
上一章中对于编译原理的说明如下:
接下来我们来对golang的数据结构进行说明,主要内容有:
- 1 数组
- 2 切片
- 3 哈希表
- 4 字符串
这一节会介绍 Go 语言中的另一个集合元素 — 哈希,也就是 Map 的实现原理;哈希表是除了数组之外,最常见的数据结构,几乎所有的语言都会有数组和哈希表这两种集合元素,有的语言将数组实现成列表,有的语言将哈希表称作结构体或者字典,但是它们是两种设计集合元素的思路,数组用于表示元素的序列,而哈希表示的是键值对之间映射关系,只是不同语言的叫法和实现稍微有些不同。
哈希表1是一种古老的数据结构,在 1953 年就有人使用拉链法实现了哈希表,它能够根据键(Key)直接访问内存中的存储位置,也就是说我们能够直接通过键找到该键对应的一个值。
1. 设计原理
O(1)哈希函数
实现哈希表的关键点在于如何选择哈希函数,哈希函数的选择在很大程度上能够决定哈希表的读写性能,在理想情况下,哈希函数应该能够将不同键映射到不同的索引上,这要求哈希函数输出范围大于输入范围,但是由于键的数量会远远大于映射的范围,所以在实际使用时,这个理想的结果是不可能实现的。
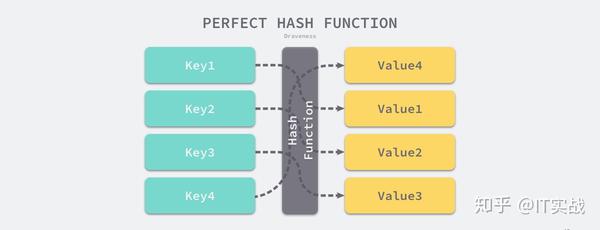
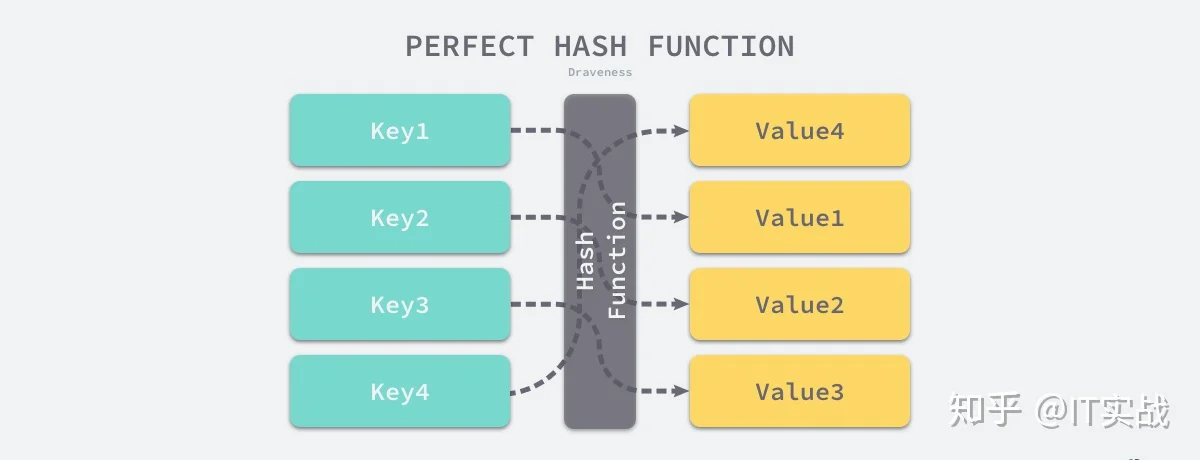
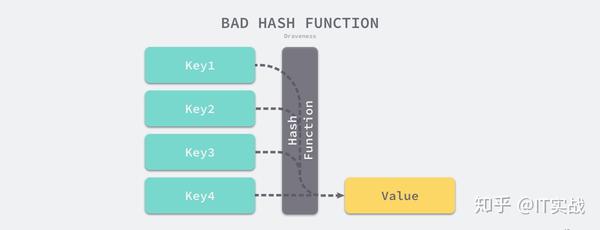
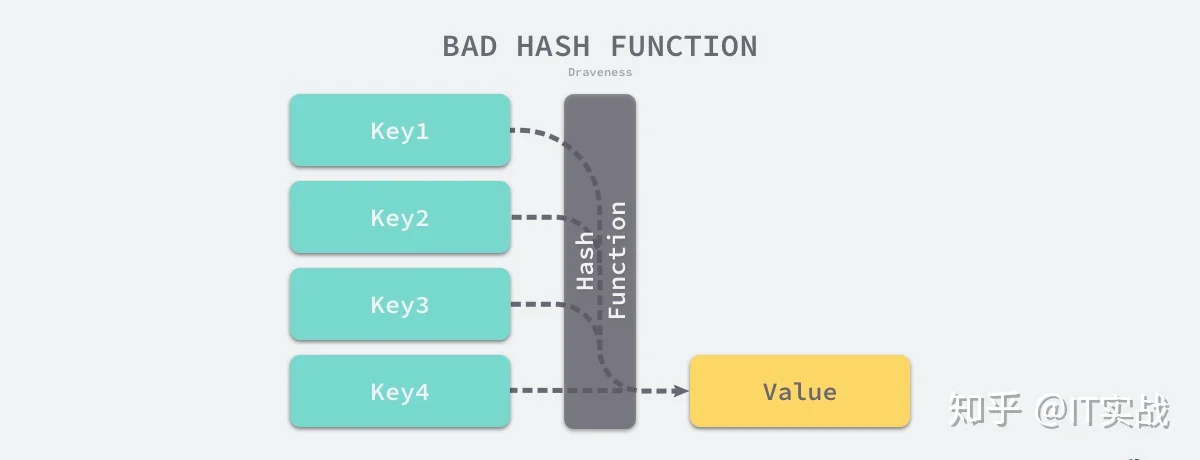
比较实际的方式是让哈希函数的结果能够尽可能的均匀分布,然后通过工程上的手段解决哈希碰撞的问题,但是哈希的结果一定要尽可能均匀,结果不均匀的哈希函数会造成更多的冲突并导致更差的读写性能。
O(1)O(n)冲突解决
就像我们之前所提到的,在通常情况下,哈希函数输入的范围一定会远远大于输出的范围,所以在使用哈希表时一定会遇到冲突,哪怕我们使用了完美的哈希函数,当输入的键足够多最终也会造成冲突。
然而我们的哈希函数往往都是不完美的,输出的范围是有限的,所以一定会发生哈希碰撞,这时就需要一些方法来解决哈希碰撞的问题,常见方法的就是开放寻址法和拉链法。
开放寻址法
(author, draven)index := hash("author") % array.len当我们向当前哈希表写入新的数据时发生了冲突,就会将键值对写入到下一个索引不为空的位置:
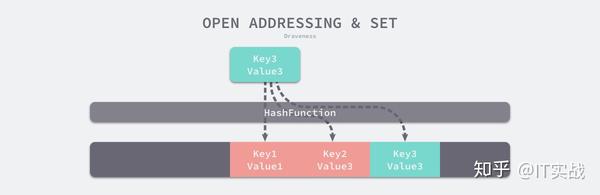
