
Golang以并发见长,支持成千上万个协程调度。Golang中协程称为Goroutine,它是Go runtime调度中的最小执行单元,Goroutine的创建、管理、调度运行的机制采用的GMP模型。本次分享介绍的就是Golang调度机制的GMP模型。
并行 vs 并发
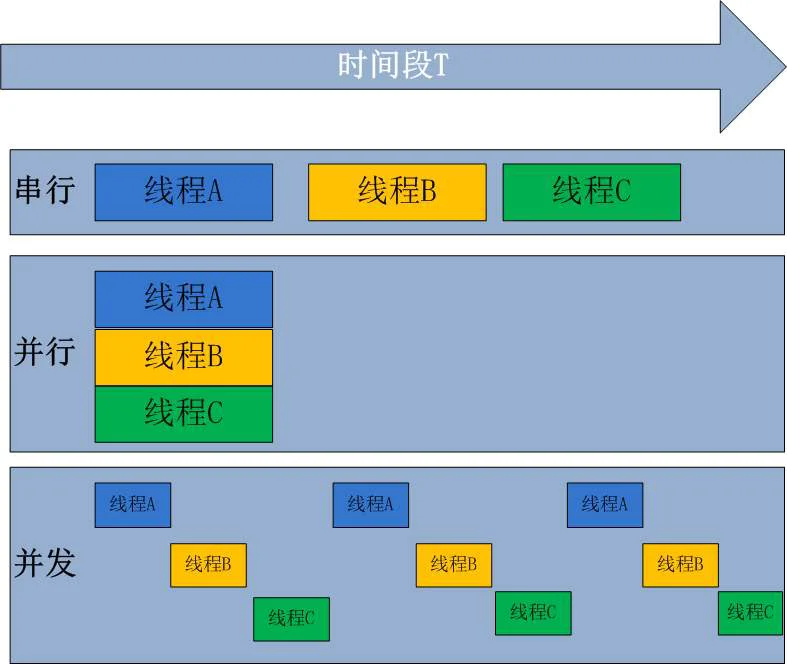
并行(Parallelism) 指的是一个CPU时间片内可以同时做多件事情。并行强调的是某一时间点内能够同时处理多件事情,并行需要多核CPU提供支持。并行是并发的子集。
并发(Concurrency) 指的是是一种同时处理许多事情的能力,并行强调是某一时间段内能够同时处理多件事情。
进程 vs 线程 vs 协程
进程
在仅支持进程的操作系统中,进程是拥有资源和独立调度的基本单位(这样的进程可以考虑是只有一个线程的进程)。在支持线程的操作系统中,线程是独立调度的基本单位,而进程是资源拥有的基本单位。
进程是应用程序运行时的抽象。一个进程包含两部分:
- 静态部分:程序运行需要的代码和数据
- 动态部分:程序运行期间的状态(程序计数器、堆、栈......)
