
关于工具
pprof用数据来驱动优化。
逃逸分析
Go 可以自动的管理内存,这帮我们避免了大量潜在 bug,但它并没有将程序员彻底的从内存分配的事情上解脱出来。因为 Go 没有提供直接操作内存的方式,所以开发者必须要搞懂其内部机制,这样才能将收益最大化。
如果读了这篇文章后,你只能记住一点,那请记住这个:栈分配廉价,堆分配昂贵。现在让我们深入讲述下这是什么意思。
Go 有两个地方可以分配内存:一个全局堆空间用来动态分配内存,另一个是每个 goroutine 都有的自身栈空间。
Go 更倾向于在栈空间上分配内存 —— 一个 Go 程序大部分的内存分配都是在栈空间上的。它的代价很低,因为只需要两个 CPU 指令:一个是把数据 push 到栈空间上以完成分配,另一个是从栈空间上释放。
malloc*int*int编译器使用逃逸分析的技术来在这两者间做选择。基本的思路就是在编译时做垃圾回收的工作。
编译器会追踪变量在代码块上的作用域。变量会携带有一组校验数据,用来证明它的整个生命周期是否在运行时完全可知。如果变量通过了这些校验,它就可以在栈上分配。否则就说它 逃逸 了,必须在堆上分配。
go build -gcflags '-m'package main
import "fmt"
func main() {
x := 42
fmt.Println(x)
}
$ go build -gcflags '-m' ./main.go
# command-line-arguments
./main.go:7: x escapes to heap
./main.go:7: main ... argument does not escape
x escapes to heapxmain()-m$ go build -gcflags '-m -m' ./main.go
# command-line-arguments
./main.go:5: cannot inline main: non-leaf function
./main.go:7: x escapes to heap
./main.go:7: from ... argument (arg to ...) at ./main.go:7
./main.go:7: from *(... argument) (indirection) at ./main.go:7
./main.go:7: from ... argument (passed to call[argument content escapes]) at ./main.go:7
./main.go:7: main ... argument does not escape
x这个机制乍看上去有些难以捉摸,但多用几次这个工具后,就能搞明白这其中的规律了。长话短说,下面是一些我们找到的,能引起变量逃逸到堆上的典型情况:
[]*stringappendcapio.Readerrr.Read(b)rb以我们的经验,这四点是 Go 程序中最常见的导致堆分配的原因。幸运的是,是有解决办法的!下面我们深入几个具体例子说明,如何定位线上系统的内存性能问题。
关于指针
一个经验是:指针指向的数据都是在堆上分配的。因此,在程序中减少指针的运用可以减少堆分配。这不是绝对的,但是我们发现这是在实际问题中最常见的问题。
一般情况下我们会这样认为:“值的拷贝是昂贵的,所以用一个指针来代替。”
但是,在很多情况下,直接的值拷贝要比使用指针廉价的多。你可能要问为什么。
nil[]bytestruct译者注: 垃圾回收器回收一个变量时,要检查该类型里是否有指针。
如果有,要检查指针所指向的内存是否可被回收,进而才能决定这个变量能否被回收。如此递归下去。
如果被回收的变量里面没有指针, 就不需要进去递归扫描了,直接回收掉就行。
减少指针的使用不仅可以降低垃圾回收的工作量,它会产生对 cache 更加友好的代码。读内存是要把数据从主内存读到 CPU 的 cache 中。
Cache 的空间是有限的,所以其他的数据必须被抹掉,好腾出空间。
被抹掉的数据很可能程序的另外一部分相关。
由此产生的 cache 抖动会引起线上服务的一些意外的和突然的抖动。
还是关于指针
减少指针的使用就意味着要深入我们自定义的数据类型。我们的一个服务,用带有一组数据结构的循环 buffer 构建了一个失败操作的队列好做重试;它大致是这个样子:
type retryQueue struct {
buckets [][]retryItem // each bucket represents a 1 second interval
currentTime time.Time
currentOffset int
}
type retryItem struct {
id ksuid.KSUID // ID of the item to retry
time time.Time // exact time at which the item has to be retried
}
buckets[]retryItemretryItemKSUID[20]bytecurrentOffsetinttime.Timetype Time struct {
sec int64
nsec int32
loc *Location // pointer to the time zone structure
}
time.TimelocretryItem我们发现,这个案例很典型。 在正常运行期间失败情况很少。 只有少量内存用于存储重试操作。 当失败突然飙升时,重试队列中的对象数量每秒增长好几千,从而对垃圾回收器增加很多压力。
time.Timetype retryItem struct {
id ksuid.KSUID
nsec uint32
sec int64
}
func (item *retryItem) time() time.Time {
return time.Unix(item.sec, int64(item.nsec))
}
func makeRetryItem(id ksuid.KSUID, time time.Time) retryItem {
return retryItem{
id: id,
nsec: uint32(time.Nanosecond()),
sec: time.Unix(),
}
retryItemretryItem传递 Slice
切片是造成低效内存分配行为的狂热区域。除非切片的大小在编译时就能知道,否则切片背后的数组(map也一样)会在堆上分配。让我们来讲几个方法,让切片在栈上分配而不是在堆上。
pproftime.Timetime.Time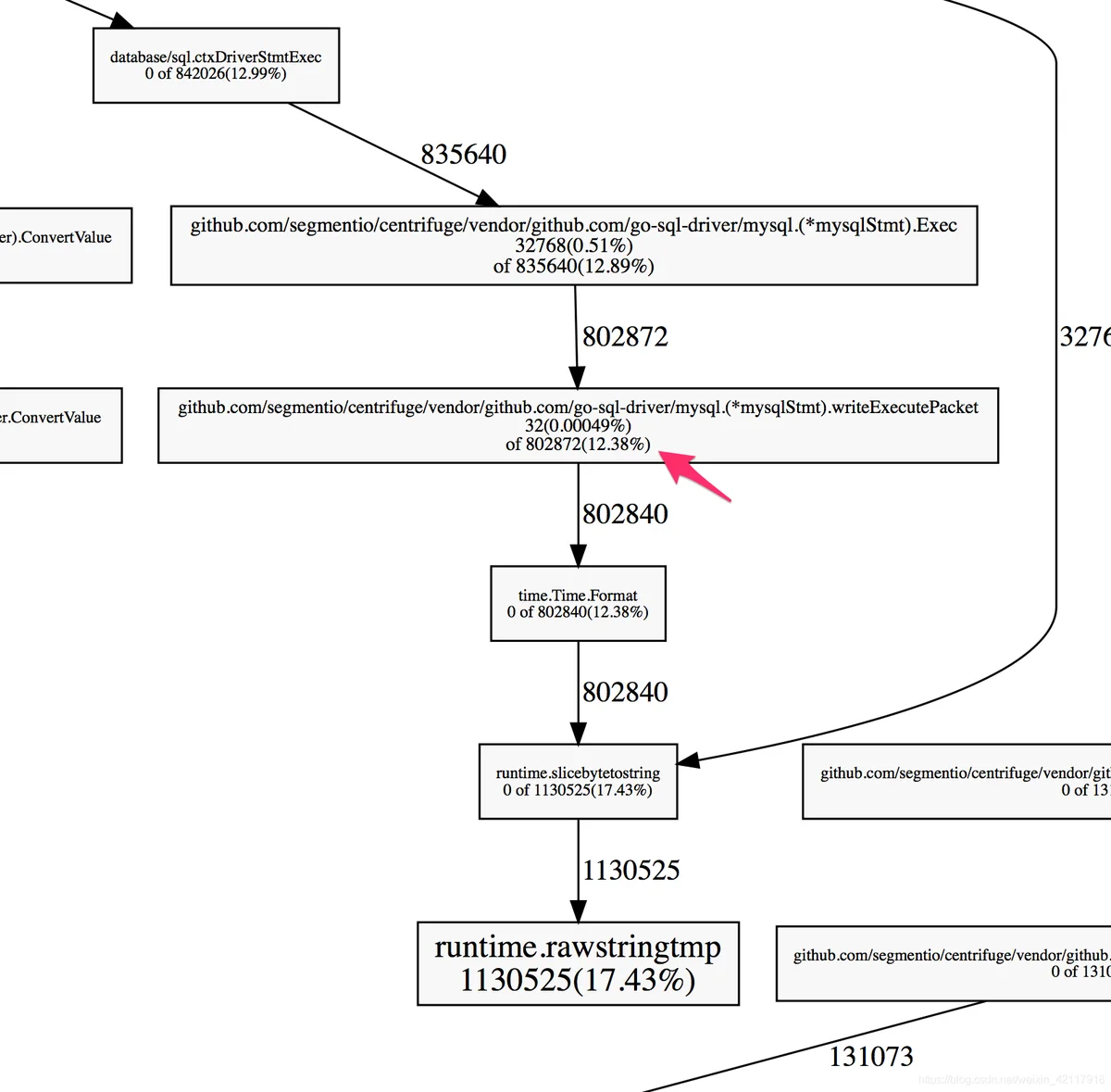
time.TimeFormat()stringstring[]byte12.38%Format()Format()
Format()AppendFormat()timeAppendFormat()Format()AppendFormat()
Format()AppendFormat()func (t Time) Format(layout string) string {
const bufSize = 64
var b []byte
max := len(layout) + 10
if max < bufSize {
var buf [bufSize]byte
b = buf[:0]
} else {
b = make([]byte, 0, max)
}
b = t.AppendFormat(b, layout)
return string(b)
}
AppendFormat()stringAppendFormat()Format()Interface 类型
众所周知的,在 Interface 类型上调用方法要比直接在 Struct 上调用方法效率低。在 interface 类型上调用方法是动态调度的。这就极大的限制了编译器确定运行时代码执行方式的能力。到目前为止我们已经大量的讨论了,调整代码好让编译器能在编译时更好的理解你的代码行为。但 interface 类型会让这一切都白做。
hashhashpackage main
import (
"fmt"
"hash/fnv"
)
func hashIt(in string) uint64 {
h := fnv.New64a()
h.Write([]byte(in))
out := h.Sum64()
return out
}
func main() {
s := "hello"
fmt.Printf("The FNV64a hash of '%v' is '%v'\n", s, hashIt(s))
}
编译上段代码,加上逃逸分析参数,会有以下输出:
./foo1.go:9:17: inlining call to fnv.New64a
./foo1.go:10:16: ([]byte)(in) escapes to heap
./foo1.go:9:17: hash.Hash64(&fnv.s·2) escapes to heap
./foo1.go:9:17: &fnv.s·2 escapes to heap
./foo1.go:9:17: moved to heap: fnv.s·2
./foo1.go:8:24: hashIt in does not escape
./foo1.go:17:13: s escapes to heap
./foo1.go:17:59: hashIt(s) escapes to heap
./foo1.go:17:12: main ... argument does not escape
hash[]bytehash一个小把戏
最后一点要比实际情况更搞笑。但是,它能让我们对编译器的逃逸分析机制有更深刻的理解。当通过阅读标准库源码来解决性能问题时,我们看到了下面这样的代码:
// noescape hides a pointer from escape analysis. noescape is
// the identity function but escape analysis doesn't think the
// output depends on the input. noescape is inlined and currently
// compiles down to zero instructions.
// USE CAREFULLY!
//go:nosplit
func noescape(p unsafe.Pointer) unsafe.Pointer {
x := uintptr(p)
return unsafe.Pointer(x ^ 0)
}
这个函数会把指针参数从编译器的逃逸分析中隐藏掉。这意味着什么呢?让我们来举个例子看下。
package main
import (
"unsafe"
)
type Foo struct {
S *string
}
func (f *Foo) String() string {
return *f.S
}
type FooTrick struct {
S unsafe.Pointer
}
func (f *FooTrick) String() string {
return *(*string)(f.S)
}
func NewFoo(s string) Foo {
return Foo{S: &s}
}
func NewFooTrick(s string) FooTrick {
return FooTrick{S: noescape(unsafe.Pointer(&s))}
}
func noescape(p unsafe.Pointer) unsafe.Pointer {
x := uintptr(p)
return unsafe.Pointer(x ^ 0)
}
func main() {
s := "hello"
f1 := NewFoo(s)
f2 := NewFooTrick(s)
s1 := f1.String()
s2 := f2.String()
}
stringString()FooTrick./foo3.go:24:16: &s escapes to heap
./foo3.go:23:23: moved to heap: s
./foo3.go:27:28: NewFooTrick s does not escape
./foo3.go:28:45: NewFooTrick &s does not escape
./foo3.go:31:33: noescape p does not escape
./foo3.go:38:14: main &s does not escape
./foo3.go:39:19: main &s does not escape
./foo3.go:40:17: main f1 does not escape
./foo3.go:41:17: main f2 does not escape
关键在这两行
./foo3.go:24:16: &s escapes to heap
./foo3.go:23:23: moved to heap: s
NewFoo()NewFooTrick()noescape()func noescape(p unsafe.Pointer) unsafe.Pointer {
x := uintptr(p)
return unsafe.Pointer(x ^ 0)
}
noescape()pxuintptr()uintptrunsafe.Pointernoescape()runtimeunsafe.Pointerunsafe.PointerunsafeUSE CAREFULLY!小贴士
- 不要过早优化,用数据来驱动我们的优化工作。
- 栈空间分配是廉价的,堆空间分配是昂贵的。
- 了解逃逸机制可以让我们写出更高效的代码。
- 指针的使用会导致栈分配更不可行。
- 找到在低效代码块中提供分配控制的 api。
- 在调用频繁的地方慎用 interface。