
Golang 是一门需要编译才能运行的编程语言,也就说代码在运行之前需要通过编译器生成二进制机器码,随后二进制文件才能在目标机器上运行,如果我们想要了解 Go 语言的实现原理,理解它的编译过程就是一个没有办法绕过的事情。
这一节会先对 Go 语言编译的过程进行概述,从顶层介绍编译器执行的几个步骤,随后的章节会分别剖析各个步骤完成的工作和实现原理,同时也会对一些需要预先掌握的知识进行介绍和准备,确保后面的章节能够被更好的理解。
预备知识
想要深入了解 Go 语言的编译过程,需要提前了解一下编译过程中涉及的一些术语和专业知识。这些知识其实在我们的日常工作和学习中比较难用到,但是对于理解编译的过程和原理还是非常重要的。这一小节会简单挑选几个常见并且重要的概念提前进行介绍,减少后面章节的理解压力。
抽象语法树
2 * 3 + 7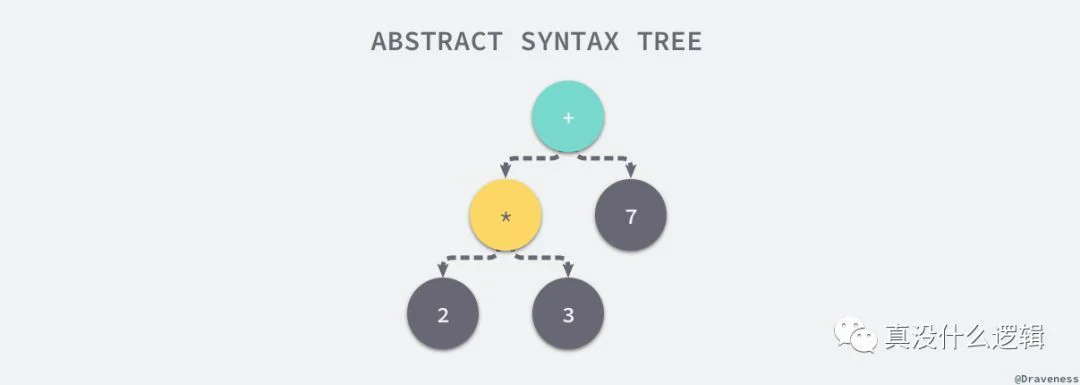
abstract-syntax-tree
作为编译器常用的数据结构,抽象语法树抹去了源代码中不重要的一些字符 - 空格、分号或者括号等等。编译器在执行完语法分析之后会输出一个抽象语法树,这棵树会辅助编译器进行语义分析,我们可以用它来确定结构正确的程序是否存在一些类型不匹配或不一致的问题。
静态单赋值
静态单赋值(SSA)是中间代码的一个特性,如果一个中间代码具有静态单赋值的特性,那么每个变量就只会被赋值一次,在实践中我们通常会用添加下标的方式实现每个变量只能被赋值一次的特性,这里以下面的代码举一个简单的例子:
x := 1
x := 2
y := x
1xx1 := 1
x2 := 2
y1 := x2
y1x1根据 Wikipedia 对 SSA 的介绍来看,在中间代码中使用 SSA 的特性能够为整个程序实现以下的优化:
常数传播(constant propagation)
值域传播(value range propagation)
稀疏有条件的常数传播(sparse conditional constant propagation)
消除无用的程式码(dead code elimination)
全域数值编号(global value numbering)
消除部分的冗余(partial redundancy elimination)
强度折减(strength reduction)
寄存器分配(register allocation)
从 SSA 的作用我们就能看出,因为它的主要作用就是代码的优化,所以是编译器后端(主要负责目标代码的优化和生成)的一部分;当然,除了 SSA 之外代码编译领域还有非常多的中间代码优化方法,优化编译器生成的代码是一个非常古老并且复杂的领域,这里就不会展开介绍了。
指令集架构
最后要介绍的一个预备知识就是指令集的架构了,很多开发者都会遇到在生产环境运行的结果和本地不同的问题,导致这种情况的原因其实非常复杂,不同机器使用不同的指令也是可能的原因之一。
uname -m$ uname -m
x86_64
x86_64 是目前比较常见的指令集架构之一,除了 x86_64 之外,还包含其他类型的指令集架构,例如 amd64、arm64 以及 mips 等等,不同的处理器使用了大不相同的机器语言,所以很多编程语言为了在不同的机器上运行需要将源代码根据架构翻译成不同的机器代码。
复杂指令集计算机(CISC)和精简指令集计算机(RISC)是目前的两种 CPU 区别,它们的在设计理念上会有一些不同,从名字我们就能看出来这两种不同的设计有什么区别,复杂指令集通过增加指令的数量减少需要执行的质量数,而精简指令集能使用更少的指令完成目标的计算任务;早期的 CPU 为了减少机器语言指令的数量使用复杂指令集完成计算任务,这两者之前的区别其实就是设计上的权衡,我们会在后面的章节 机器码生成 中详细介绍指令集架构,当然各位读者也可以自行搜索和学习。