进程具有独立的虚拟地址空间。当应用程序运行起来时候,系统会将该应用加载到内存中,应用程序会独立的、完全的占用所有内存,这里的内存指的是虚拟内存,对于32位系统,该虚拟内存大小是2^32 = 4G,也就是说每个进程都具有“独占全部内存”的假象。
下面是进程的运行时的内存布局:
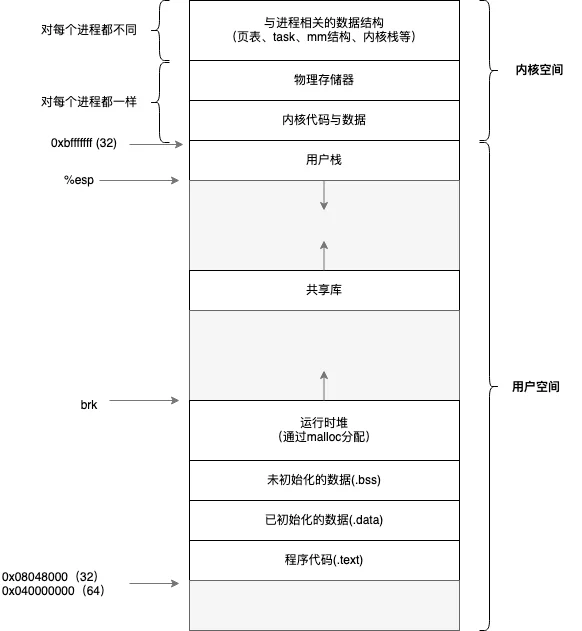
进程的创建是通过fork系统调用实现的,创建时候会将父进程的上面内存布局COPY 一份,所以说进程的创建是非常耗CPU资源操作(尽管fork系统调用支持了写时拷贝,建立映射关系也是耗时操作)。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <wait.h>
int x = 1;
int main(int argc, char *argv[]) {
int pid;
pid = fork();
if (pid == 0) { /* child */
x = 2;
printf("Child process set x=2\n");
exit(EXIT_SUCCESS);
}
if (pid < 0) { /* parent, upon error */
perror("fork");
exit(EXIT_FAILURE);
}
wait(NULL);
printf("Parent process sees x=%d\n", x);
return EXIT_SUCCESS;
}
复制代码运行上面程序,输出以下内容:
