
Go基础
1、panic与defer
defer会采用头插形成一个链表,从而达成类似于栈的执行效果,即越后面的defer越先执行
panic则是尾插,达成类似于链表的执行效果,即按先来先执行的逻辑来执行panic
程序如果正常执行失败,触发panic语句,panic执行时会执行defer语句,此时defer对应的结构体内会标记这个panic,防止defer执行时遇到panic导致再次执行自己,导致死循环。
同时,需要注意,defer是在return之前执行的,具体的过程是先给返回值赋值,然后执行defer,最后函数返回,所以defer可能会更改返回值。
eg:
func f() (result int) {
//return语句不是一条原子调用,return xxx其实是赋值+ret指令
defer func() { //defer被插入到return之前执行,也就是赋返回值和ret指令之间
result++
}()
return 0
}
//相当于 result = 0;result++;ret,因为result是提前定义好的返回值,类似于作为一个参数传入,
//所以会更改返回值,结果是1
func f() (r int) {
t := 5
defer func() { //defer被插入到赋值与返回之间执行,这个例子中返回值r没被修改过
t = t + 5
}
return t //空的return指令
}
//这个defer就不会更改返回值,返回值是提前定义好的r,所以返回的地方类似于:
// t := 5;r = t;t=t+5;return,defer部分的逻辑只改动了局部变量t的值,没有改动返回值r的
2、string
go中string包含两部分,一个为指向[]byte的指针,一个为该字符串的字节长度。而且go的string也是final不变的,每次对string的改动并不会更改原字符串,而是会创建新的字符串。
3、slice
slice是一个结构体,包含3部分,指向数组第一个元素位置的指针(未分配数据时为nil )、切片的目前的长度(len)、切片的总容量(cap)。其中,长度是下标操作的上界。
往切片中append元素,会造成切片自动扩容,若当前切片大小小于1024,按2倍扩容,大于1024,按当前的1/4扩容,若添加元素的数目使得新的切片大小是原大小的两倍以上,则直接扩容至新大小