编译原理
cmd/compile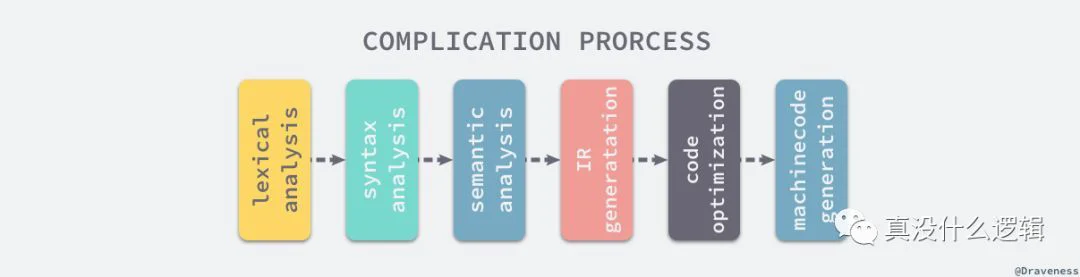
complication-process
Go 的编译器在逻辑上可以被分成四个阶段:词法与语法分析、类型检查和 AST 转换、通用 SSA 生成和最后的机器代码生成,在这一节我们会使用比较少的篇幅分别介绍这四个阶段做的工作,后面的章节会具体介绍每一个阶段的具体内容。
词法与语法分析
所有的编译过程其实都是从解析代码的源文件开始的,词法分析的作用就是解析源代码文件,它将文件中的字符串序列转换成 Token 序列,方便后面的处理和解析,我们一般会把执行词法分析的程序称为词法解析器(lexer)。
SourceFileSourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
标准的 Golang 语法解析器使用的就是 LALR(1) 的文法,语法解析的结果其实就是上面介绍过的抽象语法树(AST),每一个 AST 都对应着一个单独的 Go 语言文件,这个抽象语法树中包括当前文件属于的包名、定义的常量、结构体和函数等。

golang-files-and-ast
如果在语法解析的过程中发生了任何语法错误,都会被语法解析器发现并将消息打印到标准输出上,整个编译过程也会随着错误的出现而被中止。
我们会在这一章后面的小节 词法与语法分析 中介绍 Go 语言的文法和它的词法与语法解析过程。
类型检查
当拿到一组文件的抽象语法树 AST 之后,Go 语言的编译器会对语法树中定义和使用的类型进行检查,类型检查分别会按照顺序对不同类型的节点进行验证,按照以下的顺序进行处理:
常量、类型和函数名及类型;
变量的赋值和初始化;
函数和闭包的主体;
哈希键值对的类型;
导入函数体;
外部的声明;
通过对每一棵抽象节点树的遍历,我们在每一个节点上都会对当前子树的类型进行验证保证当前节点上不会出现类型错误的问题,所有的类型错误和不匹配都会在这一个阶段被发现和暴露出来。
makemakeslicemakechangolang-keyword-make
我们其实能够看出类型检查不止做了验证类型的工作,还做了对 AST 进行改写,处理 Go 语言内置关键字的活,所以,这一过程在整个编译流程中还是非常重要的,没有这个步骤很多关键字其实就没有办法工作,后面的章节 类型检查 会介绍这一步骤。
中间代码生成
当我们将源文件转换成了抽象语法树、对整棵树的语法进行解析并进行类型检查之后,就可以认为当前文件中的代码基本上不存在无法编译或者语法错误的问题了,Go 语言的编译器就会将输入的 AST 转换成中间代码。
Go 语言编译器的中间代码使用了 SSA(Static Single Assignment Form) 的特性,如果我们在中间代码生成的过程中使用这种特性,就能够比较容易的分析出代码中的无用变量和片段并对代码进行优化。
compileFunctions中间代码生成 这一章节会详细介绍中间代码的生成过程并简单介绍 Golang 是如何在中间代码中使用 SSA 的特性的,在这里就不展开介绍其他的内容了。
机器码生成
cmd/compile/internal作为一种在栈虚拟机上使用的二进制指令格式,它的设计的主要目标就是在 Web 浏览器上提供一种具有高可移植性的目标语言。Go 语言的编译器既然能够生成 WASM 格式的指令,那么就能够运行在常见的主流浏览器中。
$ GOARCH=wasm GOOS=js go build -o lib.wasm main.go
我们可以使用上述的命令将 Go 的源代码编译成能够在浏览器上运行的『汇编语言』,除了这种新兴的指令之外,Go 语言还支持了几乎全部常见的 CPU 指令集类型,也就是说它编译出的机器码能够在使用上述指令集的机器上运行。
机器码生成 一节会详细介绍将中间代码翻译到不同目标机器的过程,在这个章节中也会简单介绍不同的指令集架构的区别。
编译器入口
src/cmd/compile/internal/pcMainparseFilesfunc Main(archInit func(*Arch)) {
// ...
lines := parseFiles(flag.Args())
接下来就会分九个阶段对抽象语法树进行更新和编译,就像我们在上面介绍的,整个过程会经历类型检查、SSA 中间代码生成以及机器码生成三个部分:
检查常量、类型和函数的类型;
处理变量的赋值;
对函数的主体进行类型检查;
决定如何捕获变量;
检查内联函数的类型;
进行逃逸分析;
将闭包的主体转换成引用的捕获变量;
编译顶层函数;
检查外部依赖的声明;
了解了剩下的编译过程之后,我们重新回到词法和语法分析后的具体流程,在这里编译器会对生成语法树中的节点执行类型检查,除了常量、类型和函数这些顶层声明之外,它还会对变量的赋值语句、函数主体等结构进行检查:
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op != ODCL && op != OAS && op != OAS2 && (op != ODCLTYPE || !n.Left.Name.Param.Alias) {
xtop[i] = typecheck(n, ctxStmt)
}
}
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op == ODCL || op == OAS || op == OAS2 || op == ODCLTYPE && n.Left.Name.Param.Alias {
xtop[i] = typecheck(n, ctxStmt)
}
}
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op == ODCLFUNC || op == OCLOSURE {
typecheckslice(Curfn.Nbody.Slice(), ctxStmt)
}
}
checkMapKeys()
for _, n := range xtop {
if n.Op == ODCLFUNC && n.Func.Closure != nil {
capturevars(n)
}
}
escapes(xtop)
for _, n := range xtop {
if n.Op == ODCLFUNC && n.Func.Closure != nil {
transformclosure(n)
}
}
make initssaconfig()
peekitabs()
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if n.Op == ODCLFUNC {
funccompile(n)
}
}
compileFunctions()
for i, n := range externdcl {
if n.Op == ONAME {
externdcl[i] = typecheck(externdcl[i], ctxExpr)
}
}
checkMapKeys()
}
在主程序运行的最后,会将顶层的函数编译成中间代码并根据目标的 CPU 架构生成机器码,不过这里其实也可能会再次对外部依赖进行类型检查以验证正确性。
总结
Go 语言的编译过程其实是非常有趣并且值得学习的,通过对 Go 语言四个编译阶段的分析和对编译器主函数的梳理,我们能够对 Golang 的实现有一些基本的理解,掌握编译的过程之后,Go 语言对于我们来讲也不再是一个黑盒,所以学习其编译原理的过程还是非常让人着迷的。