
由于本人在准备找golang的春招实习,所以开此贴方便记录
图床有些问题,最近准备搭建一个个人博客,到时候会放出链接
由于近期看到百度文库等抄袭搬运猖獗,故只放出部分内容,如需全部请私聊。
golang
1.简述go语言GMP调度模型
G:一个G代表一个goroutine,协程的本质是用户态的线程,用户对其有控制权限,内存占用少,切换代价低。
M:内核态线程,一个M代表了一个内核线程,等同于系统线程,所有的G都要放在M上才能运行。
P:处理器,用来管理和执行goroutine,一个P代表了M所需的上下文环境。P的个数取决于设置的GOMAXPROCS,go新版本默认使用最大内核数,比如你有8核处理器,那么P的数量就是8
三者关系:G需要绑定在M上才能运行,M需要绑定P才能运行。
M的数量和P不一定匹配,可以设置很多M,M和P绑定后才可运行,多余的M处于休眠状态。
系统会通过调度器从全局队列找到G分配给空闲的M,P会选择一个M来运行,M和G的数量不等,P会有一个本地队列表示M未处理的G,M本身有一个正在处理的G,M每次处理完一个G就从本地队列里取一个G,并且更新P的schedtick字段,如果本地队列没有G,则从全局队列一次性取走G/P个数的G,如果全局队列里也没有,就从其他的P的本地队列取走一半。
2.Goroutine阻塞的话,是不是对应的M也会阻塞
这要分为以下四种情况
1、由于原子、互斥量或通道操作调用导致Goroutine阻塞
该情况的G阻塞不会阻塞内核线程M,因此不会导致M的上下文切换而只涉及到G的切换。
2、由于网络请求和文件IO操作导致Goroutine阻塞
该情况的G阻塞不会阻塞内核线程M,因此不会导致M的上下文切换而只涉及到G的切换。
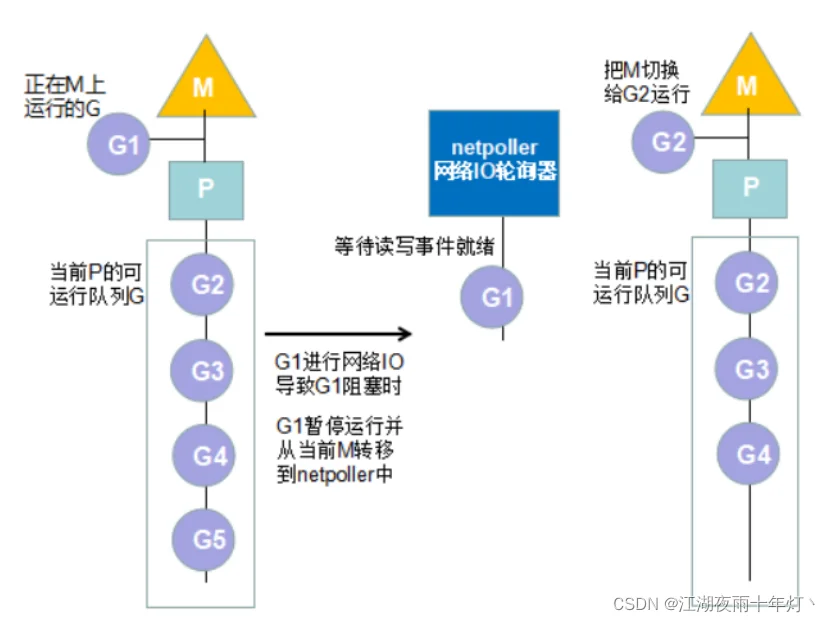
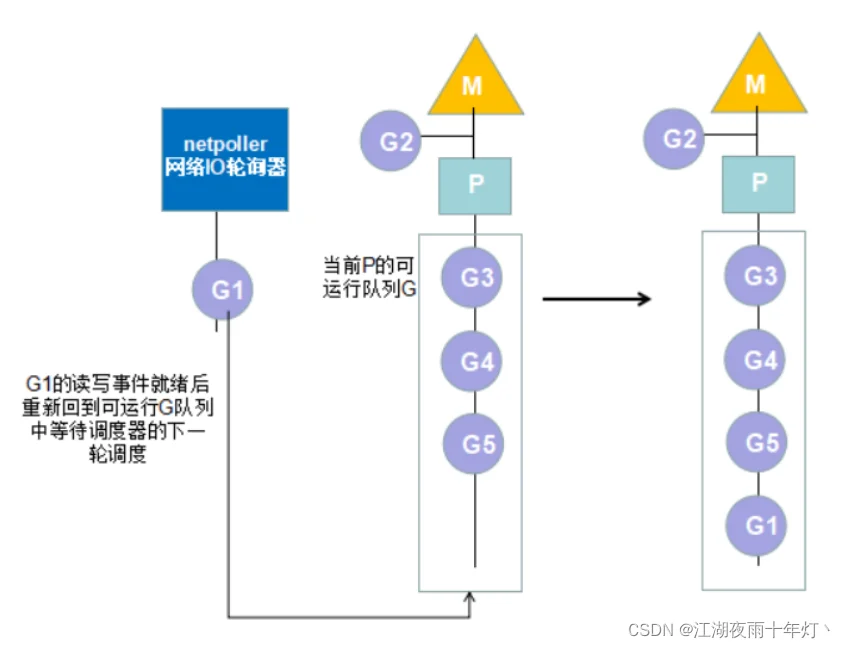
3、由于调用time.Sleep或者ticker计时器导致Goroutine阻塞
这种情况和情况2相似,不会阻塞当前M。
4、由于调用阻塞的系统调用时导致的goroutine阻塞
这种情况会导致当前M阻塞,内核会进行M的切换。而与当前M关联的当前P不会等待M的阻塞,因为这意味当前P下的所有G都无法执行,所以此时P会与当前M解除关联,转而关联到另一个内核线程M2,M2可能时新创建的内核线程,也可能时之前空闲的内核线程被唤醒来执行P的G。
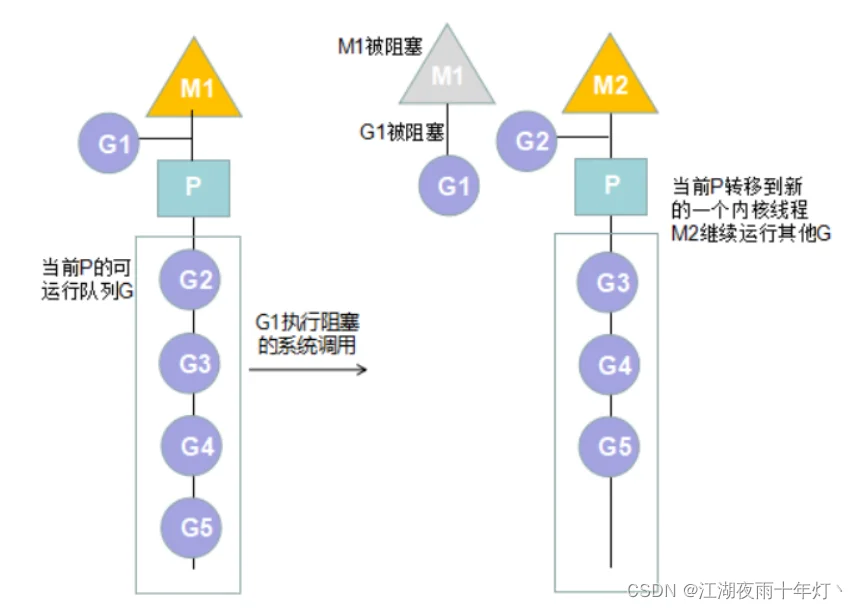

对应问题如何阻塞一个goroutine?
方法1:从一个不发送数据channel中接收数据
方法2:向不接收数据的channel中发送数据
方法3:从空的channel中接收数据
方法4:向空channel中发送数据
方法5:使用select
3.new和make的区别
make:返回类型是引用类型,只用于slice、map以及channel的初始化,无可替代
new:返回类型是指针,用于类型内存分配(初始化值为0),不常用
4.谈谈你对defer的理解
1.多个defer出现的时候,它是一个“栈”的关系,也就是先进后出。一个函数中,写在前面的defer会比写在后面的defer调用的晚。
2.return之后的语句先执行,defer后的语句后执行
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c6f73CJj-1652680479685)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220401163745250.png)]
由panic引发异常以后,程序停止执行,然后调用延迟函数(defer),就像程序正常退出一样。另外recover也是要写在延迟函数中的,如果发生异常延迟函数就不执行了,那就永远无法recover了。
5.Golang的协程与Java线程的区别?
协程是轻量级线程,多个协程可以由一个或多个线程管理。协程无需上下文切换,没有线程之间切换的开销。协程的调度不需要多线程的锁机制,因为只有一个线程,不存在同时写变量冲突,执行效率比多线程高很多。
6.go数组和slice的区别
1.数组定长,定义的时候就需要确定。切片长度不定,append时会自动扩容
2.相同大小数组可以赋值,会拷贝全部内容。slice赋值和指针一样。数组和slice之间不能相互赋值。当然slice有自己的copy函数
3.数组也可以进行切片,返回值是一个slice,改变slice时会同步修改数组内容,相当于取得了这个数组的指针
4.slice的底层数据是数组,slice是对数组的封装,它描述一个数组的片段。两者都可以通过下标来访问单个元素。
5.切片的类型和长度无关,而数组的长度是数组类型的一部分。
二维数组
vararr[4][4]int
arr[2][3]=4
fmt.Println(arr)
二维切片
node:=make([][]int,N)
fori:=0;i<N;i++{
node[i]=make([]int,N)
}
7.struct能否比较?
结构体比较时
1如果两个结构体内部成员类型不同,则不能比较
2如果两个结构体内部成员类型相同,但是顺序不同,则不能比较
3如果两个结构体内含有无法比较类型,则无法比较
4如果两个结构体类型,顺序相同,且不含有无法比较类型(slice,map)则可以进行比较
8.Select
select是Go中的一个控制结构,类似于用于通信的switch语句。每个case必须是一个通信操作,要么是发送要么是接收。
select随机执行一个可运行的case。如果没有case可运行,它将阻塞,直到有case可运行。一个默认的子句应该总是可运行的。
packagemain
import"fmt"
funcmain(){
varc1,c2,c3chanint
vari1,i2int
select{
casei1=<-c1:
fmt.Printf("received",i1,"fromc1\n")
casec2<-i2:
fmt.Printf("sent",i2,"toc2\n")
casei3,ok:=(<-c3)://sameas:i3,ok:=<-c3
ifok{
fmt.Printf("received",i3,"fromc3\n")
}else{
fmt.Printf("c3isclosed\n")
}
default:
fmt.Printf("nocommunication\n")
}
}
-
每个case都必须是一个通信
-
所有channel表达式都会被求值
-
所有被发送的表达式都会被求值
-
如果任意某个通信可以进行,它就执行,其他被忽略。
-
如果有多个case都可以运行,Select会随机公平地选出一个执行。其他不会执行。
否则:
- 如果有default子句,则执行该语句。
- 如果没有default子句,select将阻塞,直到某个通信可以运行;Go不会重新对channel或值进行求值。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H6f7iyXn-1652680479686)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220401161739511.png)]
- 在select中执行case语句时,不会自动fallthrough
- fallthrough:Go里面switch默认相当于每个case最后带有break,匹配成功后不会自动向下执行其他case,而是跳出整个switch,但是可以使用fallthrough强制执行后面的case代码。
- I:就是input、O:就是output,故称:输入输出流。
- IO操作,就是将数据写入内存或从内存输出的过程,也指应用程序和外部设备之间的数据传递,常见的外部设备包括文件、管道、网络连接。
- 常见IO流操作,一般指内存与磁盘间的输入输出流操作。
- 同步就是在一个功能调用时,在没有得到结果之前,该调用就不返回。也就是一件一件事做,等前一件做完了才做下一件事。
异步和同步相对,当一个异步过程调用出发后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态,通知和回调来通知调用者。
swich
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-byp9covY-1652680479687)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220401162317867.png)]
9.对map的理解
map可以通过赋值扩容
map使用前必须make,而切片不必
map的底层实现
使用数组+链表的形式实现的,使用拉链法消除hash冲突
hmap是Gomap的底层实现,每个hmap内都含有多个bmap(buckets桶、oldbuckets旧桶、overflow溢出桶),既每个哈希表都由多个桶组成。
当有两个或以上数量的键被哈希到了同一个bucket时,我们称这些键发生了冲突。Go使用链地址法来解决键冲突。
负载因子=键数量/bucket数量
负载因子>6.5时,也即平均每个bucket存储的键值对达到6.5个,触发扩容
扩容分为增量扩容和等量扩容
增量扩容:当负载因子过大时,就新建一个bucket,新的bucket长度是原来的2倍,然后旧bucket数据搬迁到新的bucket。
等量扩容:实际上并不是扩大容量,buckets数量不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。
map的value赋值问题
packagemain
import"fmt"
typeStudentstruct{
Namestring
}
var list map[string]Student
funcmain(){
list=make(map[string]Student)
student:=Student{"Aceld"}
list["student"]=student
list["student"].Name="LDB"
fmt.Println(list["student"])
}
map[string]Studentlist["student"]=studentlist["student"]只读list["student"].Name="LDB"packagemain
import"fmt"
typeStudentstruct{
Namestring
}
varlistmap[string]*Student
funcmain(){
list=make(map[string]*Student)
student:=Student{"Aceld"}
list["student"]=&student
list["student"].Name="LDB"
fmt.Println(list["student"])
}
我们将map的类型的value由Student值,改成Student指针。
只读map的遍历赋值问题
packagemain
import(
"fmt"
)
typestudentstruct{
Namestring
Ageint
}
funcmain(){
//定义map
m:=make(map[string]*student)
//定义student数组
stus:=[]student{
{Name:"zhou",Age:24},
{Name:"li",Age:23},
{Name:"wang",Age:22},
}
//将数组依次添加到map中
for_,stu:=rangestus{
m[stu.Name]=&stu
}
//打印map
fork,v:=rangem{
fmt.Println(k,"=>",v.Name)
}
}
m[stu.Name]=&stustruct的值拷贝正确写法
packagemain
import(
"fmt"
)
typestudentstruct{
Namestring
Ageint
}
funcmain(){
//定义map
m:=make(map[string]*student)
//定义student数组
stus:=[]student{
{Name:"zhou",Age:24},
{Name:"li",Age:23},
{Name:"wang",Age:22},
}
//遍历结构体数组,依次赋值给map
fori:=0;i<len(stus);i++{
m[stus[i].Name]=&stus[i]
}
//打印map
fork,v:=rangem{
fmt.Println(k,"=>",v.Name)
}
}
10.GC原理?
