
根据多次面试经历,总结下golang开发需要掌握的知识点
1.slice和数组的区别
slice是数组的快照,slice底层数据是一个结构体,包含三个元素,长度、容量和数组指针。所以slice的赋值就如同结构体的赋值一样,slice的应用其实都是对数组指针的操作。注意点:对slice的操作会影响到所有引用到底层数组的slice。
在这个例子中在函数中切片的更改会影响到函数外的切片,数组不会。
2.slice扩容
- 如果切片的容量小于1024个元素,那么扩容的时候slice的cap就翻番,乘以2;一旦元素个数超过1024个元素,增长因子就变成1.25,即每次增加原来容量的四分之一。
- 如果扩容之后,还没有触及原数组的容量,那么,切片中的指针指向的位置,就还是原数组,如果扩容之后,超过了原数组的容量,那么,Go就会开辟一块新的内存,把原来的值拷贝过来,这种情况丝毫不会影响到原数组。
3.append方法
在slice末尾添加元素,且长度加1,如果长度没有超过原数组的容量,则返回的还是指向原数组的slice,否则就是指向新数组的slice。
4.defer的实现原理
简述下defer实现原理,G1.13及以前都通过编译器将defer转化成汇编语言的函数调用,将方法名及参数入栈(其实是个链表),每有一个defer都会在头部插入链表结构体,结构里存有方法名和入参参数,如果不是defer后面是个表达式或者其他,编译器也是把它变成一个函数。多个defer的执行是跟defer所在位置正好相反的,越靠前越后面执行,在函数return的时候,编译器在return的汇编语言中插入代码,做如下操作。
1.保存返回值
2.将defer的栈链表取出,出栈执行defer方法。
3.将返回值返回。
这道的输出非常有意思,首先DeferFunc1的返回是t,return的时候先保存t,然后执行deferfunc(){ t +=3}(),t的值为i,i为1,t最后是4,最后将返回值t返回,输出4。
DeferFunc2的返回值式匿名的,所以return的时候保存匿名变量,值为t,也就是1,然后执行函数,t为4,返回匿名变量值为1,输出1。
DeferFunc3同样保存t,值为2,执行defer函数后,t的值为3,返回t,输出3。
值得一提的是Go1.14对defer进行了优化,defer不再编译成入栈操作的函数,而是直接整块移动到return操作的第二步,执行defer方法。这一编译器的实现大大提高了defer执行效率。
局限性在于defer操作是可以在编译时预知一定会执行的话,才会被优化,将defer操作放到if和for下,只有执行时才知道defer会不会执行的话,就不会优化。
golang defer原理
go1.14实现defer性能大幅度提升原理
5.简述map的结构
map是由桶数组组成,map会把key通过hash得到的字符串分成两部分,一部分第八位作为数组的下标,一部分作为桶内高八位hash数组的值 ,桶外通过数组映射,桶内通过遍历数组元素总数为8的hash数组。map除此之外还有B扩容次数,溢出桶、及哈希种子等比较重要的结构。
6.为什么桶内的元素要用遍历而不用映射呢?
在数量较小的情况下,遍历的效率比映射快,所以go的map采用了这个设计。
7.map如果遇到hash冲突,怎么处理?
map查找元素,除了要匹配桶中高八位hash外,还会通过指针位移找到存储的原始key,如果再次匹配key才会取value,当hash冲突,桶内还有位置,只会把冲突hash放到空位上,虽然桶内有两个一模一样的hash,但因为要进行key的比较才会取value,所以不会有任何问题。当桶内位置不够时,会再取一个溢出桶,放到当前桶的后面,就像链表的结构。遍历完当前桶,再遍历溢出桶。
补充一下新内容:
8.channel有什么比较重要的结构?
channel有一块缓存环状线性链表,锁,容量,进出的索引值和阻塞的协程列表(分为取或塞的两种协程列表)。chan操作环状线性链表都需加锁,chan通过索引值判断能取或者塞是否能进行,当不能取或塞时,就用阻塞的协程列表保存当前协程。比如当chan中没有可取的元素时,执行取操作,会阻塞当前协程,将协程加入到chan的取阻塞协程列表。当有一个协程执行塞的操作,chan会从取阻塞列表中取一个协程,将其放入就绪协程队列,以此来唤醒协程。
channel重要的是阻塞协程列表和索引,用于在常数时间内实现chan的取和塞的操作。一索引,chan缓存是一个线性结构,通过索引*每个元素大小就能在缓存中找到对应的取塞位置。二通过存储阻塞协程,能迅速唤醒协程。
9.select如何实现?