而且往切片中添加元素时,若切片当前的大小len < 容量cap,那么指向数组的指针是不变的,此时往切片中添加元素,会造成数组中元素的变动。当添加元素使得len > cap 时,go会复制数组,并扩容然后重新赋给切片的指针。
获取slice数据的内存地址:
s := make([]byte, 1024)
ptr := unsafe.Pointer(&s[0])
将一块内存地址转换为[]byte:
var ptr unsafe.Pointer
s := ((*[1<<10]byte)(ptr))[:200]
//或者也可以使用reflect.SliceHeader
4、map
map为一个指针,指向一个hmap结构体,其中包含一个*Bucket数组,用于指向存储元素的Bucket。
map每次扩容如果是因为负载而扩容(即溢出桶没使用超标,但是Bucket用的较多),那么会增大为原来的2倍。如果负载因子没有超过阈值,但是溢出桶使用过多,那么会触发等量扩容。当桶的数目小于2^15的时候,此时溢出桶数目超过常规桶,那么就算溢出桶超标,当常规桶大于2 ^15,那么溢出桶大于该值就算超标。
等量扩容常规桶的数量不变,那么有什么作用呢?
首先,溢出桶使用过多的情况在于大量的kv被删除,但是新加入的元素会加入溢出桶,而不会覆盖空闲的空间。扩容会导致所有元素重新分配,会使得溢出桶中的元素分配到常规桶中,使得空间利用更加紧凑。
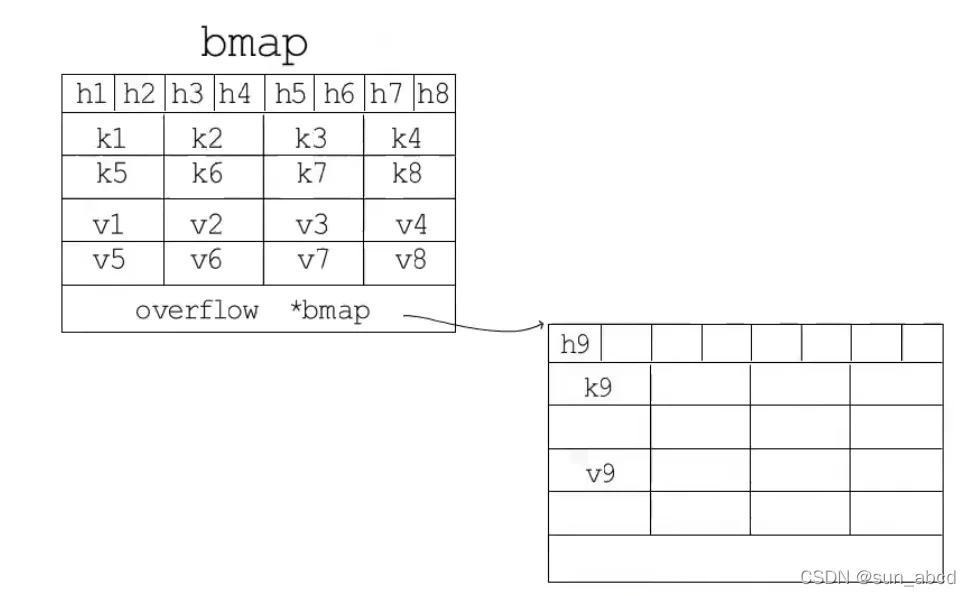
Bucket也是一个结构体,包含一个uint8的数组,存储hash值的高8位,该数组可以存储8个元素,所以每个Bucket可以存有8个KV键值对。一个指向下Bucket的指针,用于存储溢出8个的元素,两个byte数组存储数据,其中 key 存储在一个数组中,value存储在另一个数组中,依靠index来一一对应。
Bucket的结构如下图:
5、make & new
- make:用法 make(T,args),返回一个T
- new:用法 new(T),返回一个*T
6、nil
go语言中如果只声明某些类型的变量,却不赋值或者初始化,那么该变量为nil。包括:指针、函数、借口、slice、channel、map
