
TL;DR; 本文简要介绍 Golang 编译的各个阶段干了什么,即从源文件到最终的机器码中间经历的过程。并从汇编代码、AST 入手介绍了相关的应用场景及实现原理。本文第一节深度参考了 解析器眼中的 Go 语言,也非常推荐有时间的读者阅读原文。
编译原理
编译器的前端一般承担着词法分析、语法分析、类型检查和中间代码生成几部分工作.
编译器后端主要负责目标代码的生成和优化,也就是将中间代码翻译成目标机器能够运行的二进制机器码。
词法分析
过程:源代码文件 => 词法分析(lexer) => Token 序列
词法分析:词法分析是将字符序列转换为 Token 序列的过程。源代码在计算机看来其实就是一个由字符组成的、无法被理解的字符串,所有的字符在计算器看来并没有什么区别,为了理解这些字符我们需要做的第一件事情就是将字符串分组,即转换为 Token 序列,这能够降低理解字符串的成本,简化源代码的分析过程,这个转换的过程就是词法分析。
cmd/compile/internal/syntax.source.nextchcmd/compile/internal/syntax.scanner.next语法分析
过程:Token 序列 => 语法分析 => AST
语法分析:*语法分析*是根据某种特定的文法,对 Token 序列构成的输入文本进行分析并确定其语法结构的过程。语法分析由文法、分析方法构成。文法描述了语法的组成,分析方法则是解析文法的过程。
文法
上下文无关文法是用来形式化、精确描述某种编程语言的工具,我们能够通过文法定义一种语言的语法,它主要包含一系列用于转换字符串的生产规则(Production rule)。
下面是使用 EBNF 范式对 EBNF 本身进行描述:
生产规则是由 Term 与下述操作符组成:
src/cmd/compile/internal/syntax/parser.gopackageimportcmd/compile/internal/syntax.File分析方法
语法分析的分析方法一般分为自顶向下和自底向上两种,这两种方式会使用不同的方式对输入的 Token 序列进行推导:
- 自顶向下分析:解析器会从开始符号分析,通过新加入的字符判断应该使用什么生产规则展开当前的输入流;
- LL 使用自顶向下分析方法
- 自底向上分析:解析器会从输入流开始,维护一个栈用于存储未被归约的符号,当栈中符号满足规约条件,则会规约成对应的生产规则;
- LR(0)、SLR、LR(1) 和 LALR(1) 都是使用了自底向上的处理方式;
- Lookahead:在不同生产规则发生冲突时,解析器需要通过预读一些 Token 判断当前应该用什么生产规则对输入流进行展开或者归约,例如在 LALR(1) 文法中,需要预读一个 Token 保证出现冲突的生产规则能够被正确处理。
Go 语言的解析器使用了 LALR(1) 的文法来解析词法分析过程中输出的 Token 序列,得到 AST。
AST
语法分析器最终会使用不同的结构体来构建抽象语法树中的节点,File 是根结点。
src/cmd/compile/internal/syntax/nodes.go这里草草了解对 AST 的说明,在「应用」一节会举一个有关 AST 的例子,这里顺便推荐一个在线解析 AST 的工具。
另外,非常推荐一本详细讲解 AST 的书籍,有兴趣的读者可以查阅 https://chai2010.cn/go-ast-book/index.html。
类型检查
过程: AST => 类型检查 => 关键字改写的 AST
得到 AST 之后,对象类型、对象值已经出来了,这时候执行类型检查是很方便的事情;如果有任何类型不匹配,则会在该阶段抛出异常,这个过程叫做静态类型检查。
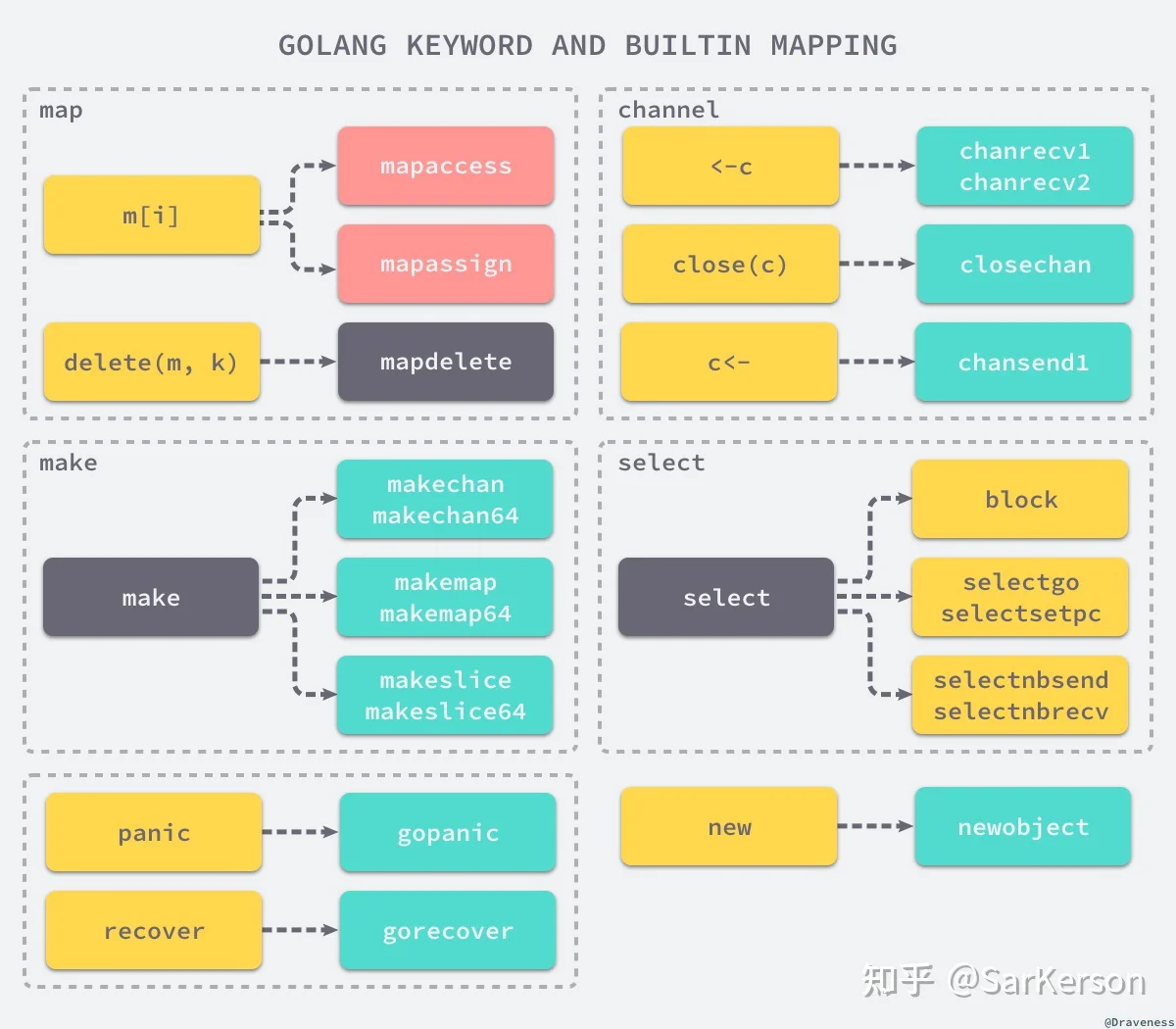
interface{}runtime.makesliceruntime.makechan中间代码生成
过程:AST => 并发编译所有函数 => SSA 等代码优化 => 中间代码
panicrecoverruntime.gopanicruntime.gorecovernewruntime.newobject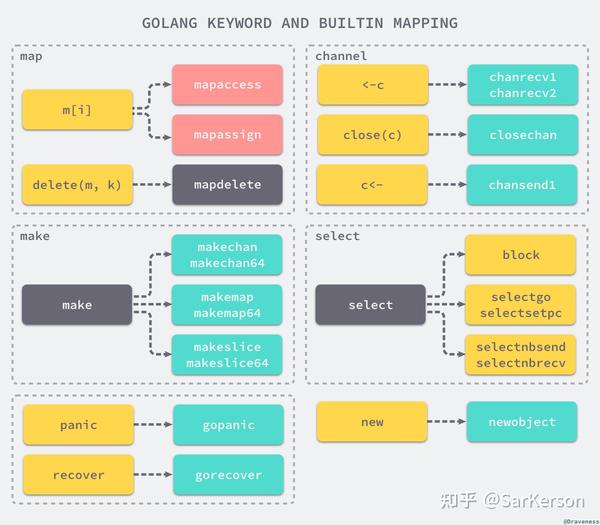
walkGOSSAFUNC=func_name go build main.go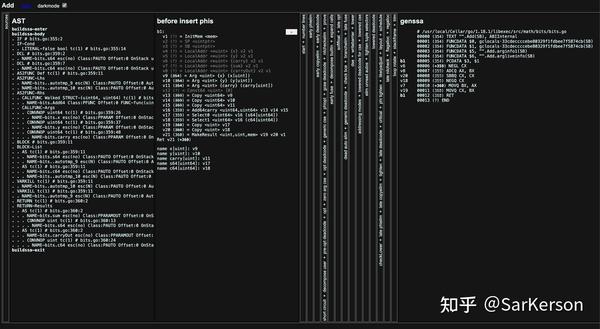
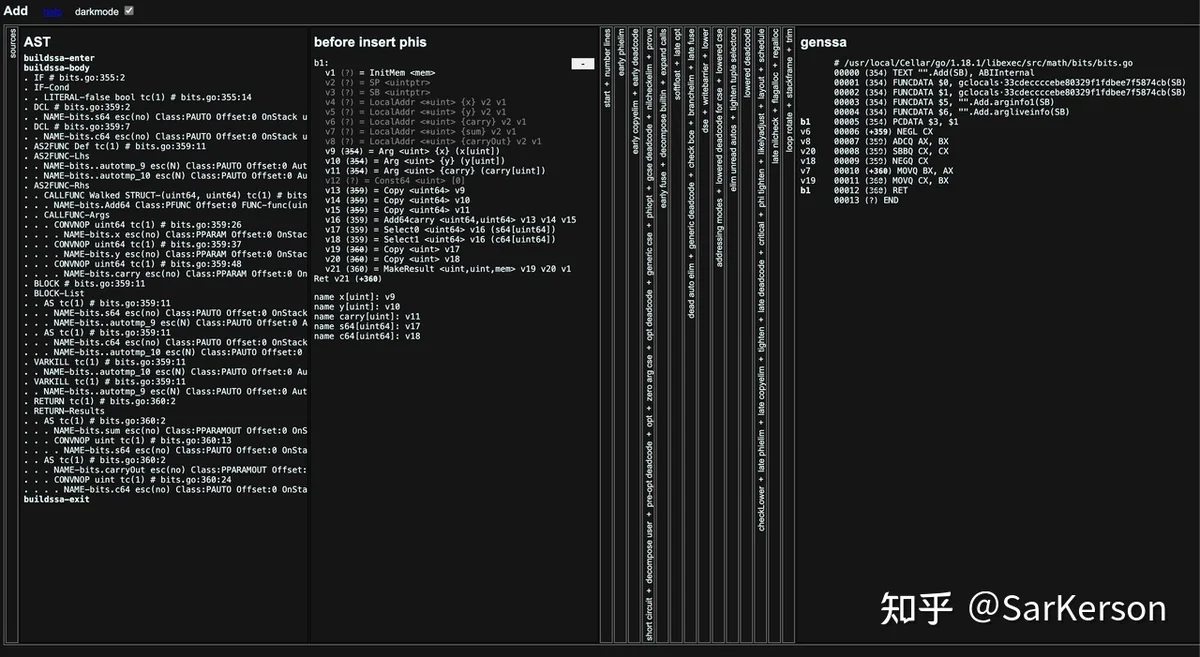
中间代码是一种更接近机器语言的表示形式,对中间代码的优化和分析相比直接分析高级编程语言更容易。
机器码生成
cmd/compile/internal/gc.Progs.Flushcmd/internal/objGOOS=linux GOARCH=amd64 go tool compile -S main.gogo tool objdump -s main 自举
$GOROOT_BOOTSTRAP应用
机器码
Monkey Patch
原理:获取 from 的函数地址 => 将跳转 to 的汇编指令替换 from 的函数体
Monkey Patch 是一个实现函数替换的工具,通常用在本地测试 Mock 数据的场景。这里简单介绍函数替换的实现原理。
replace(a, b)先看其汇编代码:
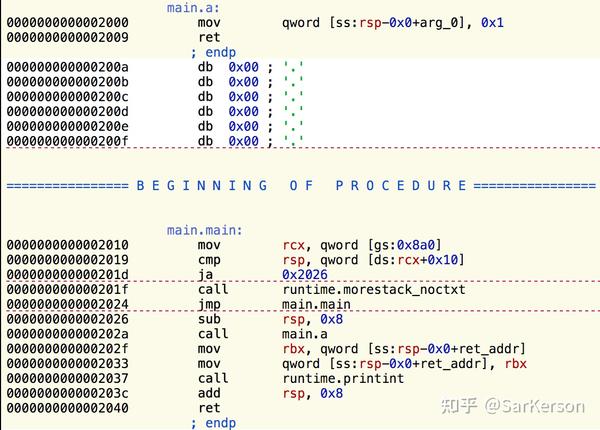
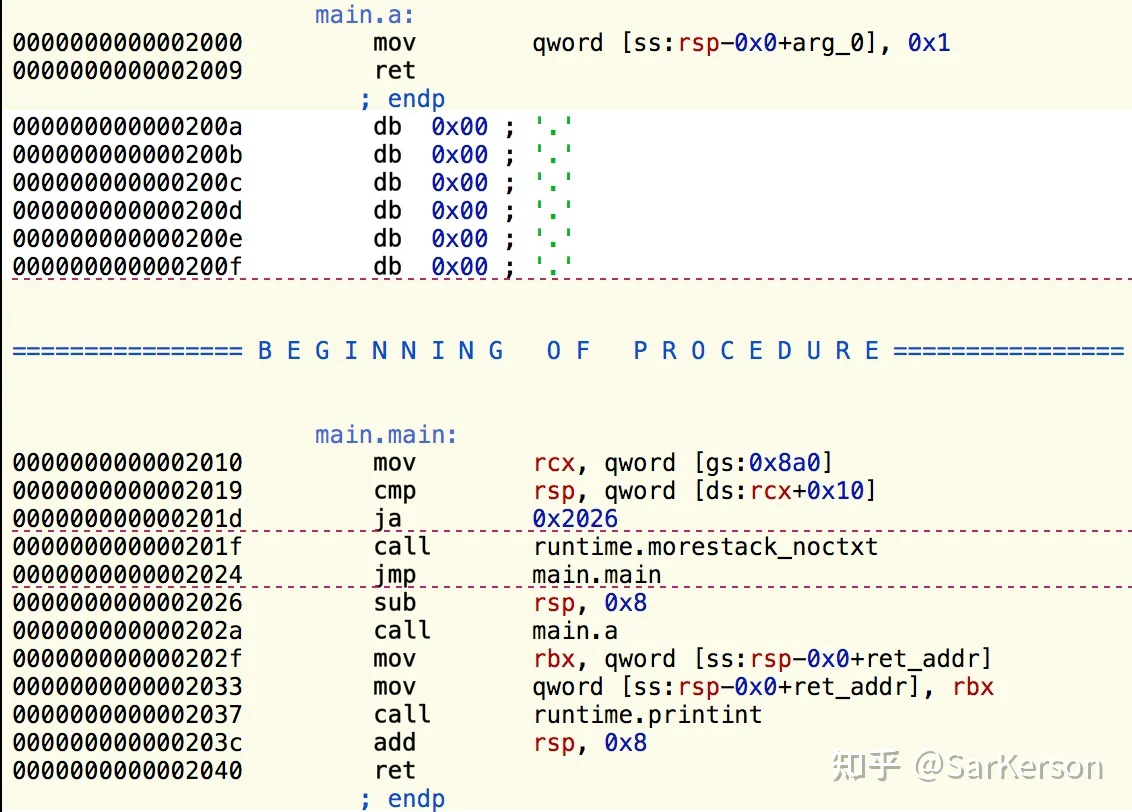
再强调一下,我们的目标是调用函数 a 的时候,实际上调用 b。
main.a那么,要达到目标,需要把下述汇编代码替换到 0x2000-0x2009 的内存位置。
main.a详细可以查阅原文,这里只是简单介绍一下实现的过程。
性能分析
我们借助 pprof 工具,对性能瓶颈进行分析。找到到更具体的问题代码块,可以再通过汇编分析等方法,定位到影响性能的代码。
下图是嵌套指针导致的指令依赖,而无法充分利用指令并行的一个例子。
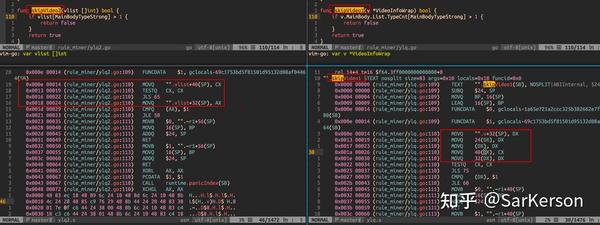
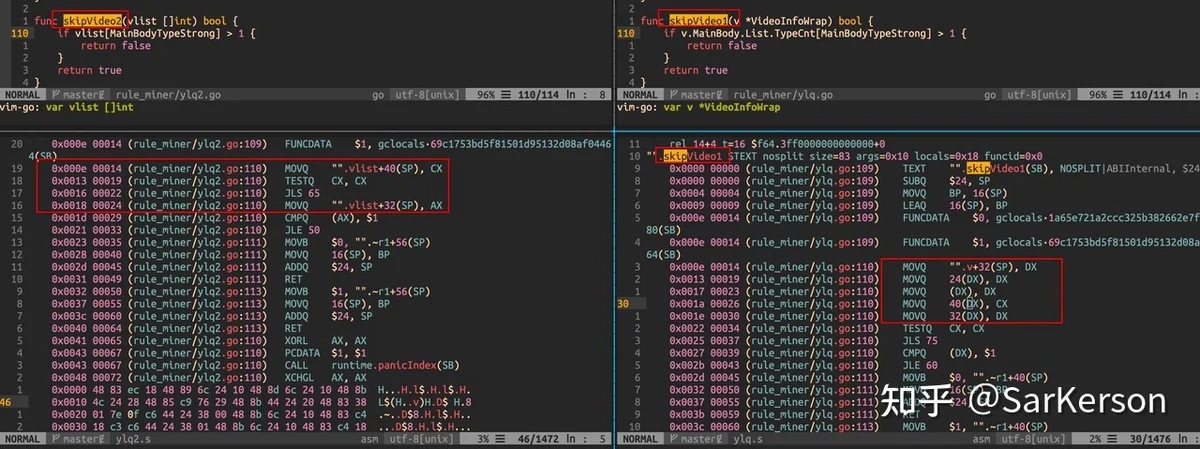
通过汇编指令分析性能瓶颈,帮助机器更好地优化,例如:
- 充分利用指令并行
- 避免不可预测的分支
- 提高指令缓存命中率
详细可以参阅 CSAPP 的第五章,之前记了相关的一段笔记:第五章 优化程序性能
AST
魔改代码
有时候,你需要批量修改代码。例如,你需要给很多个 Handler 添加一个公有的 BaseCheck 逻辑。
这时候,可选的做法是,加一个 BaseHandler 实现改 BaseCheck 方法,让其他 Handler 嵌套 BaseHandler 从而继承该公有方法。然后在所有的 Handler 的 check 方法中,调用继承过来的 BaseCheck 方法,即新增下述高亮部分的代码。
问题来了,当 handler 非常多(大型项目可能有几十上百个)时,手动给每个 handler 文件添加上述逻辑显然不是很爽。
回顾一下上面提到的 AST,我们可以利用 AST 解析整个 go 文件,得到所有的节点。那么当我知道需要在哪些节点上新增代码,便可以写代码来生成这部分代码,我们把这个工具暂称 generator。
这里面涉及两个步骤:
- 识别目标节点
- 插入新节点(要新增的代码块)
我们可以先手动对任何一个 handler 加这部分代码,然后观察其 AST,模仿该 AST 来编写 generator。上文提到一个在线解析 AST 的工具,我们把已经写好的 handler 贴进去,找到我们感兴趣的那部分逻辑。
例如你要给每个 Handler 的声明添加 *base_handler.BaseHandler 这个 field,我们来看对应的代码以及 AST:
更改目标节点
观察上述 AST,可以发现 *ast.File 这个源文件节点下面,声明部分 Decls 就有 Handler 的声明语句。这个声明中有一个 Fields 节点,就是 Handler 的字段定义。
根据该 AST 可以很方便写出目标节点的识别代码,本文使用了 "http://golang.org/x/tools/go/ast/astutil" 这个库,相比于 "go/ast" 库,astutil 支持获取节点的父节点等功能。
expr
expr 自己实现了一套语法,因此也有自己的一整套编译过程。只不过得到了 AST 之后,转换为命令+参数的形式用栈来模拟程序的执行。
gocover
go test coverage 采用的方法是在生成的 AST 上直接进行编辑,注入统计逻辑,然后根据编辑后的 AST 反向生成代码。
Gootprint
Gootprint 是字节内部一个用于对代码控制流进行统计的工具。 其原理与 gocover 实际上是类似,通过 AST 找到条件分支。不同点在于,这里插入的不是目标代码的 AST Node,而是插入一个 FrameNode 的自定义 Node,同时将其加入 Frame Tree。
在获得了 Frame Tree 之后,Code Generator 会对 Frame Tree 做先序遍历,并且在 Frame 的开始行和结束行号的位置注册 Frame 的 call back(即直接以字符串形式插入代码段)。