
摘要:本文比较了几种常见的协程框架中的通信机制,比较各种方案的实现方法,着重介绍了VLCP中的Pub/Sub通信机制,从而给各位读者一个直观认识。
协程与通信
在许多的现代异步IO框架中,调度的基本单位是协程(Coroutine)。与多线程不同,协程使用程序自定义的调度器进行调度,因此更容易控制协程之间的执行顺序,要想充分利用协程的调度模型,有一个趁手的通信机制是很重要的。它主要应该有以下的功能:
- 能从一个协程发送消息到另一个协程,通知另一个协程特定的事件已经发生
- 能够让协程在事件未发生之前挂起,等待事件发生后被调度并处理,从而有效让出CPU时间
- 能够在消息中附带相应的数据
能完成这样任务的模型很多,但是使用的方便程度上则有很大差别,我们接下来逐一分析这些模型 。
类比多线程的互斥区、信号量等
主要对于greenlet等,由于greenlet的目的是不改变代码将多线程转化为协程,因此并没有很统一的调度模型,而是使用了模拟多线程中的互斥区、信号量等的对象。这样的好处自然是不需要重复学习,对多线程编程熟悉的就可以直接用,但缺点也很明显:
- 没有利用好协程在单线程中依次执行的特性,比如greenlet中协程不会真的同时执行,在保证好同一个过程中不发生切换的条件下,许多互斥之类的操作是可以避免的
- 只能传递信号,不能传递数据,需要配合额外的手段传递数据,大大增加了复杂性
- 对于一次性或者少次使用来说效率很低
事件处理器
这实际上不是一个协程通信模型,但是有一些联系。对某个类型的事件,维护一个回调函数(也叫做事件处理器,event handler)的列表,当事件发生时,调用列表中所有的回调函数,从而实现通知的目的。但是对于协程模型来说,有几个问题:
- 同一类型的事件共享相同的事件处理程序,很难定位到单独的某个事件上。
- 如果只是临时需要处理接下来的某一个事件,不停增加和删除事件处理器非常麻烦
- 每个事件有单独的数据结构,很难协作。
Promise-Future模型
这实际上是我们要讲的第一种真正意义上的协程通信模型,它也是Python3自带的asyncio中默认的通信模型。一般意义上的Promise-Future由Promise和Future两个对象组成,它原本是一种多线程中的模型,代表一次异步通信过程:发送方通过Promise对象发送消息,接收方可以随时通过Future对象在合适的接受结果,或者等待结果到来。
在asyncio中,Promise和Future的功能被合成了一个。一般来说,通信的过程可以这么描述:
- 接收方提前通过某个方法与发送方共享一个Future对象,一般来说是某个异步方法的返回值;
- 发送方通过Future对象写入返回值
- 接收方在合适的时候尝试读取Future的返回值,或者等待Future返回值到来
asyncio的Future基于延迟调用的机制来实现这个过程,接收方等待Future返回值时会注册回调函数,发送方通过Future写入返回值时触发回调,回调函数不会马上被执行,而是放进了asyncio的一个队列中,排着队等待被唤醒。当回调函数出队时才会真正开始执行,通常这个回调函数会唤醒协程,然后开始处理Future的返回值。
Future模型有以下的特点:
- Future对象是一次性的,它只能被用来传递一次消息,带来的优点是语义明确、不会出现混淆一次触发和多次触发之类的问题,但缺点是如果需要多次传递相同类型的信息,需要反复重新获取Future,在两次重新获取Future之间如果进行了其他的异步操作,就可能丢失相应的事件,这经常对异步编程带来不小的麻烦。
- asyncio的Future对象是支持广播的,类似于事件处理器。实际上它可以看成是一种轻量级的、一次性的事件处理器。但它只能实现一到多,无法实现多到多,因为一个Future只能被使用一次,多个协程同时向某个Future设置结果时会出问题。
Future比较适合功能较简单的异步过程,但是对于很复杂的系统来说,比较难写出正确的代码。
Channel模型
