
思考从容器上该如何设置 GOMAXPROCS 大小引发,这个数字设置多少合理,其到底限制了什么,cpu 核数,系统线程数还是协程数?
背景
goGo 协程
概念
进程: 操作系统分配系统资源(cpu 时间片,内存等)的最小单位
线程:轻量级进程,是操作系统调度的最小单位
协程:轻量级线程,协程的调度由程序控制
怎么理解
进程,线程的两个最小单位如何理解?
在早期面向进程设计的计算机结构中,进程就是操作系统分配系统资源与操作系统调度的最小单位
但在现代的计算结构中,进程升级为线程的容器,多个线程共享一个进程内的系统资源,cpu 执行(调度)对象是线程
轻量级进程与轻量级线程如何理解
轻量级进程:如下图各个进程拥有独立的虚拟内存空间,里面的资源包括 栈,代码,数据,堆... 而线程拥有独立的栈,但是共享进程全部的资源。在 linux 的实现中,进程与线程的底层数据结构是一致的,只是同一进程下线程会共享资源。
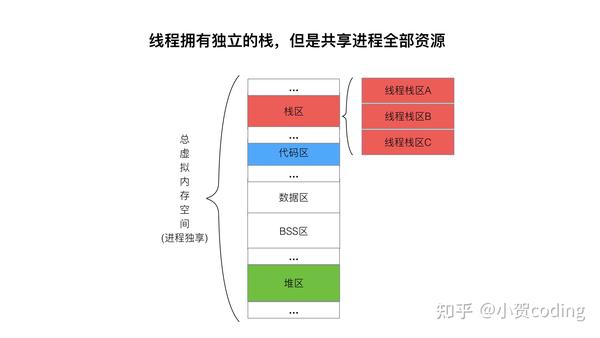
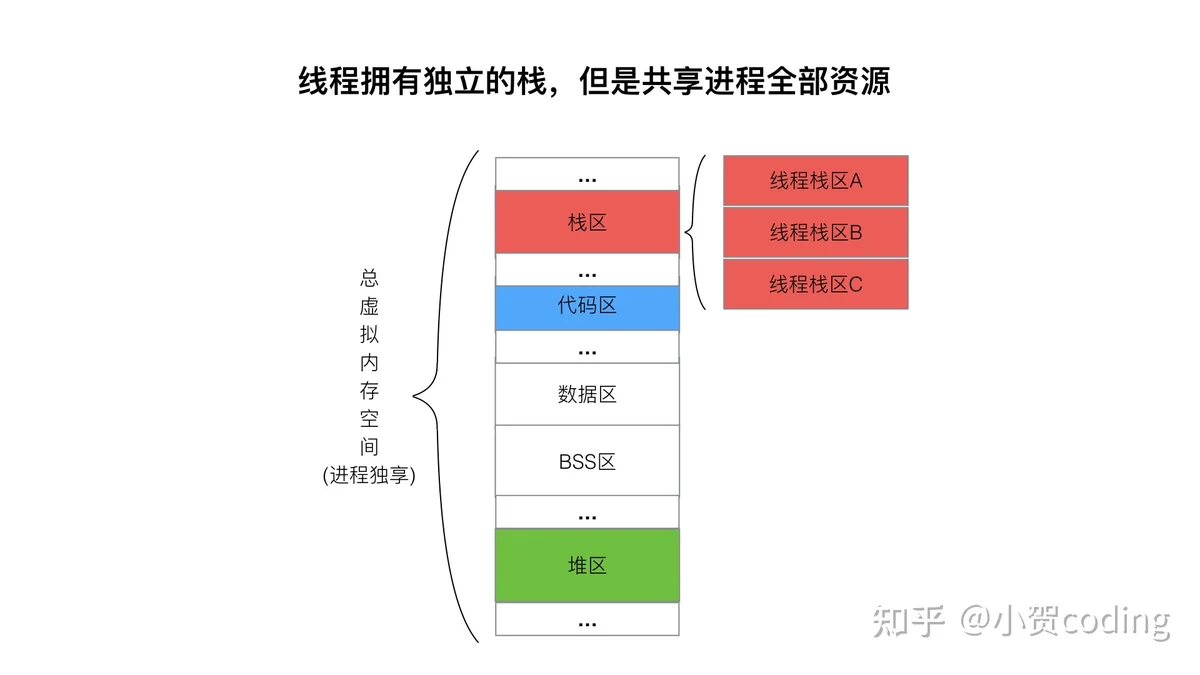
轻量级线程:线程栈大小固定 8 M,协程栈:2 KB ,动态增长。一对线程里对应多个协程,可以减少线程的数量