1、GoV1.3之前的标记-清除(markandsweep)算法
第一步,暂停程序业务逻辑,分类出可达和不可达的对象,然后做上标记。
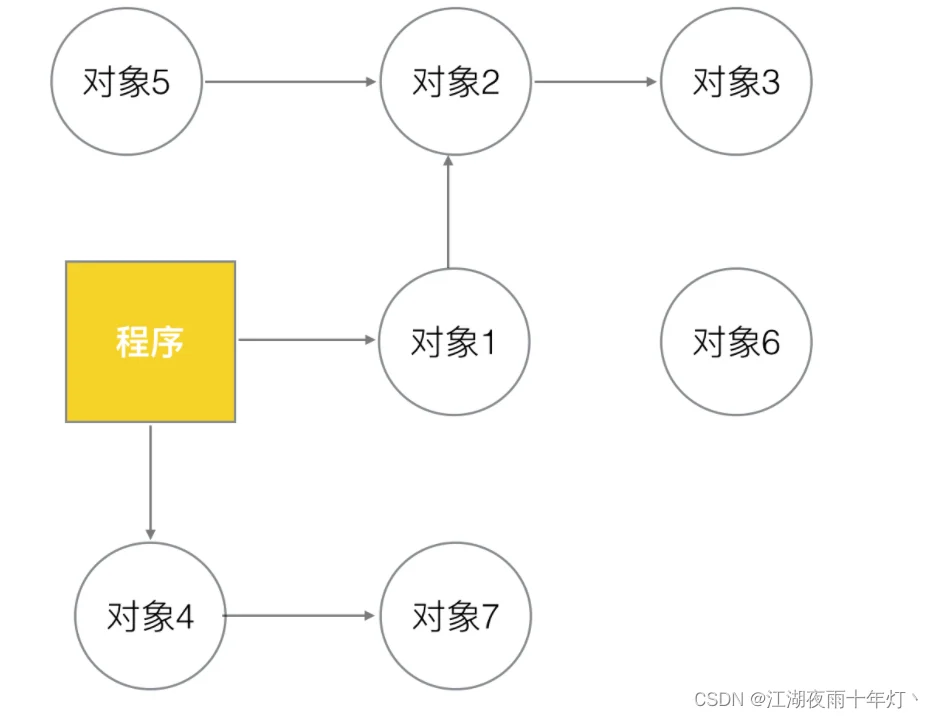
第二步,开始标记,程序找出它所有可达的对象,并做上标记。
第三步,标记完了之后,然后开始清除未标记的对象.结果如下。
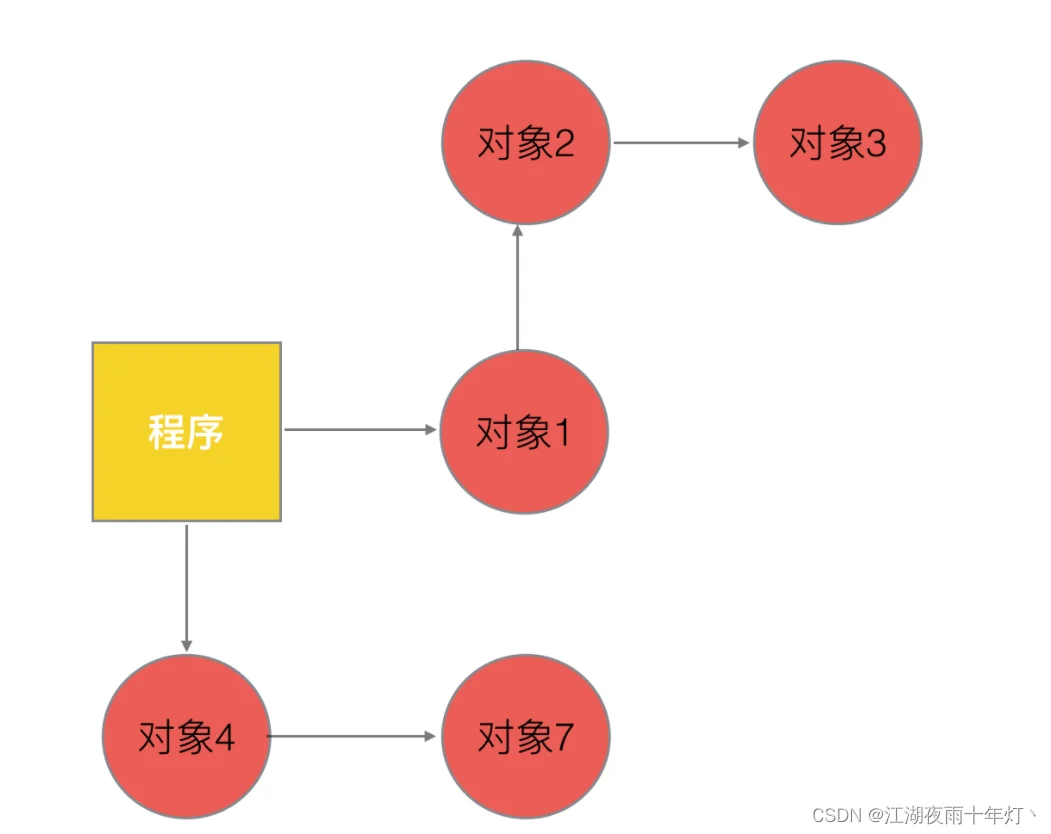
操作非常简单,但是有一点需要额外注意:markandsweep算法在执行的时候,需要程序暂停!即STW(stoptheworld),STW的过程中,CPU不执行用户代码,全部用于垃圾回收,这个过程的影响很大,所以STW也是一些回收机制最大的难题和希望优化的点。所以在执行第三步的这段时间,程序会暂定停止任何工作,卡在那等待回收执行完毕。
第四步,停止暂停,让程序继续跑。然后循环重复这个过程,直到process程序生命周期结束。
2.GoV1.5的三色并发标记法
go采用三色标记法回收内存,程序开始创建的对象全部为白色,gc扫描后将可到达的对象标记为灰色,再从灰色对象中找到其引用的其他对象,将其标记为灰色,将自身标记为黑色,重复上述步骤,直到找不到灰色对象为止。最后对所有白色对象清除。
3.GoV1.8的混合写屏障(hybridwritebarrier)机制
强三色不变式
不存在黑色对象引用到白色对象的指针
弱三色不变式
所有被黑色对象引用的白色对象都处于灰色保护状态
插入写屏障:结束时需要STW来重新扫描栈,标记栈上引用的白色对象的存活;
删除写屏障:回收精度低,GC开始时STW扫描堆栈来记录初始快照,这个过程会保护开始时刻的所有存活对象。
规则:
1、GC开始将栈上的对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需STW),
2、GC期间,任何在栈上创建的新对象,均为黑色。
3、被删除的对象标记为灰色。
4、被添加的对象标记为灰色。
Golang中的混合写屏障满足弱三色不变式,结合了删除写屏障和插入写屏障的优点,只需要在开始时并发扫描各个goroutine的栈,使其变黑并一直保持,这个过程不需要STW,而标记结束后,因为栈在扫描后始终是黑色的,也无需再进行re-scan操作了,减少了STW的时间。
最常见的垃圾回收算法有标记清除(Mark-Sweep) 和引用计数(Reference Count),Go 语言采用的是标记清除算法。并在此基础上使用了三色标记法和写屏障技术,提高了效率。
标记清除收集器是跟踪式垃圾收集器,其执行过程可以分成标记(Mark)和清除(Sweep)两个阶段:
- 标记阶段 — 从根对象出发查找并标记堆中所有存活的对象;
- 清除阶段 — 遍历堆中的全部对象,回收未被标记的垃圾对象并将回收的内存加入空闲链表。
标记清除算法的一大问题是在标记期间,需要暂停程序(Stop the world,STW),标记结束之后,用户程序才可以继续执行。为了能够异步执行,减少 STW 的时间,Go 语言采用了三色标记法。
三色标记算法将程序中的对象分成白色、黑色和灰色三类。
- 白色:不确定对象。
- 灰色:存活对象,子对象待处理。
- 黑色:存活对象。
标记开始时,所有对象加入白色集合(这一步需 STW )。首先将根对象标记为灰色,加入灰色集合,垃圾搜集器取出一个灰色对象,将其标记为黑色,并将其指向的对象标记为灰色,加入灰色集合。重复这个过程,直到灰色集合为空为止,标记阶段结束。那么白色对象即可需要清理的对象,而黑色对象均为根可达的对象,不能被清理。
三色标记法因为多了一个白色的状态来存放不确定对象,所以后续的标记阶段可以并发地执行。当然并发执行的代价是可能会造成一些遗漏,因为那些早先被标记为黑色的对象可能目前已经是不可达的了。所以三色标记法是一个 false negative(假阴性)的算法。
三色标记法并发执行仍存在一个问题,即在 GC 过程中,对象指针发生了改变。比如下面的例子:
A (黑) -> B (灰) -> C (白) -> D (白)
正常情况下,D 对象最终会被标记为黑色,不应被回收。但在标记和用户程序并发执行过程中,用户程序删除了 C 对 D 的引用,而 A 获得了 D 的引用。标记继续进行,D 就没有机会被标记为黑色了(A 已经处理过,这一轮不会再被处理)。
A (黑) -> B (灰) -> C (白)
↓
D (白)
为了解决这个问题,Go 使用了内存屏障技术,它是在用户程序读取对象、创建新对象以及更新对象指针时执行的一段代码,类似于一个钩子。垃圾收集器使用了写屏障(Write Barrier)技术,当对象新增或更新时,会将其着色为灰色。这样即使与用户程序并发执行,对象的引用发生改变时,垃圾收集器也能正确处理了。
一次完整的 GC 分为四个阶段:
- 1)标记准备(Mark Setup,需 STW),打开写屏障(Write Barrier)
- 2)使用三色标记法标记(Marking, 并发)
- 3)标记结束(Mark Termination,需 STW),关闭写屏障。
- 4)清理(Sweeping, 并发)
总结
GoV1.3-普通标记清除法,整体过程需要启动STW,效率极低。
GoV1.5-三色标记法,堆空间启动写屏障,栈空间不启动,全部扫描之后,需要重新扫描一次栈(需要STW),效率普通
GoV1.8-混合写屏障,混合写屏障机制,栈空间不启动,堆空间启动。整个过程几乎不需要STW,效率较高。
11.goroutine的创建,并发机制
当一个程序启动的时候,只有一个goroutine来调用main函数,称它为主goroutine,新的goroutine通过go语句进行创建。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-35SgnIYe-1652680479687)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220401162531461.png)]
这一题选择B无任何输出
因为一旦main函数执行结束,就意味着该Go程序运行的结束,所以sendData,getData没有执行整个程序便结束了。
可以通过三种方式来保证sendData,getData的执行:
-
time.Sleep,这种方式不可控,因为并不知道sendData,getData会执行多久,如果Sleep时间过短的话sendData,getData仍然会没有执行完
-
通过channel。syncChan会一直阻塞直到线程执行完毕,起到了等待的作用。
-
使用sync.WaitGroup
12.channel
1.本质就是数据结构-队列
2.数据是先进先出
3.线程安全,多goroutine访问时,不需要加锁,就是说channel本身就是线程安全的。
4.channel有类型的,一个string的channel只能存放string类型数据。
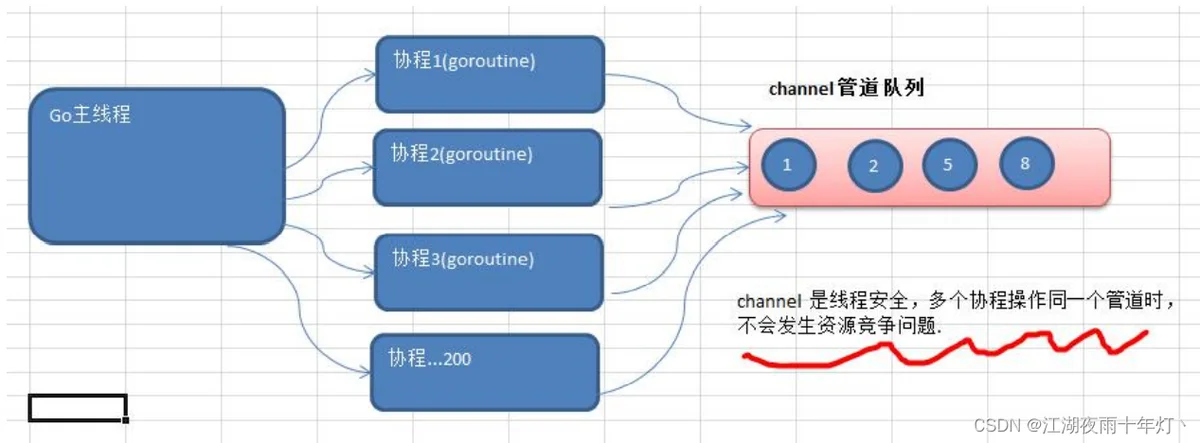
channel的遍历
注意事项
Channel读写特性(15字口诀)
给一个nilchannel发送数据,造成永远阻塞
从一个nilchannel接收数据,造成永远阻塞
给一个已经关闭的channel发送数据,引起panic
从一个已经关闭的channel接收数据,如果缓冲区中为空,则返回一个零值
无缓冲的channel是同步的,而有缓冲的channel是非同步的
空读写阻塞,写关闭异常,读关闭空零
13.go常见占位符
1、普通占位符

2、整数占位符
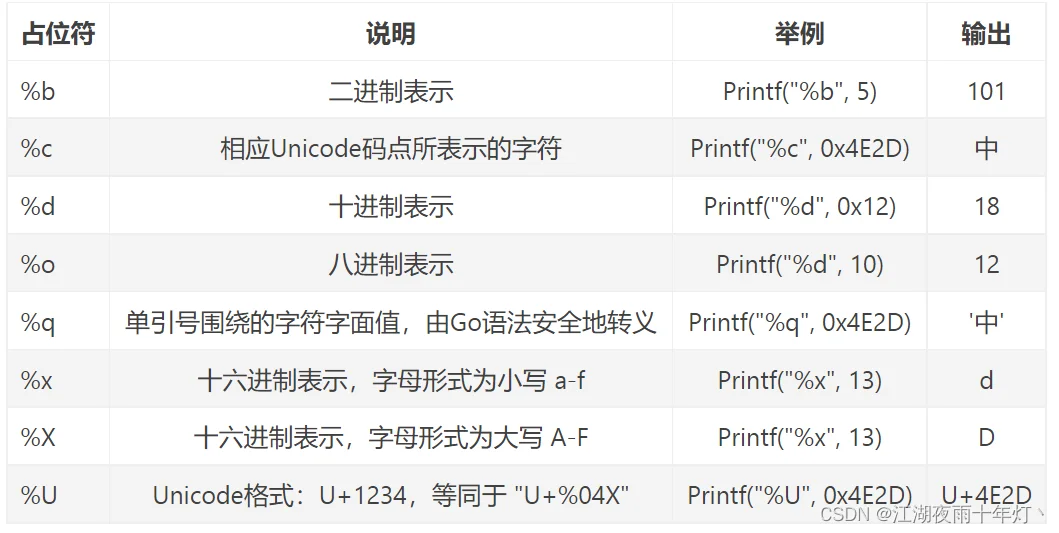
3、字符串与切片
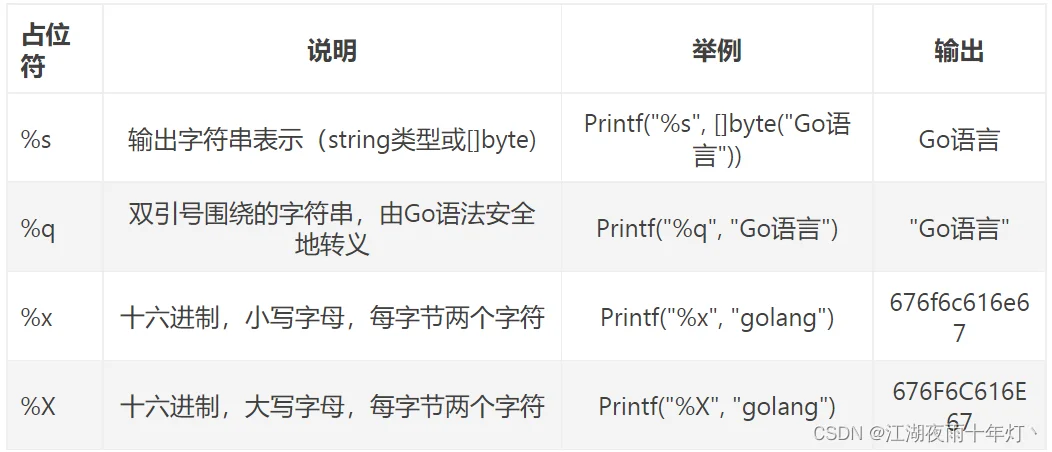
14.微服务
14.1负载均衡
什么是负载均衡?
- 当一台服务器的性能达到极限时,我们可以使用服务器集群来提高网站的整体性能。那么,在服务器集群中,需要有一台服务器充当调度者的角色,用户的所有请求都会首先由它接收,调度者再根据每台服务器的负载情况将请求分配给某一台后端服务器去处理。
- 那么在这个过程中,调度者如何合理分配任务,保证所有后端服务器都将性能充分发挥,从而保持服务器集群的整体性能最优,这就是负载均衡问题。
负载均衡的四种方式:
1.HTTP重定向实现负载均衡
- 当用户向服务器发起请求时,请求首先被集群调度者截获;调度者根据某种分配策略,选择一台服务器,并将选中的服务器的IP地址封装在HTTP响应消息头部的Location字段中,并将响应消息的状态码设为302,最后将这个响应消息返回给浏览器。
- 当浏览器收到响应消息后,解析Location字段,并向该URL发起请求,然后指定的服务器处理该用户的请求,最后将结果返回给用户。
- 在使用HTTP重定向来实现服务器集群负载均衡的过程中,需要一台服务器作为请求调度者。用户的一项操作需要发起两次HTTP请求,一次向调度服务器发送请求,获取后端服务器的IP,第二次向后端服务器发送请求,获取处理结果。
1.1调度策略
调度服务器收到用户的请求后,究竟选择哪台后端服务器处理请求,这由调度服务器所使用的调度策略决定。
- 随机分配策略
当调度服务器收到用户请求后,可以随机决定使用哪台后端服务器,然后将该服务器的IP封装在HTTP响应消息的Location属性中,返回给浏览器即可。 - 轮询策略(RR)
调度服务器需要维护一个值,用于记录上次分配的后端服务器的IP。那么当新的请求到来时,调度者将请求依次分配给下一台服务器。
由于轮询策略需要调度者维护一个值用于记录上次分配的服务器IP,因此需要额外的开销;此外,由于这个值属于互斥资源,那么当多个请求同时到来时,为了避免线程的安全问题,因此需要锁定互斥资源,从而降低了性能。而随机分配策略不需要维护额外的值,也就不存在线程安全问题,因此性能比轮询要高。
1.2优缺点分析
采用HTTP重定向来实现服务器集群的负载均衡实现起来较为容易,逻辑比较简单,但缺点也较为明显。
在HTTP重定向方法中,调度服务器只在客户端第一次向网站发起请求的时候起作用。当调度服务器向浏览器返回响应信息后,客户端此后的操作都基于新的URL进行的(也就是后端服务器),此后浏览器就不会与调度服务器产生关系,进而会产生如下几个问题
- 由于不同用户的访问时间、访问页面深度有所不同,从而每个用户对各自的后端服务器所造成的压力也不同。而调度服务器在调度时,无法知道当前用户将会对服务器造成多大的压力,因此这种方式无法实现真正意义上的负载均衡,只不过是把请求次数平均分配给每台服务器罢了。
- 若分配给该用户的后端服务器出现故障,并且如果页面被浏览器缓存,那么当用户再次访问网站时,请求都会发给出现故障的服务器,从而导致访问失败。
2.DNS负载均衡
什么是DNS?
- 我们知道,数据包采用IP地址在网络中传播,而为了方便用户记忆,我们使用域名来访问网站。那么,我们通过域名访问网站之前,首先需要将域名解析成IP地址,这个工作是由DNS完成的,也就是域名服务器。
- 我们提交的请求不会直接发送给想要访问的网站,而是首先发给域名服务器,它会帮我们把域名解析成IP地址并返回给我们。我们收到IP之后才会向该IP发起请求。
- 那么,DNS服务器有一个天然的优势,如果一个域名指向了多个IP地址,那么每次进行域名解析时,DNS只要选一个IP返回给用户,就能够实现服务器集群的负载均衡。
什么是DNS负载均衡?
- 首先需要将我们的域名指向多个后端服务器(将一个域名解析到多个IP上),再设置一下调度策略,那么我们的准备工作就完成了,接下来的负载均衡就完全由DNS服务器来实现。
- 当用户向我们的域名发起请求时,DNS服务器会自动地根据我们事先设定好的调度策略选一个合适的IP返回给用户,用户再向该IP发起请求。
2.1调度策略
一般DNS提供商会提供一些调度策略供我们选择,如随机分配、轮询、根据请求者的地域分配离他最近的服务器。
2.2优缺点分析
- DNS负载均衡最大的优点就是配置简单。服务器集群的调度工作完全由DNS服务器承担,那么我们就可以把精力放在后端服务器上,保证他们的稳定性与吞吐量。而且完全不用担心DNS服务器的性能,即便是使用了轮询策略,它的吞吐率依然卓越。
- 此外,DNS负载均衡具有较强了扩展性,你完全可以为一个域名解析较多的IP,而且不用担心性能问题。
- 但是,由于把集群调度权交给了DNS服务器,从而我们没办法随心所欲地控制调度者,没办法定制调度策略。
- DNS服务器也没办法了解每台服务器的负载情况,因此没办法实现真正意义上的负载均衡。它和HTTP重定向一样,只不过把所有请求平均分配给后端服务器罢了。
- 此外,当我们发现某一台后端服务器发生故障时,即使我们立即将该服务器从域名解析中去除,但由于DNS服务器会有缓存,该IP仍然会在DNS中保留一段时间,那么就会导致一部分用户无法正常访问网站。这是一个致命的问题!好在这个问题可以用动态DNS来解决。
2.3动态NDS
动态DNS能够让我们通过程序动态修改DNS服务器中的域名解析。从而当我们的监控程序发现某台服务器挂了之后,能立即通知DNS将其删掉。
2.4总结
DNS负载均衡是一种粗犷的负载均衡方法,这里只做介绍,不推荐使用。
3.反向代理负载均衡
反向代理服务器是一个位于实际服务器之前的服务器,所有向我们网站发来的请求都首先要经过反向代理服务器,服务器根据用户的请求要么直接将结果返回给用户,要么将请求交给后端服务器处理,再返回给用户。
我们知道,所有发送给我们网站的请求都首先经过反向代理服务器。那么,反向代理服务器就可以充当服务器集群的调度者,它可以根据当前后端服务器的负载情况,将请求转发给一台合适的服务器,并将处理结果返回给用户。
3.1优缺点
优点
- 隐藏后端服务器
与HTTP重定向相比,反向代理能够隐藏后端服务器,所有浏览器都不会与后端服务器直接交互,从而能够确保调度者的控制权,提升集群的整体性能。 - 故障转移
与DNS负载均衡相比,反向代理能够更快速地移除故障结点。当监控程序发现某一后端服务器出现故障时,能够及时通知反向代理服务器,并立即将其删除。 - 合理分配任务
HTTP重定向和DNS负载均衡都无法实现真正意义上的负载均衡,也就是调度服务器无法根据后端服务器的实际负载情况分配任务。但反向代理服务器支持手动设定每台后端服务器的权重。我们可以根据服务器的配置设置不同的权重,权重的不同会导致被调度者选中的概率的不同。
缺点
- 调度者压力过大
由于所有的请求都先由反向代理服务器处理,那么当请求量超过调度服务器的最大负载时,调度服务器的吞吐率降低会直接降低集群的整体性能。 - 制约扩展
当后端服务器也无法满足巨大的吞吐量时,就需要增加后端服务器的数量,可没办法无限量地增加,因为会受到调度服务器的最大吞吐量的制约。
3.2粘滞会话
反向代理服务器会引起一个问题:若某台后端服务器处理了用户的请求,并保存了该用户的session或存储了缓存,那么当该用户再次发送请求时,无法保证该请求仍然由保存了其Session或缓存的服务器处理,若由其他服务器处理,先前的Session或缓存就找不到了。
4.2层或者3层做负载均衡
2层负载均衡
- 也即在数据链路层做负载均衡。通过修改数据链路层的mac地址,ip使用的是虚拟IP,来实现负载均衡,解决响应数据体量过大效率低的问题。当客户端请求服务器时,负载均衡服务器替换mac地址为计算服务器,替换ip为负载均衡服务器ip,计算服务器直接响应数据到客户端。
- 这种负载均衡方式吞吐量最高,大型互联网公司都是采用这种负载均衡方式。LVS负载均衡是结合了IP层和数据链路层的负载均衡方式,linux通过配置可以实现这两种负载均衡方式。
3层负载均衡
- 网络层负载均衡。对网络层的IP地址进行替换,不需要在http层(应用层)工作,直接在操作系统内核的IP数据包中替换地址,效率比基于HTTP层的反向代理高。但是有个缺点是:请求和响应度需要经过负载均衡服务器进行ip层替换,响应数据会成为后期的瓶颈。
14.2Nginx
什么是Nginx?
Nginx是一个轻量级/高性能的反向代理Web服务器,他实现非常高效的反向代理、负载平衡,他可以处理2-3万并发连接数,官方监测能支持5万并发,现在中国使用nginx网站用户有很多,例如:新浪、网易、腾讯等。
Nginx的优缺点?