7、go关键字
go关键字可以开启一个协程,底层使用的是runtime.newproc(size,f,args),size为参数占用的空间大小,f 为要调用的函数,args为 f 的参数。
每次协程获得cpu进行执行的时候会先进行检测,查看当前栈的大小是否足够,如果不足,则会暂停执行,通过go的运行时库获取一个新的足够大的栈空间,将旧的内容拷贝到新栈中,然后恢复函数执行。栈的收缩则是在垃圾回收的过程中实现的,当检测到栈只使用了1/4不到时,栈缩小为原来的1/2.
8、闭包
闭包是由函数及其相关环境组合而成的实体,即:闭包 = 函数 + 环境
闭包底层实现为一个结构体,该结构体包含函数f和对应的环境中的变量,每次调用函数传入的是该环境中的变量。
9、interface
interface底层实现是一个结构体,包含两个成员,其中一个指向具体数据的指针,另一个包含类型信息。
空接口对应的结构体是Eface
带方法的接口对应的结构体是Iface
10、channel
Go程序的执行流程
Go程序调度
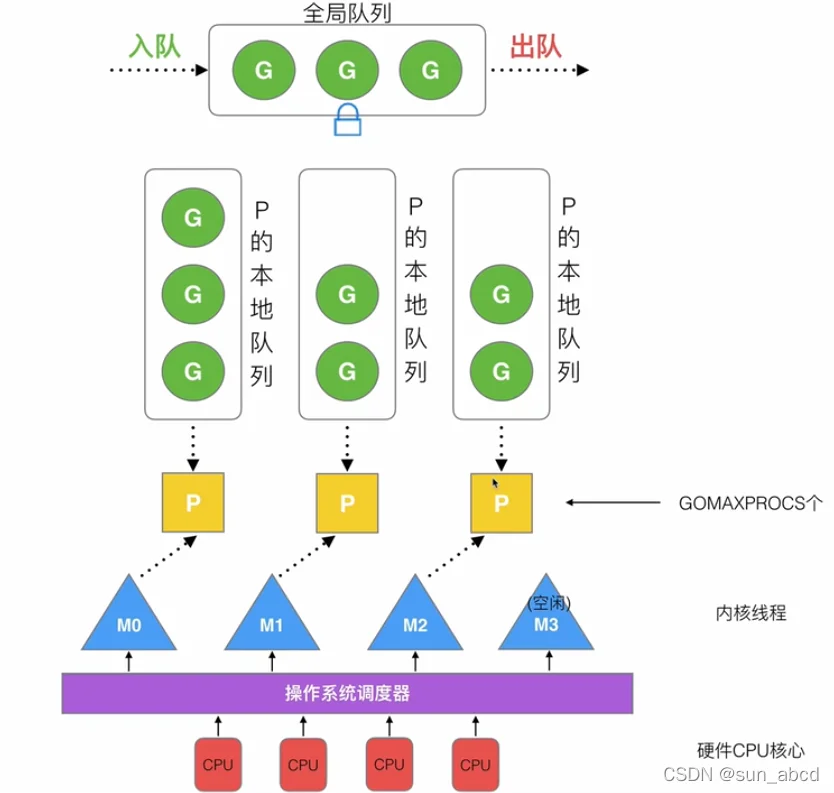
- G:每个G表示一个goroutine
- M:表示一个OS管理的线程,M结构体中包含多个指向G的指针,其中curg表示当前正在运行的G;g0表示具有调度栈的G,普通的goroutine使用堆上内存作为自己的栈,g0则是使用M所表示的物理现线程的栈;lockedg是在某些情况,将G锁定在M内部,让其不会切换到其他M中。
- P:表示Go代码执行所需要的资源,持有一个G的本地队列,但最多只能存放256个G,新创建G会优先放入P的本地队列,如果本地队列已满,则放入全局队列
- 全局队列:存放等待执行的G,空闲的M绑定的P的本地队列没有待执行的G的时候,会先从全局队列中取(需要加锁),如果全局队列为空,则从其他的P的本地队列中偷取G。
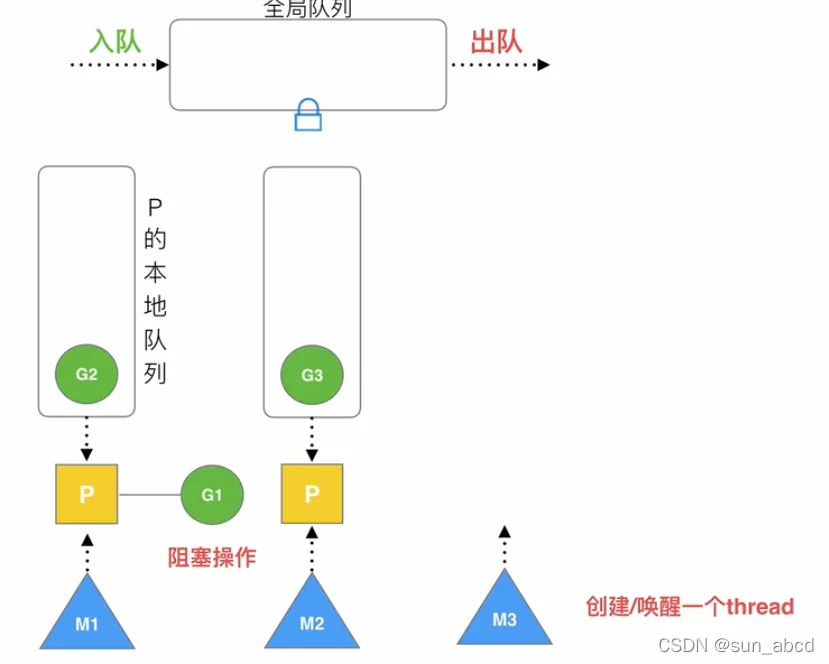
当一个M执行G的时候进行系统调用阻塞时,会创建一个新的M或者从M队列中唤醒一个沉睡的M接管阻塞M的P,然后去执行下一个G,将阻塞的M和G绑定等待,如下图:
