
sync.Pool 是 Golang 内置的对象池技术,可用于缓存临时对象,避免因频繁建立临时对象所带来的消耗以及对 GC 造成的压力。
gin.Context但需要注意的是,sync.Pool 缓存的对象随时可能被无通知的清除,因此不能将 sync.Pool 用于存储持久对象的场景。
sync.Pool 作为 goroutine 内置的官方库,其设计非常精妙。sync.Pool 不仅是并发安全的,而且实现了 lock free,里面有许多值得学习的知识点。
本文将基于 go-1.16 的源码 对 sync.Pool 的底层实现一探究竟。
基本用法
在正式讲 sync.Pool 底层之前,我们先看下 sync.Pool 的基本用法。其示例代码如下:
NewGetPut接下来,让我们详细看下 sync.Pool 是如何实现的。
sync.Pool 的底层实现
在讲 sync.Pool 之前,我们先聊下 Golang 的 GMP 调度。在 GMP 调度模型中,M 代表了系统线程,而同一时间一个 M 上只能同时运行一个 P。那么也就意味着,从线程维度来看,在 P 上的逻辑都是单线程执行的。
poolLocal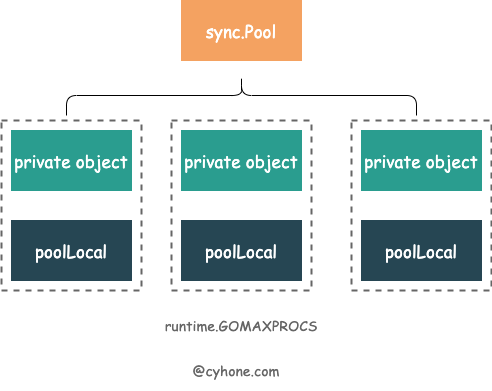
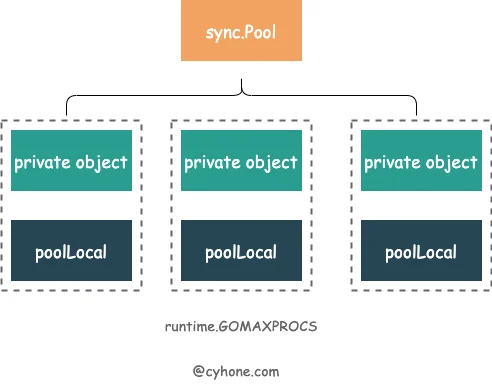
sync.Pool 的 代码定义如下 sync/pool.go#L44:
localpoolLocal[P]poolLocallocalSizelocalSizelocalNewvictimvictimSizenoCopygo vet由于每个 P 都有自己的一个本地对象池 poolLocal,Get 和 Put 操作都会优先存取本地对象池。由于 P 的特性,操作本地对象池的时候整个并发问题就简化了很多,可以尽量避免并发冲突。
poolLocalpadprivatesharedpoolChain 的实现
poolChain 的整个存储结构如下图所示:
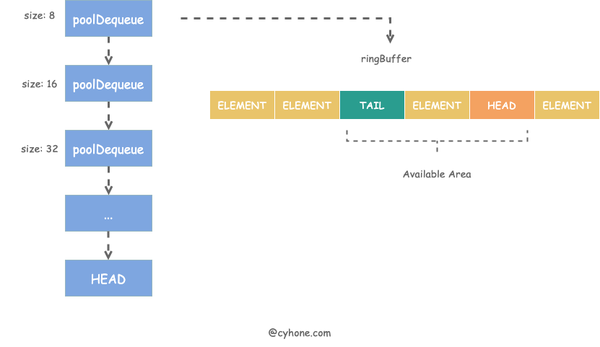
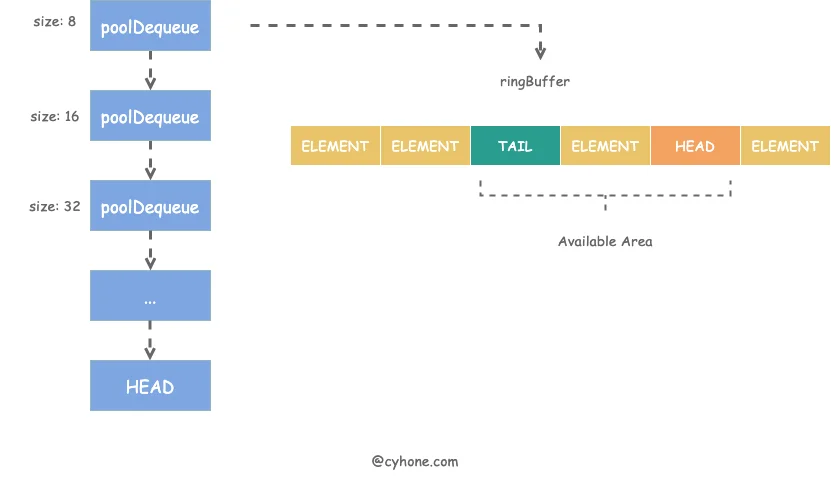
从名字大概就可以猜出,poolChain 是个链表结构,其链表头 HEAD 指向最新分配的元素项。链表中的每一项是一个 poolDequeue 对象。poolDequeue 本质上是一个 ring buffer 结构。其对应的代码定义如下:
为什么 poolChain 是这么一个链表 + ring buffer 的复杂结构呢?简单的每个链表项为单一元素不行吗?
