
引言
日常项目,有时会出现oom的情况,这时候我们光依靠code review进行问题定位是很困难的。这里我们需要一个排查工具,来定位是哪里的代码导致内存溢出的,这个工具就是pprof
前提
如果是非http(s)服务类的,需要在代码中嵌入如下几行代码
import _ "net/http/pprof"
go func() {
http.ListenAndServe("0.0.0.0:8899", nil)
}()
如果是http(s)类的的服务,可以添加上所使用的pprof第三方库,如gin
import "github.com/gin-contrib/pprof"
//StartHttp 新建HTTP服务
func StartHttp() error {
router := gin.New()
...
pprof.Register(router)
addr := fmt.Sprintf(":%d", 8899)
if err := router.Run(addr); err != nil {
return err
}
return nil
}
使用
在浏览器中输入http://ip:8899/debug/pprof/可以看到一个汇总页面

其中heap项是我们需要关注的信息,可以点进去看下,但信息比较分散,没啥大用

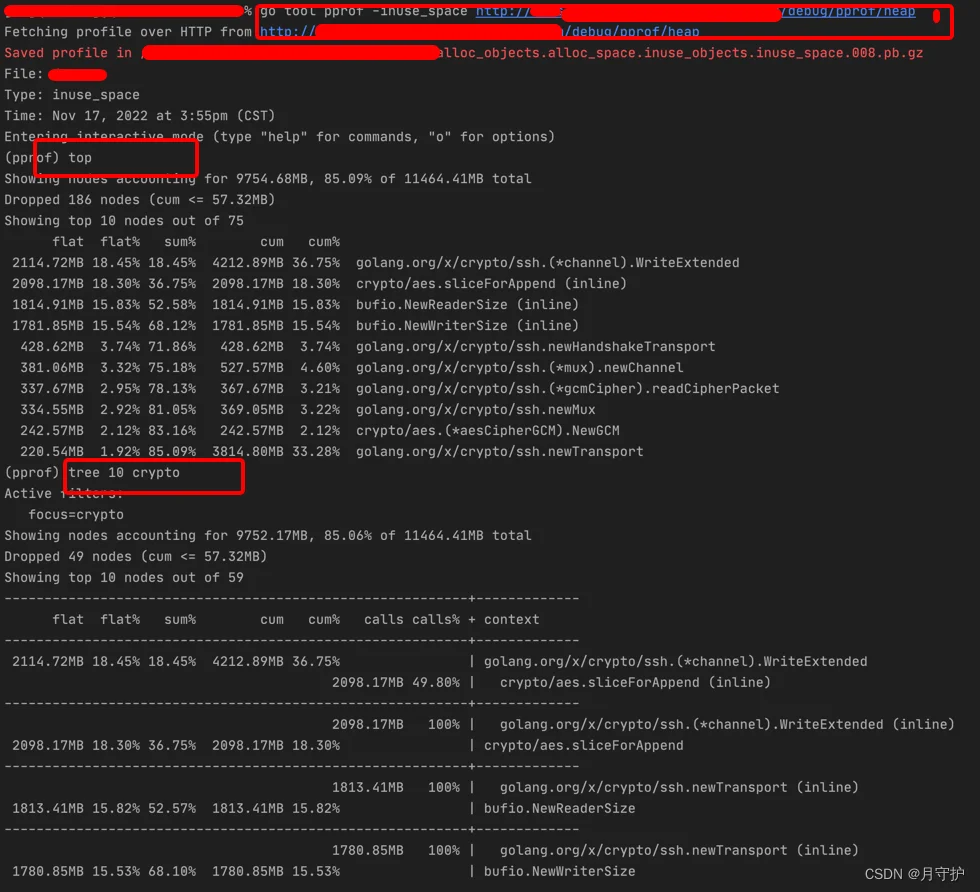
更有用的信息我们需要借助go tool pprof来进行分析
go tool pprof -alloc_space/-inuse_space http://ip:8899/debug/pprof/heap
# 注意 -alloc_space 和 -inuse_space 是两个可选项, 选一个
这里有两个选项,-alloc_space和-inuse_space,从名字应该能看出二者的区别,不过条件允许的话,我们优先使用-inuse_space来分析,因为直接分析导致问题的现场比分析历史数据肯定要直观的多,一个函数alloc_space多不一定就代表它会导致进程的RSS高,因为我们比较幸运可以在线下复现这个OOM的场景,所以直接用-inuse_space
进入后是一个交互界面
输入top命令可以前10大的内存分配
like this
(pprof) top
Showing nodes accounting for 3.73GB, 99.78% of 3.74GB total
Dropped 5 nodes (cum <= 0.02GB)
Showing top 10 nodes out of 16
flat flat% sum% cum cum%
3.70GB 98.94% 98.94% 3.70GB 98.94% bytes.makeSlice /usr/local/go/src/bytes/buffer.go
0.03GB 0.83% 99.78% 0.03GB 0.83% main.(*cmdRestore).Main /usr/local/go/src/bufio/bufio.go
0 0% 99.78% 3.70GB 98.94% bytes.(*Buffer).Write /usr/local/go/src/bytes/buffer.go
0 0% 99.78% 3.70GB 98.94% bytes.(*Buffer).grow /usr/local/go/src/bytes/buffer.go
0 0% 99.78% 3.70GB 98.94% github.com/CodisLabs/redis-port/pkg/rdb.(*Loader).NextBinEntry go_workspace/src/github.com/CodisLabs/redis-port/pkg/rdb/loader.go
0 0% 99.78% 3.70GB 98.94% github.com/CodisLabs/redis-port/pkg/rdb.(*rdbReader).Read go_workspace/src/github.com/CodisLabs/redis-port/pkg/rdb/reader.go
0 0% 99.78% 3.70GB 98.94% github.com/CodisLabs/redis-port/pkg/rdb.(*rdbReader).ReadBytes go_workspace/src/github.com/CodisLabs/redis-port/pkg/rdb/reader.go
0 0% 99.78% 3.70GB 98.94% github.com/CodisLabs/redis-port/pkg/rdb.(*rdbReader).ReadString go_workspace/src/github.com/CodisLabs/redis-port/pkg/rdb/reader.go
0 0% 99.78% 3.70GB 98.94% github.com/CodisLabs/redis-port/pkg/rdb.(*rdbReader).readFull go_workspace/src/github.com/CodisLabs/redis-port/pkg/rdb/reader.go
0 0% 99.78% 3.70GB 98.94% github.com/CodisLabs/redis-port/pkg/rdb.(*rdbReader).readObjectValue go_workspace/src/github.com/CodisLabs/redis-port/pkg/rdb/reader.go
top + num 可以指定前几
然后使用tree $num $target找到主要占用内存的调用关系,找到最终代码位置
指标
allocs:查看过去所有内存分配的样本。
block:查看导致阻塞同步的堆栈跟踪。
cmdline: 当前程序的命令行的完整调用路径。
goroutine:查看当前所有运行的 goroutines 堆栈跟踪。
heap:查看活动对象的内存分配情况。
mutex:查看导致互斥锁的竞争持有者的堆栈跟踪。
profile: 默认进行 30s 的 CPU Profiling,得到一个分析用的 profile 文件。
threadcreate:查看创建新 OS 线程的堆栈跟踪。
trace:略,trace可以单独写一篇文章来介绍。
注意,默认情况下是不追踪block和mutex的信息的,如果想要看这两个信息,需要在代码中加上两行:
runtime.SetBlockProfileRate(1) // 开启对阻塞操作的跟踪,block
runtime.SetMutexProfileFraction(1) // 开启对锁调用的跟踪,mutex
flat flat%
一个函数内的directly操作的物理耗时。例如
func foo(){
a() // step1
largeArray := [math.MaxInt64]int64{} // step2
for i := 0; i < math.MaxInt64; i++ { // step3
c() // step4
}
}
flat只会记录step2和step3的时间;flat%即是flat/总运行时间。内存等参数同理。
所有的flat相加即是总采样时间,所有的flat%相加应该等于100%。
flat一般是我们最关注的。其代表一个函数可能非常耗时,或者调用了非常多次,或者两者兼而有之,从而导致这个函数消耗了最多的时间。
如果是我们自己编写的代码,则很可能有一些无脑for循环、复杂的计算、字符串操作、频繁申请内存等等。
如果是第三方库的代码,则很可能我们过于频繁地调用了这些第三方库,或者以不正确的方式使用了这些第三方库。
cum cum%
相比flat,cum则是这个函数内所有操作的物理耗时,比如包括了上述的step1、2、3、4。
cum%即是cum的时间/总运行时间。内存等参数同理。
一般cum是我们次关注的,且需要结合flat来看。flat可以让我们知道哪个函数耗时多,而cum可以帮助我们找到是哪些函数调用了这些耗时的(flat值大的)函数。
sum%
其上所有行的flat%的累加。可以视为,这一行及其以上行,其所有的directly操作一共占了多少物理时间。
参考资料
https://zhuanlan.zhihu.com/p/396363069
https://developer.aliyun.com/article/573743