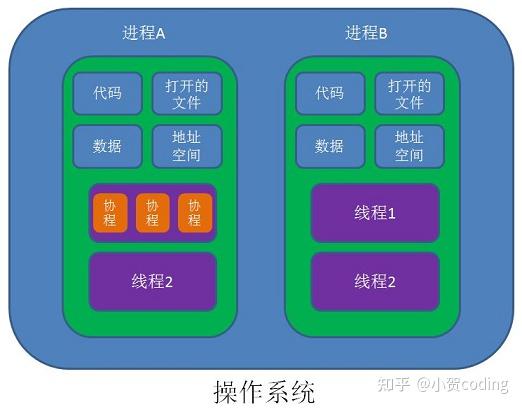
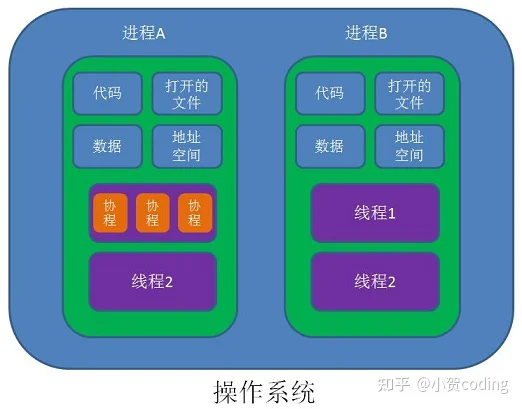
协程相对线程有什么优势
- 轻量级 (MB vs KB)
- 切换代价低 (调度由程序控制,不需要进入内核空间。需要保存上下文一般少一些)
- 切换频率低,协程协作式调度,线程调度由操作系统控制,需要保证公平性,当线程数量一多,切换频率相对比较高
协程调度器
在 Golang 中,goroutine 调度是由 Golang 运行时(runtime)负责的,不需要程序员编写代码时关注协程的调度。
GM 模型
goroutine 的调度其实是一个生产者-消费者模型。
生产者:程序起 goroutine(G)
消费者:系统线程(M)去消费(执行)goroutine
Go 1.1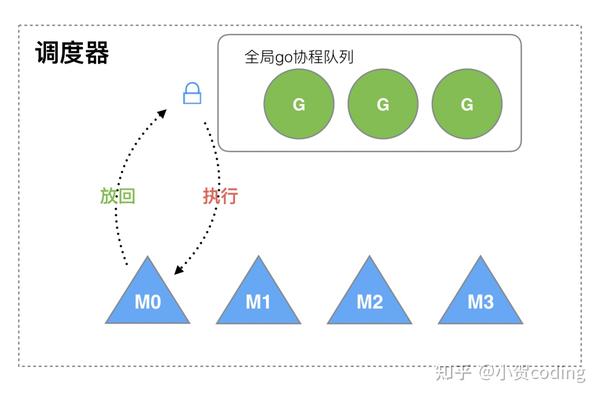
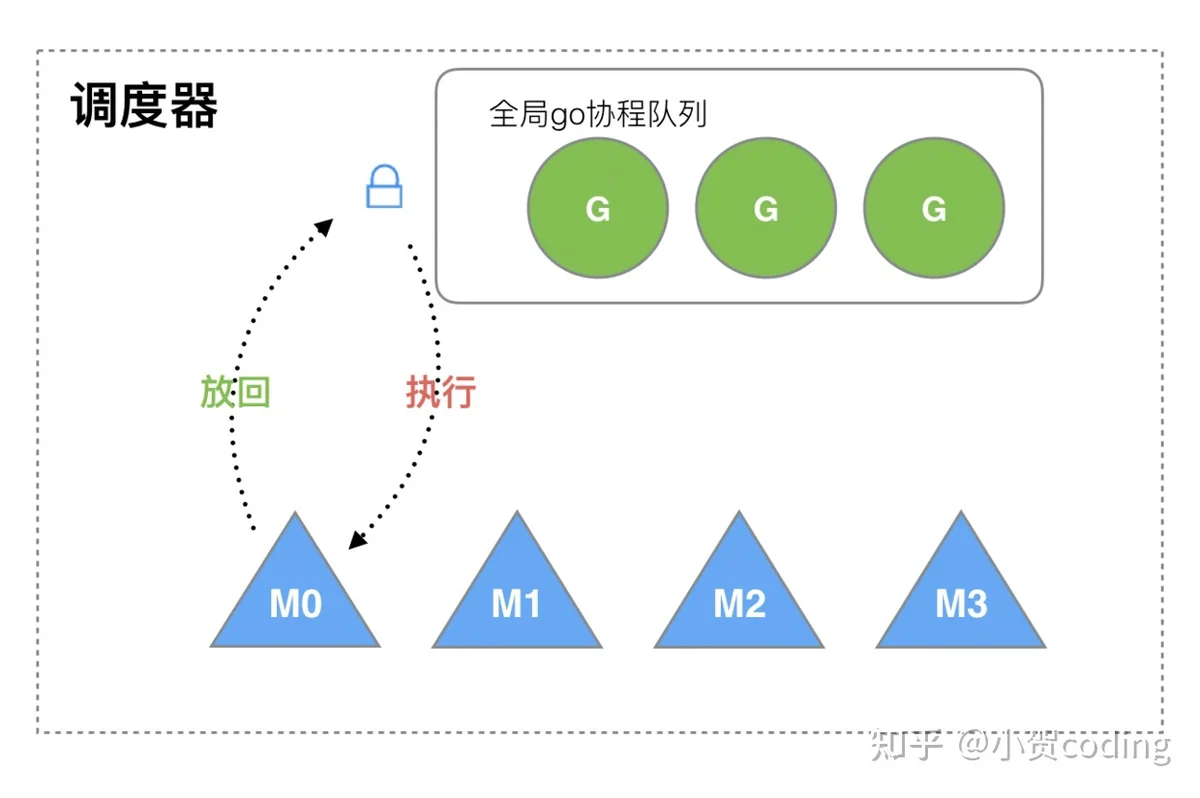
GM 模型问题
- M 是并发的,每次访问这个全局队列需要全局锁,锁竞争比较严重