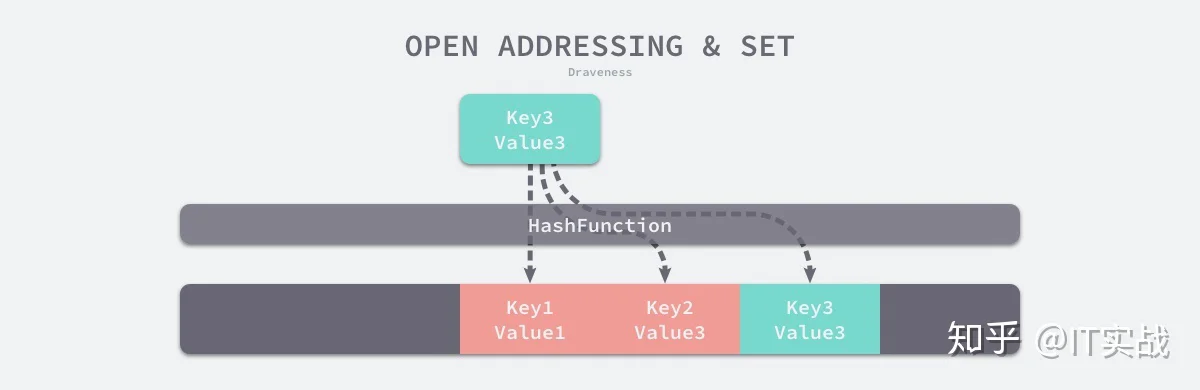
如上图所示,当 Key3 与已经存入哈希表中的两个键值对 Key1 和 Key2 发生冲突时,Key3 会被写入 Key2 后面的空闲内存中;当我们再去读取 Key3 对应的值时就会先对键进行哈希并取模,这会帮助我们找到 Key1,因为 Key1 与我们期望的键 Key3 不匹配,所以会继续查找后面的元素,直到内存为空或者找到目标元素。
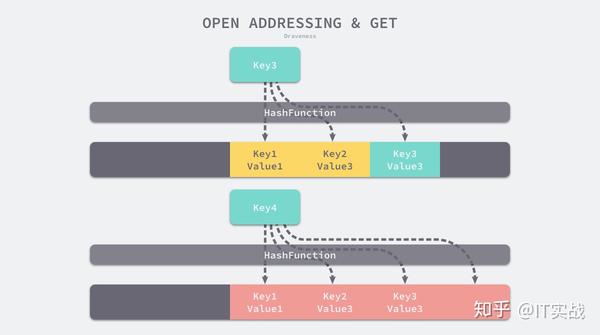
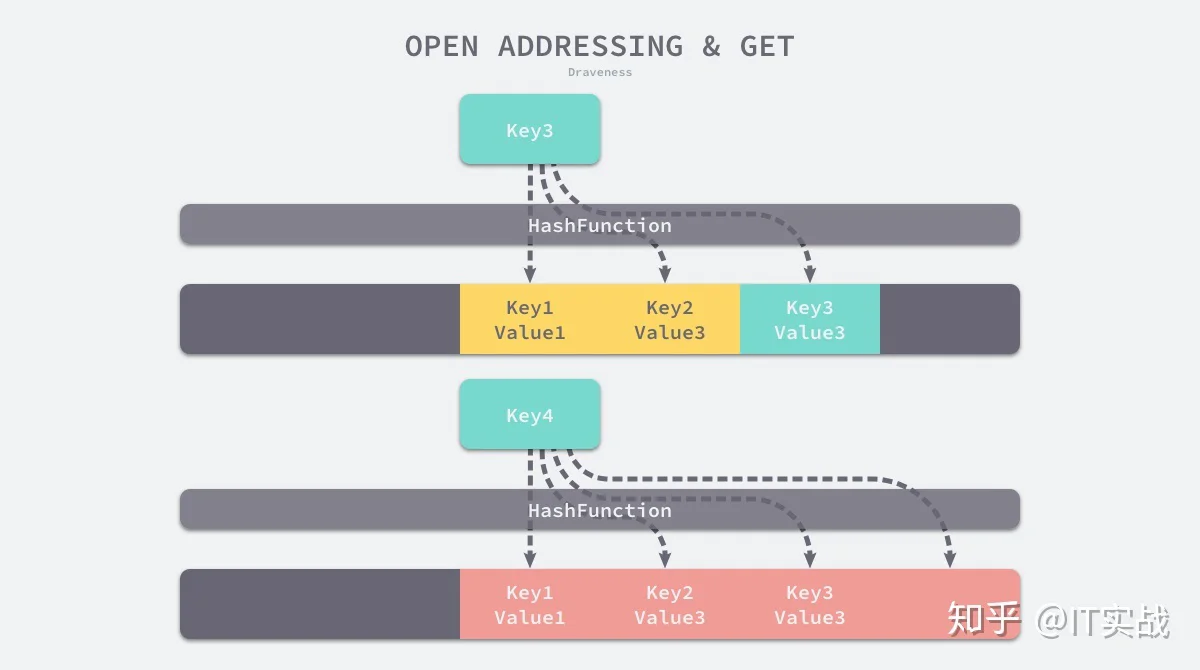
当需要查找某个键对应的值时,就会从索引的位置开始对数组进行线性探测,找到目标键值对或者空内存就意味着这一次查询操作的结束。
开放寻址法中对性能影响最大的就是装载因子,它是数组中元素的数量与数组大小的比值,随着装载因子的增加,线性探测的平均用时就会逐渐增加,这会同时影响哈希表的读写性能,当装载率超过 70% 之后,哈希表的性能就会急剧下降,而一旦装载率达到 100%,整个哈希表就会完全失效,这时查找和插入任意元素的时间复杂度都是 O(n)O(n) 的,它们可能需要遍历数组中全部的元素,所以在实现哈希表时一定要时刻关注装载因子的变化。
拉链法
与开放地址法相比,拉链法是哈希表中最常见的实现方法,大多数的编程语言都用拉链法实现哈希表,它的实现比较开放地址法稍微复杂一些,但是平均查找的长度也比较短,各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间。
实现拉链法一般会使用数组加上链表,不过有一些语言会在拉链法的哈希中引入红黑树以优化性能,拉链法会使用链表数组作为哈希底层的数据结构,我们可以将它看成一个可以扩展的『二维数组』:
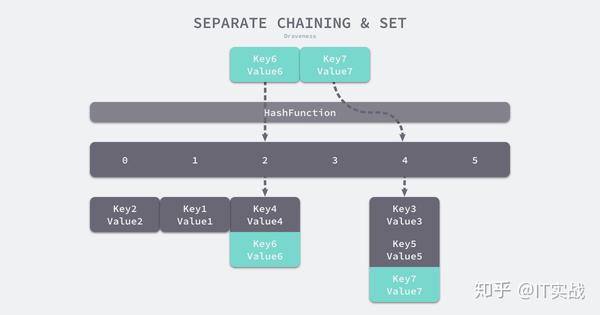
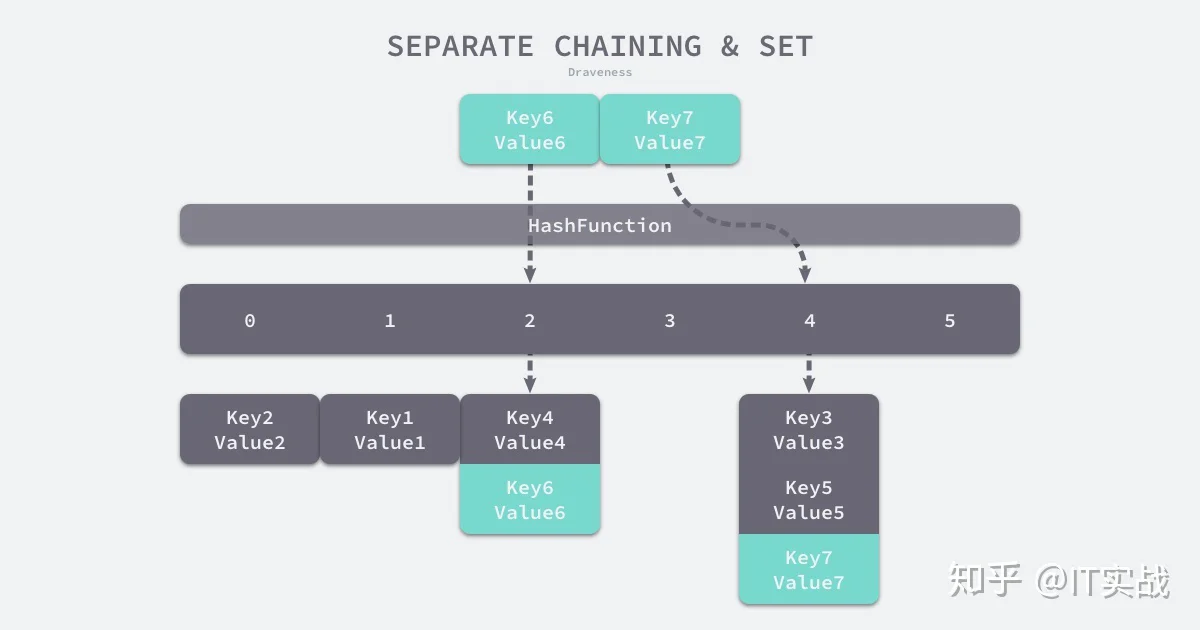
(Key6, Value6)Key6index := hash("Key6") % array.len选择了 2 号桶之后就可以遍历当前桶中的链表了,在遍历链表的过程中会遇到以下两种情况:
- 找到键相同的键值对 —— 更新键对应的值;
- 没有找到键相同的键值对 —— 在链表的末尾追加新键值对;
将键值对写入哈希之后,要通过某个键在其中获取映射的值,就会经历如下的过程:
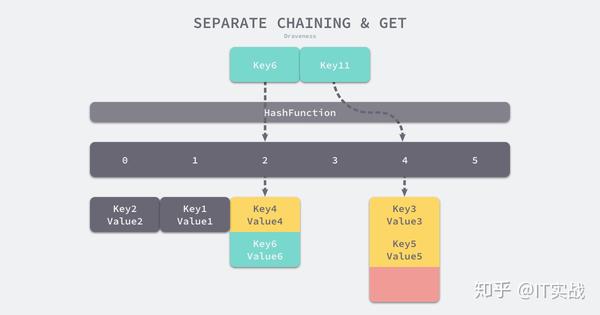
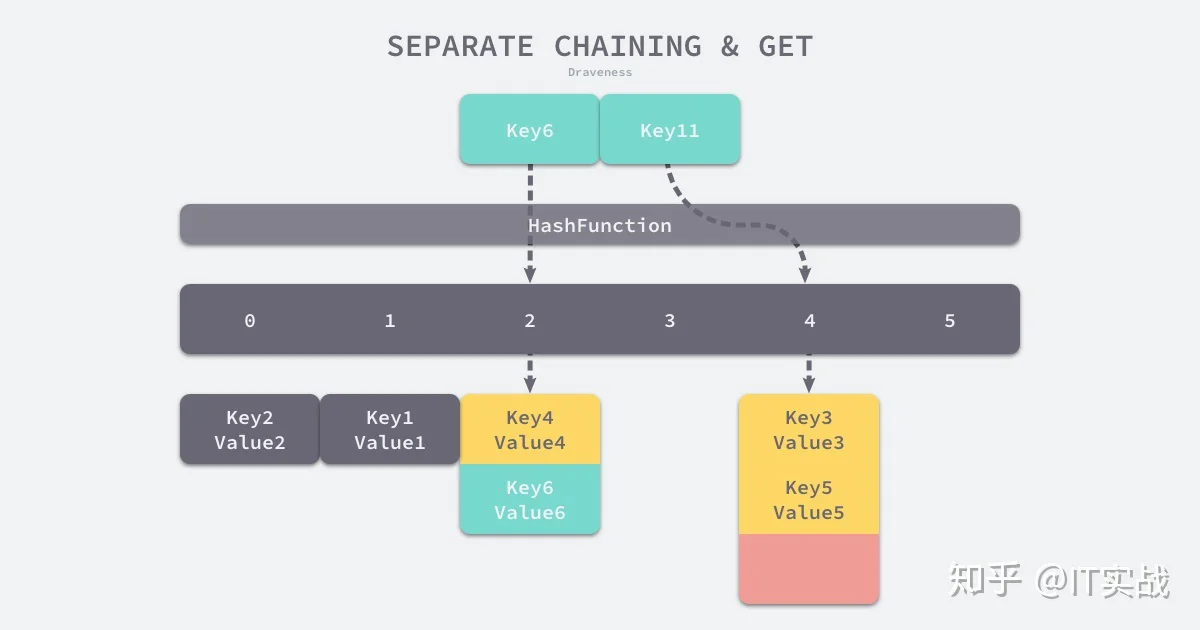
Key11 展示了一个键在哈希表中不存在的例子,当哈希表发现它命中 4 号桶时,它会依次遍历桶中的链表,然而遍历到链表的末尾也没有找到期望的键,所以哈希表中没有该键对应的值。
在一个性能比较好的哈希表中,每一个桶中都应该有 0~1 个元素,有时会有 2~3 个,很少会超过这个数量,计算哈希、定位桶和遍历链表三个过程是哈希表读写操作的主要开销,使用拉链法实现的哈希也有装载因子这一概念:
装载因子 := 元素数量 / 桶数量与开放地址法一样,拉链法的装载因子越大,哈希的读写性能就越差,在一般情况下使用拉链法的哈希表装载因子都不会超过 1,当哈希表的装载因子较大时就会触发哈希的扩容,创建更多的桶来存储哈希中的元素,保证性能不会出现严重的下降。如果有 1000 个桶的哈希表存储了 10000 个键值对,它的性能是保存 1000 个键值对的 1/10,但是仍然比在链表中直接读写好 1000 倍。
2. 数据结构
Go 语言运行时同时使用了多个数据结构组合表示哈希表,其中使用 结构体来表示哈希,我们先来看一下这个结构体内部的字段:
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}countBbucketslen(buckets) == 2^Bhash0oldbucketsbucketsbuckets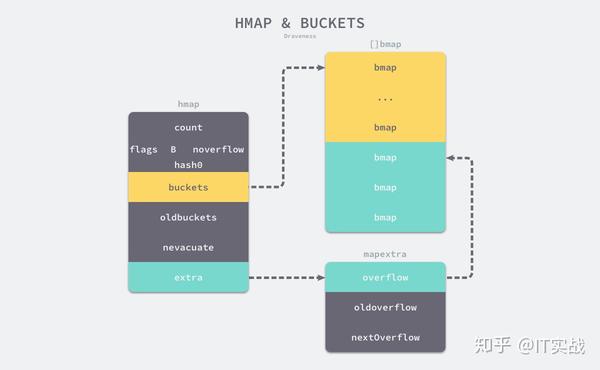
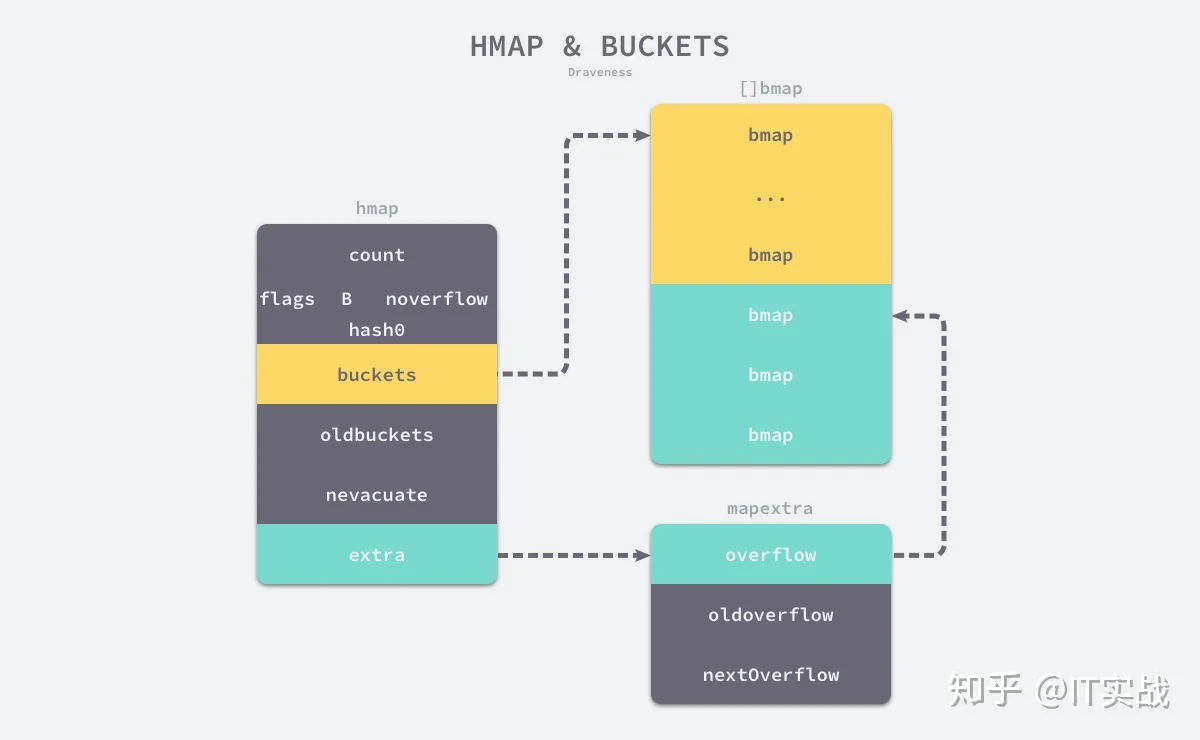
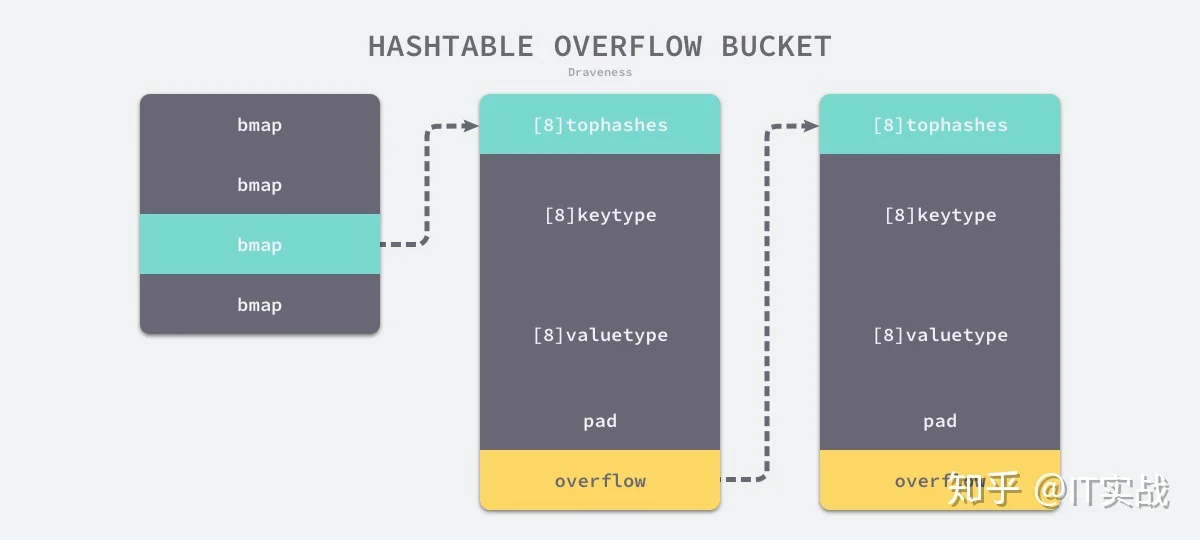
hmapbmapbmapextra.overflowbmapbmapbmaptophashtophashtype bmap struct {
tophash [bucketCnt]uint8
}bmaptophashtype bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}如果哈希表存储的数据逐渐增多,我们会对哈希表进行扩容或者使用额外的桶存储溢出的数据,不会让单个桶中的数据超过 8 个,不过溢出桶只是临时的解决方案,创建过多的溢出桶最终也会导致哈希的扩容。
从 Go 语言哈希的定义中就可以发现,它比前面两节提到的数组和切片复杂得多,结构体中不仅包含大量字段,还使用了较多的复杂结构,在后面的小节中我们会详细介绍不同字段的作用。
3. 初始化