Child process set x=2
Parent process sees x=1
复制代码线程
线程是更加轻量级的运行时抽象。线程只包含运行时的状态:
- 静态部分由进程提供
- 包括了执行所需的最小状态(主要是寄存器和栈)
一个进程可以包含多个线程。一个进程的多线程可以在不同处理器上同时执行,调度的基本单元由进程变为了线程,上下问的切换单位是线程。每个线程都拥有自己的栈,内核也有为线程准备的内核栈。
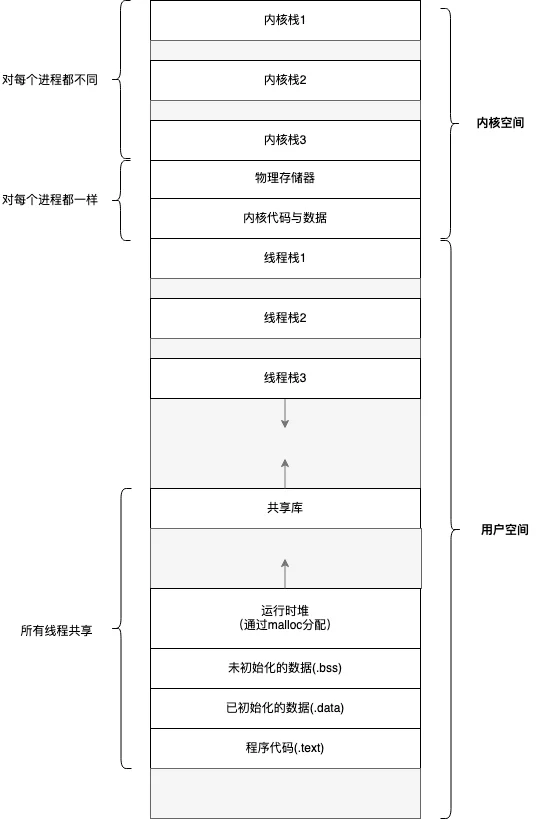
根据线程是否受内核直接管理,可以把线程分为两类:用户级线程和内核级线程。
- 在用户级线程中,线程的创建、管理等所有工作都由应用程序基于线程库完成,内核意识不到线程的存在。
- 在内核级线程中,线程管理的所有工作都由内核完成。
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int x = 1;
void *mythread(void *arg) {
x = 2;
printf("Child process set x=2\n");
return NULL;
}
int main(int argc, char *argv[]) {
int en;
pthread_t tid;
void *vp;
if ((en = pthread_create(&tid, NULL, mythread, NULL)) != 0) {