- 忽略了 G 之间的关系,例如,M1 执行 G1 时,G1 创建了 G2,为了执行 G2 很有可能放到 M2 中执行。而 G1,G2 是相关的,缓存大概率是比较接近的,这样会导致性能下降
- 每一个 M 都分配一块缓存 MCache,比较浪费
GOMAXPROCS:在这个版本代表了最多同时支持 GOMAXPROCS 个活跃的线程。
GMP 模型
- G:go 协程
- M:系统线程
- P:逻辑处理器,负责提供相关的上下文环境,内存缓存的管理, Goroutine任务队列等
上述的 GM 模型性能问题比较严重,于是如下图所示, Go 将一个全局队列拆成了多个本地队列,这个管理本地队列的结构被称作 P。
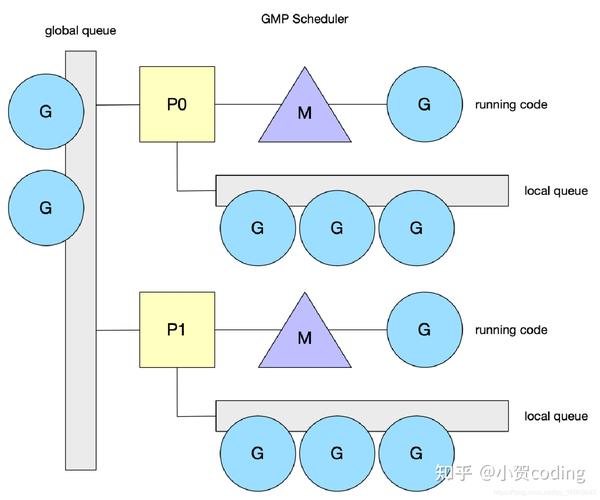
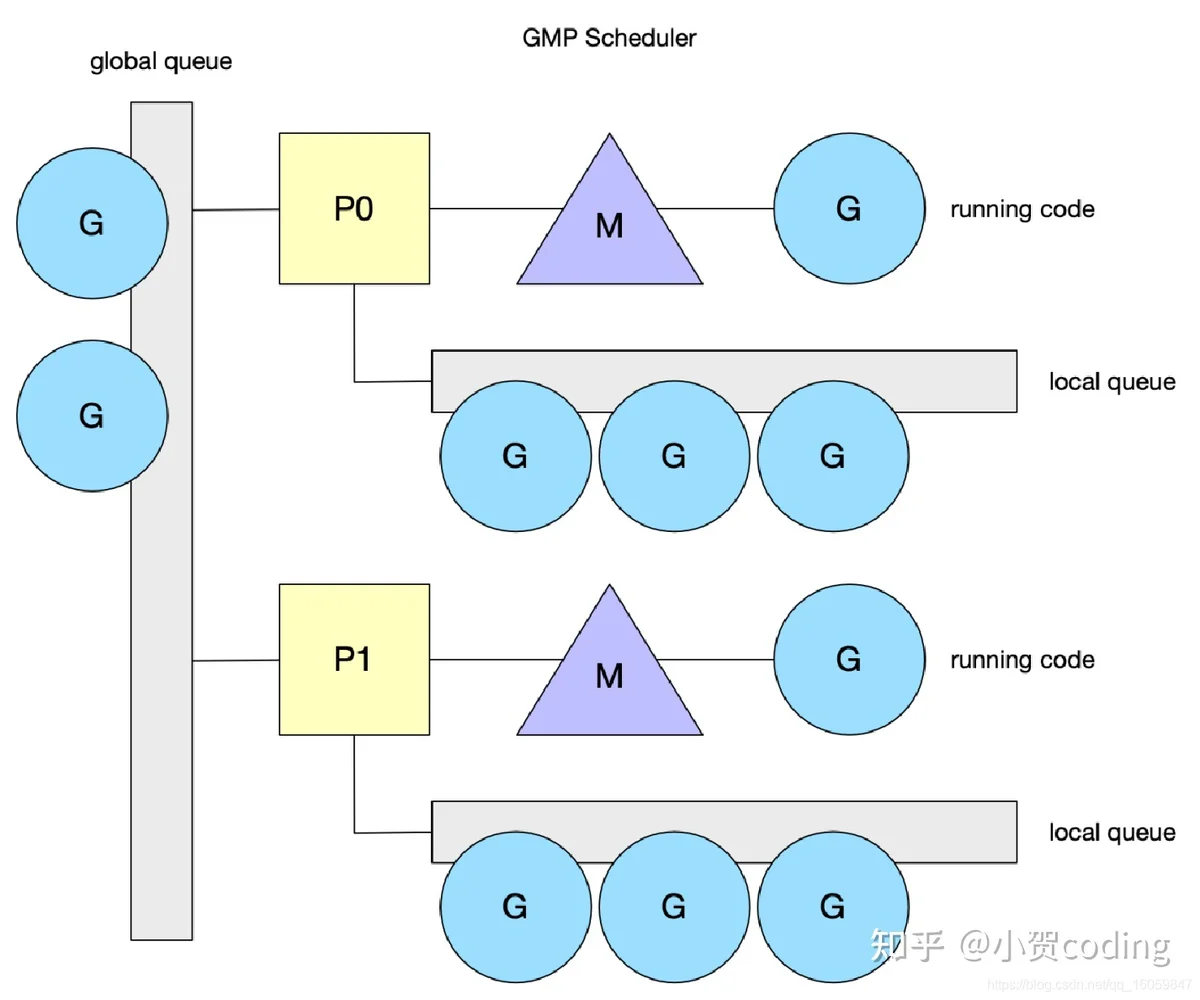
P 结构特点
- M 通过 P 取 G 时,并发访问大大降低,本地队列不需要全局锁了。
- 每个 P 的本地 G 队列长度限定在 256,而 goroutine 的数量是不定的,因此 Go 还保留了一个无限长度的全局队列。
- 本地队列数据结构是数组,全局队列数据结构是链表
- P 中除了本地队列,还加了一个 runnext 的结构,为了优先执行刚创建的 goroutine
