
协程
优势:
- 与线程相比更加轻量,约2kb,协程的栈大小可以根据需要扩大缩小,允许创建大量的协程
- 协程是用户空间的,协程切换开销小,不需要用户空间和内核空间的切换
协程调度的时机
- 可能阻塞的系统调用
- time系列的定时操作
- chan读写阻塞的时候
- 垃圾回收之后
- 主动调用runtime.gosched()
slice和map
makemap 和 makeslice 的区别,带来一个不同点:当 map 和 slice 作为函数参数时,在函数参数内部对 map 的操作会影响 map 自身;而对 slice 却不会
主要原因:一个是指针( *hmap),一个是结构体( slice)。Go 语言中的函数传参都是值传递,在函数内部,参数会被 copy 到本地。*hmap指针 copy 完之后,仍然指向同一个 map,因此函数内部对 map 的操作会影响实参。而 slice 被 copy 后,会成为一个新的 slice,对它进行的操作不会影响到实参。
但是操作slice中的数组会影响数据,因为新的slice仍然是指向同个数组
slice和数组
数组是在编译阶段就确定长度的一个容器,如此可以让编译器更好分配合适的空间存储数据,但无法灵活扩容。
切片则是没有提前约定长度的”数组“,它的长度动态可变。切片本质上是一个结构体,由指针、长度和容量构成。
由数组创建的切片指针仍然会指向原数组的对应位置,此时切片和数组对应位置同时变化;而当切片容量不足时会进行复制扩容,之后与原数组就没有关系了。
数组被函数调用是传值,对参数数组的改变不会影响原数组;切片也是值传递,会改变切片中指针指向的数组的值。
slice len3 cap4
s2:= append(slice,2) //slice的底层数组是被改变了的
arr:=[][]{}
arr=append(arr,slice)
s3:=append(slice,3)
arr=append(arr,slice)
slice的底层数组是被改变了的, x,x,x,3
slice扩容
- 扩容需要的数量cap1 大于 2*cap,那么新cap设置为cap1
- 如果需要的容量没有超过2cap,那么判断旧切片长度是否小于1024,小于1024双倍扩容,大于等于1024则每次扩1/4直到超过所需容量
- 内存对齐,按扩容后所需的内存大小 按照span的级别向上取整
- 如果g进入了系统调用状态,那么与其绑定的M也将进入系统调用状态
- M是实际线程的封装,P代表逻辑处理器
- go运行时的调度器将m结构体中的本地线程存储[6]uintptr将操作系统的线程与运行时代表线程的m绑定
struct 比较
相同类型的struct:
含有map、slice,function等不可比较的属性 则 struct不可以比较,==编译通不过
若所有属性都可以比较,那么可以比较
不同类型的struct:
若符合↑,强转后可以比较
reflect.DeepEqual ptr1==ptr2 || 所有的变量相等
defer
延迟执行语句,在所属的函数退出之前,按defer的逆序进行执行
(close关闭一个无缓冲的通道,会让其由阻塞变为不断读出0值的通道?)
context包
谷歌官方开发的,用于对一个请求衍生出来的各个goroutine施加约束。比如context传递给多个goroutine使用时,执行一次cancel就可以取消所有的goroutine。
协程同步
select +chan
waitGroup
context
什么是goroutine chan
goroutine 是 Go语言中的轻量级线程实现,由 Go 运行时(runtime)管理。Go 程序会智能地将 goroutine 中的任务合理地分配给每个 CPU。
goroutine 是 Go语言程序的并发体的话,那么 channels 就是它们之间的通信机制。它可以让一个 goroutine 通过它给另一个 goroutine 发送值信息。
chan:
- 关闭的chan进行写操作会panic,读操作会返回类型零值和false
- 单方向通道不可以隐式转换为普通通道,反之可以
- 通道数据结构hchan是数组和下标指针模拟环形队列、读写等待协程链表
- chan写入:
1、读等待协程链表有协程那么直接获取第一个等待读数据的协程,并把数据复制到那个协程并唤醒他
2、没有等待的读协程,环形缓冲队列还有位置
3、缓冲队列没有位置那么将当前协程加入写等待协程链表
select
- select和switch类似,但是每个case都是一个通道读写
- 多个case的通道准备好数据时,随机选择一个
- 只有一个case的时候,编译器会优化去掉select
- 两轮循环,第一轮循环检查是否有准备好的case,或者default,没有的话第二轮循环创建一个sudog结构体,放入所有case中的读写通道的读写等待协程链表后面,并阻塞当前线程。当任意一个case不再阻塞,唤醒当前协程,并取消当前协程的sudog挂在其他case中的通道的等待链表
race是通过谷歌开发的Threadsantinizer检测的,本来是检测C++的数据争用问题,go中通过GOC调用
自旋锁
获取到锁才操作,没有获取到就一直循环等待锁
mutex互斥锁
结构体 m{state int32 , sema uint32}
高29位是当前互斥锁上等待的goroutine个数
饥饿状态位,唤醒状态位,锁定状态位 低三位
加锁过程
原子CAS操作加锁,如果发现锁定状态位为1,那么进入慢加锁过程
- 如果是非饥饿模式,且满足(多核多P,当前P本地队列无其他协程,自旋次数小于4)则先自旋获取锁,30次pause
- 如果长时间未获取到锁那么开始用信号量同步
。。。
读写锁
读写锁复用了互斥锁,写锁只能有一个,需要互斥获取
type RWMutex struct{
w Mutex
writerSem uint32
readerSem uint32
readerCount int32
readerWait int32
}
写锁加锁
获取互斥锁,减去一个很大的数,表示有写锁
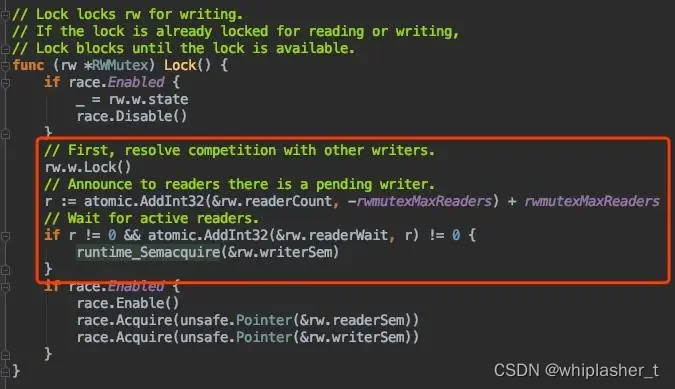
获取互斥锁之后,将readerCount 减去1<<30 ,为了告诉reader在尝试加写锁或者已经有写锁,因为一般的readerCount在增加读者时,也就几个几十个,释放读锁时,readerCount原子操作减一,最小为0。
r表示原来的readerCount,将其赋值给readerWait表示阻塞的写锁等待这么多的读者退出
然后对writerSem信号量p操作阻塞住
读锁加锁
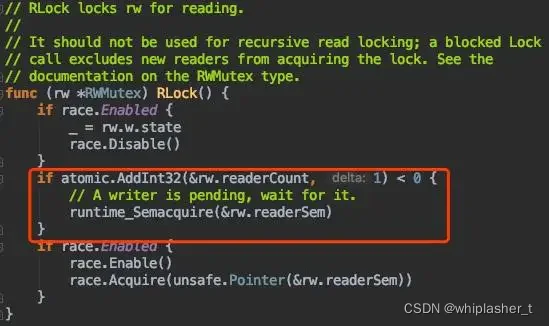
读锁可以加很多把,根据上面的写锁,当有写锁在准备加或者已经有写锁时,阻塞当前协程,在readerSem上进行p操作
读锁释放
readerCount原子操作减一,若结果是负数,说明有写锁等待或者有写锁,那么尝试对readerWait(加写锁时还有的读者数量)减一,恰好是最后一个读者,那么对writerSem进行V操作,唤醒欲加写锁的协程。
写锁释放
将readerCount+那个很大的数,结果为r,在写锁期间,有r个协程阻塞,对readerSem 进行r次V操作,依次唤醒。
google开发的Thread caching malloc
程序启动时,申请一块虚拟内存,spans,bitmap(指针位和扫描位),heapArea
heapArea被分为8KB的页,一些页组合起来成为span,span有67个大小不同的级别
spans存放mspan的指针,每个指针指向一页,
内存分配器
三个组件:mcache mcentral mheap
mcache与每个p绑定有一个,拥有所有规格的mspan,各2个,一个包含指针一个不包含指针。mspan由mcache动态向mcentral申请
mcentral:
empty表示这条链表里的mspan都被分配了object,或者是已经被cache取走了的mspan,这个mspan就被那个工作线程独占了。而nonempty则表示有空闲对象的mspan列表。每个central结构体都在mheap中维护。
mcache从其中获取要加锁,因为是全局mcache共享的。获取时,从noempty链表取下放入empty链表。
mheap:
一个全局mheap对象管理堆内存
**当mcentral没有空闲的mspan时,会向mheap申请。而mheap没有资源时,会向操作系统申请新内存。mheap主要用于大对象的内存分配,以及管理未切割的mspan,用于给mcentral切割成小对象。
**
对象分配:
> 32KB 的对象,直接从mheap上分配;
<=16B 的对象使用mcache的tiny分配器分配;
(16B,32KB] 的对象,首先计算对象的规格大小,然后使用mcache中相应规格大小的mspan分配;
如果mcache没有相应规格大小的mspan,则向mcentral申请
如果mcentral没有相应规格大小的mspan,则向mheap申请
如果mheap中也没有合适大小的mspan,则向操作系统申请