使用 ring buffer 是因为它有以下优点: 1. 预先分配好内存,且分配的内存项可不断复用。 2. 由于ring buffer 本质上是个数组,是连续内存结构,非常利于 CPU Cache。在访问poolDequeue 某一项时,其附近的数据项都有可能加载到统一 Cache Line 中,访问速度更快。
ring buffer 的这两个特性,非常适合于 sync.Pool的应用场景。
我们再注意看一个细节,poolDequeue 作为一个 ring buffer,自然需要记录下其 head 和 tail 的值。但在 poolDequeue 的定义中,head 和 tail 并不是独立的两个变量,只有一个 uint64 的 headTail 变量。
这是因为 headTail 变量将 head 和 tail 打包在了一起:其中高 32 位是 head 变量,低 32 位是 tail 变量。如下图所示:

为什么会有这个复杂的打包操作呢?这个其实是个非常常见的 lock free 优化手段。我们在 《Golang WaitGroup 原理深度剖析》 一文中也讨论过这种方法。
对于一个 poolDequeue 来说,可能会被多个 P 同时访问(具体原因见下文 Get 函数中的对象窃取逻辑),这个时候就会带来并发问题。
head - tail = 1在不引入 Mutex 锁的前提下,sync.Pool 是怎么实现的呢?sync.Pool 利用了 atomic 包中的 CAS 操作。两个 P 都可能会拿到对象,但在最终设置 headTail 的时候,只会有一个 P 调用 CAS 成功,另外一个 CAS 失败。
head++Put 的实现
我们看下 Put 函数的实现。通过 Put 函数我们可以把不用的对象放回或者提前放到 sync.Pool 中。Put 函数的代码逻辑如下:
pin()pinruntime.GOMAXPROCS- 防止当前 P 被抢占。 这点非常重要。在 Go 1.14 以后,Golang 实现了抢占式调度:一个 goroutine 占用 P 时间过长,将会被调度器强制挂起。如果一个 goroutine 在执行 Put 或者 Get 期间被挂起,有可能下次恢复时,绑定就不是上次的 P 了。那整个过程就会完全乱掉。因此,这里使用了 runtime 包里面的 procPin,暂时不允许 P 被抢占。
private如果私有变量之前已经设置过了,那就只能往当前 P 的本地缓存池 poolChain 里面写了。我们接下来看下,sync.Pool 的每个 P 的内部缓存池 poolChain 是怎么实现的。
在 Put 的时候,会去直接取 poolChain 的链表头元素 HEAD: 如果 HEAD 不存在 ,则新建一个 buffer 长度为 8 的 poolDequeue,并将对象放置在里面。 如果 HEAD 存在,且 buffer 尚未满,则将元素直接放置在 poolDequeue 中。 * 如果 HEAD 存在,但 buffer 满了,则新建一个新的 poolDequeue,长度为上个 HEAD 的 2 倍。同时,将 poolChain 的 HEAD 指向新的元素。
Put 的过程比较简单,整个过程不需要和其他 P 的 poolLocal 进行交互。
Get 的实现
在了解 Put 是如何实现后,我们接着看 Get 的实现。通过 Get 操作,可以从 sync.Pool 中获取一个对象。
相比于 Put 函数,Get 的实现更为复杂。不仅涉及到对当前 P 本地对象池的操作,还涉及对其他 P 的本地对象池的对象窃取。其代码逻辑如下:
pin()private首先,Get 函数会尝试从当前 P 的 本地对象池 poolChain 中获取对象。从当前 P 的 poolChain 中取数据时,是从链表头部开始取数据。 具体来说,先取位于链表头的 poolDequeue,然后从 poolDequeue 的头部开始取数据。