第二种模型是Go语言当中的统一通信模型,它重点解决了Future只能一次性使用的缺点。一个Channel对象好比是一个可以写入信号的管道,一头可以不断写入新的信号,一头则可以不断取出新的信号,写入的信号遵循先进先出的原则,而且信号本身也可以是数据。Channel还有缓冲区大小的限制,如果写入的信号过多而没有人读出则会产生阻塞;同样如果Channel为空而从Channel中读取也会产生阻塞。Go还支持一种特殊的缓冲区大小为0的Channel,比如要求两个协程恰好一个正在尝试写入、一个正在尝试读取才能成功,否则都会产生阻塞。
使用Channel模型通信的过程可以如下描述:
- 通信双方通过某种方式共享一个Channel,比如通过创建协程时当作参数传入;
- 发送方将要传递的信息写入Channel。如果Channel已满则阻塞。
- 接收方在需要时从Channel中按先进先出顺序读取数据,如果Channel为空则阻塞。
- 当Channel不再需要时需要进行关闭。
Channel模型有以下的特点:
- 可以有多个发送者和多个接收者,实现多对多的关系。多个接收者可以自动实现负载均衡。当接收者不能接收更多信号的时候,发送方也会被阻塞,非常适合实现生产者、消费者模型。
- 同一个Channel中的信号可以实现可靠的传递,不被取出则不会丢失;而且能保证先进先出。
- 在Go当中可以使用select语句同时等待多个channel,在任意一个可以读取出消息时返回,很容易实现等待多个条件之一发生的逻辑
- 同一个信号只能被接收一次,而不能广播给多个接收者,这是Channel模型的一个缺点,要实现广播给多个接收者,需要维护一个Channel的列表,由专门的逻辑负责将信号复制并发送给多个接收者。
Pub/Sub模型——VLCP
之前的文章中介绍了新的协程框架VLCP。它使用的是一种Pub/Sub模型,即发布者、订阅者模型,这是常用于消息队列中的模型,熟悉消息队列用法就会非常熟悉这一套用法。接下来我们详细介绍一下这一套方法,并且看一下这种设计如何结合前几种方案的优点,弥补前几种方案的缺点。
在Pub/Sub模型中,主要分为三个不同的角色:
- 发送方:通过send方法发送一个事件
- 接收方:通过参数订阅并接收一个事件
- 管理:调整事件的优先顺序等
管理也可以由发送方或接收方中任意一个来兼任,主要目的是在许多事件同时存在时,调整优先级顺序,从而影响协程的执行先后次序。
在VLCP当中,发送通过scheduler.send(或者更高层的RoutinerContainer.waitForSend),接收则通过yield语句,可以非常容易的进行。管理则通过调整调度器队列设置进行。
VLCP中的事件是vlcp.event.Event的子类,它首先根据子类类型进行区分,但与其他框架不同,子类可以进一步携带一组索引,用来标识这个事件的不同性质,它与事件类型一起共同起着类似于Pub/Sub中的主题(Topic)的作用。比如说,我们处理OpenFlow协议中的PACKET_IN消息,现在希望定义一种事件来表示有一个PACKET_IN消息到来了,对于接收方来说,可能关心的信息有:消息来自于哪个datapath;来自于哪个连接对象;由哪个table中、cookies为多少的流表生成。我们可以将这些信息作为索引来定义这个事件:
如你所见,定义一个事件非常容易,而定义一个事件几乎就完成了通信需要进行的所有准备工作——不需要创建额外的Future或者Channel对象,甚至,不需要关心要进行通信的双方究竟是谁、在哪、有多少个。使用注解withIndices来定义一个Event的索引,这是必须的,即使Event没有可选的索引,也必须用@withIndices()来表明Event没有索引。
接下来,处理OpenFlow协议的协程会在这个事件发生时通知需要处理事件的协程,它只需要调用发送方的标准方法:
在这个过程中,我们创建了一个新的Event的实例,并提供了相应的索引的值。除了规定的索引值以外,我们还可以给这个Event对象提供额外的属性,它可以直接通过keyword-argument在构造函数中初始化,也可以在创建后再进行属性赋值。所有的索引也会自动被赋给相应的属性,比如说newevent.datapath就会得到datapath索引的值。将这个对象传递给waitForSend过程就完成了发送,waitForSend是个协程过程,使用for来在外层协程中代理这个过程,在Python3当中也可以更简单写成yield from container.waitForSend(...)
