstatus(gp, Gwaiting, Grunnable);
execute(gp); // Schedule it back, never returns.
}
}
schedule();
}
Gdead
最后,当一个任务执行结束后,会调用runtime·goexit结束自己的生命——将状态置为Gdead,并将结构体链到一个属于当前P的空闲G链表中,以备后续使用。
Go语言的并发模型基本上遵照了CSP模型,goroutine间完全靠channel通信,没有像Unix进程的wait或waitpid的等待机制,也没有类似“POSIX Thread”中的pthread_join的汇合机制,更没有像kill或signal这类的中断机制。每个goroutine结束后就自行退出销毁,不留一丝痕迹。