如果从当前 P 的 poolChain 取不到数据,意味着当前 P 的缓存池为空,那么将尝试从其他 P 的缓存池中 窃取对象。这也对应 getSlow 函数的内部实现。
在 getSlow 函数,会将当前 P 的索引值不断递增,逐个尝试从其他 P 的 poolChain 中取数据。注意,当尝试从其他 P 的 poolChain 中取数据时,是从链表尾部开始取的。
在对其他 P 的 poolChain 调用 popTail,会先取位于链表尾部的 poolDequeue,然后从 poolDequeue 的尾部开始取数据。如果从这个 poolDequeue 中取不到数据,则意味着该 poolDequeue 为空,则直接从该 poolDequeue 从 poolChain 中移除,同时尝试下一个 poolDequeue。
如果从其他 P 的本地对象池,也拿不到数据。接下来会尝试从 victim 中取数据。上文讲到 victim 是上一轮被清理的对象池, 从 victim 取对象也是 popTail 的方式。
New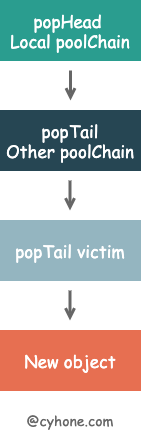
sync.Pool 在设计的时候,当操作本地的 poolChain 时,无论是 push 还是 pop,都是从头部开始。而当从其他 P 的 poolChain 获取数据,只能从尾部 popTail 取。这样可以尽量减少并发冲突。
对象的清理
sync.Pool 没有对外开放对象清理策略和清理接口。我们上面讲到,当窃取其他 P 的对象时,会逐步淘汰已经为空的 poolDequeue。但除此之外,sync.Pool 一定也还有其他的对象清理机制,否则对象池将可能会无限制的膨胀下去,造成内存泄漏。
allPools []*Pool这里需要正式介绍下 sync.Pool 的 victim(牺牲者) 机制,我们在 Get 函数的对象窃取逻辑中也有提到 victim。
在每轮 sync.Pool 的清理中,暂时不会完全清理对象池,而是将其放在 victim 中。等到下一轮清理,才完全清理掉 victim。也就是说,每轮 GC 后 sync.Pool 的对象池都会转移到 victim 中,同时将上一轮的 victim 清空掉。
为什么这么做呢? 这是因为 Golang 为了防止 GC 之后 sync.Pool 被突然清空,对程序性能造成影响。因此先利用 victim 作为过渡,如果在本轮的对象池中实在取不到数据,也可以从 victim 中取,这样程序性能会更加平滑。
victim 机制最早用在 CPU Cache 中,详细可以阅读这篇 wiki: Victim_cache。
其他的优化
false sharing 问题的避免
我们在上面讲到 poolLocal 时,会发现这么一个奇怪的结构:poolLocal 有一个 pad 属性,从这个属性的定义方式来看,明显是为了凑齐了 128 Byte 的整数倍。为什么会这么做呢?
这里是为了避免 CPU Cache 的 false sharing 问题:CPU Cache Line 通常是以 64 byte 或 128 byte 为单位。在我们的场景中,各个 P 的 poolLocal 是以数组形式存在一起。假设 CPU Cache Line 为 128 byte,而 poolLocal 不足 128 byte 时,那 cacheline 将会带上其他 P 的 poolLocal 的内存数据,以凑齐一整个 Cache Line。如果这时,两个相邻的 P 同时在两个不同的 CPU 核上运行,将会同时去覆盖刷新 CacheLine,造成 Cacheline 的反复失效,那 CPU Cache 将失去了作用。
CPU Cache 是距离 CPU 最近的 cache,如果能将其运用好,会极大提升程序性能。Golang 这里为了防止出现 false sharing 问题,主动使用 pad 的方式凑齐 128 个 byte,这样就不会和其他 P 的 poolLocal 共享一套 CacheLine。
sync.Pool 的性能之道
pin