既然已经介绍了常见哈希表的基本原理和实现方法,那么可以开始分析 Go 语言中哈希表的实现,首先要分析的就是在 Go 语言中初始化哈希的两种方法 — 通过字面量和运行时。
字面量
key: valuehash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}我们需要在初始化哈希时声明键值对的类型,这种使用字面量初始化的方式最终都会通过 函数初始化,我们来分析一下 函数初始化哈希的过程:
func maplit(n *Node, m *Node, init *Nodes) {
a := nod(OMAKE, nil, nil)
a.Esc = n.Esc
a.List.Set2(typenod(n.Type), nodintconst(int64(n.List.Len())))
litas(m, a, init)
var stat, dyn []*Node
for _, r := range n.List.Slice() {
stat = append(stat, r)
}
if len(stat) > 25 {
...
} else {
addMapEntries(m, stat, init)
}
}addMapEntrieshash := make(map[string]int, 3)
hash["1"] = 2
hash["3"] = 4
hash["5"] = 6这种初始化的方式与前面两节分析的数组和切片的几乎完全相同,由此看来集合类型的初始化在 Go 语言中有着相同的处理方式和逻辑。
一旦哈希表中元素的数量超过了 25 个,就会在编译期间创建两个数组分别存储键和值的信息,这些键值对会通过一个如下所示的 for 循环加入目标的哈希:
hash := make(map[string]int, 26)
vstatk := []string{"1", "2", "3", ... , "26"}
vstatv := []int{1, 2, 3, ... , 26}
for i := 0; i < len(vstak); i++ {
hash[vstatk[i]] = vstatv[i]
}vstatkvstatvmake[]运行时
makemakefunc makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}这个函数的执行过程会分成以下几个部分:
fastrandhintBfunc makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b)