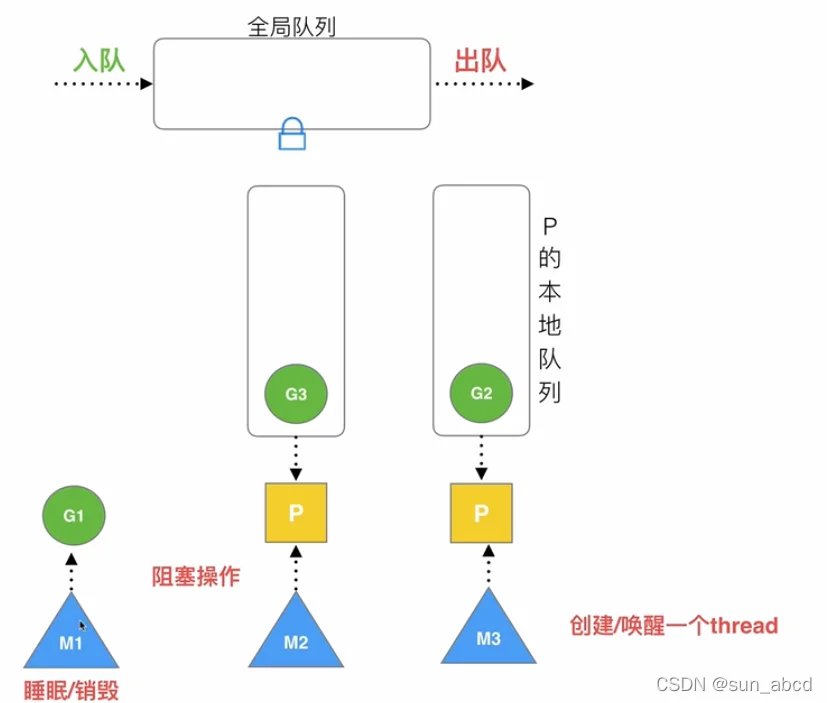
M1进入阻塞后,唤醒M3,将P和M3绑定,执行G2:
M0 & G0
M0是启动程序后的主线程,负责执行初始化操作和启动第一个G,之后和其他M一样。
每个M都持有一个G0,仅负责调度,也不使用堆来分配栈空间,而是使用执行G0的M的物理线程的栈空间。在进行G调度的时候,M先执行G0的逻辑,由G0选择一个G进行执行。
创建协程的过程
协程的生命周期
Tips
- M应该表示为内核级线程,即由OS调度管理的线程,而不是内核线程,内核线程是指那些只运行在内核态的线程。同理,用户线程是指运行在用户态的线程,但如果是通过系统调用创建的,那也同时属于内核级线程。
- 用户级线程则是不通过OS来调度管理的,比如go里的G,它就属于用户级线程
- 一个G创建另一个G的时候,新创建的G优先放入当前P的本地队列中
序列化问题
todo
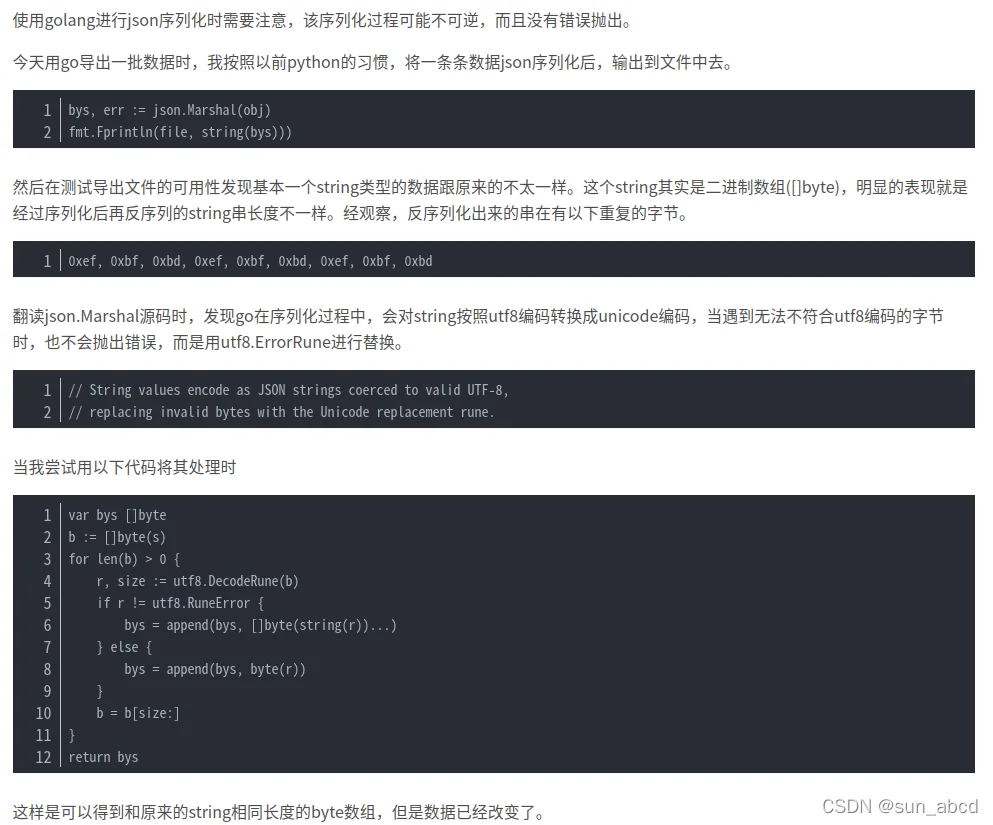
go的string强转[]byte会发生什么?为什么两者的二进制不同?
示例代码:
func main() {
//UTSTest()
aa := "hello"
for i := range aa {
fmt.Printf("%b", i)
println()
}
println()
//hello的byte数组
a := []byte(aa)
fmt.Printf("%v", a)
println()
b := string(a)
println(b)
//序列化hello
marshal, _ := json.Marshal(aa)
var c string
err := json.Unmarshal(marshal, &c)
if err != nil {
return
}
println(c)
//序列化 hello byte数组
bytes, _ := json.Marshal(a)
var d string
err = json.Unmarshal(bytes, &d)
if err != nil {
return
}
println(d)
}
输出:
0
1
10
11
100
[104 101 108 108 111]
hello
hello
aGVsbG8=