select本质上通过数组实现,数组中存储case结构,有chan、操行的类型kind和接受结构体elem。首先select数组随机打乱顺序,然后,循环取数组中的元素执行操作,如chan1执行取操作,判断chan1是否有元素(通过chan内部字段),如果没有就将当前协程加入到chan1的阻塞列表。循环完成后,当前协程G1挂起。
如上一节chan那样,chan1会在有塞操作的时候,自动将G1送回协程就绪队列,之后协程G1被调度到,又进行一次上面的操作。
go的select的机制就和操作系统层面的select是一模一样的,同样是异步通知,但不知道是哪一个事件已经就绪,需要都遍历一遍。
参考:
10.panic是如何执行的?
1.panic执行时,先取当前协程结构G,G中保存defer列表和panic列表,循环执行defer列表的函数,这意味着所有和协程有关的defer都会执行,包括调用链上层函数的defer,全部defer执行完后,打印调用栈结束程序。
2.需要注意只有在panic函数之前调用的defer才会被执行,且必须是同一个协程。因此需要被回收的资源,在创建成功之后,立马执行defer释放函数,确保万无一失。
3.使用recover函数恢复时,recover会恢复程序,但程序运行时,不会执行出错程序的下一行,而是回到recover函数所在函数的上一级函数。记住defer的函数总在当前函数返回时执行,如果函数中途panic,然后recover恢复,返回值是返回类型的零值。
函数输出是
cccc
qqqqq
ssss
cccc
qqqqq
ssss
cccc
qqqqq
.......
dddd是不会被执行,recover后,a被赋予int的零值0,之后执行下一行if a==0.
11.unsafe.Pointer 和 uintptr关系及应用
1.这两个类型可以相互转化。unsafe.Pointer 可以被转化成任何指针类型,但不能运算。uintptr可以进行运算,不能转化成除unsafe.Pointer外的其他指针类型。
2.大量应用在chan、map等底层结构。使用reflect,性能较差,可以使用指针运算直接操作内存的方法优化。
有不对的地方,希望大家能指出
12.关于go的安全并发和锁的实现
1.go的锁的实现一定会涉及到go的GMP调度,但我不打算讲细节,我会先简单将协程并发和阻塞的情况做一个总结。
2.channel、select、time、网络io、sync.Mutex、sync.Waitgroup、atomic等情况。按实现方式分,其中channel、select归为一类,time和网络io一类,sync.Mutex、sync.Waitgroup和rwmutex等一类,atomic一类。
