
函数是 Go 语言中的一等公民,理解和掌握函数的调用过程是深入学习 Golang 时无法跳过的步骤,这里会介绍 Go 语言中函数调用的过程和实现原理并与 C 语言中函数执行的过程进行对比,同时对参数传递的原理进行剖析,让读者能够清楚地知道 Go 在函数的执行过程中究竟都做了哪些工作。
本文将从函数的调用惯例和参数的传递方法两个方面分别介绍函数的执行过程,同时在这里会默认阅读这篇文章的读者已经掌握了 栈、寄存器 等概念,文章并不会就这两部分内容展开进行介绍。
调用惯例
在计算机科学中,调用惯例其实就是指在实现层面上,一个函数(子程序)如何接受主程序传递的参数并如何将返回值传递回主程序。不同语言对于传递参数和返回值的实现上会有一些差异,不过无论是在 C、Go 语言这种比较接近系统的编程语言,还是 Ruby、Python 这类语言,它们在函数调用上往往都具有相同的形式,也就是一般包含函数名、参数列表两个部分:
somefunction(arg0, arg1)
虽然它们的调用形式看起来差不多,但是在这里我们需要考虑 C 和 Go 这两门语言究竟是如何实现调用惯例的,这对于我们理解的 Go 语言的函数调用原理会有非常大的帮助。
C 语言
如果想要了解 C 语言中的函数调用的原理,我们可以通过 gcc 或者 clang 将 C 语言的代码编译成汇编语言,从汇编语言中可以一窥函数调用的具体过程,作者使用的是编译器和内核的版本如下:
$ gcc --version
gcc (Ubuntu 4.8.2-19ubuntu1) 4.8.2
Copyright (C) 2013 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
$ uname -a
Linux iZ255w13cy6Z 3.13.0-32-generic #57-Ubuntu SMP Tue Jul 15 03:51:08 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
gcc 和 clang 虽然在编译 C 语言代码时生成的汇编语言可能有比较大的差别,但是生成代码的结构不会有太大的区别,需要注意的是不同内核版本的操作系统生成的汇编指令可能有比较大的不同,不过对于我们这些只是想要了解实现原理的开发者来说没有太多的影响。
mainmy_functionint my_function(int arg1, int arg2) {
return arg1 + arg2;
}
int main() {
int i = my_function(1, 2);
}
gcc -S main.cmain.smy_function:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -8(%rbp), %eax
movl -4(%rbp), %edx
addl %edx, %eax // arg1 + arg2
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
main:
.LFB1:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $2, %esi // 处理第二个参数
movl $1, %edi // 处理第一个参数
call my_function
movl %eax, -4(%rbp)
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
my_functionmy_functionmainmy_functionimy_function// main.c
int my_function(int arg1, int arg2, int arg3, int arg4, int arg5, int arg6, int arg7, int arg8) {
return arg1 + arg2 + arg3 + arg4 + arg5 + arg6 + arg7 + arg8;
}
int main() {
my_function(1, 2, 3, 4, 5, 6, 7, 8);
}
// main.s
main:
.LFB1:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $8, 8(%rsp)
movl $7, (%rsp)
movl $6, %r9d
movl $5, %r8d
movl $4, %ecx
movl $3, %edx
movl $2, %esi
movl $1, %edi
call my_function
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
mainmy_function需要说的是,rbp 是一个存储函数调用堆栈基址指针的寄存器,也就是说当前函数栈是从哪里开始的;另一个寄存器 rsp 存储的就是当前函数调用栈栈顶的位置,也就是当前栈的内存分配到了哪里,这两个寄存器表示一个函数栈的开始和结束。
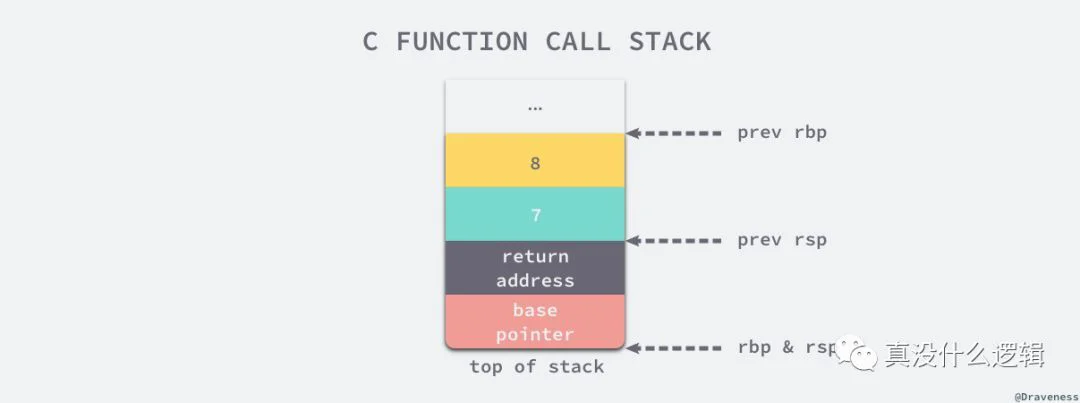