- MCache 从 M 移到了P
- 通过设置 GOMAXPROCS 控制 P 的数量
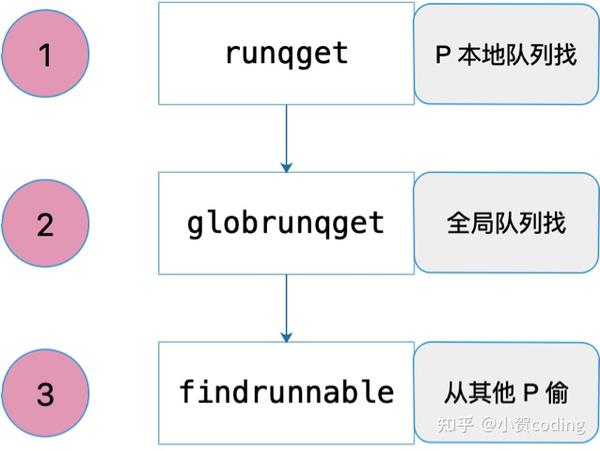
M 的消费逻辑(获取G)
- 先从绑定的 P 本地队列(优先 runnext)获取 G
- 定期从全局队列中获取 G:每执行 61 次调度会看一下全部队列(保证公平),并且在这个过程会把全局队列中 G 分给各个 P
- work stealing,若全局队列没有 G,则随机选择一个 P 偷一半的任务过来,若没有任务可偷,线程休眠。偷任务会导致并发访问本地队列,因此操作本地队列需要加自旋锁
G 的生产逻辑
go func引入 P 解决的问题
- 全局锁,P 中的协程是串行的
- 数据局部性,G 创建时优先在 P 的本地队列,M 获取可用 P 时,优先之前绑定的 P
- 内存消耗问题,多个线程共用 MCache
回到最开始的思考,容器上的 GOMAXPROCS 设置问题。GOMAXPROCS 代表着 P 的数量,也即代表着运行go 代码的最大线程数,默认为 CPU 的核数,有利于减少线程数量进而减少线程切换,但在容器中,不应该使用物理机的实际核数,应修改为容器限制的核数。