
1、字符串截取
func main() {
var str0 = "12345678901234567890"
str1 := str0[:10]
}
以上代码,会有10字节的内存泄漏,我们知道,str0和str1底层共享内存,只要str1一直活跃,str0 就不会被回收,10字节的内存被使用,剩下的10字节内存就造成了临时性的内存泄漏,直到str1不再活跃
如果str0足够大,str1截取足够小,或者在高并发场景中频繁使用,那么可想而知,会造成临时性内存泄漏,对性能产生极大影响。
解决方案1:string to []byte, []byte to string
func main() {
var str0 = "12345678901234567890"
str1 := string([]byte(str0[:10]))
}
将需要截取的部分先转换成[]byte,再转换成string,但是这种方式会产生两个10字节的临时变量,string转换[]byte时产生一个10字节临时变量,[]byte转换string时产生一个10字节的临时变量
解决方案2:
func main() {
var str0 = "12345678901234567890"
str1 := (" " + str0[:10])[1:]
}
这种方式仍旧会产生1字节的浪费
解决方案3:strings.Builder
func main() {
var str0 = "12345678901234567890"
var builder strings.Builder
builder.Grow(10)
builder.WriteString(str0[:10])
str1 := builder.String()
}
这种方式的缺点就是代码量过多
解决方案4:strings.Repeat
func main() {
var str0 = "12345678901234567890"
str1 := strings.Repeat(str0[:10], 1)
}
这种方式底层还是用到了strings.Builder,优点就是将方案3进行了封装,代码量得到了精简
2、切片截取引起子切片内存泄漏
func main() {
var s0 = []int{1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := s0[:5]
}
这种情况与字符串截取引起的内存泄漏情况类似,s1活跃情况下,造成s0中部分内存泄漏
解决方案:append
func main() {
var s0 = []int{1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := append(s0[:0:0], s0[:5]...)
}
append为内置函数,go源码src/builtin/builtin.go中释义:
// The append built-in function appends elements to the end of a slice. If
// it has sufficient capacity, the destination is resliced to accommodate the
// new elements. If it does not, a new underlying array will be allocated.
// Append returns the updated slice. It is therefore necessary to store the
// result of append, often in the variable holding the slice itself:
// slice = append(slice, elem1, elem2)
// slice = append(slice, anotherSlice...)
// As a special case, it is legal to append a string to a byte slice, like this:
// slice = append([]byte("hello "), "world"...)
func append(slice []Type, elems ...Type) []Type
3、没有重置丢失的子切片元素中的指针
func main() {
var s0 = []*int{new(int), new(int), new(int), new(int), new(int)}
s1 := s0[1:3]
}
原切片元素为指针类型,原切片被截取后,丢失的子切片元素中的指针元素未被置空,导致内存泄漏
解决方案:元素置空
func main() {
var s0 = []*int{new(int), new(int), new(int), new(int), new(int)}
s0[0], s0[3], s0[4] = nil, nil, nil
s1 := s0[1:3]
}
4、函数数组传参
Go数组是值类型,赋值和函数传参都会复制整个数组
func main() {
var arrayA = [3]int{1, 2, 3}
var arrayB = [3]int{}
arrayB = arrayA
fmt.Printf("arrayA address: %p, arrayA value: %+v\n", &arrayA, arrayA)
fmt.Printf("arrayB address: %p, arrayB value: %+v\n", &arrayB, arrayB)
array(arrayA)
}
func array(array [3]int) {
fmt.Printf("array address: %p, array value: %+v\n", &array, array)
}
打印结果:
arrayA address: 0xc0000ae588, arrayA value: [1 2 3]
arrayB address: 0xc0000ae5a0, arrayB value: [1 2 3]
array address: 0xc0000ae5e8, array value: [1 2 3]
可以看到,三条打印的地址都不相同,说明数组是值传递的,这会导致什么问题呢?
如果我们在函数传参的时候用到了数组传参,且这个数组够大(我们假设数组大小为100万,64位机上消耗的内存约为800w字节,即8MB内存),或者该函数短时间内被调用N次,那么可想而知,会消耗大量内存,对性能产生极大的影响,如果短时间内分配大量内存,而又来不及GC,那么就会产生临时性的内存泄漏,对于高并发场景相当可怕。
解决方案1:采用指针传递
func main() {
var arrayA = [3]int{1, 2, 3}
var arrayB = &arrayA
fmt.Printf("arrayA address: %p, arrayA value: %+v\n", &arrayA, arrayA)
fmt.Printf("arrayB address: %p, arrayB value: %+v\n", arrayB, *arrayB)
arrayP(&arrayA)
}
func arrayP(array *[3]int) {
fmt.Printf("array address: %p, array value: %+v\n", array, *array)
}
打印结果:
arrayA address: 0xc00000e6a8, arrayA value: [1 2 3]
arrayB address: 0xc00000e6a8, arrayB value: [1 2 3]
array address: 0xc00000e6a8, array value: [1 2 3]
可以看到,三条打印的地址相同,说明指针是引用传递的 ,三个数组指向的都是同一块内存,就算数组很大,或者函数短时间被调用N次,也不会产生额外的内存开销,这样会不会有隐患呢?
有,如果arrayA的指针地址发生变化,那么,arrayB和函数内array的指针地址也随之改变,稍不注意,容易发生bug
解决方案2:利用切片可以很好的解决以上两个问题
func main() {
var arrayA = [3]int{1, 2, 3}
var arrayB = arrayA[:]
fmt.Printf("arrayA address: %p, arrayA value: %+v\n", &arrayA, arrayA)
fmt.Printf("arrayB address: %p, arrayB value: %+v\n", &arrayB, arrayB)
arrayS(arrayB)
}
func arrayS(array []int) {
fmt.Printf("array address: %p, array value: %+v\n", &array, array)
}
打印结果:
arrayA address: 0xc00000e6a8, arrayA value: [1 2 3]
arrayB address: 0xc0000040d8, arrayB value: [1 2 3]
array address: 0xc000004108, array value: [1 2 3]
可以看到,三条打印的地址都不相同,而切片本身是一个引用类型,arrayA和arrayB底层共享内存,不会产生额外内存开销,而且arrayA的指针地址发生改变,arrayB的指针地址也不会改变,切片的数据结构如下:
type slice struct {
array unsafe.Pointer
len int
cap int
}
5、goroutine
“Go里面10次内存泄漏有9次都是goroutine泄漏引起的”
有些编码不当的情况下,goroutine被长期挂住,导致该协程中的内存也无法被释放,就会造成永久性的内存泄漏。例如协程结束时协程中的channel没有关闭,导致一直阻塞;例如协程中有死循环;等等
我们来看下
func main() {
ticker := time.NewTicker(time.Second * 1)
for {
<-ticker.C
ch := make(chan int)
go func() {
for i := 0; i < 100; i++ {
ch <- i
}
}()
for v := range ch {
if v == 50 {
break
}
}
}
}
将代码运行起来,并利用pprof工具,在web输入http://localhost/debug/pprof/,我们可以看到,goroutine的数量随着时间在不断的增加,而且丝毫没有减少的迹象
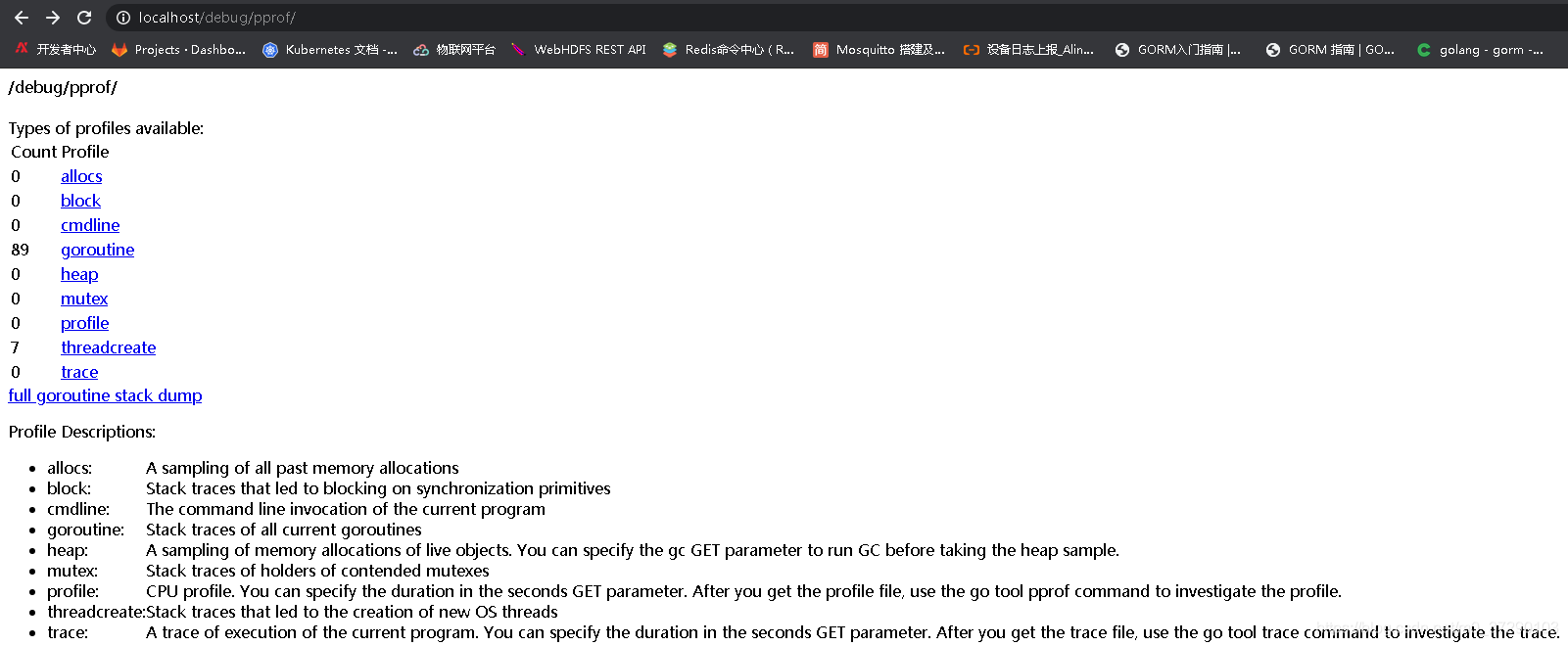
这是因为break的时候,协程中的channel并没有关闭,导致协程一直存活,无法被回收
解决方案:
func main() {
ticker := time.NewTicker(time.Second * 1)
for {
<-ticker.C
cxt, cancel := context.WithCancel(context.Background())
ch := make(chan int)
go func(cxt context.Context) {
for i := 0; i < 100; i++ {
select {
case <-cxt.Done():
return
case ch <- i:
}
}
}(cxt)
for v := range ch {
if v == 50 {
cancel()
break
}
}
}
}
利用context,在break之前cancel,目的就是通知协程退出,这样就避免了goroutine泄漏
6、定时器
1)time.After
func main() {
ch := make(chan int)
go func() {
for {
timerC := time.After(100 * time.Second)
//timerC 每次都是重新创建的,什么意思呢?简单说来,当 select 成功监听 ch 并进入它的处理分支,下次循环 timerC 重新创建了,时间肯定就重置了。
select {
//如果有多个 case 都可以运行,select 会随机公平选择出一个执行。其余的则不会执行
case num := <-ch:
fmt.Println("get num is", num)
case <-timerC:
//等价于 case <-time.After(100 * time.Second)
fmt.Println("time's up!!!")
//done<-true
}
}
}()
for i := 1; i < 100000; i++ {
ch <- i
time.Sleep(time.Millisecond)
}
}
以上代码会造成内存泄漏,time.After底层实现是一个timer,而定时器未到触发时间,该定时器不会被gc回收,从而导致临时性的内存泄漏,而如果定时器一直在创建,那么就造成了永久性的内存泄漏了。
解决方案:采用timer定时器
func main() {
ch := make(chan int)
go func() {
timer := time.NewTimer(100 * time.Second)
defer timer.Stop()
for {
timer.Reset(100 * time.Second)
select {
case num := <-ch:
fmt.Println("get num is", num)
case <-timer.C:
fmt.Println("time's up!!!")
}
}
}()
for i := 1; i < 100000; i++ {
ch <- i
time.Sleep(time.Millisecond)
}
}
创建timer定时器,每次需要启动定时器的时候,使用Reset方法重置定时器,这样就不用每次都要创建新的定时器了
2)timer、ticker
在高并发、高性能场景中,使用time.NewTimer或者time.NewTicker定时器,都需要注意及时调用Stop方法来及时释放资源,否则可能造成临时性或者永久性的内存泄漏。