
一、思路:
1、UTF8编码规则:
对于单字节字符,8个比特位最高位为0
对于多字节字符,若字符由n个字节组成,则第一个字节8个比特中最高n位都是1,剩下n-1字节中最高位都是10
2、读取文件得到字节流
3、判断是单字节字符还是多字节字符
4、定义计数器nBytes,遍历每个字节,将字节与0x80进行与运算判断,结果为0,单字节字符,没毛病。结果不为0,用nBytes记录最高位出现的1的个数,然后判读剩下n-1个字符最高位是否10,将n-1字节分别与0xc做与运算,若有一个不满足直接返回false,否则每次nBytes--,最后根据nBytes是否为0判断是否为U8编码。
二、代码实现
package main
import (
"io/ioutil"
"fmt"
)
func validUTF8(buf []byte) bool{
nBytes := 0
for i:= 0;i<len(buf);i++{
if nBytes == 0{
if (buf[i] & 0x80) != 0 { //与操作之后不为0,说明首位为1
for (buf[i] & 0x80) != 0 {
buf[i] <<= 1 //左移一位
nBytes++ //记录字符共占几个字节
}
if nBytes < 2 || nBytes > 6 { //因为UTF8编码单字符最多不超过6个字节
return false
}
nBytes-- //减掉首字节的一个计数
}
}else{ //处理多字节字符
if buf[i] & 0xc0 != 0x80{ //判断多字节后面的字节是否是10开头
return false
}
nBytes--
}
}
return nBytes == 0
}
func main(){
b,err := ioutil.ReadFile(`test.txt`)
if err != nil{
fmt.Println(err)
}
fmt.Println(validUTF8(b))
}
三、测试
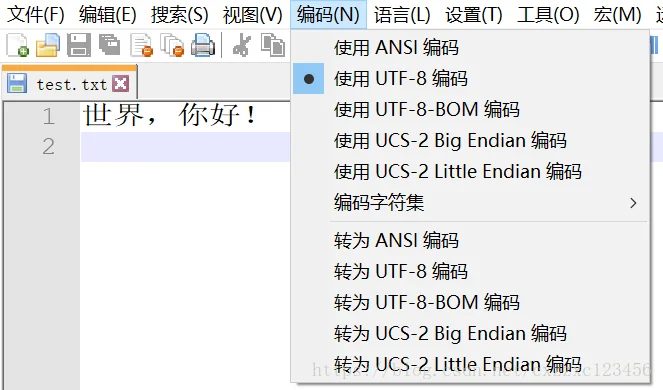
返回 true
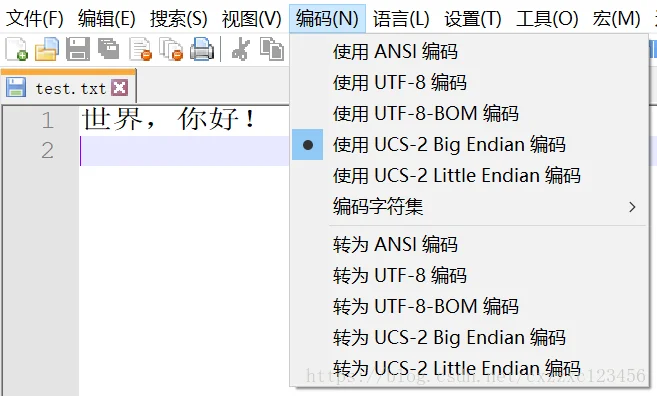
返回 false