nbuckets := base
if b >= 4 {
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
buckets = newarray(t.bucket, int(nbuckets))
if base != nbuckets {
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
last.setoverflow(t, (*bmap)(buckets))
}
return buckets, nextOverflow
}hmap4. 读写操作
哈希表作为一种数据结构,我们肯定需要分析它的常见操作,首先就需要了解其读写操作的实现原理,访问哈希表一般都是通过下标或者遍历两种方式进行的:
_ = hash[key]
for k, v := range hash {
// k, v
}rangedeletehash[key] = value
hash[key] = newValue
delete(hash, key)除了这些操作之外,我们还会分析哈希的扩容过程,这能帮助我们深入理解哈希是如何对数据进行存储的。
访问
hash[key]v := hash[key] // => v := *mapaccess1(maptype, hash, &key)
v, ok := hash[key] // => v, ok := mapaccess2(maptype, hash, &key)赋值语句左侧接受参数的个数会决定使用的运行时方法:
bucketMaskaddfunc mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
return v
}
}
}
return unsafe.Pointer(&zeroVal[0])
}bucketlooptophashtophashtophashtophash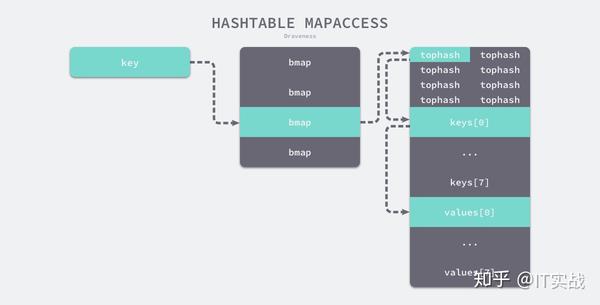
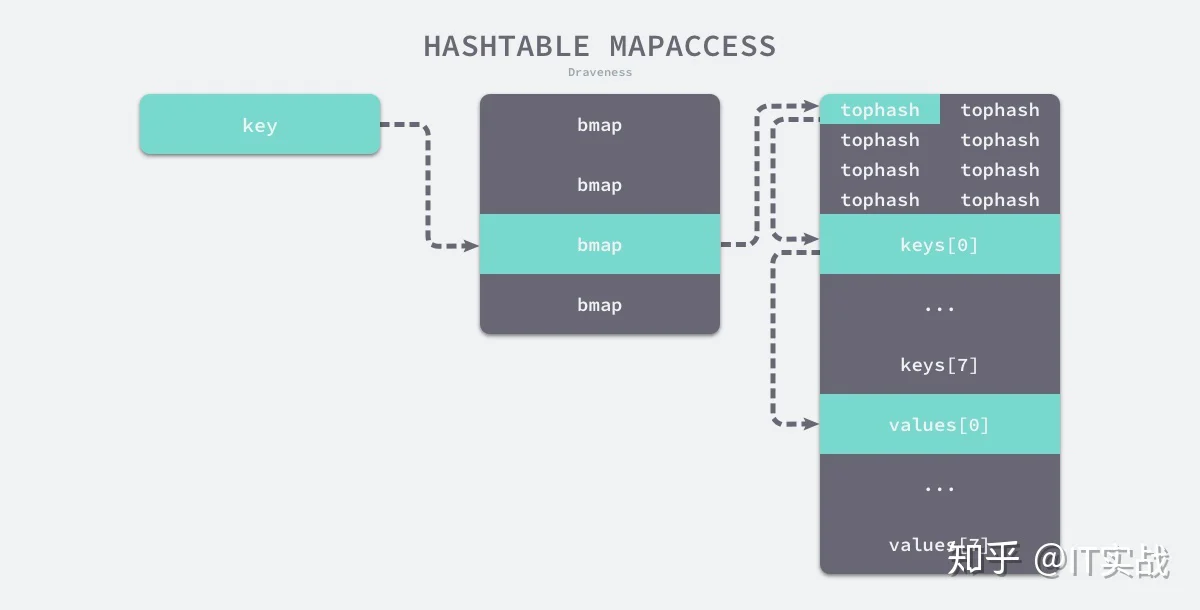
tophashtophashkeys[0]keyvalues[0]另一个同样用于访问哈希表中数据的 只是在 的基础上多返回了一个标识键值对是否存在的布尔值:
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
...