c-function-call-stack
subq $16, %rspcall my_functionmy_functionmy_function:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl %edx, -12(%rbp)
movl %ecx, -16(%rbp)
movl %r8d, -20(%rbp)
movl %r9d, -24(%rbp)
movl -8(%rbp), %eax // eax = 2
movl -4(%rbp), %edx // edx = 1
addl %eax, %edx // edx = eax + edx = 3
movl -12(%rbp), %eax
addl %eax, %edx
movl -16(%rbp), %eax
addl %eax, %edx
movl -20(%rbp), %eax
addl %eax, %edx
movl -24(%rbp), %eax
addl %eax, %edx
movl 16(%rbp), %eax // eax = 7
addl %eax, %edx // edx = eax + edx = 28
movl 24(%rbp), %eax // eax = 8
addl %edx, %eax // edx = eax + edx = 36
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
my_functionsubq简单总结一下,如果我们在 C 语言中调用一个函数,函数的参数是通过寄存器和栈传递的,在 x86_64 的机器上,6 个以下(含 6 个)的参数会按照顺序分别使用 edi、esi、edx、ecx、r8d 和 r9d 六个寄存器传递,超过 6 个的剩余参数会通过栈进行传递;函数的返回值是通过 eax 寄存器进行传递的,这也就是为什么 C 语言中不支持多个返回值。
Golang
介绍了 C 语言中函数调用的流程之后,接下来我们再来剖析一下 Golang 中函数调用时参数和返回值如何传递的。在这里我们以下面这个非常简单的代码片段为例简单分析一下:
package main
func myFunction(a, b int) (int, int) {
return a + b, a - b
}
func main() {
myFunction(66, 77)
}
myFunctionintintmain"".main STEXT size=68 args=0x0 locals=0x28
0x0000 00000 (main.go:7) TEXT "".main(SB), $40-0
0x0000 00000 (main.go:7) MOVQ (TLS), CX
0x0009 00009 (main.go:7) CMPQ SP, 16(CX)
0x000d 00013 (main.go:7) JLS 61
0x000f 00015 (main.go:7) SUBQ $40, SP // 分配 40 字节栈空间
0x0013 00019 (main.go:7) MOVQ BP, 32(SP) // 将基址指针存储到栈上
0x0018 00024 (main.go:7) LEAQ 32(SP), BP
0x001d 00029 (main.go:8) MOVQ $66, (SP) // 第一个参数
0x0025 00037 (main.go:8) MOVQ $77, 8(SP) // 第二个参数
0x002e 00046 (main.go:8) PCDATA $0, $0
0x002e 00046 (main.go:8) CALL "".myFunction(SB)
0x0033 00051 (main.go:9) MOVQ 32(SP), BP
0x0038 00056 (main.go:9) ADDQ $40, SP
0x003c 00060 (main.go:9) RET
GOOS=linux GOARCH=amd64 go tool compile -S -N -l main.gomainmainmyFunction
golang-function-call-stack-before-calling
mainSUBQ $40, SPmainmyFunctionCALL "".myFunction(SB)mainmyFunction"".myFunction STEXT nosplit size=49 args=0x20 locals=0x0
0x0000 00000 (main.go:3) TEXT "".myFunction(SB), NOSPLIT, $0-32
0x0000 00000 (main.go:3) MOVQ $0, "".~r2+24(SP) // 初始化第一个返回值
0x0009 00009 (main.go:3) MOVQ $0, "".~r3+32(SP) // 初始化第二个返回值
0x0012 00018 (main.go:4) MOVQ "".a+8(SP), AX // AX = 66
0x0017 00023 (main.go:4) ADDQ "".b+16(SP), AX // AX = AX + 77 = 143
0x001c 00028 (main.go:4) MOVQ AX, "".~r2+24(SP) // (24)SP = AX = 143
0x0021 00033 (main.go:4) MOVQ "".a+8(SP), AX // AX = 66
0x0026 00038 (main.go:4) SUBQ "".b+16(SP), AX // AX = AX - 77 = -11
0x002b 00043 (main.go:4) MOVQ AX, "".~r3+32(SP) // (32)SP = AX = -11
0x0030 00048 (main.go:4) RET
mainintmyFunction
golang-function-call-stack-before-return
myFunctionmain 0x0033 00051 (main.go:9) MOVQ 32(SP), BP
0x0038 00056 (main.go:9) ADDQ $40, SP
0x003c 00060 (main.go:9) RET
通过对 Golang 伪汇编语言语言的分析,我们发现 Go 语言传递和接受参数使用的都是栈,它没有像 C 语言一样在函数参数较少时使用寄存器传递参数,同时使用栈代替 eax 寄存器传递返回值也能够同时返回多个结果,但是需要注意的是,函数入参和出参的内存空间都需要调用方在栈上进行分配,这种使用栈进行参数传递的方式虽然跟使用寄存器相比在性能上会有一些损失,但是也能够带来其他的好处:
能够降低实现的复杂度;
不需要考虑超过寄存器个数的参数应该如何传递;
更方便的兼容不同的硬件;
不同 CPU 的寄存器差别比较大;
函数可以具有多个返回值;
栈上的内存地址与相比寄存器的个数是无限的;
使用寄存器支持多个返回值也会非常困难,超出寄存器个数的返回值也需要使用栈来传递;
参数传递
除了函数的调用惯例之外,函数的参数在调用时究竟是传值还是传引用也是一个非常有趣的问题,很多人都会说无论是传值还是传引用本质上都是对值的传递,这种论调其实并没有什么意义,我们其实需要知道对函数中参数的修改会不会影响调用方栈上的内容。
不同语言对于参数传递的方式可能设计有所不同,Java 在传递基本类型时会对字面量进行拷贝,不过传递对象参数时就是对象在堆中的地址,相比于 Java 这种稍显复杂的设计,Golang 的设计就简单了很多,无论是传递基本类型、结构体还是指针,都会对传递的参数进行拷贝,这一节剩下的内容就会帮助验证这个结论的正确性。
整型和数组
myFunctioniarrfunc myFunction(i int, arr []int) {
fmt.Printf("in my_funciton - i=%p arr=%p\n", &i, &arr)
}
func main() {
i := 30
arr := []int{66, 77}
fmt.Printf("before calling - i=%p arr=%p\n", &i, &arr)
myFunction(i, arr)
fmt.Printf("after calling - i=%p arr=%p\n", &i, &arr)
}
$ go run main.go
before calling - i=0xc000018178 arr=0xc00000a0a0
in my_funciton - i=0xc000018190 arr=0xc00000a0c0
after calling - i=0xc000018178 arr=0xc00000a0a0
mainmyFunctionmyFunctionmyFunctionfunc myFunction(i int, arr []int) {
i = 29
arr = append(arr, 88)
fmt.Printf("in my_funciton - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
func main() {
i := 30
arr := []int{66, 77}
fmt.Printf("before calling - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
myFunction(i, arr)
fmt.Printf("after calling - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
$ go run main.go
before calling - i=(30, 0xc000018178) arr=([66 77], 0xc00000a0a0)
in my_funciton - i=(29, 0xc0000181a8) arr=([66 77 88], 0xc00000a0e0)
after calling - i=(30, 0xc000018178) arr=([66 77], 0xc00000a0a0)
myFunction结构体和指针
MyStructmyFunctiontype MyStruct struct {
i int
}
func myFunction(a MyStruct, b *MyStruct) {
a.i = 31
b.i = 41
fmt.Printf("in my_function - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
}
func main() {
a := MyStruct{i: 30}
b := &MyStruct{i: 40}
fmt.Printf("before calling - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
myFunction(a, b)
fmt.Printf("after calling - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
}
$ go run main.go
before calling - a=({30}, 0xc000018178) b=(&{40}, 0xc00000c028)
in my_function - a=({31}, 0xc000018198) b=(&{41}, 0xc00000c038)
after calling - a=({30}, 0xc000018178) b=(&{41}, 0xc00000c028)
b.i(*b).ibpackage main
import "unsafe"
import "fmt"
type MyStruct struct {
i int
j int
}
func myFunction(ms *MyStruct) {
ptr := unsafe.Pointer(ms)
for i := 0; i < 2; i++ {
c := (*int)(unsafe.Pointer((uintptr(ptr) + uintptr(8*i))))
*c += i + 1
fmt.Printf("[%p] %d\n", c, *c)
}
}
func main() {
a := &MyStruct{i: 40, j: 50}
myFunction(a)
fmt.Printf("[%p] %v\n", a, a)
}
$ go run main.go
[0xc000018180] 41
[0xc000018188] 52
[0xc000018180] &{41 52}
MyStructintiintjmyFuncionMyStructtype MyStruct struct {
i int
j int
}
func myFunction(ms *MyStruct) *MyStruct {
return ms
}
// assembly
"".myFunction STEXT nosplit size=20 args=0x10 locals=0x0
0x0000 00000 (main.go:8) TEXT "".myFunction(SB), NOSPLIT, $0-16
0x0000 00000 (main.go:8) FUNCDATA $0, gclocals·aef1f7ba6e2630c93a51843d99f5a28a(SB)
0x0000 00000 (main.go:8) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:8) MOVQ $0, "".~r1+16(SP) // 初始化返回值
0x0009 00009 (main.go:9) MOVQ "".ms+8(SP), AX // 复制引用
0x000e 00014 (main.go:9) MOVQ AX, "".~r1+16(SP) // 返回引用
0x0013 00019 (main.go:9) RET
MOVQ "".ms+8(SP), AX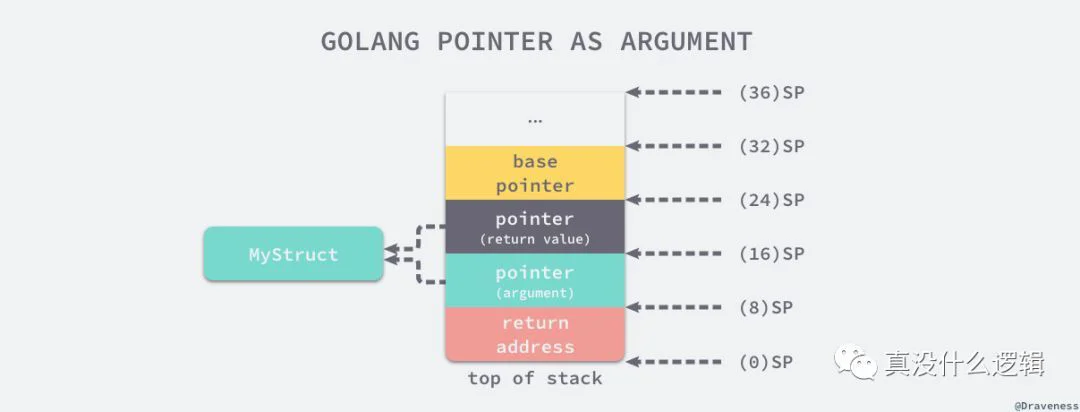
golang-pointer-as-argument
所以其实将指针作为参数传入某一个函数时,其实在函数内部会对指针进行复制,也就是会同时出现两个指针指向原有的内存空间,所以 Go 语言中『传指针』其实也是传值。
小结
当我们对 Go 语言中大多数常见的数据结构进行验证之后,其实就能够推测出 Go 语言在传递参数时其实使用的就是传值的方式,接收方收到参数时会对这些参数进行复制;了解到这一点之后,在传递数组或者内存占用非常大的结构体时,我们在一些函数中应该尽量使用指针作为参数类型来避免发生大量数据的拷贝而影响性能。
总结
这一节我们详细介绍了 Go 语言中方法调用时的调用惯例,包括参数传递的过程和原理,简单梳理一下方法调用的过程:Go 通过堆栈的方式对函数的参数和返回值进行传递和接受,在调用函数之前会在栈上为返回值分配合适的内存空间,随后按照入参从右到左按顺序压栈,被调用方接受参数时会对参数进行拷贝后再进行计算,返回值最终会被放置到调用者预留好的栈空间上,Go 语言函数调用的原理可以总结成以下的几条规则:
通过堆栈传递参数,入栈的顺序是从右到左;
函数返回值通过堆栈传递并由调用者预先分配内存空间;
调用函数时都是传值,接收方会对入参进行复制再计算;