
1.使用goquery爬取初始静态HTML文件中的元素
在用golang编写爬虫的过程中,goquery提供了非常方便的对于静态html页面元素提前的接口.
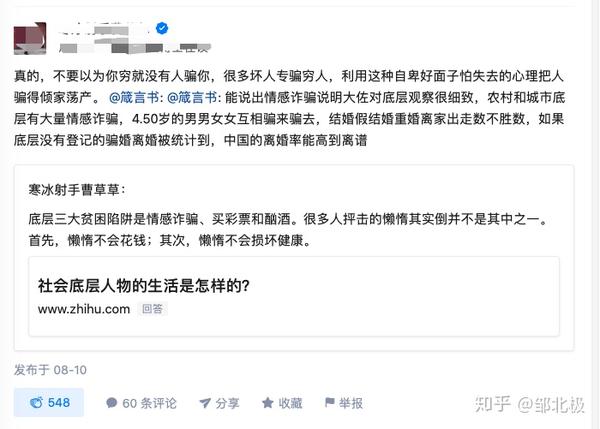
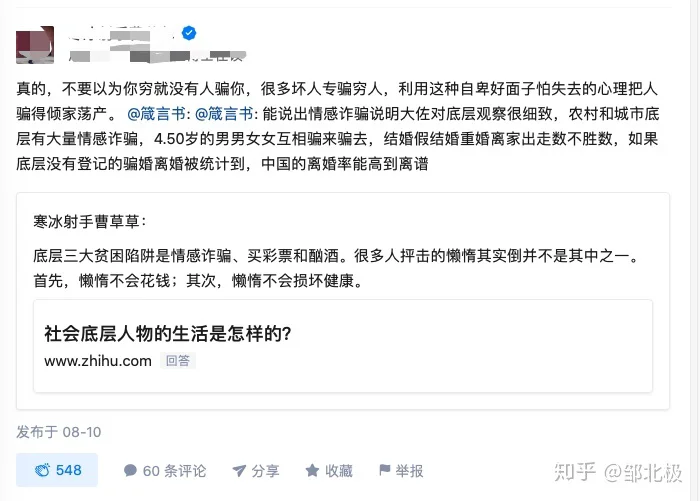
比如这种直接出现在出现在静态hmtl文件中的元素,就可以直接爬取
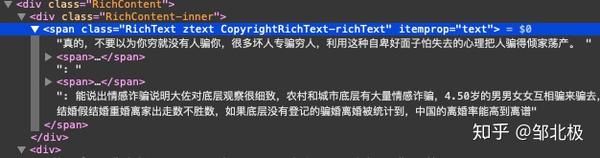
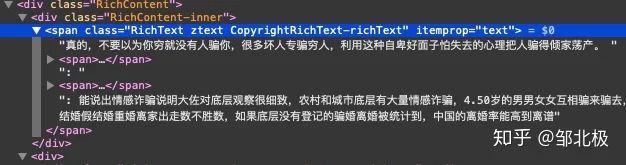
goquery支持这种Xpath风格的查询,在找到对应的节点后可以直接获取其中的属性值.
但是很快我又发现了问题,就是在一个页面中他的想法在元素审查这个界面有10个,但是在静态html文件中只有2个,也就是说审查元素和我们http请求获得的源码不一致.
所谓查看网页源代码,就是别人服务器发送到浏览器的原封不动的代码。这是爬虫获得的代码.
你那些在源码中找不到的代码(元素),那是在浏览器执行js动态生成的,这些能在审查元素中看到.
通过审查元素就看到就是浏览器处理过的最终的html代码。
在这里可行的解决方案之一就是采集在浏览器中最终生成的元素,这时就需要借助我们的第二个工具--chromedp.
2. 使用chromedp获取网页执行动态js后的代码(即审查元素)
chromedp 本质上就是一个浏览器调度包,它与Selenium非常类似,但是使用起来更加方便,更易拓展,而且对golang更加友好
使用chromedp(当然,你必须安装了chrome浏览器),我们可以将需要浏览的网站的url传入,然后等待网页把全部的动态js执行完毕,生成最后的html文件,这时再获取其中的元素,便可以读取所有的元素.
chromedp的使用过程会大量牵涉到golang 中context包的应用, 想要深入理解的小伙伴可以去系统的学习一下这个包的使用.
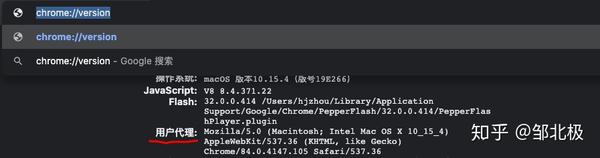
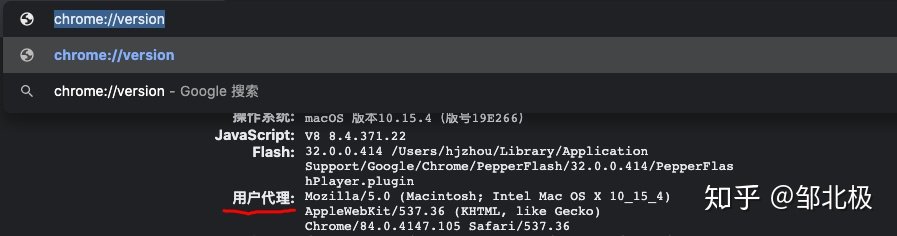
代码中的Useragent可以在浏览器中输入chrome://version获取
随后依然使用goquery来读取这些你想要的元素,这里要注意把获得的html文件(原string类型)转化为 Reader类型.
至此,想法的爬取已经结束.
3. 拓展chromedp函数爬取想法下面的热评
获取了所有的想法之后,接下来需要获取的就是想法下面的热评了.
问题不大,只需要点击一个按钮之后他就可以出现,在chromedp.run的条件里面加点击语句就和等待语句可以了
但是这里出现了问题,一个网页page有多个想法,每个想法又有自己的评论,也就是说每个想法的评论按钮都需要点击,这是一个批量的操作,这时chromedp自身所提供的函数Click()已经无法满足需求了,也就是说需要自己造轮子.
在这里我直接把函数贴出来,其实非常简单,拥有些许编程功力的人在阅读了源码中的Click()函数应该都可以完成.只是有几点需要注意一下
- 迭代变量 i 每次的自增是2, 这个具体原因我也说不清楚,似乎是因为chromedp中的Query每次寻找某一元素都会产生两个结果,所以我们要每次都跳过一个伴随生成的元素.
- MouseClickNode()函数会自动将页面滚动到要点击的地方,如果需要点击处不在当前页面中的话. 而后台程序移动页面的速度非常的均匀和迅速,会导致阿乎的监控程序监测出非人为操作,从而弹出登录窗口.类似下图.
我原本想做一个模拟登录的过程,但是奈何阿乎的验证码系统有点难搞,所以我选择了最简单最暴力的方法,等待这个登录窗口出现之后,直接关闭这个登录窗口,即上述代码的1、2处.
最后,在chromedp.run下面加入相应的action即可
至此,大功告成.