fprintf(stderr, "pthread_create: %s\n", strerror(en));
exit(EXIT_FAILURE);
}
if ((en = pthread_join(tid, &vp)) != 0) {
fprintf(stderr, "pthread_join: %s\n", strerror(en));
exit(EXIT_FAILURE);
}
printf("Parent process sees x=%d\n", x);
return EXIT_SUCCESS;
}
复制代码运行上面程序,输出以下内容:
Child process set x=2
Parent process sees x=2
复制代码协程
协程是用户态下的轻量级线程,在不同的场景下中有不同的叫法,由Linux实现的叫做纤程(Fiber),由开发语言实现的一般叫协程(Coroutine)。协程的实现采用模型一般是用户级线程模型或者两级线程模型。Go语言的协程叫做Goroutine(是由Go 和 Coroutine拼接出来的词)。Goroutine具有以下特点:
- 启动成本小,初始的栈空间大小仅2Kb,并且栈空间可以自动伸缩
- 工作在用户态,切换成很小
- 采用两级线程模型,可以在n个系统级线程上多工调度m个Goroutine。
线程模型
线程创建、管理、调度等采用的方式称为线程模型。线程模型一般可分为以下三种:
-
内核级线程模型
-
用户级线程模型
-
两级线程模型,也称混合型线程模型
三大线程模型最大差异就在于用户级线程与内核调度实体KSE(KSE,Kernel Scheduling Entity)之间的对应关系。KSE是Kernel Scheduling Entity的缩写,其是可被操作系统内核调度器调度的对象实体,是操作系统内核的最小调度单元,可以简单理解为内核级线程。
内核级线程模型
内核级线程模型中用户线程与内核线程是一对一关系(1 : 1)。线程的创建、销毁、切换工作都是有内核完成的。应用程序不参与线程的管理工作,只能调用内核级线程编程接口。每个用户线程都会被绑定到一个内核线程。用户线程在其生命期内都会绑定到该内核线程。一旦用户线程终止,两个线程都将离开系统。
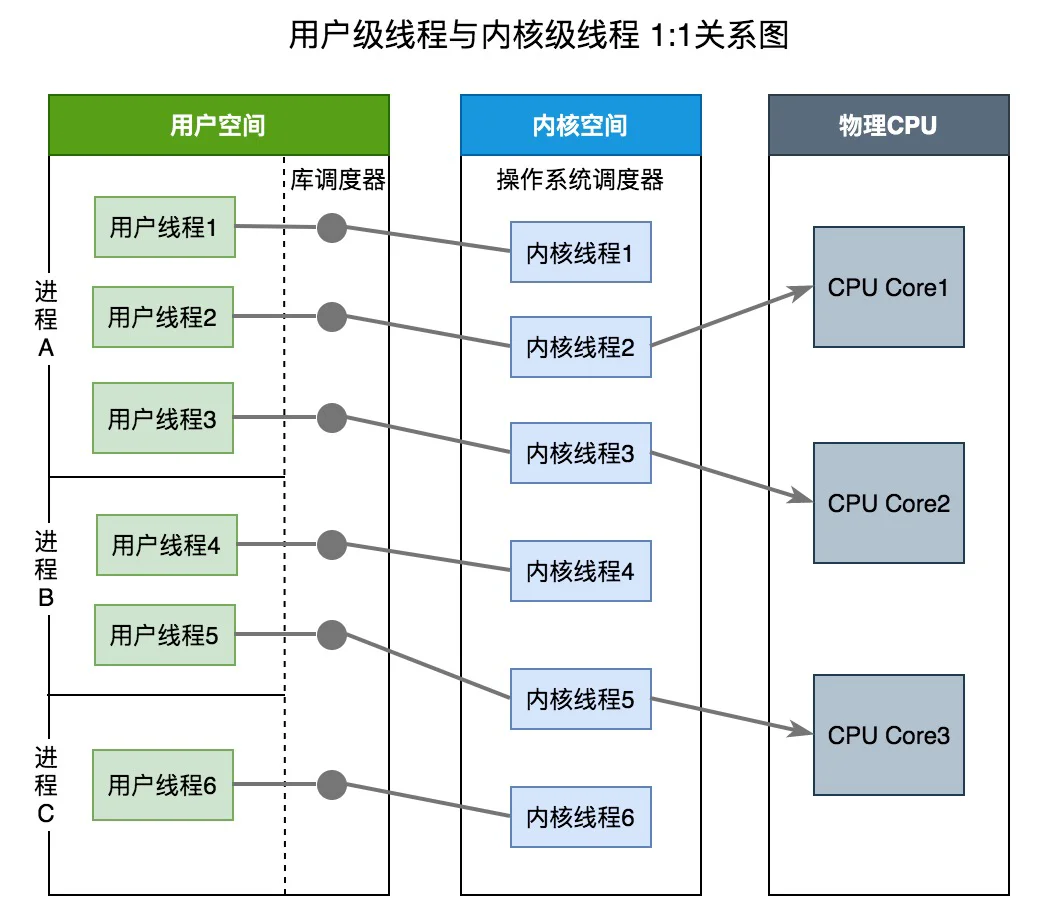
操作系统调度器管理、调度并分派这些线程。运行时库为每个用户级线程请求一个内核级线程。内核级线程模型有如下优缺点:
优点:
-
在多处理器系统中,内核能够并行执行同一进程内的多个线程
-
如果进程中的一个线程被阻塞,不会阻塞其他线程,是能够切换同一进程内的其他线程继续执行
缺点:
- 线程的创建与删除,调度等都需要系统内核参与,成本大。
用户级线程模型
用户级线程模型中的用户态线程与内核态线程KSE是多对一关系(N : 1)。线程的创建、销毁以及线程之间的协调、同步等工作都是在用户态完成,具体来说就是由应用程序的线程库来完成。从宏观上来看,任意时刻每个进程只能够有一个线程在运行,且只有一个处理器内核会被分配给该进程。
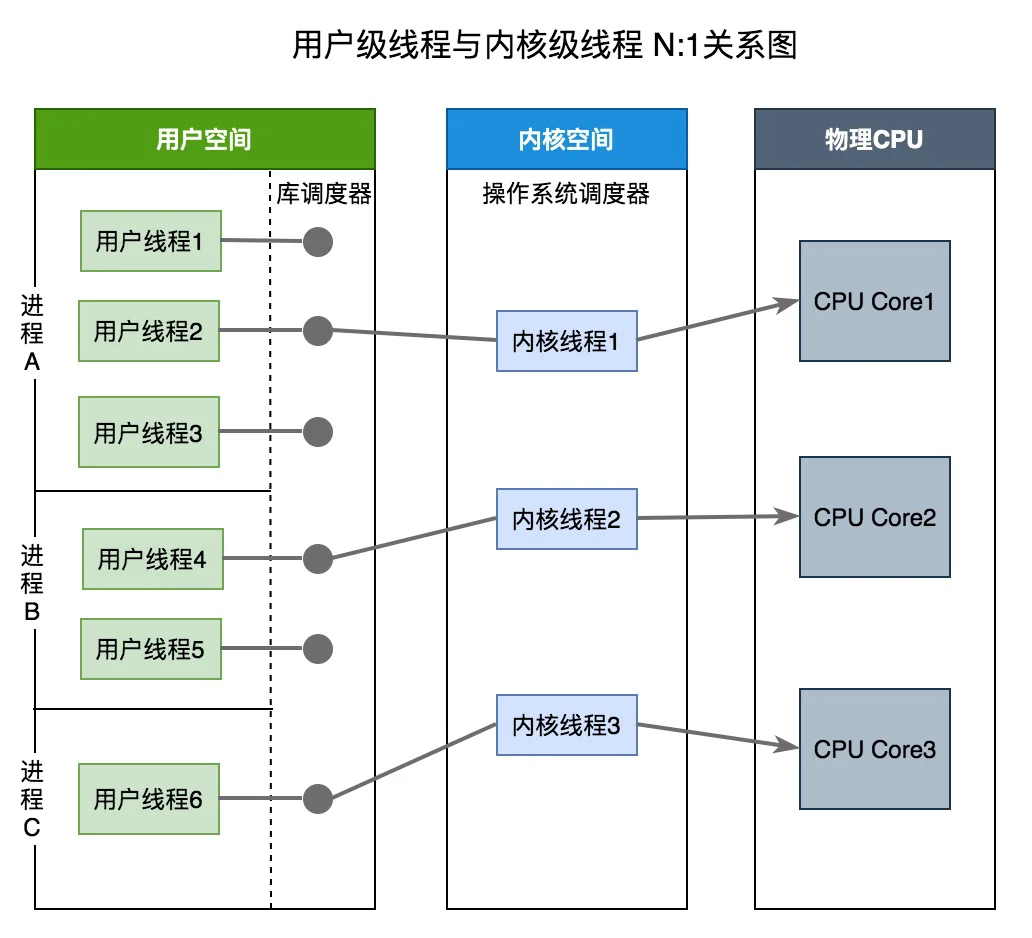
从上图中可以看出来:库调度器从进程的多个线程中选择一个线程,然后该线程和该进程允许的一个内核线程关联起来。内核线程将被操作系统调度器指派到处理器内核。用户级线程是一种”多对一”的线程映射。
用户级线程模型有如下优缺点:
优点:
-
创建和销毁线程、线程切换代价等线程管理的代价比内核线程少得多, 因为保存线程状态的过程和调用程序都只是本地过程
-
线程能够利用的表空间和堆栈空间比内核级线程多
缺点:
-
线程发生I/O或页面故障引起的阻塞时,如果调用阻塞系统调用则内核由于不知道有多线程的存在,而会阻塞整个进程从而阻塞所有线程, 因此同一进程中只能同时有一个线程在运行
-
资源调度按照进程进行,多个处理机下,同一个进程中的线程只能在同一个处理机下分时复用
两级线程模型
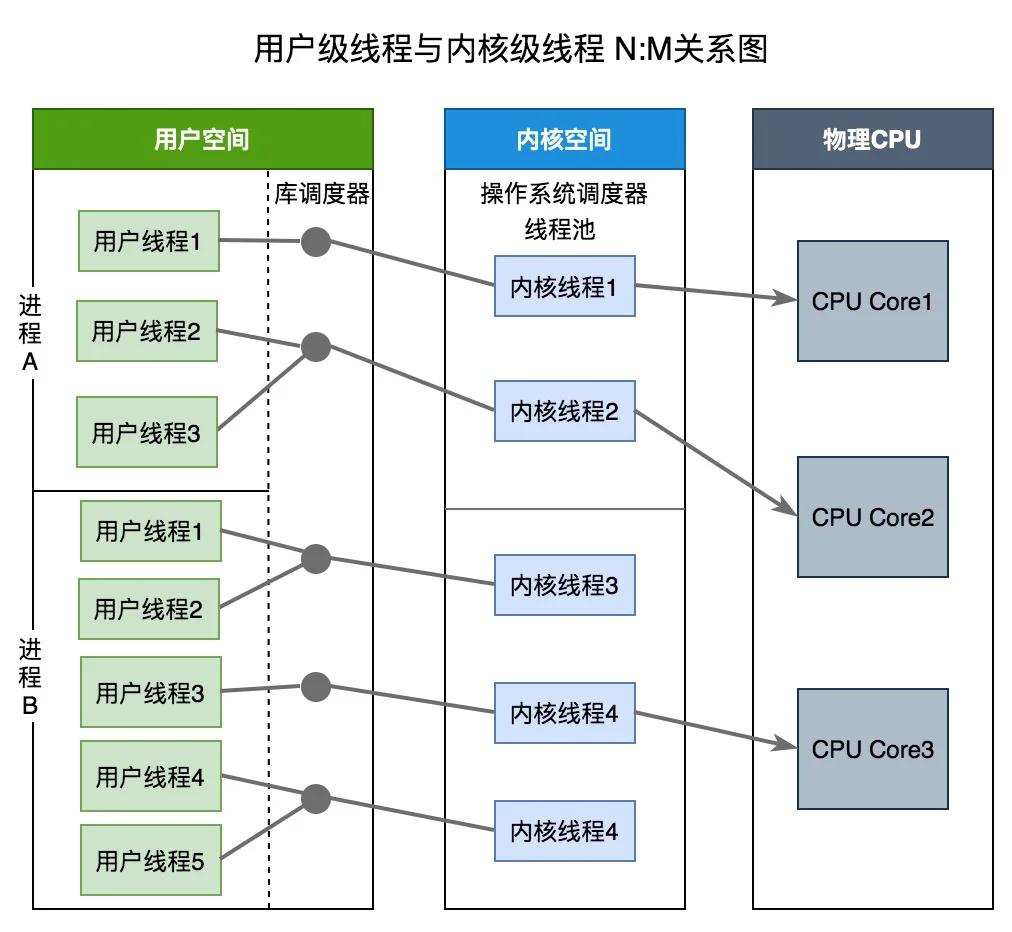
两级线程模型中用户态线程与内核态线程是多对多关系(N : M)。两级线程模型充分吸收上面两种模型的优点,尽量规避缺点。其线程创建在用户空间中完成,线程的调度和同步也在应用程序中进行。一个应用程序中的多个用户级线程被绑定到一些(小于或等于用户级线程的数目)内核级线程上。
Golang的线程模型
Golang在底层实现了混合型线程模型。下图中M代表着系统线程,一个M关联一个KSE,即两级线程模型中的系统线程。G为Groutine,即两级线程模型的的应用级线程。M与G的关系是N:M。
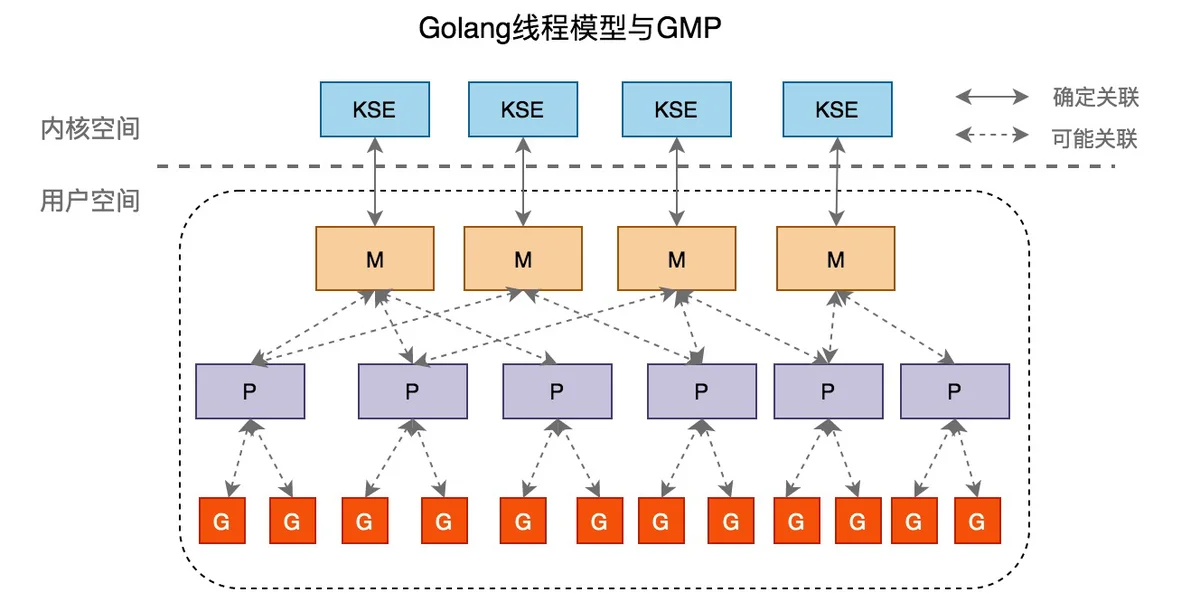
GMP模型
G,M,P 分别是Go runtime调度的核心底层数据结构,所以Golang中调度模型也称为GMP模型。GMP分别代表的含义如下:
- G - Goroutine,为Go协程,是参与调度与执行的最小单位,是并发的关键。
- M - Machine,指的是系统级线程,负责执行G。
- P - Processor,指的是逻辑处理器,数量等于CPU核数,代表了并行。每个P都拥有一个本地可运行G的队列(Local ruanble queue,简称为LRQ),该队列最多可存放256个G。
GMP模型概览图:
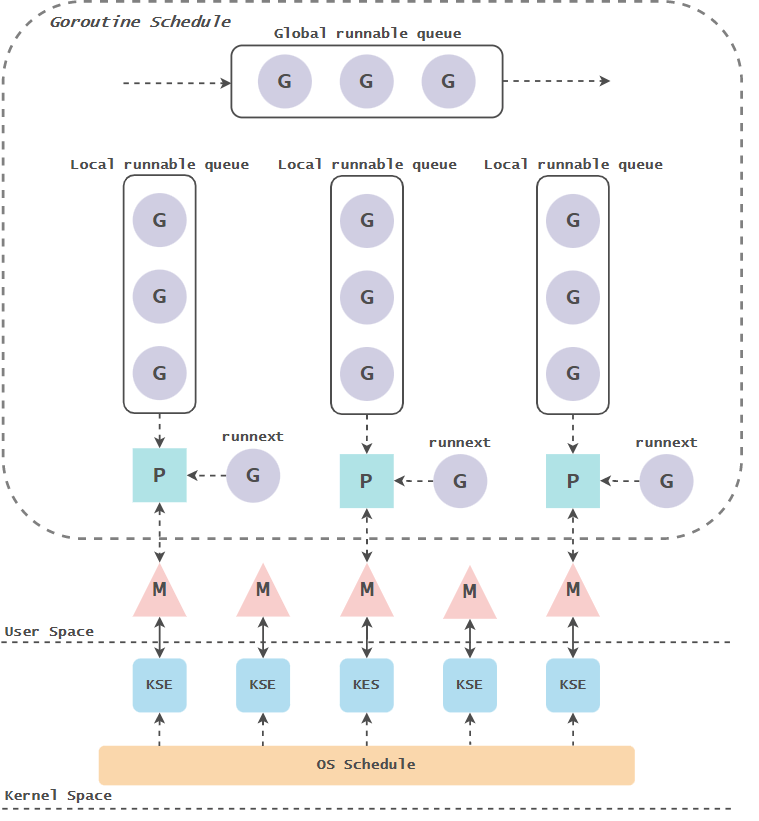
Golang最开始的调度模型只有G和M,G放在全局队列中,M都是从全局队列中获取可运行的G,这需要全局的锁保证并发安全,性能比较差。后续追加P数据结构,对应每一个CPU核心,M执行G之前都需关联一个P,后续M获取G只需从其关联的P的本地队列获取,这个获取过程是无锁。
当M关联的P的LRQ没有可以执行的G时候,其可以从Gloable runable queue(GRQ)或者其他P上窃取(work stealing)可以执行的G。
调度的流程
func main() {
runtime.GOMAXPROCS(1)
for i := 1; i <= 5; i++ {
j := i
go func() {
fmt.Println(j)
}()
}
time.Sleep(3 * time.Second)
}