优点
- 占内存小,可实现高并发连接,处理响应快
- 可实现http服务器、虚拟主机、方向代理、负载均衡
- Nginx配置简单
- 可以不暴露正式的服务器IP地址
缺点
- nginx处理静态文件好,耗费内存少,但是处理动态页面则很鸡肋,现在一般前端用nginx作为反向代理抗住压力
Golang中的逃逸现象
接口
接口赋值问题
packagemain
import(
"fmt"
)
typePeopleinterface{
Speak(string)string
}
typeStduentstruct{}
func(stu*Stduent)Speak(thinkstring)(talkstring){
ifthink=="love"{
talk="Youareagoodboy"
}else{
talk="hi"
}
return
}
funcmain(){
varpeoPeople=Stduent{}
think:="love"
fmt.Println(peo.Speak(think))
}
继承与多态的特点
在golang中对多态的特点体现从语法上并不是很明显。
我们知道发生多态的几个要素:
1、有interface接口,并且有接口定义的方法。
2、有子类去重写interface的接口。
3、有父类指针指向子类的具体对象
那么,满足上述3个条件,就可以产生多态效果,就是,父类指针可以调用子类的具体方法。
varpeoPeople=Stduent{}Student{}People{}Speak(string)stringvarpeoPeople=&Student{}interface的内部构造(非空接口)
packagemain
import(
"fmt"
)
typePeopleinterface{
Show()
}
typeStudentstruct{}
func(stu*Student)Show(){
}
funclive()People{
varstu*Student
returnstu
}
funcmain(){
iflive()==nil{
fmt.Println("AAAAAAA")
}else{
fmt.Println("BBBBBBB")
}
}
结果
BBBBBBB
空接口与非空接口
空接口emptyinterface
varMyInterfaceinterface{}
非空接口non-emptyinterface
typeMyInterfaceinterface{
function()
}
structefaceiface空接口eface
typeefacestruct{//空接口
_type*_type//类型信息
dataunsafe.Pointer//指向数据的指针(go语言中特殊的指针类型unsafe.Pointer类似于c语言中的void*)
}
_type属性:是GO语言中所有类型的公共描述,Go语言几乎所有的数据结构都可以抽象成_type,是所有类型的公共描述,**type负责决定data应该如何解释和操作,**type的结构代码如下:
type_typestruct{
sizeuintptr//类型大小
ptrdatauintptr//前缀持有所有指针的内存大小
hashuint32//数据hash值
tflagtflag
alignuint8//对齐
fieldalignuint8//嵌入结构体时的对齐
kinduint8//kind有些枚举值kind等于0是无效的
alg*typeAlg//函数指针数组,类型实现的所有方法
gcdata*byte
strnameOff
ptrToThistypeOff
}
unsafe.Pointervoid*非空结构iface
typeifacestruct{
tab*itab
dataunsafe.Pointer
}
itabpairtypeitabstruct{
inter*interfacetype//接口自身的元信息
_type*_type//具体类型的元信息
link*itab
badint32
hashint32//_type里也有一个同样的hash,此处多放一个是为了方便运行接口断言
fun[1]uintptr//函数指针,指向具体类型所实现的方法
}
其中值得注意的字段,个人理解如下:
interfacetypepackagepathmethodtypehash_type.hashfun[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wou1JGcI-1652680479688)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220414135834790.png)]
ifacetypePeopleinterface{
Show()
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IfExc0Hl-1652680479688)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220414135929956.png)]
funclive()People{
varstu*Student
returnstu
}
returnstu匿名变量People=stulive()Peopleinsterface{}ifacestruct{}ifaceifacestruct{}[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8mjWdsAn-1652680479689)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220414140400241.png)]
interface的内部构造(空接口)
funcFoo(xinterface{}){
ifx==nil{
fmt.Println("emptyinterface")
return
}
fmt.Println("non-emptyinterface")
}
funcmain(){
varp*int=nil
Foo(p)
}
结果
non-emptyinterface
Foo()xinterface{}efacestruct{}Foo(p)xinterface{}=p[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m5kdnecp-1652680479689)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220414140811946.png)]
所以x结构体本身不为nil,而是data指针指向的p为nil。
inteface{}与*interface{}
typeSstruct{
}
funcf(xinterface{}){
}
funcg(x*interface{}){
}
funcmain(){
s:=S{}
p:=&s
f(s)//A
g(s)//B
f(p)//C
g(p)//D
}
B、D两行错误
B错误为:cannotuses(typeS)astype*interface{}inargumenttog:
*interface{}ispointertointerface,notinterface
D错误为:cannotusep(type*S)astype*interface{}inargumenttog:
*interface{}ispointertointerface,notinterface
funcf(xinterface{})interface{}funcg(x*interface{})*interface{}反射
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-si2pEWRu-1652680479689)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220407150920945.png)]
20.切片的底层原理
切片是围绕动态数组的概念进行构建的
type SliceHeader struct{
Data uintptr
Len int
Cap int
}
切片的结构由三个信息组成:
- 指针,指向底层数组中切片指定的开始位置
- 长度,即切片的长度
- 最大长度,也就是切片开始位置到数组的最后位置的长度
20.解决哈希冲突的方法
1、开放定址法:我们在遇到哈希冲突时,去寻找一个新的空闲的哈希地址。
1.1线性探测法
当我们的所需要存放值的位置被占了,我们就往后面一直加1并对m取模直到存在一个空余的地址供我们存放值,取模是为了保证找到的位置在0~m-1的有效空间之中。
1.2平方探测法
2.拉链法
将所有哈希地址相同的记录都链接在同一链表中
3.再哈希法:同时构造多个不同的哈希函数,等发生哈希冲突时就使用第二个、第三个……等其他的哈希函数计算地址,直到不发生冲突为止。虽然不易发生聚集,但是增加了计算时间
4、建立公共溢出区:将哈希表分为基本表和溢出表,将发生冲突的都存放在溢出表中。
21.切换协程
WaitGroup与goroutine的竞速问题
packagemain
import(
"sync"
//"time"
)
constN=10
varwg=&sync.WaitGroup{}
funcmain(){
fori:=0;i<N;i++{
gofunc(iint){
wg.Add(1)
println(i)
deferwg.Done()
}(i)
}
wg.Wait()
}
结果
结果不唯一,代码存在风险,所有go未必都能执行到
gowg.Add(1)packagemain
import(
"sync"
)
constN=10
varwg=&sync.WaitGroup{}
funcmain(){
fori:=0;i<N;i++{
wg.Add(1)
gofunc(iint){
println(i)
deferwg.Done()
}(i)
}
wg.Wait()
}
切片排序
sort.Slice(intervals, func(i, j int) bool {
return intervals[i][0] < intervals[j][0]
})
WaitGroup
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OFhr7Io0-1652680479690)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220507102353376.png)]
语法
byte和rune
byte等同于int8,常用来处理ascii字符
rune等同于int32,常用来处理unicode或utf-8字符
strconv
1.int转换为字符串:Itoa()
2.string转换为int:Atoi()
string是不可修改值的,但是可以改为byte数组修改
packagemain
import"fmt"
//golang的字符串是不可变的
//修改时,可以将字符串转换为[]byte进行修改
//[]byte和sting可以通过强制类型转换互换
funcmain(){
angel:="Herosneverdie"
angelBytes:=[]byte(angel)
fori:=4;i<=8;i++{
angelBytes[i]='x'
}
fmt.Println(string(angelBytes))
}
golang执行循环输入
for{
_,err:=fmt.Scan(&m,&n)
iferr==io.EOF{
break
}
fmt.Prinltn(m,n)
}
math函数
math.MaxInt得到int的最大值
iota用法
iota是golang语言的常量计数器,只能在常量的表达式中使用。
iota在const关键字出现时将被重置为0(const内部的第一行之前),const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。
packagemain
import"fmt"
const(
i=1<<iota
j=3<<iota
k
l
)
fmt.Prinltn(i,j,j,l) //161224
append扩容特点
packagemain//必须有个main包
import"fmt"
funcmain(){
//如果超过原来的容量,通常以2倍容量扩容
s:=make([]int,0,1)//长度为0,容量为1
oldCap:=cap(s)
fori:=0;i<20;i++{
s=append(s,i)
ifnewCap:=cap(s);oldCap<newCap{
fmt.Printf("cap:%d===>%d\n",oldCap,newCap)
oldCap=newCap
}
}
}
cap:1===>2
cap:2===>4
cap:4===>8
cap:8===>16
cap:16===>32
匿名函数
匿名函数可以直接赋值给一个变量或者直接执行
计算机网络
OSI七层模型与五层模型与四层模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8l5bg2Wj-1652680479691)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220412172028098.png)]
OSI七层协议
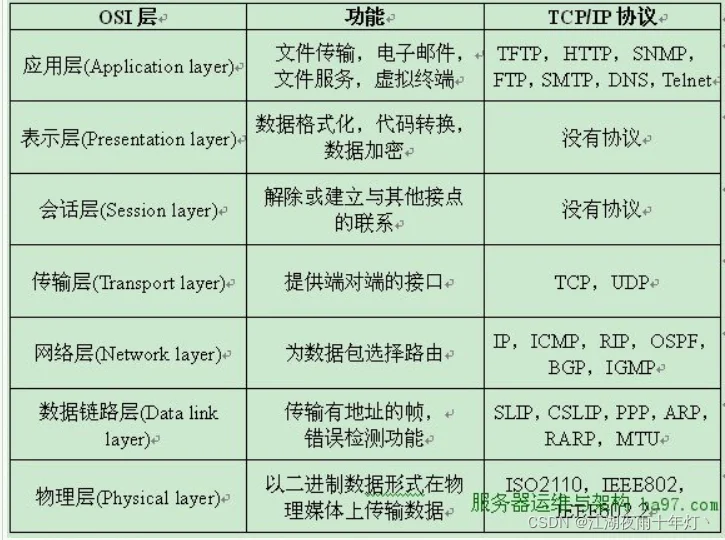
- 应用层:为特定应用程序提供数据传输服务,例如域名系统DNS,支持万维网应用的HTTP协议,电子邮件系统采用的SMTP协议等。在应用层交互的数据单元我们称之为报文
- 表示层:作用是使通信的应用程序能够解释交换数据的含义。该层提供的服务主要包括数据压缩,数据加密以及数据描述。这使得应用程序不必担心在各台计算机中表示和存储的内部格式差异。
- 会话层:会话层就是负责建立、管理和终止表示层实体之间的通信会话。该层提供了数据交换的定界和同步功能,包括了建立检查点和恢复方案的方法。
- 传输层:为进程提供通用数据传输服务。由于应用层协议很多,定义通用的传输层协议就可以支持不断增多的应用层协议。**传输层的主要任务是为两台主机进程之间的通信提供服务。应用程序利用该服务传送应用层报文。该服务并不针对某一特定的应用,多种应用可以使用同一个运输层服务。由于一台主机可同时运行多个线程,因此运输层有复用和分用的功能。所谓复用就是指多个应用层进程可同时使用下面运输层的服务,分用和复用相反,是运输层把收到的信息分别交付上面应用层中的相应进程。**运输层包括两种协议:传输控制协议TCP,提供面向连接、可靠的数据传输服务,数据单位为报文段;用户数据报协议UDP,提供无连接、尽最大努力的数据传输服务,数据单位为用户数据报。TCP主要提供完整性服务,UDP主要提供及时性服务。
- 网络层:为不同网络中的主机提供数据传输服务,网络层的主要任务就是选择合适的网间路由和交换节点,确保数据按时成功传送。而传输层协议是为主机中的进程提供数据传输服务。网络层把传输层传递下来的报文段或者用户数据报封装成分组。
- 数据链路层:网络层针对的还是主机之间的数据传输服务,而主机之间可以有很多链路,链路层协议就是为同一链路(网络)的主机提供数据传输服务。数据链路层把网络层传下来的分组封装成帧。数据链路层通常也叫做链路层,在物理层和网络层之间。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层协议。在两个相邻节点之间传送数据时,数据链路层将网络层交下来的IP数据报组装成帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息。通过控制信息我们可以知道一个帧的起止比特位置,此外,也能使接收端检测出所收到的帧有无差错,如果发现差错,数据链路层能够简单的丢弃掉这个帧,以避免继续占用网络资源。
- 物理层:物理层的作用是实现计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。使其上面的数据链路层不必考虑网络的具体传输介质是什么。
路由器、防火墙、交换机处于哪一层
- 路由器:网络层
- 防火墙:工作在网络层,传输层,应用层,取决于防火墙的种类2.1过滤型防火墙:过滤型防火墙是在网络层与传输层中,可以基于数据源头的地址以及协议类型等标志特征进行分析,确定是否可以通过。在符合防火墙规定标准之下,满足安全性能以及类型才可以进行信息的传递,而一些不安全的因素则会被防火墙过滤、阻挡。2.2应用代理防火墙:应用代理防火墙主要的工作范围就是在OIS的最高层,位于应用层之上。其主要的特征是可以完全隔离网络通信流,通过特定的代理程序就可以实现对应用层的监督与控制。2.3复合型防火墙技术:目前应用较为广泛的防火墙技术当属复合型防火墙技术,综合了包过滤防火墙技术以及应用代理防火墙技术的优点,譬如发过来的安全策略是包过滤策略,那么可以针对报文的报头部分进行访问控制;如果安全策略是代理策略,就可以针对报文的内容数据进行访问控制,因此复合型防火墙技术综合了其组成部分的优点,同时摒弃了两种防火墙的原有缺点,大大提高了防火墙技术在应用实践中的灵活性和安全性。
- 交换机:数据链路层
转发分组的详细过程
- 检查ip数据报首部是否出错,出错则丢弃该ip数据报并通告源主机,没有出错则进行转发
- 若主机与此路由器直接相连,则把数据报直接交付目的主机D;否则是间接交付,执行(3)。
- 若路由表中有目的地址为D的特定主机路由,则把数据报传送给路由表中所指明的下一跳路由器;否则,执行(4)。
- 若路由表中有到达网络N的路由,则把数据报传送给路由表指明的下一跳路由器;否则,执行(5)。
- 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;否则,执行(6)。
- 报告转发分组出错。
同一个网络中的主机可以直接进行通信,属于直接交付!>不同网络中的主机进行通信,需要通过路由器中转,属于间接交付。
网关
什么是网关?
大家都知道,从一个房间走到另一个房间,必然要经过一扇门。同样,从一个网络向另一个网络发送信息,也必须经过一道“关口”,这道关口就是网关。顾名思义,网关就是一个网络连接到另一个网络的“关口”。也就是网络关卡。
TCP和UDP
TCP和UDP区别
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Scpc7int-1652680479691)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413170025713.png)]
| UDP(UserDatagramProtocol) | TCP(TransmissionControlProtocol) |
|---|---|
| 无连接 | 面向连接 |
| 支持一对一,一对多,多对一,多对多通信 | 因为双方需要提前建立连接,因此只能一对一进行通信(全双工:双方随时都可以发送和接收数据) |
| 面向报文段(对应用层发送的报文段直接添加首部并传送到IP) | 面向字节流 |
| 不保证可靠交付:尽最大努力交付,不使用流量控制和拥塞控制 | 可靠传输,使用确认序号,滑动窗口,流量控制以及拥塞控制等来实现可靠传输 |
| 首部只有8字节 | 首部最小有20自己,最大有60字节 |
TCP协议头
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l6SG95Ok-1652680479692)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413170125645.png)]
**序号:**用于对字节流进行编号,例如序号为301,表示第一个字节的编号为301,如果携带的数据长度为100字节,那么下一个报文段的序号应为401。
**确认号:**期望收到的下一个报文段的序号。例如B正确收到A发送来的一个报文段,序号为501,携带的数据长度为200字节,因此B期望下一个报文段的序号为701,B发送给A的确认报文段中确认号就为701。
**数据偏移:**指的是数据部分距离报文段起始处的偏移量,实际上指的是首部的长度。
**控制位:**八位从左到右分别是CWR,ECE,URG,ACK,PSH,RST,SYN,FIN。
**CWR:**CWR标志与后面的ECE标志都用于IP首部的ECN字段,ECE标志为1时,则通知对方已将拥塞窗口缩小;
**ECE:**若其值为1则会通知对方,从对方到这边的网络有阻塞。在收到数据包的IP首部中ECN为1时将TCP首部中的ECE设为1;
**URG:**该位设为1,表示包中有需要紧急处理的数据,对于需要紧急处理的数据,与后面的紧急指针有关;
**ACK:**该位设为1,确认应答的字段有效,TCP规定除了最初建立连接时的SYN包之外该位必须设为1;
**PSH:**该位设为1,表示需要将收到的数据立刻传给上层应用协议,若设为0,则先将数据进行缓存;
**RST:**该位设为1,表示TCP连接出现异常必须强制断开连接;
**SYN:**用于建立连接,该位设为1,表示希望建立连接,并在其序列号的字段进行序列号初值设定;
**FIN:**该位设为1,表示今后不再有数据发送,希望断开连接。当通信结束希望断开连接时,通信双方的主机之间就可以相互交换FIN位置为1的TCP段。
每个主机又对对方的FIN包进行确认应答之后可以断开连接。不过,主机收到FIN设置为1的TCP段之后不必马上回复一个FIN包,而是可以等到缓冲区中的所有数据都因为已成功发送而被自动删除之后再发FIN包;
**窗口:**窗口值作为接收方让发送方设置其发送窗口的依据。之所以要有这个限制,是因为接收方的数据缓存空间是有限的。
TCP可靠性的实现方式
TCP是通过序列号、确认应答、重发控制、连接管理以及窗口控制等机制实现可靠性传输的。
三次握手和四次挥手
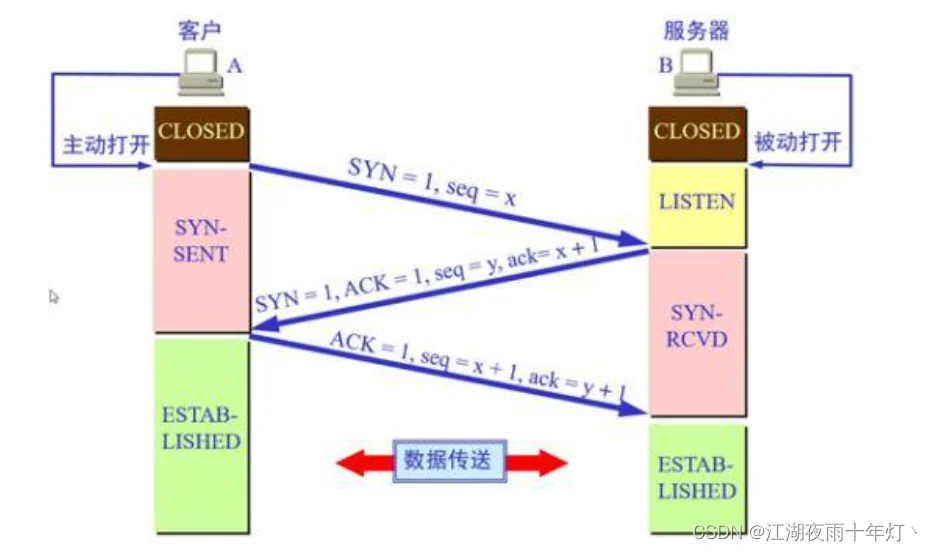
为什么是三次握手,不是两次和四次?
- 主要原因:三次握手才可以阻止重复历史连接的初始化
- 三次握手才可以同步双方的初始化序列号
- 三次握手才可以避免资源浪费
两次握手无法放置历史连接的建立,会造成双方资源的浪费,也无法可靠的同步双方序列号四次握手:三次握手就已经理论上最少可靠连接建立,所以不需要使用更多的通信次数
为什么挥手需要四次:
- 假设关闭连接的时候,是客户端向服务端首先发送fin报文,仅仅表示客户端不再发送数据了但是还能接受数据
- 服务端收到客户端的fin报文之后,先回一个ack应答报文,而服务端还有可能还有数据要处理和发送,等服务端不再发送数据时,才发送fin报文给客户端表示同意现在关闭服务器到客户端的连接
(1)序号(sequencenumber):Seq序号,占32位,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记。
(2)确认号(acknowledgementnumber):Ack序号,占32位,只有ACK标志位为1时,确认序号字段才有效,Ack=Seq+1。
(3)标志位(Flags):共6个,即URG、ACK、PSH、RST、SYN、FIN等。

1、三次握手
2、四次挥手
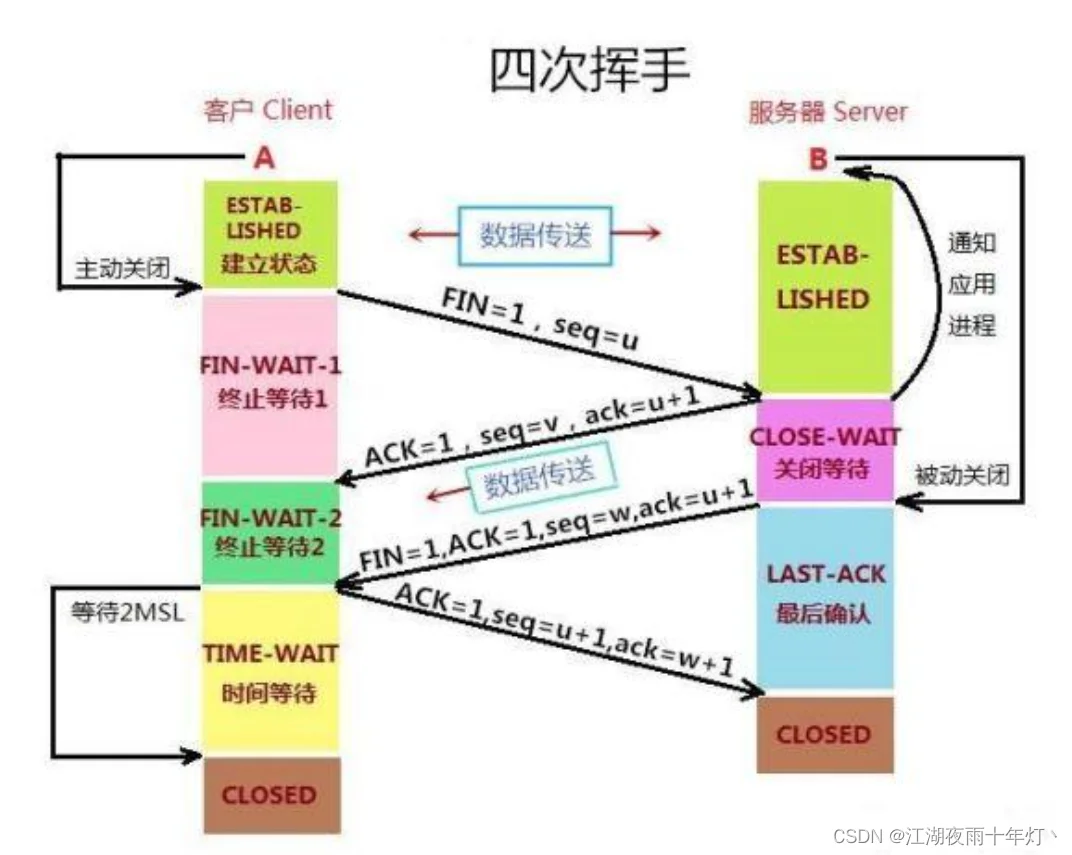
为什么客户端在time-wait阶段要等2msl?
当客户端发出最后的ACK确认报文时,并不能确定服务器端能够收到该段报文。所以客户端在发送完ACK确认报文之后,会设置一个时长为2MSL的计时器。MSL指的是MaximumSegmentLifetime:一段TCP报文在传输过程中的最大生命周期。2MSL即是服务器端发出为FIN报文和客户端发出的ACK确认报文所能保持有效的最大时长。
服务器端在1MSL内没有收到客户端发出的ACK确认报文,就会再次向客户端发出FIN报文;
如果客户端在2MSL内,再次收到了来自服务器端的FIN报文,说明服务器端由于各种原因没有接收到客户端发出的ACK确认报文。客户端再次向服务器端发出ACK确认报文,计时器重置,重新开始2MSL的计时
否则客户端在2MSL内没有再次收到来自服务器端的FIN报文,说明服务器端正常接收了ACK确认报文,客户端可以进入CLOSED阶段,完成“四次挥手”。
拥塞控制
慢启动:每次翻倍增加,涨到慢启动门限为止。
拥塞避免:当超过慢启动门限之后就开始拥塞避免算法,每次都是线性增长
拥塞发生:(如何判断拥塞何时发生:出现超时重传(重传计时器超时)以及快速重传(收到3个重复的ACK))
快速重传:快速重传的工作方式是当收到三个相同的ACK报文时,会在定时器过期之前,重传丢失的报文段。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H4vycpso-1652680479692)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220408195438875.png)]
TCP四元组
源IP地址、目的IP地址、源端口、目的端口
五元组
源IP地址、目的IP地址、协议号、源端口、目的端口
七元组
源IP地址、目的IP地址、协议号、源端口、目的端口,服务类型以及接口索引
视频面试用的是TCP还是UDP
tcp需要进行三次握手,建立会话需要时间,tcp在网络拥塞的情况下会进行tcp全局同步,根据网络带宽调整tcp滑动窗口大小,引起tcp传输速度下降,甚至有可能会导致tcp报文没有带宽可用,导致tcp饿死,而视频传输对带宽的需求比较大,对时延要求比较高,对丢包率要求不是那么高,udp是面向无连接的传输协议,不需要进行三次握手,也没有tcp的滑动窗口,报文也比tcp小,正好满足了对视频传输的要求。
TCP异常
1.试图与一个主机上的不存在的端口建立连接
这符合触发发送RST分节的条件,目的为某端口的SYN分节到达,而端口没有监听,那么内核会立即响应一个RST,表示出错。客户端TCP收到这个RST之后则放弃这次连接的建立,并且返回给应用程序一个错误。正如上面所说的,建立连接的过程对应用程序来说是不可见的,这是操作系统帮我们来完成的,所以即使进程没有启动,也可以响应客户端。
2.试图与一个不存在的主机上的某端口建立连接
这也是一种比较常见的情况,当某台服务器主机宕机了,而客户端并不知道,仍然尝试去与其建立连接。根据上面的经验,这次主机已经处于未启动状态,操作系统也帮不上忙了,那么也就是连RST也不能响应给客户端,此时服务器端是一种完全没有响应的状态。那么此时客户端的TCP会怎么办呢?据书上介绍,如果客户端TCP没有得到任何响应,那么等待6s之后再发一个SYN,若无响应则等待24s再发一个,若总共等待了75s后仍未收到响应就会返回ETIMEDOUT错误。这是TCP建立连接自己的一个保护机制,但是我们要等待75s才能知道这个连接无法建立,对于我们所有服务来说都太长了。更好的做法是在代码中给connect设置一个超时时间,使它变成我们可控的,让等待时间在毫秒级还是可以接收的。
3.Server进程被阻塞
由于某些情况,服务器端进程无法响应任何请求,比如所在主机的硬盘满了,导致进程处于完全阻塞,通常我们测试时会用gdb模拟这种情况。上面提到过,建立连接的过程对应用程序是不可见的,那么,这时连接可以正常建立。当然,客户端进程也可以通过这个连接给服务器端发送请求,服务器端TCP会应答ACK表示已经收到这个分节(这里的收到指的是数据已经在内核的缓冲区里准备好,由于进程被阻塞,无法将数据从内核的缓冲区复制到应用程序的缓冲区),但永远不会返回结果。
Http和Https
即超文本传输协议和超文本传输安全协议
运行在TCP之上
http和https的区别
- HTTP是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS则解决HTTP不安全的缺陷,在TCP和HTTP网络层之间加入了SSL/TLS安全协议,使得报文能够加密传输。
- HTTP连接建立相对简单,TCP三次握手之后便可进行HTTP的报文传输。而HTTPS在TCP三次握手之后,还需进行SSL/TLS的握手过程,才可进入加密报文传输。
- HTTP的端口号是80,HTTPS的端口号是443。
- HTTPS协议需要向CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
HTTP状态码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gGEdri9o-1652680479692)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413172215330.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ri3d4xHo-1652680479693)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413172234095.png)]
HTTP报文
HTTP协议主要由三大部分组成:
起始行(startline)头部字段(header)消息正文(entity)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uu0r4TeG-1652680479693)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413173248187.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ND8Okz0U-1652680479693)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413173305348.png)]
HTTP请求方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ehjKEkVb-1652680479693)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413173017199.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QWmbx1Ql-1652680479694)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413173046983.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WTTNnRE9-1652680479694)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413173107486.png)]
DNS
浏览器中输入URL到返回页面的全过程
- 1.根据域名,进行DNS域名解析;
- 2.拿到解析的IP地址,建立TCP连接;
- 3.向IP地址,发送HTTP请求;
- 4.服务器处理请求;
- 5.返回响应结果;
- 6.关闭TCP连接;
- 7.浏览器解析HTML;
- 8.浏览器布局渲染;
DNS服务器间进行域传输的时候用TCP53
客户端查询DNS服务器时用UDP53
DNS查询超过512字节
TC标志出现,使用TCP发送
arp协议
arp协议在TCP/IP模型中属于IP层(网络层),在OSI模型中属于链路层。
计算机中会维护一个ARP缓存表,这个表记录着IP地址与MAC地址的映射关系,我们可以通过在电脑的控制台通过arp-a指令查看一下我们自己计算机的ARP缓存表。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GkjgW57Y-1652680479694)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220411151053731.png)]
静态映射需要管理员手工建立和维护
动态映射不需要管理员手工建立和维护
mac地址又称物理地址,以太网地址。
IP地址MAC地址ARP协议IP地址转换成MAC地址ARP协议的主要工作就是建立、查询、更新、删除ARP表项。
工作原理
(1)每台主机都会在自己的ARP缓冲区建立一个ARP列表,以表示IP地址和MAC地址的对应关系。当源主机需要将一个数据包发送到目的主机时,会先检查自己的ARP列表中是否存在该IP地址对应的MAC地址,如果有,就直接将数据包发送到这个MAC地址;如果没有,就向本地网段发起一个ARP请求的广播包,查询此目的主机对应的MAC地址。此ARP请求数据包里包括源主机的IP地址,硬件地址,以及目的主机的IP地址。
(2)网络中所有主机收到这个ARP请求之后,会检查数据包中的目的IP是否和自己的IP地址一致,如果不一致就忽略此数据包;如果相同,该主机首先将发送端的MAC地址和IP地址添加到自己的ARP列表中,如果ARP列表中已经存在该IP的信息,则将其覆盖,然后将自己的MAC地址写入ARP响应数据包中发送给源主机,告诉源主机自己是它想要找的MAC地址。给源主机发送一个ARP响应数据包
(3)源主机收到这个ARP响应数据包之后,将得到的目的主机的IP地址和MAC地址添加到自己的ARP列表中,并利用此信息开始数据的传输。如果源主机一直没有收到ARP响应数据包,表示ARP查询失败。
报文格式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XLe1RqTW-1652680479695)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220411151655873.png)]
rarp协议
反向地址转换协议
ARP(地址解析协议)是设备通过自己知道的IP地址来获得自己不知道的物理地址的协议。
工作原理
- 发送主机发送一个本地的RARP广播,在此广播包中,声明自己的MAC地址并且请求任何收到此请求的RARP服务器分配一个IP地址;
- 本地网段上的RARP服务器收到此请求后,检查其RARP列表,查找该MAC地址对应的IP地址;
- 如果存在,RARP服务器就给源主机发送一个响应数据包并将此IP地址提供给对方主机使用;
- 如果不存在,RARP服务器对此不做任何的响应;
- 源主机收到从RARP服务器的响应信息,就利用得到的IP地址进行通讯;如果一直没有收到RARP服务器的响应信息,表示初始化失败。
ARP把逻辑(IP)地址映射为物理地址。RARP把物理地址映射为逻辑(IP)地址。
网络连接的三种模式
1.桥接模式,虚拟系统和外部系统通讯,但是容易造成IP冲突
2.NAT模式,网络地址转换模式,虚拟系统可以和外部系统通讯,不造成IP冲突
3.主机模式,独立的系统
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CQqq5W6y-1652680479695)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220411205333679.png)]
公钥加密算法
操作系统
Linux命令
常用指令
ls 显示文件或目录
-l列出文件详细信息l(list)
-a列出当前目录下所有文件及目录,包括隐藏的a(all)
mkdir创建目录
-p创建目录,若无父目录,则创建p(parent)
cd切换目录
touch创建空文件
echo创建带有内容的文件。
cat查看文件内容
cp拷贝
mv移动或重命名
rm删除文件
-r递归删除,可删除子目录及文件
-f强制删除
find在文件系统中搜索某文件
wc统计文本中行数、字数、字符数
grep在文本文件中查找某个字符串
rmdir删除空目录
tree树形结构显示目录,需要安装tree包
pwd显示当前目录
ln创建链接文件
more、less分页显示文本文件内容
head、tail显示文件头、尾内容
ctrl+alt+F1命令行全屏模式
系统管理命令
stat显示指定文件的详细信息,比ls更详细
who显示在线登陆用户
whoami显示当前操作用户
hostname显示主机名
uname显示系统信息
top动态显示当前耗费资源最多进程信息
ps显示瞬间进程状态ps-aux
du查看目录大小du-h/home带有单位显示目录信息
df查看磁盘大小df-h带有单位显示磁盘信息
ifconfig查看网络情况
ping测试网络连通
netstat显示网络状态信息
man命令不会用了,找男人如:manls
clear清屏
alias对命令重命名如:aliasshowmeit="ps-aux",另外解除使用unaliaxshowmeit
kill杀死进程,可以先用ps或top命令查看进程的id,然后再用kill命令杀死进程。
打包压缩命令
gzip:
bzip2:
tar:打包压缩
-c归档文件
-x压缩文件
-zgzip压缩文件
-jbzip2压缩文件
-v显示压缩或解压缩过程v(view)
-f使用档名
例:
tar-cvf/home/abc.tar/home/abc只打包,不压缩
tar-zcvf/home/abc.tar.gz/home/abc打包,并用gzip压缩
tar-jcvf/home/abc.tar.bz2/home/abc打包,并用bzip2压缩
当然,如果想解压缩,就直接替换上面的命令tar-cvf/tar-zcvf/tar-jcvf中的“c”换成“x”就可以了。
关机/重启机器
shutdown
-r关机重启
-h关机不重启
now立刻关机
halt关机
reboot重启
Linux管道
将一个命令的标准输出作为另一个命令的标准输入。也就是把几个命令组合起来使用,后一个命令除以前一个命令的结果。
例:grep-r"close"/home/*|more在home目录下所有文件中查找,包括close的文件,并分页输出。
Linux软件包管理
dpkg(DebianPackage)管理工具,软件包名以.deb后缀。这种方法适合系统不能联网的情况下。
比如安装tree命令的安装包,先将tree.deb传到Linux系统中。再使用如下命令安装。
sudodpkg-itree_1.5.3-1_i386.deb安装软件
sudodpkg-rtree卸载软件
注:将tree.deb传到Linux系统中,有多种方式。VMwareTool,使用挂载方式;使用winSCP工具等;
APT(AdvancedPackagingTool)高级软件工具。这种方法适合系统能够连接互联网的情况。
依然以tree为例
sudoapt-getinstalltree安装tree
sudoapt-getremovetree卸载tree
sudoapt-getupdate更新软件
sudoapt-getupgrade
将.rpm文件转为.deb文件
.rpm为RedHat使用的软件格式。在Ubuntu下不能直接使用,所以需要转换一下。
sudoalienabc.rpm
vim使用
im三种模式:命令模式、插入模式、编辑模式。使用ESC或i或:来切换模式。
命令模式下:
:q退出
:q!强制退出
:wq保存并退出
:setnumber显示行号
:setnonumber隐藏行号
/apache在文档中查找apache按n跳到下一个,shift+n上一个
yyp复制光标所在行,并粘贴
h(左移一个字符←)、j(下一行↓)、k(上一行↑)、l(右移一个字符→)
用户管理
/etc/passwd存储用户账号
/etc/group存储组账号
/etc/shadow存储用户账号的密码
/etc/gshadow存储用户组账号的密码
useradd用户名
userdel用户名
adduser用户名
groupadd组名
groupdel组名
passwdroot给root设置密码
suroot
su-root
/etc/profile系统环境变量
bash_profile用户环境变量
.bashrc用户环境变量
suuser切换用户,加载配置文件.bashrc
su-user切换用户,加载配置文件/etc/profile,加载bash_profile
更改文件的用户及用户组
sudochown[-R]owner[:group]{File|Directory}
例如:还以jdk-7u21-linux-i586.tar.gz为例。属于用户hadoop,组hadoop
要想切换此文件所属的用户及组。可以使用命令。
sudochownroot:rootjdk-7u21-linux-i586.tar.gz
进程线程协程
操作系统为了跟踪每个进程的活动状态,维护了一个进程表。进程表的内部列出了每个进程的状态以及每个进程使用的资源等。
进程:正在执行程序的一个实例,是资源分配的基本单位。(进程控制块(processcontrolblock)描述进程的基本信息和运行状态,所谓的创建和撤销进程,都是指对PCB的操作)
线程:进程中的单条流向,是程序独立调度的基本单位。
进程和线程的区别
- (拥有资源)一个进程可以有多个线程,由于线程不拥有资源,这几个线程共享进程内的资源。
- (资源开销)创建和撤销线程比进程开销小很多,因为创建线程仅仅需要堆栈空间以及程序计数器就可以了而创建进程需要分配虚拟地址空间,数据资源等,开销比较大。
- (调度)由于线程是独立调度的基本单位,同一进程中线程的切换不会引起进程的切换,但是两个不同进程中的线程切换会引起进程切换。
- (通信)线程可以通过直接读写同一进程中的数据进行通信,但是进程通信需要借助IPC。
- 进程是资源分配的基本单位,线程是独立运行和独立调度的基本单位(CPU上真正运行的是线程)
线程和协程推荐在IO密集型的任务(比如网络调用)中使用,而在CPU密集型的任务中,表现较差。
为什么进程切换开销大
进程切换与线程切换的一个最主要区别就在于进程切换涉及到虚拟地址空间的切换而线程切换则不会。因为每个进程都有自己的虚拟地址空间,而线程是共享所在进程的虚拟地址空间的,因此同一个进程中的线程进行线程切换时不涉及虚拟地址空间的转换。
进程之间如何通信
-
消息队列:消息队列是内核中存储消息的链表,它由消息队列标识符进行标识,这种方式能够在不同的进程中间提供全双工通信连接
-
管道:用于两个相关进程间通信,是一种半双工的通信方式,只能在父子进程中使用,如果需要全双工,需要另外的一个管道。
-
套接字:与其他通信方式不同,可以用于不同机器之间的进程通信。
-
信号量:是一个计数器,用于为多个进程提供对共享数据对象的访问
-
共享内存:使用所有进程的内存来建立连接,不过需要同步进程(信号量)来保护访问。是最快的IPC方式。
-
消息传递:消息传递是进程间实现通信和同步等待的机制。消息直接由发送方传递给接收方。
-
远程调用RPC
-
管道/匿名管道(Pipes):用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
-
有名管道(NamesPipes):匿名管道由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道。有名管道严格遵循先进先出(firstinfirstout)。有名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。
-
信号(Signal):信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
-
消息队列(MessageQueuing):消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显示地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比FIFO更有优势。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺。
-
信号量(Semaphores):信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
-
共享内存(Sharedmemory):使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
-
套接字(Sockets):此方法主要用于在客户端和服务器之间通过网络进行通信。套接字是支持TCP/IP的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
全双工、半双工和单工
全双工通信允许数据同时在两个方向上传输,即有两个信道,因此允许同时进行双向传输。全双工通信是两个单工通信方式的结合,要求收发双方都有独立的接收和发送能力。
半双工通信允许信号在两个方向上传输,但某一时刻只允许信号在一个信道上单向传输。半双工通信实际上是一种可切换方向的单工通信。
单工通信只支持信号在一个方向上传输(正向或反向),任何时候不能改变信号的传输方向。
进程的生命周期
- 创建状态:系统已为其分配了PCB,但进程所需资源尚未分配,进程还未进入主存,即创建工作尚未完成,进程还不能被调度运行。
- 就绪状态:进程已分配到除CPU以外打的所有必要资源,等待获得CPU。
- 执行状态:进程已获得CPU,程序正在执行。
- 阻塞状态:正在执行的进程由于某事件而暂时无法继续执行时,放弃处理机而自行阻塞。
- 终止状态:进程到达自然结束点或者因意外被终结,将进入终止状态,进入终止状态的进程不能再执行,但在操作系统中仍然保留着一个记录,其中保存状态码和一些计时统计数据,供其它进程收集。
进程调度
当两个或两个以上的进程/线程处于就绪状态时,如果只有一个CPU可用,那么必须选择接下来哪个进程/线程可以运行,操作系统中有一个叫做调度程序(scheduler)的角色存在就是做这件事的。
不同的系统中,调度算法是不同的,有如下3种情况:
- 批处理
- 先来先服务
- 最短作业有限
- 最短剩余时间优先
- 交互式
- 轮询调度(时间片轮转调度算法)
- 优先级调度
- 多级队列
- 最短进程优先
- 保证调度
- 彩票调度
- 公平分享调度
- 实时
- 单比率调度
- 限期调度
- 最少裕度法
并发与并行
并发:在操作系统中,某一时间段,几个程序在同一个CPU上运行,但在任意一个时间点上,只有一个程序在CPU上运行。
并行:当操作系统有多个CPU时,一个CPU处理A线程,另一个CPU处理B线程,两个线程互相不抢占CPU资源,可以同时进行,这种方式成为并行。
注意点:并发的关键是你有处理多个任务的能力,不一定要同时。并行的关键是你有同时处理多个任务的能力。所以我认为它们最关键的点就是:是否是『同时』
一个让人更加容易理解的例子:
- 你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
- 你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
- 你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
线程共享与不共享
共享的:
- 堆。由于堆是在进程空间中开辟出来的,所以它是理所当然地被共享的;因此new出来的都是共享的(16位平台上分全局堆和局部堆,局部堆是独享的)
- 全局变量。它是与具体某一函数无关的,所以也与特定线程无关;因此也是共享的
- 静态变量。虽然对于局部变量来说,它在代码中是“放”在某一函数中的,但是其存放位置和全局变量一样,存于堆中开辟的.bss和.data段,是共享的
- 文件等公用资源。这个是共享的,使用这些公共资源的线程必须同步。Win32提供了几种同步资源的方式,包括信号、临界区、事件和互斥体。
独享的:
- 栈。栈是独享的
- 寄存器。这个可能会误解,因为电脑的寄存器是物理的,每个线程去取值难道不一样吗?其实线程里存放的是副本,包括程序计数器PC
僵尸进程,孤儿进程
僵尸进程:子进程退出了,但是父进程没有用wait或waitpid去获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中,这种进程称为僵尸进程。
孤儿进程:父进程结束了,而它的一个或多个子进程还在运行,那么这些子进程就成为孤儿进程(fatherdied)。子进程的资源由init进程(进程号PID=1)回收。
如何解决僵尸进程和孤儿进程
既然所有进程都必须在退出之后被wait()或waitpid()以释放其遗留在系统中的一些资源,那么应该由谁来处理孤儿进程的善后事宜呢?这个重任就落到了init进程身上,init进程就好像是一个民政局,专门负责处理孤儿进程的善后工作。每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程“凄凉地”结束了其生命周期的时候,init进程就会代表党和政府出面处理它的一切善后工作。这样来看,孤儿进程并不会有什么危害,真正会对系统构成威胁的是僵尸进程。那么,什么情况下僵尸进程会威胁系统的稳定呢?设想有这样一个父进程:它定期的产生一个子进程,这个子进程需要做的事情很少,做完它该做的事情之后就退出了,因此这个子进程的生命周期很短,但是,父进程只管生成新的子进程,至于子进程退出之后的事情,则一概不闻不问,这样,系统运行上一段时间之后,系统中就会存在很多的僵尸进程,倘若用ps命令查看的话,就会看到很多状态为Z的进程。严格地来说,僵尸进程并不是问题的根源,罪魁祸首是产生出大量僵尸进程的那个父进程。因此,当我们寻求如何消灭系统中大量的僵尸进程时,答案就是把产生大量僵尸进程的那个元凶枪毙掉(通过kill发送SIGTERM或者SIGKILL信号)。枪毙了元凶进程之后,它产生的僵尸进程就变成了孤儿进程,这些孤儿进程会被init进程接管,init进程会wait()这些孤儿进程,释放它们占用的系统进程表中的资源,这样,这些已经“僵尸”的孤儿进程就能瞑目而去了。
进程池和线程池
池是保证计算机能够正常运行的前提下,能最大限度开采的资源的量,他降低的程序的运行效率,但是保证了计算机硬件的安全,从而让你写的程序可以正常运行。池就是一个量的单位,代表了你所能开采的资源的度,超过这个度,身体就跨了,首先要用,其次要有度。
区别
进程池是主程序结束就自动结束
线程池是主程序结束不影响线程池
IO模型
什么是IO
io即输入输出,涉及计算机核心与其他设备间数据迁移的过程,就是IO。
应用程序发起的一次IO操作包含两个阶段:
IO调用:应用程序进程向操作系统内核发起调用。
IO执行:操作系统内核完成IO操作。
操作系统内核完成IO操作还包括两个过程:
准备数据阶段:内核等待I/O设备准备好数据
拷贝数据阶段:将数据从内核缓冲区拷贝到用户进程缓冲区
一个完整的IO过程包括以下几个步骤:
应用程序进程向操作系统发起IO调用请求
操作系统准备数据,把IO外部设备的数据,加载到内核缓冲区
操作系统拷贝数据,即将内核缓冲区的数据,拷贝到用户进程缓冲区
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WTUqI4FS-1652680479701)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413204254032.png)]
阻塞IO与非阻塞IO
阻塞IO:
假设应用程序的进程发起IO调用,但是如果内核的数据还没准备好的话,那应用程序进程就一直在阻塞等待,一直等到内核数据准备好了,从内核拷贝到用户空间,才返回成功提示,此次IO操作,称之为阻塞IO。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1a3hoywq-1652680479701)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413204457463.png)]
阻塞IO比较经典的应用就是阻塞socket、JavaBIO。阻塞IO的缺点就是:如果内核数据一直没准备好,那用户进程将一直阻塞,浪费性能,可以使用非阻塞IO优化。
非阻塞IO:
如果内核数据还没准备好,可以先返回错误信息给用户进程,让它不需要等待,而是通过轮询的方式再来请求。这就是非阻塞IO。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sDbvJJbK-1652680479702)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413204601337.png)]
流程:
- 应用进程向操作系统内核,发起recvfrom读取数据。
- 操作系统内核数据没有准备好,立即返回EWOULDBLOCK错误码。
- 应用程序进程轮询调用,继续向操作系统内核发起recvfrom读取数据。
- 操作系统内核数据准备好了,从内核缓冲区拷贝到用户空间。
- 完成调用,返回成功提示。
非阻塞IO模型,简称NIO,Non-BlockingIO。它相对于阻塞IO,虽然大幅提升了性能,但是它依然存在性能问题,即频繁的轮询,导致频繁的系统调用,同样会消耗大量的CPU资源。可以考虑IO复用模型,去解决这个问题。
IO多路复用模型
既然NIO无效的轮询会导致CPU资源消耗,我们等到内核数据准备好了,主动通知应用进程再去进行系统调用,那不就好了嘛。
文件描述符fd(FileDescriptor),它是计算机科学中的一个术语,形式上是一个非负整数。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。
IO复用模型核心思路:系统给我们提供一类函数(如我们耳濡目染的select、poll、epoll函数),它们可以同时监控多个fd的操作,任何一个返回内核数据就绪,应用进程再发起recvfrom系统调用。
IO多路复用之select
应用进程通过调用select函数,可以同时监控多个fd,在select函数监控的fd中,只要有任何一个数据状态准备就绪了,select函数就会返回可读状态,这时应用进程再发起recvfrom请求去读取数据。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZvynsVrR-1652680479702)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413204941609.png)]
非阻塞IO模型(NIO)中,需要N(N>=1)次轮询系统调用,然而借助select的IO多路复用模型,只需要发起一次询问就够了,大大优化了性能。
但是呢,select有几个缺点:
监听的IO最大连接数有限,在Linux系统上一般为1024。
select函数返回后,是通过遍历fdset,找到就绪的描述符fd。(仅知道有I/O事件发生,却不知是哪几个流,所以遍历所有流)
因为存在连接数限制,所以后来又提出了poll。与select相比,poll解决了连接数限制问题。但是呢,select和poll一样,还是需要通过遍历文件描述符来获取已经就绪的socket。如果同时连接的大量客户端,在一时刻可能只有极少处于就绪状态,伴随着监视的描述符数量的增长,效率也会线性下降。
IO多路复用之epoll
epoll先通过epoll_ctl()来注册一个fd(文件描述符),一旦基于某个fd就绪时,内核会采用回调机制,迅速激活这个fd,当进程调用epoll_wait()时便得到通知。这里去掉了遍历文件描述符的坑爹操作,而是采用监听事件回调的机制。这就是epoll的亮点。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J68gXLpq-1652680479702)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413205151267.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vYhccGLw-1652680479702)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413205221360.png)]
epoll明显优化了IO的执行效率,但在进程调用epoll_wait()时,仍然可能被阻塞。
IO模型之信号驱动模型
信号驱动IO不再用主动询问的方式去确认数据是否就绪,而是向内核发送一个信号(调用sigaction的时候建立一个SIGIO的信号),然后应用用户进程可以去做别的事,不用阻塞。当内核数据准备好后,再通过SIGIO信号通知应用进程,数据准备好后的可读状态。应用用户进程收到信号之后,立即调用recvfrom,去读取数据。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j55CMJN9-1652680479703)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413205435750.png)]
信号驱动IO模型,在应用进程发出信号后,是立即返回的,不会阻塞进程。它已经有异步操作的感觉了。但是你细看上面的流程图,发现数据复制到应用缓冲的时候,应用进程还是阻塞的。回过头来看下,不管是BIO,还是NIO,还是信号驱动,在数据从内核复制到应用缓冲的时候,都是阻塞的。
IO模型之异步IO(AIO)
前面讲的BIO,NIO和信号驱动,在数据从内核复制到应用缓冲的时候,都是阻塞的,因此都不算是真正的异步。AIO实现了IO全流程的非阻塞,就是应用进程发出系统调用后,是立即返回的,但是立即返回的不是处理结果,而是表示提交成功类似的意思。等内核数据准备好,将数据拷贝到用户进程缓冲区,发送信号通知用户进程IO操作执行完毕。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5QIWkFt1-1652680479703)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413205541082.png)]
异步IO的优化思路很简单,只需要向内核发送一次请求,就可以完成数据状态询问和数据拷贝的所有操作,并且不用阻塞等待结果。日常开发中,有类似思想的业务场景:
比如发起一笔批量转账,但是批量转账处理比较耗时,这时候后端可以先告知前端转账提交成功,等到结果处理完,再通知前端结果即可。
阻塞、非阻塞、同步、异步IO划分
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8sL29xYz-1652680479703)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413205614217.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zbJFDOvo-1652680479704)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413205729465.png)]
一个通俗例子读懂BIO、NIO、AIO
同步阻塞(blocking-IO)简称BIO
同步非阻塞(non-blocking-IO)简称NIO
异步非阻塞(asynchronous-non-blocking-IO)简称AIO
一个经典生活的例子:
小明去吃同仁四季的椰子鸡,就这样在那里排队,等了一小时,然后才开始吃火锅。(BIO)
小红也去同仁四季的椰子鸡,她一看要等挺久的,于是去逛会商场,每次逛一下,就跑回来看看,是不是轮到她了。于是最后她既购了物,又吃上椰子鸡了。(NIO)
小华一样,去吃椰子鸡,由于他是高级会员,所以店长说,你去商场随便逛会吧,等下有位置,我立马打电话给你。于是小华不用干巴巴坐着等,也不用每过一会儿就跑回来看有没有等到,最后也吃上了美味的椰子鸡(AIO)
死锁
死锁一般发生在多线程(两个或两个以上)执行的过程中。因为争夺资源造成线程之间相互等待,这种情况就产生了死锁。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-960mje8A-1652680479704)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413202418326.png)]
比如你有资源1和2,以及线程A和B,当线程A在已经获取到资源1的情况下,期望获取线程B持有的资源2。与此同时,线程B在已经获取到资源2的情况下,期望获取现场A持有的资源1。
那么线程A和线程B就处理了相互等待的死锁状态,在没有外力干预的情况下,线程A和线程B就会一直处于相互等待的状态,从而不能处理其他的请求。
死锁产生的必要条件
1、互斥:多个线程不能同时使用一个资源。比如线程A已经持有的资源,不能再同时被线程B持有。如果线程B请求获取线程A已经占有的资源,那线程B只能等待这个资源被线程A释放。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B38fv2Zg-1652680479704)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413202651577.png)]
2、持有并等待:当线程A已经持有了资源1,又提出申请资源2,但是资源2已经被线程C占用,所以线程A就会处于等待状态,但它在等待资源2的同时并不会释放自己已经获取的资源1。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VFKASsdc-1652680479705)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413202657952.png)]
3、线程A获取到资源1之后,在自己使用完之前不能被其他线程(比如线程B)抢占使用。如果线程B也想使用资源1,只能在线程A使用完后,主动释放后再获取。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4eicFOX5-1652680479705)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413202703240.png)]
4、发生死锁时,必然会存在一个线程,也就是资源的环形链。比如线程A已经获取了资源1,但同时又请求获取资源2。线程B已经获取了资源2,但同时又请求获取资源1,这就会形成一个线程和资源请求等待的环形图。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J7b3lrXQ-1652680479705)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413202709025.png)]
如何解决死锁
并发场景下一旦死锁,一般没有特别好的方法,很多时候只能重启应用。因此,最好是规避死锁,那么具体怎么做呢?答案是:至少破坏其中一个条件(互斥必须满足,你可以从其他三个条件出发)。
持有并等待:我们可以一次性申请所有的资源,这样就不存在等待了。
不可剥夺:占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源,这样不可剥夺这个条件就破坏掉了。
循环等待:可以靠按序申请资源来预防,也就是所谓的资源有序分配原则,让资源的申请和使用有线性顺序,申请的时候可以先申请资源序号小的,再申请资源序号大的,这样的线性化操作就自然就不存在循环了。
阻塞与非阻塞
- 阻塞是指调用线程或者进程被操作系统挂起。
- 非阻塞是指调用线程或者进程不会被操作系统挂起。
同步与异步
同步是阻塞模式,异步是非阻塞模式。
- 同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去;
- 异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。当有消息返回式系统会通知进程进行处理,这样可以提高执行的效率。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b0rUdqVO-1652680479705)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413203359868.png)]
epoll底层实现
epoll是一种更加高效的IO多路复用的方式,它可以监视的文件描述符数量突破了1024的限制(十万),同时不需要通过轮询遍历的方式去检查文件描述符上是否有事件发生,因为epoll_wait返回的就是有事件发生的文件描述符。本质上是事件驱动。
具体是通过红黑树和就绪链表实现的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EaGVtX3z-1652680479706)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220413203550548.png)]
fork
在Linux中fork函数是非常重要的函数,它的作用是从已经存在的进程中创建一个子进程,而原进程称为父进程。
fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LTIlrTPg-1652680479706)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220414154346040.png)]
调用fork(),当控制转移到内核中的fork代码后,内核开始做:
1.分配新的内存块和内核数据结构给子进程。
2.将父进程部分数据结构内容拷贝至子进程。
3.将子进程添加到系统进程列表。
4.fork返回开始调度器,调度。
数据结构
1.LRU缓存机制
type LRUCachestruct{
size int
capacity int
cachemap[int]*DLinkedNode
head,tail*DLinkedNode
}
type DLinkedNodestruct{
key,value int
prev,next* DLinkedNode
}
func initDLinkedNode(key,valueint) *DLinkedNode{
return &DLinkedNode{
key:key,
value:value,
}
}
func Constructor(capacityint) LRUCache{
l:=LRUCache{
cache:map[int]*DLinkedNode{},
head:initDLinkedNode(0,0),
tail:initDLinkedNode(0,0),
capacity:capacity,
}
l.head.next=l.tail
l.tail.prev=l.head
return l
}
func(this*LRUCache)Get(keyint)int{
if_,ok:=this.cache[key];!ok{
return -1
}
node:=this.cache[key]
this.moveToHead(node)
return node.value
}
func(this*LRUCache)Put(keyint,valueint){
if_,ok:=this.cache[key];!ok{
node:=initDLinkedNode(key,value)
this.cache[key]=node
this.addToHead(node)
this.size++
if this.size>this.capacity{
removed:=this.removeTail()
delete(this.cache,removed.key)
this.size--
}
}else{
node:=this.cache[key]
node.value=value
this.moveToHead(node)
}
}
func(this*LRUCache)addToHead(node*DLinkedNode){
node.prev=this.head
node.next=this.head.next
this.head.next.prev=node
this.head.next=node
}
func(this*LRUCache)removeNode(node*DLinkedNode){
node.prev.next=node.next
node.next.prev=node.prev
}
func(this*LRUCache)moveToHead(node*DLinkedNode){
this.removeNode(node)
this.addToHead(node)
}
func(this*LRUCache)removeTail()*DLinkedNode{
node:=this.tail.prev
this.removeNode(node)
return node
}
注意不要遗漏以下几点。
1、cache:map[int]*DLinkedNode{}的括号
2、node.value=value覆盖后给node赋新值
3、this.cache[key]=node插入链表时,将初始化的链表赋给哈希表
4、delete(this.cache,removed.key)超出容量后删除哈希表
2.二叉树
2.1树的层序遍历
func levelOrder(root*TreeNode)[][]int{
num:=[][]int{}
if root==nil{
return num
}
start:=[]*TreeNode{root} //结构体类型切片
for i:=0;len(start)>0;i++{ //开始遍历
replace:=[]*TreeNode{}
num=append(num,[]int{}) //向二维数组切片中增加一个空数组
for j:=0;j<len(start);j++{ //遍历该层
node:=start[j]
num[i]=append(num[i],node.Val)
if node.Left!=nil{
replace=append(replace,node.Left)
}
if node.Right!=nil{
replace=append(replace,node.Right)
}
}
start=replace //替换成下一层结点
}
return num
}
2.2二叉树的锯齿形层序遍历
funcreverse(array[]int){
head:=0
end:=len(array)-1
for;head<end;{
array[head],array[end]=array[end],array[head]
head++
end--
}
}
funczigzagLevelOrder(root*TreeNode)[][]int{
result:=[][]int{}
ifroot==nil{
returnresult
}
tree:=[]*TreeNode{root}
fori:=0;len(tree)>0;i++{
newtree:=[]*TreeNode{}
result=append(result,[]int{})
forj:=0;j<len(tree);j++{
node:=tree[j]
result[i]=append(result[i],node.Val)
ifnode.Left!=nil{
newtree=append(newtree,node.Left)
}
ifnode.Right!=nil{
newtree=append(newtree,node.Right)
}
}
tree=newtree
}
fori:=0;i<len(result);i++{
ifi%2==1{
reverse(result[i])
}
}
returnresult
}
2.3中序遍历
funcinorder(root*TreeNode,result*[]int){
ifroot!=nil{
inorder(root.Left,result)
*result=append(*result,root.Val)
inorder(root.Right,result)
}
}
funcinorderTraversal(root*TreeNode)[]int{
result:=[]int{}
inorder(root,&result)
returnresult
}
2.4树形DP
美团最优二叉树
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XKl3I923-1652680479709)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220401203811557.png)]
package main
import(
"fmt"
)
varans[301][301][301]int
varnums[301]int
func main(){
var N int
fmt.Scanln(&N)
for i:=1;i<=N;i++{
fmt.Scan(&nums[i])
}
result:=dp(1,N,0) //0为虚拟节点
fmt.Println(result)
}
funcdp(headint,endint,fatherint)int{
ifhead>end{
return 0
}
ifans[head][end][father]!=0{
returnans[head][end][father]
}
ret:=999999999
fori:=head;i<=end;i++{ //每个节点都可能做根
left:=dp(head,i-1,i) //i做节点时,左子树的开销
right:=dp(i+1,end,i) //i做节点时,右子树的开销
ret=min(ret,left+right+nums[i]*nums[father])//总开销要加上根节点*父节点
}
ans[head][end][father]=ret
returnans[head][end][father]
}
funcmin(a,bint)int{
ifa>b{
returnb
}
returna
}
二叉树的右视图
func rightSideView(root *TreeNode) []int {
num:=[][]int{}
res:=[]int{}
if root==nil{
return res
}
start:=[]*TreeNode{root}
for i:=0;len(start)>0;i++{
newstart:=[]*TreeNode{}
num=append(num,[]int{})
for j:=0;j<len(start);j++{
node:=start[j]
num[i]=append(num[i],node.Val)
if node.Left!=nil{
newstart=append(newstart,node.Left)
}
if node.Right!=nil{
newstart=append(newstart,node.Right)
}
}
start=newstart
}
for i:=0;i<len(num);i++{
res=append(res,num[i][len(num[i])-1])
}
return res
}
3.反转链表II
func reverse(head*ListNode){
var pre *ListNode
curr:=head
for curr!=nil{
next:=curr.Next
curr.Next=pre
pre=curr
curr=next
}
}
func reverseBetween(head*ListNode,leftint,rightint)*ListNode{
frist:=&ListNode{Val:-1}
frist.Next=head
pre:=frist
for i:=1;i<left;i++{
pre=pre.Next
}
leftNode:=pre.Next
rightNode:=head
for j:=1;j<right;j++{
rightNode=rightNode.Next
}
end:=rightNode.Next
pre.Next=nil
rightNode.Next=nil
reverse(leftNode)
pre.Next=rightNode
leftNode.Next=end
return frist.Next
}
4.排序
1.冒泡排序
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rajIj8hf-1652680479709)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220401154206637.png)]
2.选择排序
第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。选择排序是不稳定的排序方法。
3.插入排序
插入排序(InsertionSorting)的基本思想是:把n个待排序的元素看成为一个有序表和一个无序表,开始时有序表中只包含一个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,把它的排序码依次与有序表元素的排序码进行比较,将它插入到有序表中的适当位置,使之成为新的有序表。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kP6ffSOH-1652680479709)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220401154340880.png)]
4.快速排序
funcQuickSort(headint,endint,array[]int){
left:=head //定义首尾
right:=end
pivot:=array[head] //取中点为划分点也可取首尾
for;left<right;{ //当首尾碰面后,代表结束
for;array[left]<pivot;{ //找到一个需要交换的点
left++
}
for;array[right]>pivot;{
right--
}
ifleft>=right{ //相遇则结束本次循环
break
}
array[left],array[right]=array[right],array[left]
ifarray[left]==pivot{ //当有值和pivot相同时,左右指针无法碰面
right--
}
ifarray[right]==pivot{
left++
}
}
ifleft==right{ //走一步,切分
right--
left++
}
ifhead<right{
QuickSort(head,right,array)
}
ifend>left{
QuickSort(left,end,array)
}
}
5.三数之和
functhreeSum(nums[]int)[][]int{
result:=[][]int{}
n:=len(nums)
ifn<3{
returnresult
}
sort.Ints(nums)
fori:=0;i<n;i++{
ifi>0&&nums[i]==nums[i-1]{
continue
}
k:=n-1
forj:=i+1;j<n;j++{
ifj>i+1&&nums[j]==nums[j-1]{
continue
}
forj<k&&nums[i]+nums[j]+nums[k]>0{
k--
}
ifj==k{
break
}
ifnums[i]+nums[j]+nums[k]==0{
result=append(result,[]int{nums[i],nums[j],nums[k]})
}
}
}
returnresult
}
6.动态规划
何为动态规划?避免重复节点的计算,来加速节点的计算过程。空间换时间。带备忘录的递归。递归树的剪枝。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TaQU58w1-1652680479709)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220409153338917.png)]
1.暴力枚举(时间复杂度指数)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WT2iYXn2-1652680479710)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220409153618386.png)]
2.剪枝(用字典)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vTwVVoWn-1652680479710)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220409153751691.png)]
3.迭代(逆序思想)从后往前,类似数学归纳法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7o8MUKMr-1652680479710)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220409154044976.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oc32CUFy-1652680479710)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220409154313276.png)]
动态规划思想顺序
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BL15Ibip-1652680479711)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220409154350560.png)]
6.1最大子数组和
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kl9TH4EA-1652680479711)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220325210637389.png)]
f(i)=max{f(i−1)+nums[i],nums[i]}
funcmaxSubArray(nums[]int)int{
n:=len(nums)
max:=nums[0]
fori:=1;i<n;i++{
ifnums[i-1]>0{//计算f(i)
nums[i]+=nums[i-1]
}
ifmax<nums[i]{
max=nums[i]
}
}
returnmax
}
6.2买卖股票的最佳时机
funcmax(a,bint)int{
ifa>b{
returna
}
returnb
}
funcmin(a,bint)int{
ifa<b{
returna
}
returnb
}
funcmaxProfit(prices[]int)int{
result:=0
minvalue:=999999
n:=len(prices)
fori:=0;i<n;i++{
result=max(result,prices[i]-minvalue)
minvalue=min(minvalue,prices[i])
}
returnresult
}
6.3最长回文子串
暴力解法,从0开始递增检查每一段长度为n的子串是否为回文串
funclongestPalindrome(sstring)string{
n:=len(s)
ifn<2{
returns
}
dp:=make([][]bool,n)
fori,_:=rangedp{
dp[i]=make([]bool,n)
}
max:=""
forl:=0;l<n;l++{//l为本次循环遍历的子串长度
fori:=0;i<n-l;i++{
j:=i+l//j到达回文子串的最右边
ifl==0{
dp[i][j]=true//单个字符肯定是回文串
}elseifl==1{
dp[i][j]=(s[i]==s[j])
}else{
dp[i][j]=(s[i]==s[j]&&dp[i+1][j-1])//内部是回文串,加上外部一个条件
}
ifdp[i][j]&&l+1>len(max){//如果i到j是回文子串且子串长度大于max
max=s[i:j+1]
}
}
}
returnmax
}
最长递增子序列
暴力解
func lengthOfLIS(nums []int) int {
res:=0
dp:=make([]int,len(nums))
for i:=0;i<len(nums);i++{
dp[i]=1
for j:=0;j<i;j++{
if nums[i]>nums[j] && dp[j]+1>dp[i]{
dp[i]=dp[j]+1
}
}
if dp[i]>res{
res=dp[i]
}
}
return res
}
二分查找
func lengthOfLIS(nums []int) int {
dp:=[]int{}
for _,num:=range nums{
if len(dp)==0 || dp[len(dp)-1]<num{
dp=append(dp,num) //dp是一个单调递增的序列
}else{
l,r:=0,len(dp)-1
pos:=r
for l<=r{ //二分查找,将值替换到合适的位置
mid:=(l+r)/2
if dp[mid]>=num{
pos=mid
r=mid-1
}else{
l=mid+1
}
}
dp[pos]=num
}
}
return len(dp)
}
7.快慢指针
7.1环形链表
funchasCycle(head*ListNode)bool{
ifhead==nil||head.Next==nil{
returnfalse
}
slow,fast:=head,head.Next
forslow!=fast{
iffast==nil||fast.Next==nil{
returnfalse
}
slow=slow.Next
fast=fast.Next.Next
}
returntrue
}
8.哈希表
8.1环形链表
通过哈希表的键占位来实现目的
funchasCycle(head*ListNode)bool{
seen:=map[*ListNode]struct{}{}
forhead!=nil{
if_,ok:=seen[head];ok{
returntrue
}
seen[head]=struct{}{}
head=head.Next
}
returnfalse
}
8.2有效的括号
funcisValid(sstring)bool{
n:=len(s)
ifn%2==n{
returnfalse
}
dic:=map[byte]byte{
')':'(',
']':'[',
'}':'{',
}
stack:=[]byte{}
fori:=0;i<n;i++{
ifdic[s[i]]>0{
iflen(stack)==0||stack[len(stack)-1]!=dic[s[i]]{
returnfalse
}
stack=stack[:len(stack)-1]
}else{
stack=append(stack,s[i])
}
}
returnlen(stack)==0
}
9.大数相加
funcaddStrings(num1string,num2string)string{
add:=0
ans:=""
fori,j:=len(num1)-1,len(num2)-1;i>=0||j>=0||add!=0;i,j=i-1,j-1{
varx,yint
ifi>=0{
x=int(num1[i]-'0')
}
ifj>=0{
y=int(num2[j]-'0')
}
result:=x+y+add
ans=strconv.Itoa(result%10)+ans //得到其个位 切记ans要在后面
add=result/10 //进位
}
returnans
}
10.广义表
长度:去掉一层括号剩下的是几部分。
深度:去掉几层括号可以到最后一部分。
比如:例如E((a,(a,b),((a,b),c)))的长度和深度分别为1和4
11.图
京东完全多部图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R56Jxxsi-1652680479711)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220401202326272.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c0KjoB3P-1652680479711)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220401202337520.png)]
解题思想:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TBSdZYZQ-1652680479712)(C:\Users\杰\AppData\Roaming\Typora\typora-user-images\image-20220401202443391.png)]
func main(){
var T,N,M,X,Yint
fmt.Scanln(&T)
fori:=0;i<T;i++{
fmt.Scanln(&N,&M)
node:=make([][]int,N)
fori:=0;i<N;i++{
node[i]=make([]int,N)
}
forj:=0;j<M;j++{
fmt.Scanln(&X,&Y)
node[X-1][Y-1]=1
node[Y-1][X-1]=1
}
list:=[]int{}
fori:=0;i<N;i++{
list=append(list,i)
}
ifask(node,list){
fmt.Println("Yes")
}else{
fmt.Println("No")
}
}
}
fun cask(node[][]int,list[]int)bool{
iflen(list)<3{
returntrue
}
newlist:=[]int{}
newlist=append(newlist,list[0])
list=list[1:]
fori:=len(list)-1;i>=0;i--{ //这里要倒序,因为list是变化的
ifnode[list[i]][newlist[0]]==0{
newlist=append(newlist,list[i])
ifi==len(list)-1{
list=append(list[:i])
}else{
list=append(list[:i],list[i+1:]...) //注意越界
}
}
}
fori:=0;i<len(newlist);i++{
forj:=0;j<len(list);j++{
ifnode[list[j]][newlist[i]]==0{
returnfalse
}
}
}
returnask(node,list)
}
岛屿数量
func numIslands(grid [][]byte) int {
rows:=len(grid)
columns:=len(grid[0])
res:=0
for i:=0;i<rows;i++{
for j:=0;j<columns;j++{
if grid[i][j]=='1'{
res++
dfs(grid,i,j)
}
}
}
return res
}
func dfs(grid[][]byte, i,j int) {
rows:=len(grid)
columns:=len(grid[0])
if i>=rows ||i<0 || j<0|| j>=columns {
return
}
if grid[i][j]=='0' {
return
}
grid[i][j]='0'
dfs(grid,i-1,j)
dfs(grid,i+1,j)
dfs(grid,i,j-1)
dfs(grid,i,j+1)
}
字符串处理
字符串转换整数(atoi)
func myAtoi(s string) int {
if len(s)<1{
return 0
}
for s[0]==' '&&len(s)>1{
s=s[1:]
}
flag:=false
if s[0]=='-'{
flag=true
s=s[1:]
}else if s[0]=='+'{
s=s[1:]
}
if len(s)<1{
return 0
}
if s[0]<'0'||s[0]>'9'{
return 0
}
n:=len(s)
for i:=1;i<n;i++{
if s[i]<'0'||s[i]>'9'{
s=s[:i]
break
}
}
n=len(s)
flag2:=false
res:=0
for i:=0;i<n;i++{
res*=10
res+=int(s[i]-'0')
if res>math.MaxInt32{
flag2=true
break
}
}
if flag==true{
res=-res
}
if flag2==true{
if flag==true{
return math.MinInt32
}else{
return math.MaxInt32
}
}
return res
}
go循环输入
func main() {
var s int
for {
_,err:=fmt.Scan(&s)
if err!=nil {
break
}
}
fmt.Println(s)
}
go输入带有空格的字符串(大坑)
方法一:读入一行
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
reader := bufio.NewReader(os.Stdin)
res, _, err := reader.ReadLine()
if err!= nil {
fmt.Println(err)
}
fmt.Println(string(res))
}
方法二:读到回车结束
这个还是蛮好用的,可以指定读到什么结束
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
reader := bufio.NewReader(os.Stdin)
res,err := reader.ReadString('\n')
if err!= nil {
fmt.Println(err)
}
fmt.Println(string(res))
}
字符串相加
func addStrings(num1 string, num2 string) string {
add:=0 //进位
var res string
for i,j:=len(num1)-1,len(num2)-1;i>=0 ||j>=0||add!=0; i,j=i-1,j-1{
var x,y int
if i>=0{
x=int(num1[i]-'0')
}
if j>=0{
y=int(num2[j]-'0')
}
result:=x+y+add
res=strconv.Itoa(result%10)+res
add=result/10
}
return res
}
回溯问题
二叉树的最近公共祖先
func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
if root==nil{
return nil
}
if root.Val==p.Val || root.Val==q.Val{
return root
}
left:=lowestCommonAncestor(root.Left,p,q)
Right:=lowestCommonAncestor(root.Right,p,q)
if left!=nil&&Right!=nil{
return root
}
if left==nil {
return Right
}
return left
}
全排列
var res [][] int
func permute(nums []int) [][]int {
res=[][]int{}
backtrack(nums,len(nums),[]int{})
return res
}
func backtrack(nums []int,numslen int,path []int) {
if len(nums)==0{
p:=make([]int,len(path)) //path是地址引用,会改变
copy(p,path)
res=append(res,p)
}
for i:=0;i<numslen;i++{ //每次删完元素,添加完之后要加回去
cur:=nums[i]
path=append(path,cur)
nums=append(nums[:i],nums[i+1:]...)
backtrack(nums,len(nums),path)
nums=append(nums[:i],append([]int{cur},nums[i:]...)...)
path=path[:len(path)-1]
}
}
螺旋矩阵
func spiralOrder(matrix [][]int) []int {
rows:=len(matrix) //行
columns:=len(matrix[0]) //列
res:=make([]int,rows*columns) //定义新数组
left,right,top,bottom:=0,columns-1,0,rows-1 //定义初始边界
index:=0
for left<=right && top<=bottom {
for i:=left;i<=right;i++{
res[index]=matrix[top][i]
index++
}
for j:=top+1;j<=bottom;j++{
res[index]=matrix[j][right]
index++
}
if left<right &&top<bottom{
for i:=right-1;i>left;i--{
res[index]=matrix[bottom][i]
index++
}
for j:=bottom;j>top;j--{
res[index]=matrix[j][left]
index++
}
}
left++
right--
top++
bottom--
}
return res
}
删除排序链表中的重复元素II
func deleteDuplicates(head *ListNode) *ListNode {
if head==nil{
return nil
}
dummy:= &ListNode{0,head}
curr:=dummy
for curr.Next!=nil && curr.Next.Next!=nil{
if curr.Next.Val==curr.Next.Next.Val{
x:=curr.Next.Val
for curr.Next!=nil && curr.Next.Val==x{
curr.Next=curr.Next.Next
}
}else{
curr=curr.Next
}
}
return dummy.Next
}
递归
合并两个有序链表
func mergeTwoLists(list1 *ListNode, list2 *ListNode) *ListNode {
if list1==nil{
return list2
}
if list2==nil{
return list1
}
if list1.Val<list2.Val{
list1.Next=mergeTwoLists(list1.Next,list2)
return list1
}else{
list2.Next=mergeTwoLists(list1,list2.Next)
return list2
}
}
排序链表
func sortList(head *ListNode) *ListNode {
return sort(head,nil)
}
func sort(head,tail *ListNode) *ListNode{ //分解成最小单位,然后组成有序链表
if head==nil { //空链表直接返回
return head
}
if head.Next==tail{ //两个节点进行拆分
head.Next=nil
return head
}
slow:=head
fast:=head
for fast!=tail{
slow=slow.Next
fast=fast.Next
if fast!=tail{
fast=fast.Next
}
}
curr:=slow
return merge(sort(head,curr),sort(curr,tail))
}
func merge(list1 *ListNode,list2 *ListNode) *ListNode{
if list1==nil{
return list2
}
if list2==nil{
return list1
}
if list1.Val<list2.Val {
list1.Next=merge(list1.Next,list2)
return list1
}else{
list2.Next=merge(list1,list2.Next)
return list2
}
}
下一个排列
func nextPermutation(nums []int) []int {
n:=len(nums)
if n<2 {
return nums
}
num1:=0
for n>1{
if nums[n-1]>nums[n-2]{
num1=n-2
break
}
n--
}
num2:=0
flag:=false
for i:=len(nums)-1;i>=0;i--{
if nums[num1]<nums[i]{
num2=i
flag=true
break
}
}
nums[num1],nums[num2]=nums[num2],nums[num1]
if flag==false{
sort.Ints(nums)
}else{
sort.Ints(nums[num1+1:])
}
return nums
}
两数相加
func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode {
var head,tail *ListNode
add:=0
for l1!=nil || l2!=nil{
n1,n2:=0,0
if l1!=nil{
n1=l1.Val
l1=l1.Next
}
if l2!=nil{
n2=l2.Val
l2=l2.Next
}
sum:=n1+n2+add
add=sum/10
sum,add=sum%10,add
if head==nil{
head=&ListNode{Val:sum}
tail=head
}else{
tail.Next=&ListNode{Val:sum}
tail=tail.Next
}
}
if add>0{
tail.Next=&ListNode{Val:add}
}
return head
}
合并区间
func merge(intervals [][]int) [][]int {
res:=[][]int{}
n:=len(intervals)
if n<=1{
return intervals
}
sort.Slice(intervals,func(i,j int) bool{
return intervals[i][0]<intervals[j][0]
})
for i:=0;i<n-1;i++{
if intervals[i][1]>=intervals[i+1][0]{
big:=max(intervals[i][1],intervals[i+1][1])
small:=min(intervals[i][0],intervals[i+1][0])
intervals[i+1]=[]int{small,big}
}else{
res=append(res,intervals[i])
}
if i==n-2{
res=append(res,intervals[n-1])
}
}
return res
}
func max(a,b int)int {
if a>b{
return a
}
return b
}
func min(a,b int) int{
if a<b{
return a
}
return b
}