3.channel、select的实现,如上所述,chan保存取和塞阻塞协程队列,当chan执行取和塞的时候,唤醒阻塞协程重新执行会阻塞的步骤。
4.time、网络io,底层都是使用netepoll网络轮训器来实现,在linux上是使用操作系统的epoll函数,这个函数就是多路复用。go进程在启动时,会单独起一个线程运行sysmon方法,sysmon每隔段时间调用epollwait方法获取已经准备好的事件,从事件中取出对应的协程并返回。接着在injectglist函数,将返回的协程列表的协程全部变成就绪状态。
参考:
源码:/usr/local/go/src/runtime/proc.go:5143
5.sync.rwmutex,sync.Mutex、sync.Waitgroup都是通过runtime_SemacquireMutex和runtime_Semrelease来实现阻塞协程切换和释放被阻塞协程重新运行等操作。其中锁Mutex的sema变量,这个变量的值不是关键,它的地址一定是唯一的,所以能作为标示这个锁的唯一键。这些源码在/usr/local/go/src/runtime/sema.go:70,go通过全局变量semtable来存储锁对应的阻塞协程,通过锁Mutex结构体的sema的地址hash映射到semtable数组,数组的元素是一颗平衡二叉搜索树,通过sema地址大小排序。树中每个节点是sudog结构,sudog结构通过waitlink存储了一个协程列表。因此mutex加锁阻塞时,在semtable和底下树中找到对应的位置,并将当前协程结构改变成阻塞状态,加入到waitlink中,解锁时,从waitlink取出一个解锁。同样Waitgroup也有一个state1变量,state1[2]就是same变量,通过相同的机制实现加锁解锁。不同的在于Mutex有饥饿状态,一旦锁出现饥饿状态,解锁的协程会让出调度给等待锁的协程。
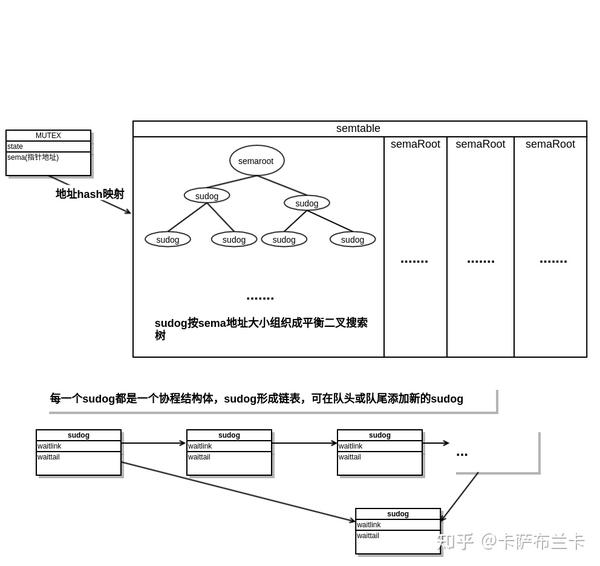
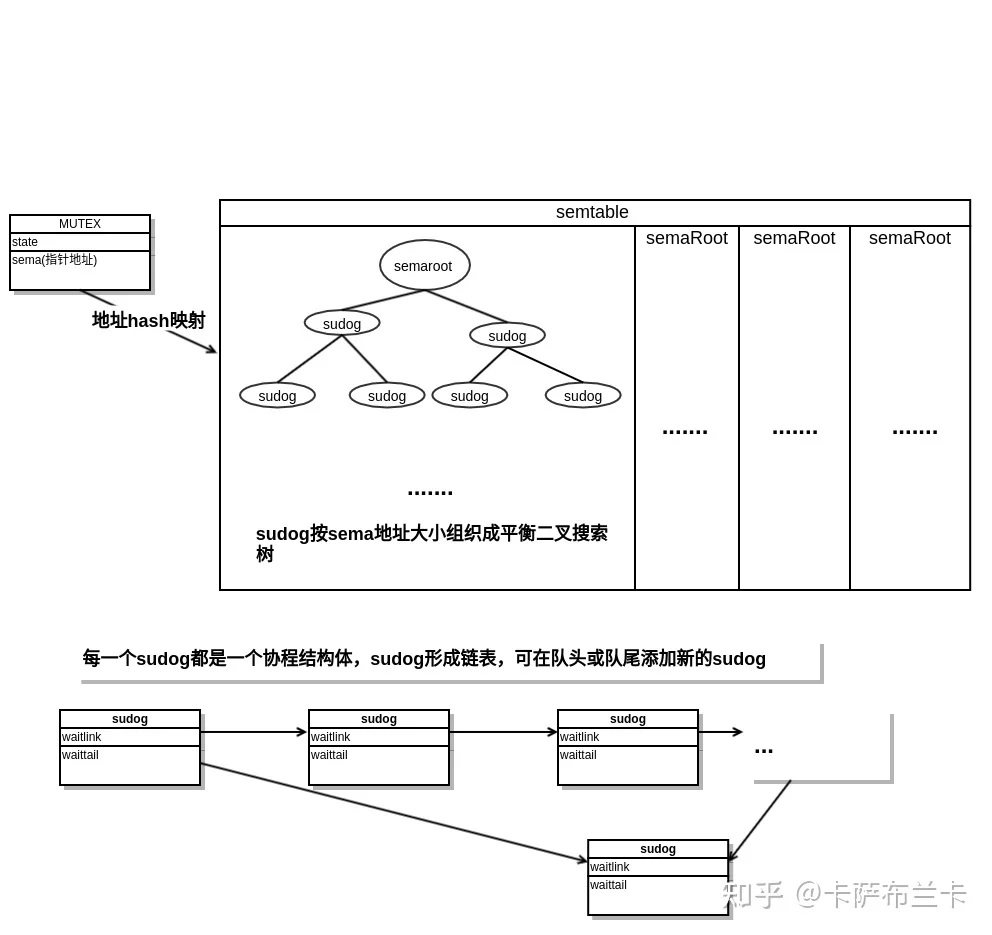
参考:
6.semtable会被多个协程操作,有并发问题,但这个是底层数据结构,Mutex依赖于它,semtable是如何保证并发安全的呢?这块涉及到真正的底层锁mutex,只在go源码使用,这个锁在不同场景有不同的实现。其中一种实现先用自旋和原子操作加锁,失败后原子操作和让出调度,如果再失败使用futexsleep来加锁,会一直等待释放锁的时候才恢复调度。futex是操作系统层面共享内存的用户内核混合模式,使用futex变量用来表示是否有线程在操作这个临界区,先在用户态用原子操作将锁状态更改成占有,失败则陷入内核态休眠,等待锁释放,唤起线程,具体实现请看:
自旋或自旋锁,指的是cpu的pause指令,其实就是什么事都不做,等待几个周期。
代码:
/usr/local/go/src/runtime/sema.go:132 lockWithRank函数
/usr/local/go/src/runtime/lock_futex.go:50
7.atomic包,真正的底层并发实现,实际上是执行cpu的原子指令,最高效的修改共享数据的方式。
13.浅聊锁的实现
1.以独占锁为例,当有多个线程抢锁,只有一个抢到,其他线程有两种选择。一、futex模式陷入内核态休眠,等待锁的释放再唤起,二、自旋重试。两种方案各有优缺点,自旋重试,如果长期取不到锁,会使cpu空转,但如果锁很快释放,则优于futex,futex陷入内核态很耗时。协程提供了第三种的方案,保存协程队列,实现协程的切换,比陷入内核态消耗更小,也不会使cpu长期空转。
2.锁的粒度,锁的粒度越小,冲突的可能越小。go的sync.map只有一把锁,而java的concurrentMap是数组+链表,每个数组元素一把锁,所以sync.map在高并发性能不佳。可以用[]map来取代sync.map,将所有key hash到对应map,每个map一把锁,减少锁的粒度。
3.其他考量,锁的公平问题,一个线程等待时间长,但一直拿不到锁,总被新来的线程抢锁。换句话说,如果有人插队,你是不是想打他。解决此类问题,go实现的锁有等待协程队列,按等待时间排序,很好解决这类问题,futex机制也能同样解决问题。
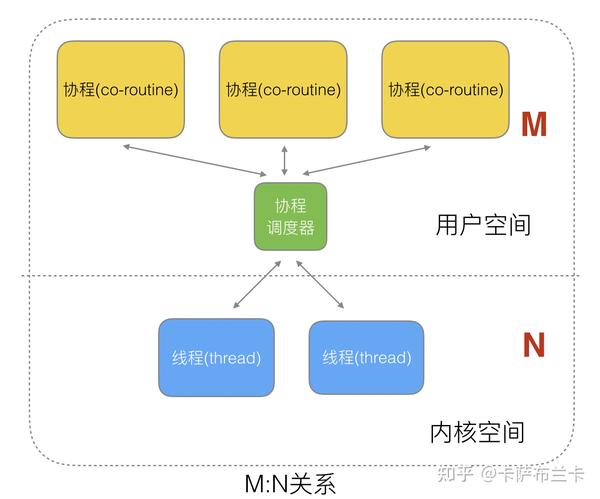
14.GMP模型和进程、线程之间的关系
1.进程和线程在操作系统层面是同样的调度单位,线程只是概念与进程不同,其实就是父进程fork出来的子进程,只是父子进程共享同样的内存空间,包括堆,全局变量常量,代码区等等。由同一个进程通过共享内存空间fork出来的进程称为同一进程下的线程,父进程被称为主线程。这样fork的好处是当线程切换成同一进程的其他线程,是不需要切换页表的。
2.协程是用户定义的调度单位,对操作系统是透明的,协程只有挂载到线程才能执行。协程切换由用户代码自行控制,这部分代码在go中的实现就是GMP模型。
3.在讲解GMP模型前,举下面试官经常提及的问题来加深理解。
1.操作系统的线程有哪几种?
2.如果一个线程被系统OOM了,同一进程的其他线程会这么样?协程被OOM会这么样?
4.问题1:线程分为 内核线程、用户态线程、混合模式线程。内核线程指的是由操作系统创建的线程,由操作系统调度,当线程被调度时,会陷入内核态 ,所以称为内核态线程。用户态线程指是在用户态调度的线程,对操作系统是透明的。混合模式是指内核线程和用户态线程都存在的模式。按照这个定义协程符合用户态线程,GMP模式符合混合模式线程的定义。所以说线程只是个概念,不代表一定是在进程的下一层的实际运行单元,应该是比进程更轻量级的调度单元。这里统一下概念:线程指内核线程,协程指的是用户态线程。用户态和内核态的网上资料很多,这里不再累述。
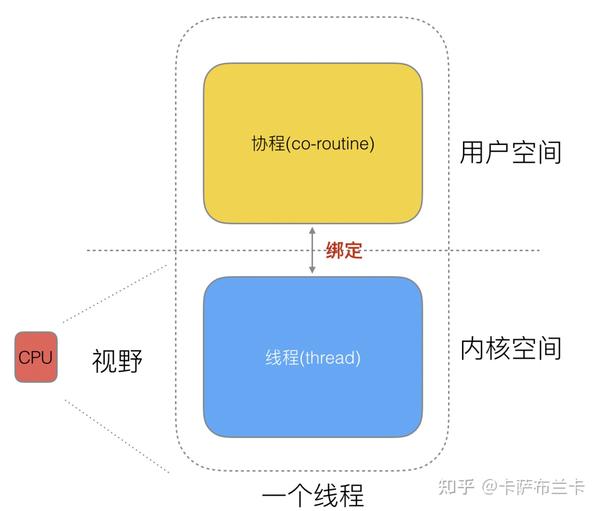
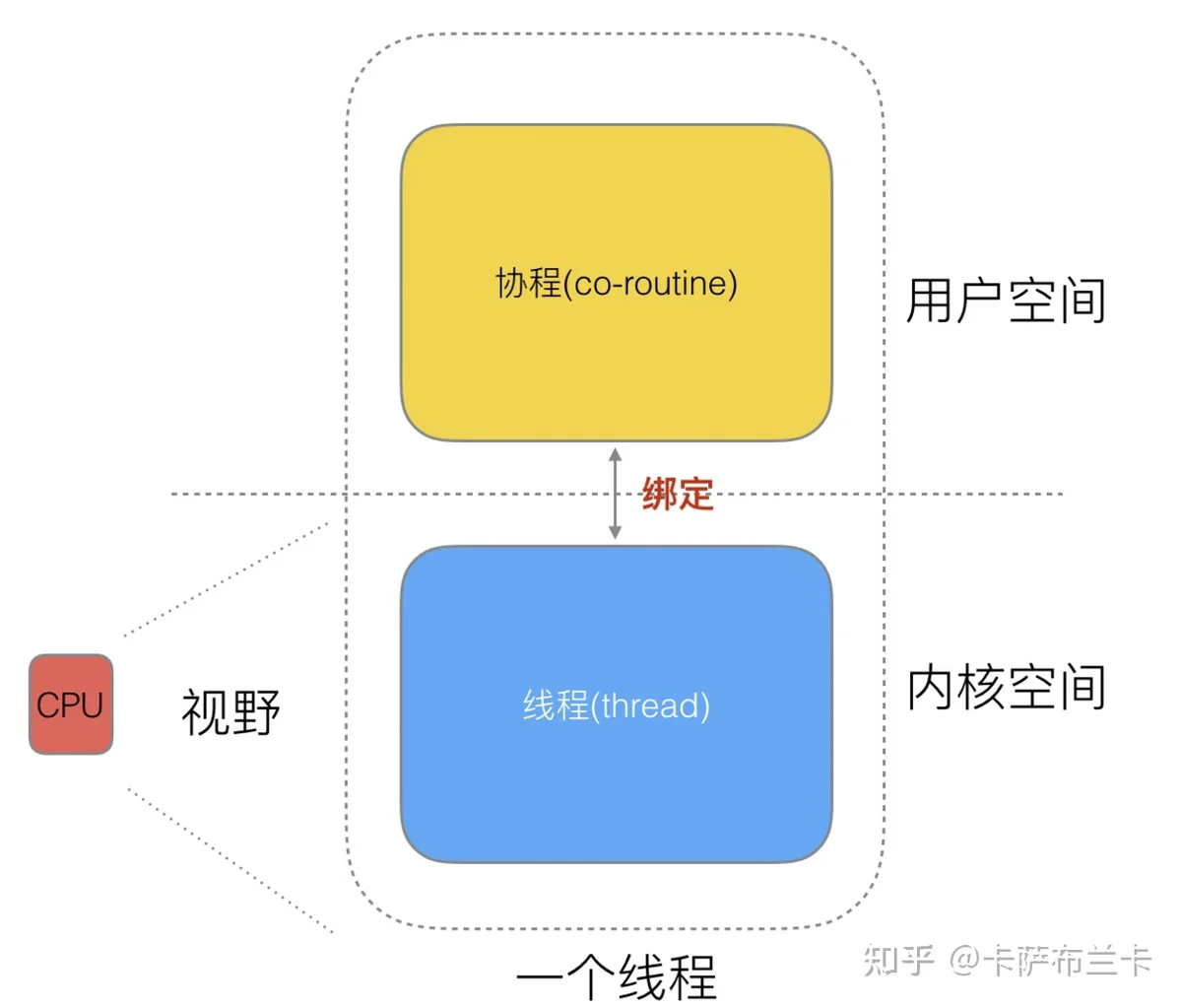
问题2:OOM是out of memory,内存溢出,不管是进程还是线程,操作系统只会把这个进程或线程杀掉,并回收内存空间。所以共享内存空间的其他线程会崩溃,并被回收。协程被OOM这种问法是诳面试者的,对操作系统透明的协程不会被OOM,操作系统只会管线程分配内存是否过多。
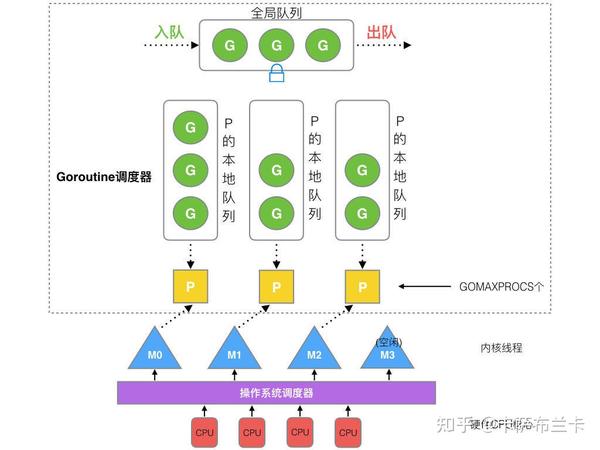
5.重点--GMP模型,G是协程,M是内核线程,P是虚拟CPU,P的数量一般等于CPU核数,也就是能同时并行跑的程序的数量,有些CPU有超线程,P的数量可以是CPU核数的倍数,可通过GOMAXPROCS环境变量设置。GMP同时存在时才会运行代码,P运行代码的主体,M是操作系统最小调度单位,G是代码本身。要运行的代码有很多,G的数量远大于M和P,所以,go实现了协程调度策略。有全局协程列表,刚生成的协程都放在这里。每个P都有一个协程队列,队列容量256,队列会从全局协程列表中获取协程。开始时,P会寻找空闲的M,没有就创建M,并从自身的协程队列中取一个协程执行。
G会在以下情况让出调度:
a.主动让出调度,在go源码上的实现有:chan阻塞、select、mutex、waitgroup.Wait(),runtime.Gosched()等等
b.系统调用,如网络磁盘io,time.Sleep(),内存申请等等
c.检测协程,go会在编译阶段自动在每个函数头部插入一些检测代码,这些代码会检测协程运行时间,如果是 超过一定时间,会执行抢占的逻辑。在go1.14版本后,还有一种信号抢占,这是在执行GC时,会暂停协程的运行,这时进行检测来判断是否抢占。
d.其他情况,如GC 的STW (stop the world)暂停所有协程的执行和协程辅助gc回收。
情况a、c、d在用户态进行切换,保存现场,切换协程的栈及pc寄存器。协程的切换比线程的切换轻量很多,线程因为会在执行到任何指令的时候被切换,所以会保存所有寄存器的值,而协程的切换一定是在go的一行代码所生成的所有指令都执行完后,这就导致协程无需保存浮点数寄存器存储这些临时数据的寄存器。线程的切换一定要先进入内核态,执行操作系统的代码,尽管内核很精简,但也要考虑各种情况,这也导致了进入内核态,相比与协程切换逻辑更复杂更消耗资源。在GMP模型中,这步是M和G解锁,G进入阻塞状态,而M从P里的协程队列取一个协程继续执行。当阻塞的G被唤醒时,G会重新进入全局列表或P的协程列表或重新执行。
情况b会使M陷入内核态,这时P会和M解耦,M和G一起陷入阻塞,P会从新寻找或创建M,并执行剩下G的代码。当系统调用结束后,M和G会解耦,M进入空闲M队列,G进入全局队列。
协程还有一个特点就是栈特别轻量级,开始是2k,扩容x2,最大是1G,相比于线程固定2M(32位)灵活得多。
参考: