
Go 程序会在两个地方为变量分配内存,一个是全局的堆上,另一个是函数调用栈,Go 语言有垃圾回收机制,在Go中变量分配在堆还是栈上是由编译器决定的,因此开发者无需过多关注变量是分配在栈上还是堆上。但如果想写出高质量的代码,了解语言背后的实现是有必要的,变量在栈上分配和在堆上分配底层实现的机制完全不同,变量的分配与回收流程不同,性能差异是非常大的。
堆与栈的区别
堆
程序运行时动态分配的内存都位于堆中,这部分内存由内存分配器负责管理,该区域的大小会随着程序的运行而变化,即当我们向堆请求分配内存但分配器发现堆中的内存不足时,它会向操作系统内核申请向高地址方向扩展堆的大小,而当我们释放内存把它归还给堆时如果内存分配器发现剩余空闲内存太多则又会向操作系统请求向低地址方向收缩堆的大小,从内存申请和释放流程可以看出,从堆上分配的内存用完之后必须归还给堆,否则内存分配器可能会反复向操作系统申请扩展堆的大小从而导致堆内存越用越多,最后出现内存不足,这就是所谓的内存泄漏。值的一提的是传统的 c/c++ 代码需要手动处理内存的分配和释放,而在 Go 语言中,有垃圾回收器来回收堆上的内存,所以程序员只管申请内存,而不用管内存的释放,大大降低了程序员的心智负担,这不光是提高了程序员的生产力,更重要的是还会减少很多bug的产生。
栈
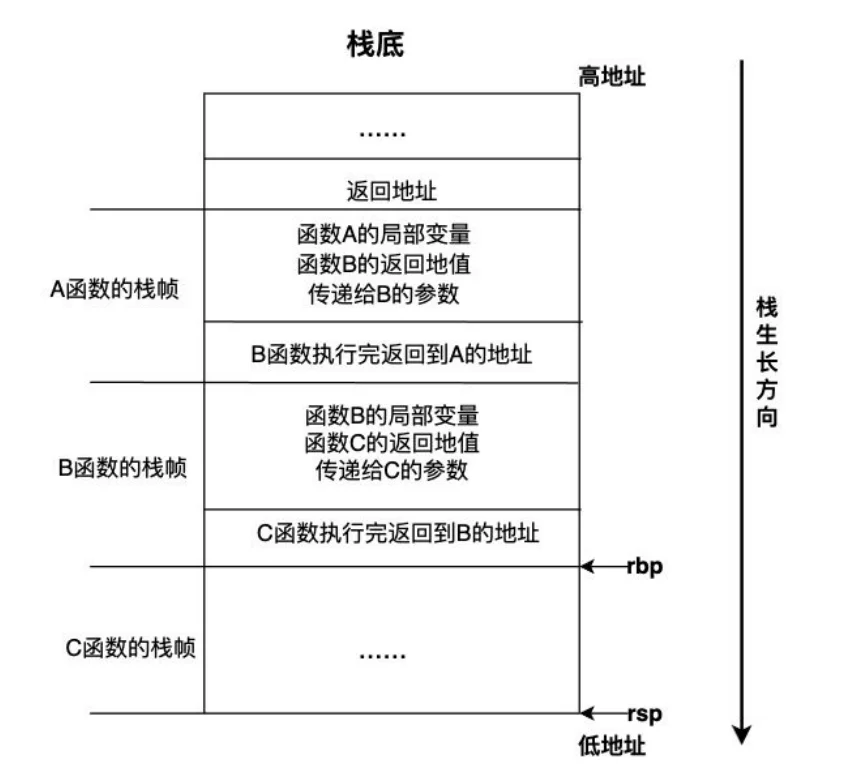
函数调用栈简称栈,在程序运行过程中,不管是函数的执行还是函数调用,栈都起着非常重要的作用,它主要被用来:
- 保存函数的局部变量;
- 向被调用函数传递参数;
- 返回函数的返回值;
- 保存函数的返回地址,返回地址是指从被调用函数返回后调用者应该继续执行的指令地址;
每个函数在执行过程中都需要使用一块栈内存用来保存上述这些值,我们称这块栈内存为某函数的栈帧(stack frame)。当发生函数调用时,因为调用者还没有执行完,其栈内存中保存的数据还有用,所以被调用函数不能覆盖调用者的栈帧,只能把被调用函数的栈帧“push”到栈上,等被调函数执行完成后再把其栈帧从栈上“pop”出去,这样,栈的大小就会随函数调用层级的增加而生长,随函数的返回而缩小,也就是说函数调用层级越深,消耗的栈空间就越大。栈的生长和收缩都是自动的,由编译器插入的代码自动完成,因此位于栈内存中的函数局部变量所使用的内存随函数的调用而分配,随函数的返回而自动释放,所以程序员不管是使用有垃圾回收还是没有垃圾回收的高级编程语言都不需要自己释放局部变量所使用的内存,这一点与堆上分配的内存截然不同。
值类型与引用类型
不管是Java、C#还是golang中,都有值类型和引用类型的概念。在使用两者时,发现这两种语言之间还是有差异的。
基本类型
基本类型是 Go 语言自带的类型,比如 数值、浮点、字符串、布尔、数组 及 错误 类型,他们本质上是原始类型,也就是不可改变的,所以对他们进行操作,一般都会返回一个新创建的值,所以把这些值传递给函数时,其实传递的是一个值的副本。
1
2
3
4
5
6
7
8
9
10
11
12
func main() {
name := "张三"
fmt.Println(modify(name))
fmt.Println(name)
}
func modify(sstring)string{
s = s + s
return s
}
张三张三
张三
以上是一个操作字符串的例子,通过打印的结果,可以看到,本来 name 的值并没有被改变,也就是说,我们传递的时一个副本,并且返回一个新创建的字符串。
基本类型因为是拷贝的值,并且在对他进行操作的时候,生成的也是新创建的值,所以这些类型在多线程里是安全的,我们不用担心一个线程的修改影响了另外一个线程的数据。
引用类型
引用类型和原始的基本类型恰恰相反,它的修改可以影响到任何引用到它的变量。在 Go 语言中,引用类型有 切片(slice)、字典(map)、接口(interface)、函数(func) 以及 通道(chan) 。
引用类型之所以可以引用,是因为我们创建引用类型的变量,其实是一个标头值,标头值里包含一个指针,指向底层的数据结构,当我们在函数中传递引用类型时,其实传递的是这个标头值的副本,它所指向的底层结构并没有被复制传递,这也是引用类型传递高效的原因。
本质上,我们可以理解函数的传递都是值传递,只不过引用类型传递的是一个指向底层数据的指针,所以我们在操作的时候,可以修改共享的底层数据的值,进而影响到所有引用到这个共享底层数据的变量。
1
2
3
4
5
6
7
8
9
10
func main() {
ages := map[string]int{"张三": 20}
fmt.Println(ages)
modify(ages)
fmt.Println(ages)
}
func modify(mmap[string]int) {
m["张三"] = 10
}
这是一个很明显的修改引用类型的例子,函数 modify 的修改,会影响到原来变量 ages 的值。
结构类型
结构类型是用来描述一组值的,比如一个人有身高、体重、名字和年龄等,本质上是一种聚合型的数据类型。
1
2
3
4
type person struct {
age int
name string
}
除了基本的原始类型外,结构体内的值也可以是引用类型,或者自己定义的其他类型。具体选择类型,要根据实际情况,比如是否允许修改值本身,如果允许的话,可以选择引用类型,如果不允许的话,则需要使用基本类型。
函数传参是值传递,所以对于结构体来说也不例外,结构体传递的是其本身以及里面的值的拷贝。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
func main() {
jim := person{10, "Jim"}
fmt.Println(jim)
modify(jim)
fmt.Println(jim)
}
func modify(p person) {
p.age = p.age + 10
}
type person struct {
age int
name string
}
以上示例的输出是一样的,所以我们可以验证传递的是值的副本。如果上面的例子我们要修改 age 的值可以通过传递结构体的指针,我们稍微改动下例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
func main() {
jim := person{10, "Jim"}
fmt.Println(jim)
modify(&jim)
fmt.Println(jim)
}
func modify(p *person) {
p.age = p.age + 10
}
type person struct {
age int
name string
}
输出结果
1
2
{10 Jim}
{20 Jim}
非常明显的, age 的值已经被改变。如果结构体里有引用类型的值,比如 map ,那么我们即使传递的是结构体的值副本,如果修改这个 map 的话,原结构的对应的 map 值也会被修改。
使用经验
1
2
3
4
5
6
// A WaitGroup must not be copied after first use.
type WaitGroup struct {
noCopy noCopy
......
}