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
return v, true
}
}
}
return unsafe.Pointer(&zeroVal[0]), false
}v, ok := hash[k]v == nilv上面的过程其实是在正常情况下,访问哈希表中元素时的表现,然而与数组一样,哈希表可能会在装载因子过高或者溢出桶过多时进行扩容,哈希表的扩容并不是一个原子的过程,在扩容的过程中保证哈希的访问是比较有意思的话题,我们在这里其实也省略了相关的代码,不过会在下面展开介绍。
写入
hash[k]func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
h.flags ^= hashWriting
again:
bucket := hash & bucketMask(h.B)
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash)tophashinsertiinsertkvalkvalvar inserti *uint8
var insertk unsafe.Pointer
var val unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if !alg.equal(key, k) {
continue
}
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}tophashkey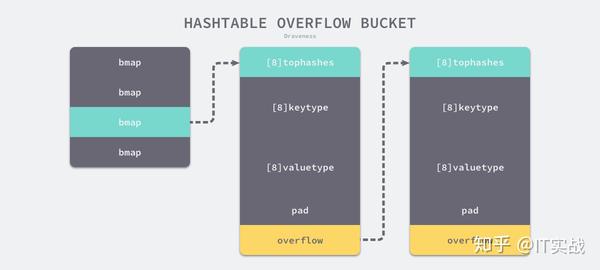
newoverflowhmapnoverflownoverflowif inserti == nil {
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
return val
}typedmemmovevalmapassign00018 (+5) CALL runtime.mapassign_fast64(SB)
00020 (5) MOVQ 24(SP), DI ;; DI = &value
00026 (5) LEAQ go.string."88"(SB), AX ;; AX = &"88"
00027 (5) MOVQ AX, (DI) ;; *DI = AX24(SP)LEAQAXMOVQ"88"扩容
我们在介绍哈希的写入过程时省略了扩容操作,随着哈希表中元素的逐渐增加,哈希的性能会逐渐恶化,所以我们需要更多的桶和更大的内存保证哈希的读写性能:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
...
}函数会在以下两种情况发生时触发哈希的扩容:
- 装载因子已经超过 6.5;
- 哈希使用了太多溢出桶;
不过由于 Go 语言哈希的扩容不是一个原子的过程,所以 函数还需要判断当前哈希是否已经处于扩容状态,避免二次扩容造成混乱。
sameSizeGrowsameSizeGrowsameSizeGrow扩容的入口是 函数:
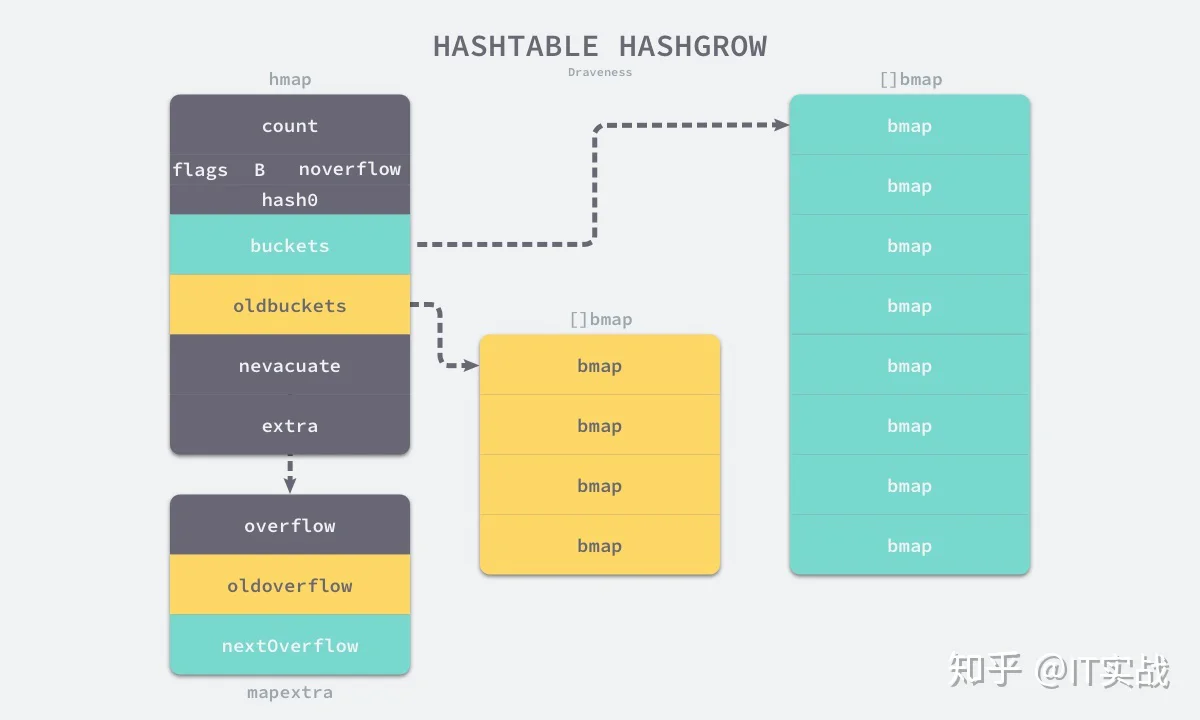
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
h.extra.nextOverflow = nextOverflow
}oldbucketsbuckets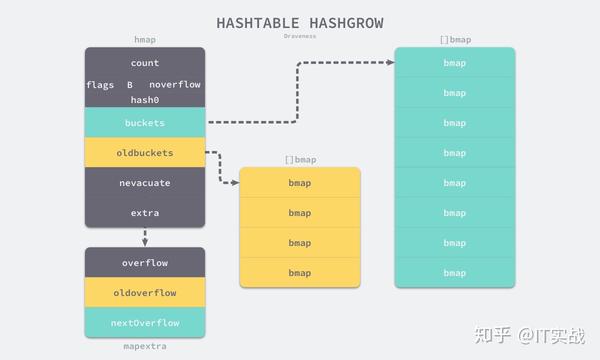
我们在 中还看不出来等量扩容和翻倍扩容的太多区别,等量扩容创建的新桶数量只是和旧桶一样,该函数中只是创建了新的桶,并没有对数据进行拷贝和转移,哈希表的数据迁移的过程在是 函数中完成的,它会对传入桶中的元素进行『再分配』。
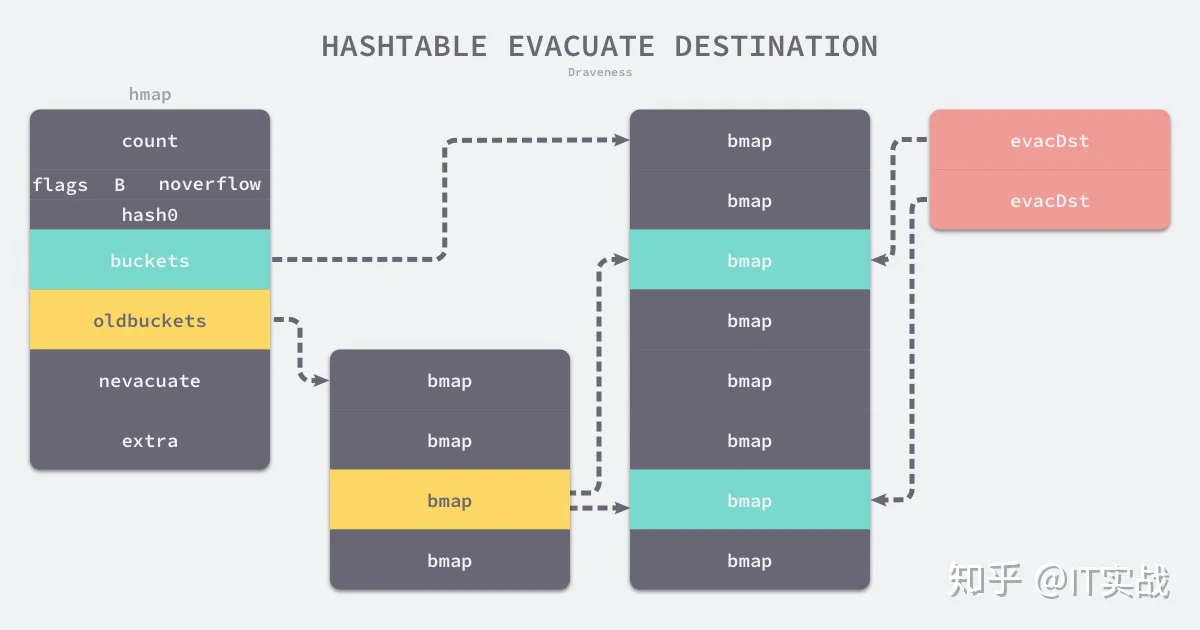
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
if !evacuated(b) {
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.v = add(x.k, bucketCnt*uintptr(t.keysize))
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.v = add(y.k, bucketCnt*uintptr(t.keysize))evacDst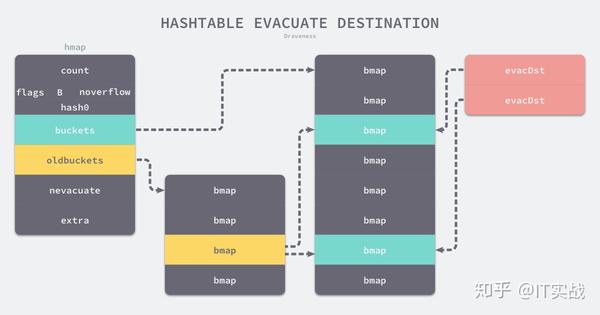
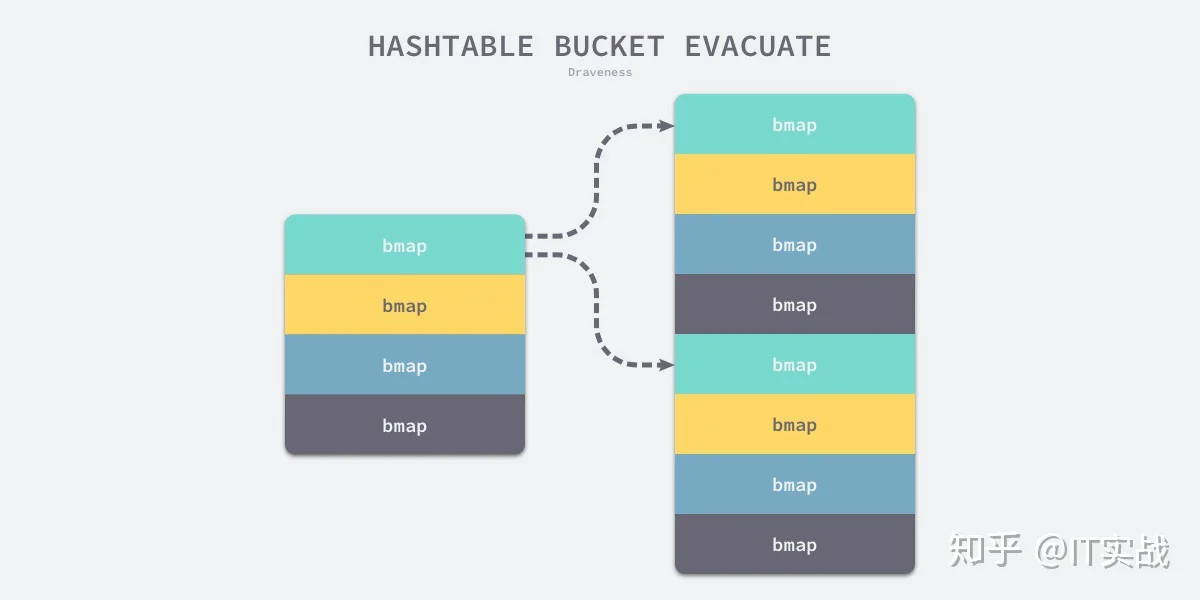
evacDstfor ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
v := add(k, bucketCnt*uintptr(t.keysize))
for i := 0; i < bucketCnt; i, k, v = i+1, add(k, uintptr(t.keysize)), add(v, uintptr(t.valuesize)) {
top := b.tophash[i]
k2 := k
var useY uint8
hash := t.key.alg.hash(k2, uintptr(h.hash0))
if hash&newbit != 0 {
useY = 1
}
b.tophash[i] = evacuatedX + useY
dst := &xy[useY]
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.v = add(dst.k, bucketCnt*uintptr(t.keysize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.key, dst.k, k)
typedmemmove(t.elem, dst.v, v)
dst.i++
dst.k = add(dst.k, uintptr(t.keysize))
dst.v = add(dst.v, uintptr(t.valuesize))
}
}
...