那么接下来是接收方的问题,接收方不需要关心事件何时由谁发出,当需要等待一个新的事件发生的时候,只需要简单使用:
在协程中使用yield会暂停协程执行,在VLCP中,yield返回的是一个EventMatcher构成的元组,它可以包含一个或多个EventMatcher。EventMatcher通过Event子类的createMatcher方法创建,它代表一种匹配规则,即匹配这个子类的Event中,相应索引匹配相应值的事件。返回多个EventMatcher时,yield语句会在某个事件匹配任意一个EventMatcher时返回。匹配到的EventMatcher会保存在container.matcher,而发生的事件会保存在container.event。
VLCP内部使用前缀树的数据结构对Event和EventMatcher进行匹配,这是一个很有效率的数据结构,将Event匹配到相应的EventMatcher只需要O(1)的时间。
对同一个事件,不同的协程可以通过createMatcher时的不同参数,来匹配事件集合的不同的子集,这在处理量非常大的时候可以有效提高处理效率,同时不增加程序复杂度。除了使用索引以外,还可以增加一个自定义的筛选过程:
_ismatch的keyword参数用来指定一个函数用于筛选,它接受Event作为唯一的参数,返回True或者False表示是否应当匹配这个Event。_ismatch只有指定索引值已经匹配的情况下才会进行计算。
Event的子类可以进一步派生。进一步派生的Event会继承父类的类型和索引,但也会有自己的类型和索引。子类的子类遵循一般的继承派生的规则:父类的EventMatcher可以匹配子类的Event,但子类的EventMatcher不能匹配父类的Event。比如:
利用这种特殊的继承关系可以拓展原有逻辑,在兼容以前代码的情况下提供新的功能。
VLCP的事件循环结构
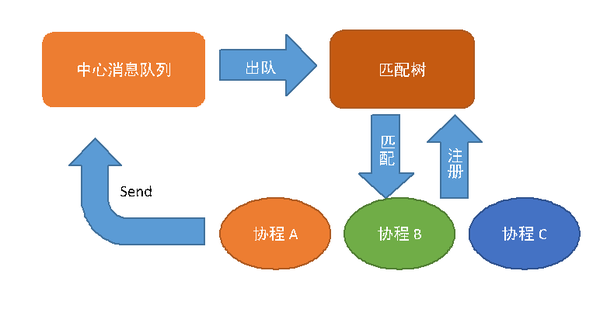
VLCP的事件循环结构可以用上图表示。所有在调度器中运行的协程,都会在暂停运行时将自己注册到匹配树中,与一个或多个EventMatcher进行关联,这个过程通过yield语句完成。在事件循环运行过程中,调度器每次从中心队列中取出一个事件,在匹配树中查找与这个事件匹配的EventMatcher和相关联的协程,然后依次唤醒这些协程,通知它们等待的事件已经发生;协程在运行时,可以将事件通过send过程发送到中心消息队列。在协程停止运行时,协程重新使用yield语句将自己注册到匹配树中,等待下一个循环。
当消息队列为空或无法出队时,调度器会调用Poller(在Linux当中由EPoll实现,其他操作系统当中使用Select)等待socket活动。Poller会将socket的活动返回成PollEvent,这同样是Event的子类,这些事件会由负责处理socket活动的协程进行处理,然后进一步产生后续的事件。当没有活动的socket时,调度器会开始引导整个框架退出。
防止事件遗失
通常的Event可以有一个或多个协程进行处理,也可以没有处理协程,这些未被处理的事件会被安全地丢弃,这个逻辑类似于Future,需要协程自己保证正确注册了EventMatcher,但VLCP的事件是按顺序一个一个处理的,因此:
- 不会像Future中一样,出现同时等待的多个事件同时发生,更类似于Channel中的select
- 由于一次只处理一个事件,只要注意在每个yield中都注册了相应的EventMatcher,就不会遗漏某种类型的事件
我们举个例子,我们有EventA和EventB两种类型的事件,我希望在协程中能处理所有的EventA和EventB,一般只需要这样写:
如果event_a或event_b的处理过程需要等待其他Event,则要小心,处理不当可能会导致事件遗漏:
只要注意所有的yield语句就可以避免这种情况发生,除了有显示的yield语句的地方,协程不会发生中断。解决上面的问题的一种方法是启动一个新协程来执行比较复杂的过程:
创建了一个闭包来作为协程使用,简单明了
前面的方法会对每个到来的事件启动一个新的协程,这样上一个事件还没处理完的时候下一个事件到来,会有两个处理过程并行执行。有的时候我们不希望事件的处理过程重入,在上一批事件处理结束之前不要启动新的处理过程,这可以通过在处理过程的每个yield中插入需要等待的EventMatcher来防止遗漏,但这样显然比较复杂,RoutineContainer.withCallback方法可以自动在某个协程过程的每个yield上插入相同的EventMatcher,并在发生时调用一个简单的回调函数(使用event和matcher作为参数),然后返回到原来的协程过程中,比如下面的例子:
在复杂的处理过程中,我们插入一个callback,将发生的事件缓存到一个列表中,防止丢失。这样在处理过程中调用其他协程方法也没有关系。
withCallback的另一个有趣的应用是在callback当中抛出一个异常,这个异常会打断withCallback的执行,从而结束整个过程,它可以用来实现执行超时、网络中断异常之类的异常处理,让已经没有必要继续下去的过程尽早结束。RoutineContainer.withException是个等效的实现,在EventMatcher匹配到事件时立即抛出异常从而中断内部过程的执行,RoutineContainer.executeWithTimeout则是一个应用,通过TimerEvent来触发异常中断执行。使用withCallback可以更细致地选择在哪些情况下抛出异常,哪些情况下继续执行。
可见对于比较复杂的过程来说,使用VLCP的模型,要比使用Future更容易写出正确、优雅的代码。
阻塞式事件
虽然前一节中已经表明只要充分留意就不会发生遗漏事件的情况,但有些时候我们仍然需要Channel当中的阻塞式的特性,来实现生产者、消费者模型。VLCP通过阻塞式事件来实现这一目的。实现上其实非常简单,只需要将某个Event的canignore属性设置为False即可。为了让某个Event默认阻塞,可以在class中定义canignore = False作为默认值:
具有canignore = False的事件在处理结束后如果仍有canignore=False,这个事件会重新回到事件队列中,并将相应的队列阻塞,阻止同队列中的事件被处理,直到有新的协程匹配了这个事件为止。这就正确实现了Channel模型当中的阻塞效果。
匹配并处理这个事件的协程需要在匹配到之后将canignore设置为True,从而告知事件循环该事件已经正确处理。如:
阻塞式事件本身可以保证每个事件都被正确处理,因此处理过程中可以任意使用yield,不用担心遗漏事件。如果有多个协程想要仿照Channel的模型进行负载均衡的处理,可以像上面的例子一样检查canignore是否已经被其他协程设置,从而保证一个事件只被处理一次。
有些时候我们需要丢弃一些阻塞式事件,比如在连接已经断开的情况下,与连接相关的事件应当被丢弃,因为连接相关的协程可能已经退出,没有协程能够继续处理了。这对应Channel模型中的close过程。这个过程可以通过两种机制实现:一种是对队列的clear操作(后面会提到),一种是ignore/canignorenow的组合使用,这些属于实现细节,可以参考代码,一般不会在应用代码中使用。
阻塞式事件使用起来是比较复杂的,而且不正确的使用可能会导致很严重的问题,比如实现逻辑错误或者内存泄漏等。它通常只在很底层的逻辑中(比如Socket写入,Stream写入等)被使用,用来提供双向阻塞的能力。在asyncio中,如果需要连续向socket写入大量内容,需要主动使用drain方法,否则就会将大量数据保存在缓冲区中,甚至导致内存溢出。在VLCP当中则不会有这种担心,通过阻塞机制,尝试向Socket写入过多数据的协程会自动被阻塞,这简化了许多逻辑的实现。
子队列
前面提到,对于阻塞式事件来说,没有及时处理时会回到事件队列,并阻塞队列直到被正确处理为止。如果我们的中心消息队列只有一条先进先出的队列,则整个队列都会被阻塞,这可能会导致CPU时间被浪费甚至死锁。解决这个问题的方法是引入多队列。中心消息队列可以为特定类型的事件创建子队列,在入队时将事件放入子队列中;当事件发生阻塞时,只有所在子队列被阻塞,其他子队列仍然能正常取出事件。除了防止阻塞以外,子队列模型还起着重新安排事件优先级的作用,当高优先级子队列中有事件时会优先处理,而同一优先级的队列则会轮流取出事件,这样可以帮助调度系统将有限的CPU时间均匀分配给不同的任务,防止某些协程任务过多占用资源。
子队列可以有长度限制,这样可以实现Channel模型形式的写入阻塞。当队列已满时,使用waitForSend协程过程向队列写入事件会产生阻塞,这样就防止生产者生产过快而消费者无法及时消费的情况出现。配合阻塞式事件则产生了等效的Channel模型。
子队列的长度限制是个软限制,在特殊情况下(比如finally过程中,不能使用yield中断执行),可以使用emergesend的方法强制将事件送入队列而不产生阻塞,此时队列长度可能会超过限制,只有重新恢复到限制以下之后才能正常写入。需要避免产生阻塞时可以用这种方法,但破坏了设计好的限制可能会带来问题。
子队列长度限制最小为1,因此不支持Go当中的无缓存Channel,但有一个小技巧可以提供类似的功能:先创建长度限制为1的子队列,然后向子队列中预先写入一个阻塞式的事件,使队列变满。这样只有取出前一个事件时后一个事件才能写入。VLCP中的Lock使用这个方法实现,缺点则是只能发送信号而不能传输数据。
子队列能够进一步创建子队列,这个设计模仿了Linux当中的tc,可以实现精细的事件整形(模仿Traffic Shaping的Event Shaping)。子队列是父队列的一部分,当父队列有机会取出事件时,嵌套的子队列会按照相同的规则:优先级从高到低、同优先级轮询的方式取出事件。子队列和父队列的长度限制会同时生效,两者任意一个到达上限则不能写入。
除了可以等待队列可写以外,也可以等待某个子队列变为空,这可以用于实现某些逻辑,比如在尝试关闭socket时,保证socket上最后的数据仍然正确写出。
对子队列优先级的细微调整可以微调协程的执行顺序,这对于有精细的执行顺序要求的场景下是比较重要的。但一般来说是一个不需要大量使用的高级功能。
有用的控制流程
RoutineContainer当中预先设计了一些有用的协程控制流程,它们是基础的Pub/Sub模型的补充,而且全部由Pub/Sub模型来实现。使用这些流程可以快速实现需要的逻辑。
使用camel命名而不是PEP8推荐的下划线命名是一个历史遗留问题
- subroutine:启动新的协程独立执行。这个之前介绍过
- terminate:让某个协程结束。subroutine会返回一个协程的句柄(其实是个生成器对象),terminate调用这个生成器的close方法来让这个协程推出。也可以直接调用close。VLCP不需要使用asyncio当中的复杂的cancel机制。
- waitForSend:如前面介绍的一样,发送指定的Event,如果发生了阻塞则等待直到写入成功。
- waitWithTimeout:等待若干个EventMatcher匹配到事件,同时设置超时时间,如果时间到了仍然没有任何一个Event匹配到,则返回timeout(设置container.timeout = True);否则设置timeout为False,且正常返回event和matcher。如果一个matcher都不提供,则相当于sleep的作用。如果timeout为None则无限等待(相当于直接yield matchers)
- executeWithTimeout:执行一个指定的协程过程,同时指定超时时间。如果时间到了仍然没有执行结束,则强制中止协程过程,并返回timeout = True。否则timeout = False。
- doEvents:主动让出时间片给其他协程,直到事件循环的下一个周期Poller()被执行之后再继续,对于非常耗时的过程可以防止占用太长时间导致socket停止响应之类的问题。
- withException:执行指定的协程过程,并指定一个或多个EventMatcher,如果期间EventMatcher匹配到了某个事件,则抛出异常并终止协程过程的执行。
- withCallback:执行指定的协程过程,并指定一个callback函数,和一个或多个EventMatcher。在执行协程过程期间匹配到了相应的事件,则执行callback函数然后继续原来的过程。如果callback函数中抛出异常则中止协程过程的执行。
- waitForEmpty:等待直到某个队列中不再存在事件。在这期间队列中可以被写入新的事件,直到队列第一次为空时触发。如果队列已经为空则立即返回。
- waitForAll:等待所有的EventMatcher均各自匹配到一次Event,相当于asyncio中的gather方法。
- waitForAllToProcess:与waitForAll相似,但可以用来处理阻塞式事件,会在匹配到事件后自动设置canignore=True。
- waitForAllEmpty:等待所有指定的队列都为空。只有所有队列同时为空时才会返回,因为可能出现某个队列曾经为空,后来又被写入事件的情况出现。
- delegate:执行一个协程,并等待协程完成。许多协程过程必须在指定的RoutineContainer当中执行,这个方法可以用于在其他RoutineContainer当中启动一个协程过程。
- delegateOther:与delegate类似,但可以在执行完成后获取协程过程的返回值。
- beginDelegateOther:delegateOther的非协程过程版本,会在成功启动协程后立即返回一个EventMatcher,等待这个EventMatcher就可以等待协程完成
- executeAll:beginDelegateOther的一个最有用的应用。并行执行多个协程过程,并收集协程执行的结果(相当于asyncio的gather方法)
具体实现可以参考 https://github.com/hubo1016/vlcp/blob/master/vlcp/event/runnable.py 。阅读这些实现也有助于理解VLCP的Pub/Sub模型的一般编程方法。
对接线程池
基于Event/EventMatcher的Pub/Sub模型可以拓展到异步逻辑以外,这是通过vlcp.utils.connector实现的。有时候我们需要调用非协程的库,这些库可能是基于多线程的,我们需要在另外一个线程中执行这些过程来防止主线程被阻塞。最简单的方法是使用TaskPool,它会自动创建线程池(或者使用multiprocesing来创建多进程代替)来执行一些小任务。它有三个不同的方法:
- runTask:最常用的方法,三个参数为container, task, newthread。container是当前协程关联的RoutineContainer,task是一个无参数的函数(可以用functools.partial,或者lambda函数,或者嵌套函数的方式生成一个闭包),它会在线程池中执行,然后在执行结束时将结果写入container.retvalue。如果线程池中的任务发生了异常,异常会被回传到runTask中抛出。对于很耗时的过程可以指定newthread = True,让线程池创建一个独立的线程来执行这个过程,防止线程池本身被阻塞,默认为False。
- runGenTask:一个略为高级的方法,参数为container,gentask, newthread,意义与runTask类似,但newthread的默认值为True。有时候我们希望在线程池中执行的任务除了返回最终结果以外,能返回一些中间过程的信号,比如说一个下载过程,可以在中间返回进度提示。runGenTask传入的gentask是一个生成器方法,它可以通过yield返回一系列的自定义的Event,这些Event会由TaskPool回传到协程调度器的中心队列中,由其他协程进行处理。
- runAsyncTask:另一种返回中间结果的方法。有时候我们执行的任务本身也会使用多线程,不能在本线程中返回Event,这时可以使用runAsyncTask,它的参数为container,asynctask,newthread,newthread默认值为True。asynctask是一个有一个参数sender(event)的函数,sender(event)是一个回调方法,在asynctask中可以调用sender来回传自定义的Event,实现线程池中方法与协程的通信。asynctask可以返回一个结果,这个结果会写入container.retvalue。
注意线程池中执行的任务不会被取消,即使协程方法被executeWithTimeout之类的方法打断也是这样。如果没有空闲的线程导致堆积任务过多时,尝试发送线程池任务会通过子队列阻塞这个协程,然后让其他协程进行调度,而不会产生整个主线程的阻塞,非常安全。这个机制也是通过前面提到的子队列长度限制实现的。
总结
VLCP的Pub/Sub模型是面向较为复杂的异步逻辑设计的,它可以帮助你很容易地实现复杂的异步逻辑。它综合了其他模型的优点,甚至在这种模型的基础上可以很容易模拟出其他模型。其他优点还包括:
- 非常松散的耦合,而且天然支持广播,因此非常有利于扩展。增加一个接收者完全不需要改动发送者的逻辑,也不会影响其他接收者的正常工作。
- 发送方和接收方不需要提前进行同步,期间任何一方都可以重新启动而不会影响另一方工作,这样可以实现Erlang风格的热更新而不影响逻辑
- 与MQ模型相似,可以很容易通过外部的MQ将程序逻辑拓展到分布式系统上。
- 可以通过调整子队列设置来微调协程调度顺序。
它的缺点则是调度过程比起asyncio等要复杂一些,影响整体性能。但是相应的,业务代码逻辑会更加清晰,在业务相对复杂的时候,压力集中在核心代码中,而核心代码可以通过Cython等手段进行优化,所以反而可能产生性能优势。