复制代码j:=i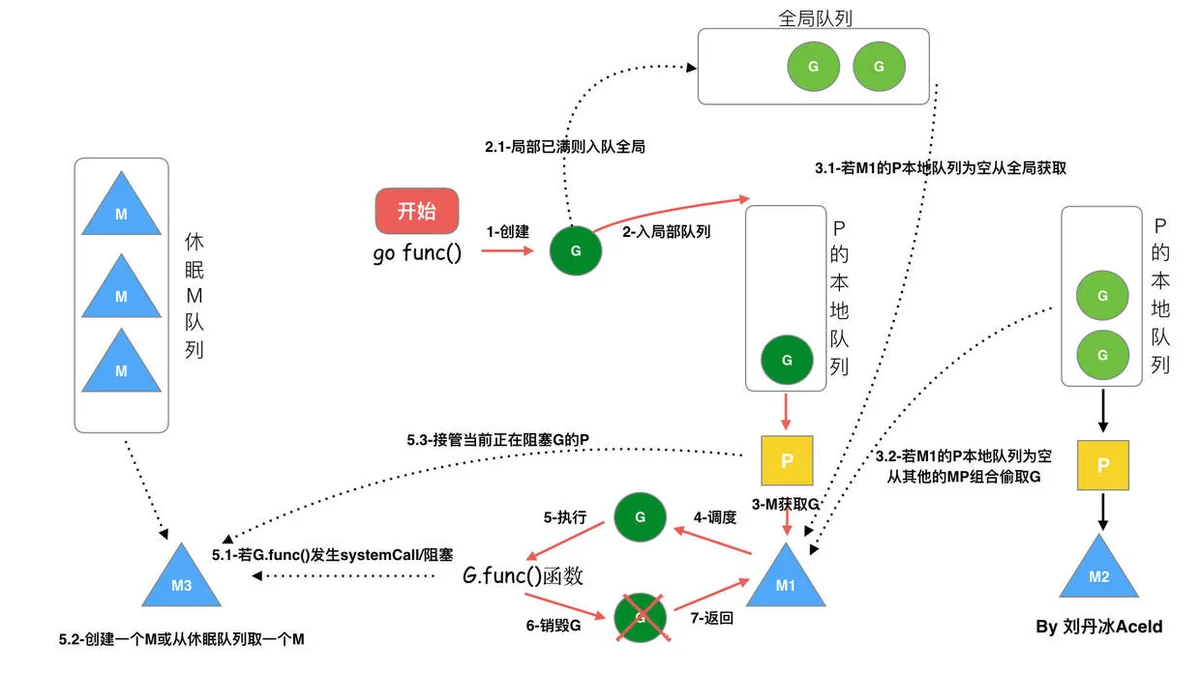
-
每个P有个局部队列(LRQ),局部队列保存待执行的goroutine(流程2),当M绑定的P的的局部队列已经满了之后就会把goroutine放到全局队列(流程2-1)
-
每个P和一个M绑定,M是真正的执行P中goroutine的实体(流程3) ,M从绑定的P中的局部队列获取G来执行
-
当M绑定的P的局部队列为空时,M会从全局队列获取到本地队列来执行G(流程3.1),当从全局队列中没有获取到可执行的G时候,M会从其他P的局部队列中偷取G来执行(流程3.2),这种从其他P偷的方式称为work stealing
-
当G因系统调用阻塞(属于系统调用阻塞)时会阻塞M,此时P会和M解绑即hand off,并寻找新的idle的M,若没有idle的M就会新建一个M(流程5.1)
-
当G因channel(属于用户态阻塞)或者network I/O阻塞时,不会阻塞M,M会寻找其他runnable的G;当阻塞的G恢复后会重新进入runnable进入P队列等待执行(流程5.3)
GMP模型高效的保证策略有:
-
M是可以复用的,不需要反复创建与销毁,当没有可执行的Goroutine时候就处于自旋状态,等待唤醒
-
Work Stealing和Hand Off策略保证了M的高效利用
-
内存分配状态(mcache)位于P,G可以跨M调度,不再存在跨M调度局部性差的问题
-
M从关联的P中获取G,不需要使用锁,是lock free的
参考资料
复制代码