}b72bfae3f3285244c4732ce457cca823bc189e0b0b11(3)0xb72bfae3f3285244c4732ce457cca823bc189e0b & 0b11 #=> 00b110b111typedmemmove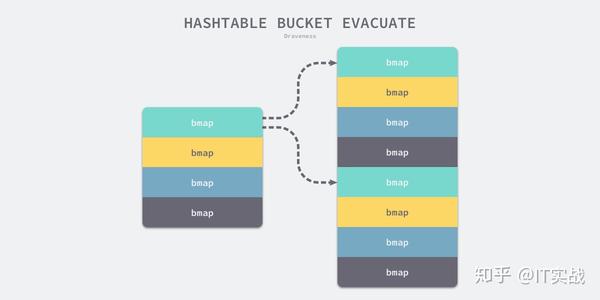
nevacuateoldbucketsoldoverflowfunc advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit == # of oldbuckets
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}oldbucketsfunc mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
bucketloop:
...
}因为旧桶中还没有被 函数分流,其中还保存着我们需要使用的数据,会替代新创建的空桶提供数据。
我们在 函数中也省略了一段逻辑,当哈希表正在处于扩容状态时,每次向哈希表写入值时都会触发 对哈希表的内容进行增量拷贝:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
...
}当然除了写入操作之外,删除操作也会在哈希表扩容期间触发 ,触发的方式和代码与这里的逻辑几乎完全相同,都是计算当前值所在的桶,然后对该桶中的元素进行拷贝。
sameSizeGrow删除
delete
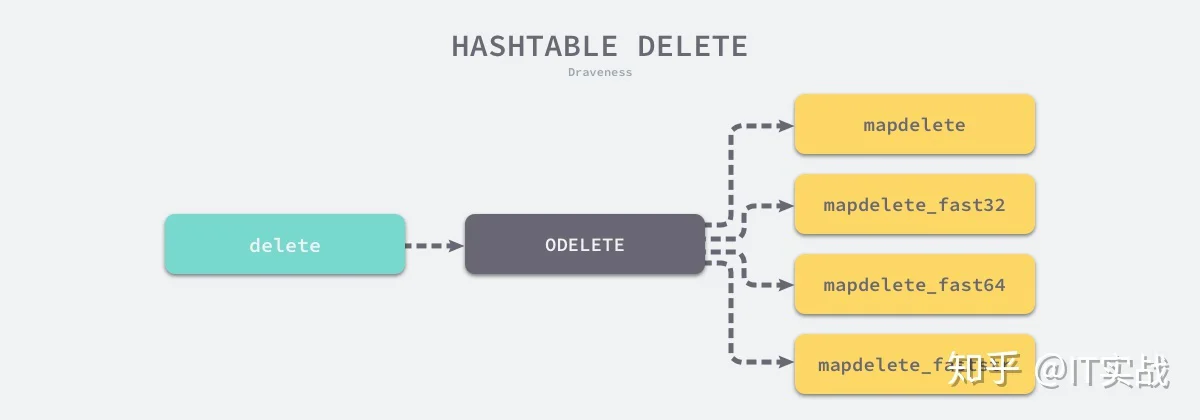
deleteODELETEODELETEmapdeletemapdeletemapdelete_faststrmapdelete_fast32mapdelete_fast64func walkexpr(n *Node, init *Nodes) *Node {
switch n.Op {
case ODELETE:
init.AppendNodes(&n.Ninit)
map_ := n.List.First()
key := n.List.Second()
map_ = walkexpr(map_, init)
key = walkexpr(key, init)
t := map_.Type
fast := mapfast(t)
if fast == mapslow {
key = nod(OADDR, key, nil)
}
n = mkcall1(mapfndel(mapdelete[fast], t), nil, init, typename(t), map_, key)
}
}这些函数的实现其实差不多,我们来分析其中的 函数,哈希表的删除逻辑与写入逻辑非常相似,只是触发哈希的删除需要使用关键字,如果在删除期间遇到了哈希表的扩容,就会对即将操作的桶进行分流,分流结束之后会找到桶中的目标元素完成键值对的删除工作。
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
...
if h.growing() {
growWork(t, h, bucket)
}
...
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break search
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if !alg.equal(key, k2) {
continue
}
*(*unsafe.Pointer)(k) = nil
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
*(*unsafe.Pointer)(v) = nil
b.tophash[i] = emptyOne
...
}
}
}delete5. 小结
Go 语言使用拉链法来解决哈希碰撞的问题实现了哈希表,它的访问、写入和删除等操作都在编译期间转换成了运行时的函数或者方法。
tophash随着键值对数量的增加,溢出桶的数量和哈希的装载因子也会逐渐升高,超过一定范围就会触发扩容,扩容会将桶的数量翻倍,元素再分配的过程也是在调用写操作时增量进行的,不会造成性能的瞬时巨大抖动。
全套教程点击下方链接直达: