
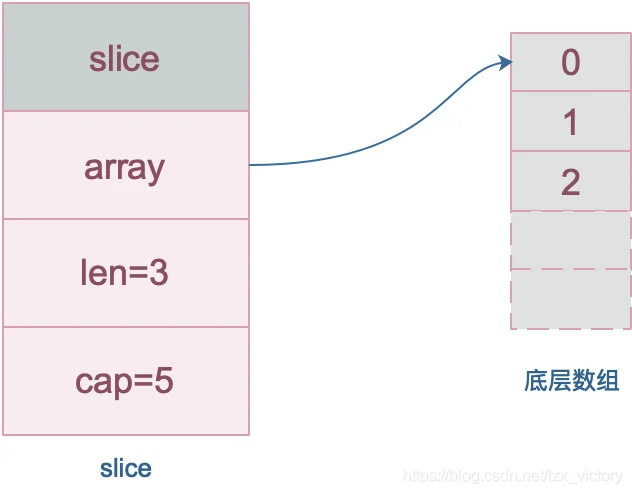
数组与切片
数组:最基本的数据结构,特点是定长.
切片:基于数组实现,底层的数据结构以数组为基础,可以动态的扩容.
type slice struct {
array unsafe.Pointer
len int
cap int
}
切片扩容
当原 slice 容量小于 1024 的时候,新 slice 容量变成原来的 2 倍;原 slice 容量超过 1024,新 slice 容量变成原来的1.25倍。然后再进行一个内存对齐的操作,实际的容量是会大于2倍和1.25倍.
函数传参
函数传参如果传入slice更新底层的数据,会反应到实际的参数.底层数据在 slice 结构体里是一个指针,仅管 slice 结构体自身不会被改变,也就是说底层数据地址不会被改变。append操作不会反应到实际的参数.
Map
Map实现就是传统的hash结构,注意Go语言当中的Map访问不是并发安全的,因此需要特别注意并发访问的问题.Map 不能进行并发读写.
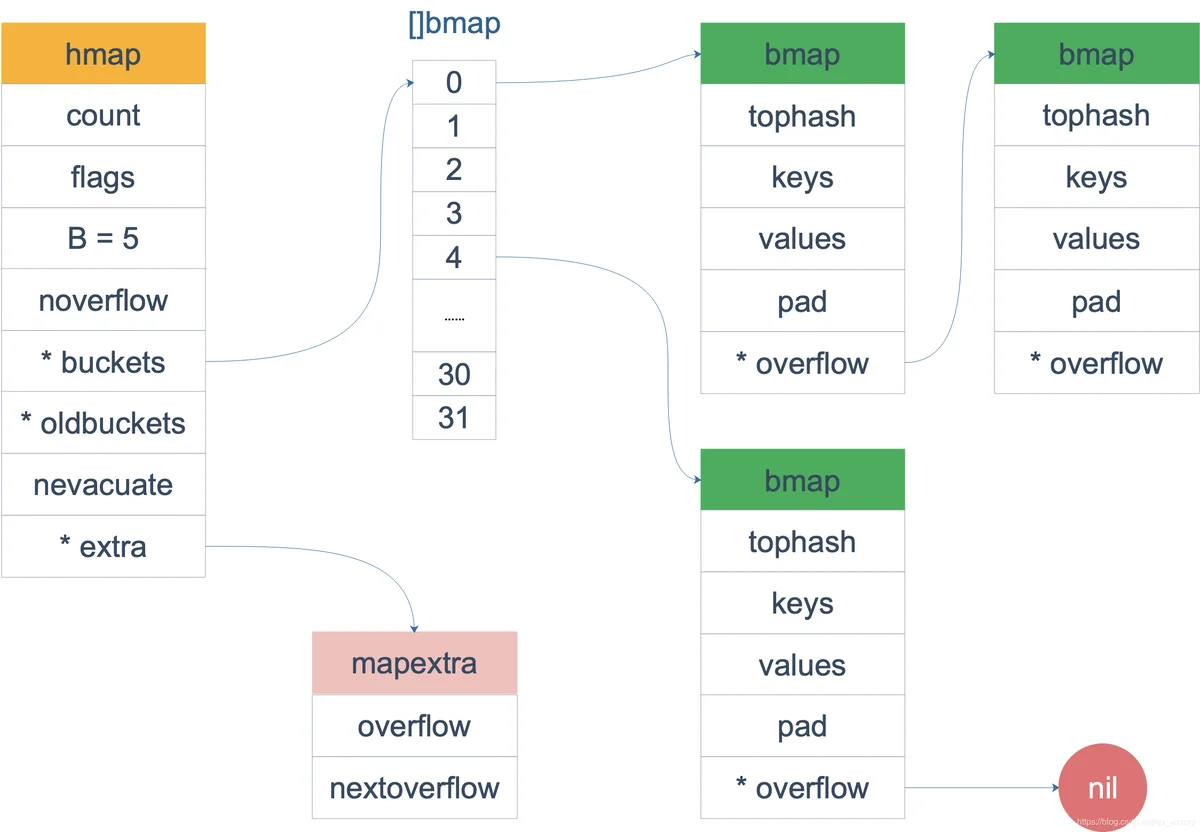
Map底层数据结构
Map的内存模型:
// A header for a Go map.
type hmap struct {
// 元素个数,调用 len(map) 时,直接返回此值
count int
flags uint8
// buckets 的对数 log_2
B uint8
// overflow 的 bucket 近似数
noverflow uint16
// 计算 key 的哈希的时候会传入哈希函数
hash0 uint32
// 指向 buckets 数组,大小为 2^B
// 如果元素个数为0,就为 nil
buckets unsafe.Pointer
// 等量扩容的时候,buckets 长度和 oldbuckets 相等
// 双倍扩容的时候,buckets 长度会是 oldbuckets 的两倍
oldbuckets unsafe.Pointer
// 指示扩容进度,小于此地址的 buckets 迁移完成
nevacuate uintptr
extra *mapextra // optional fields
}
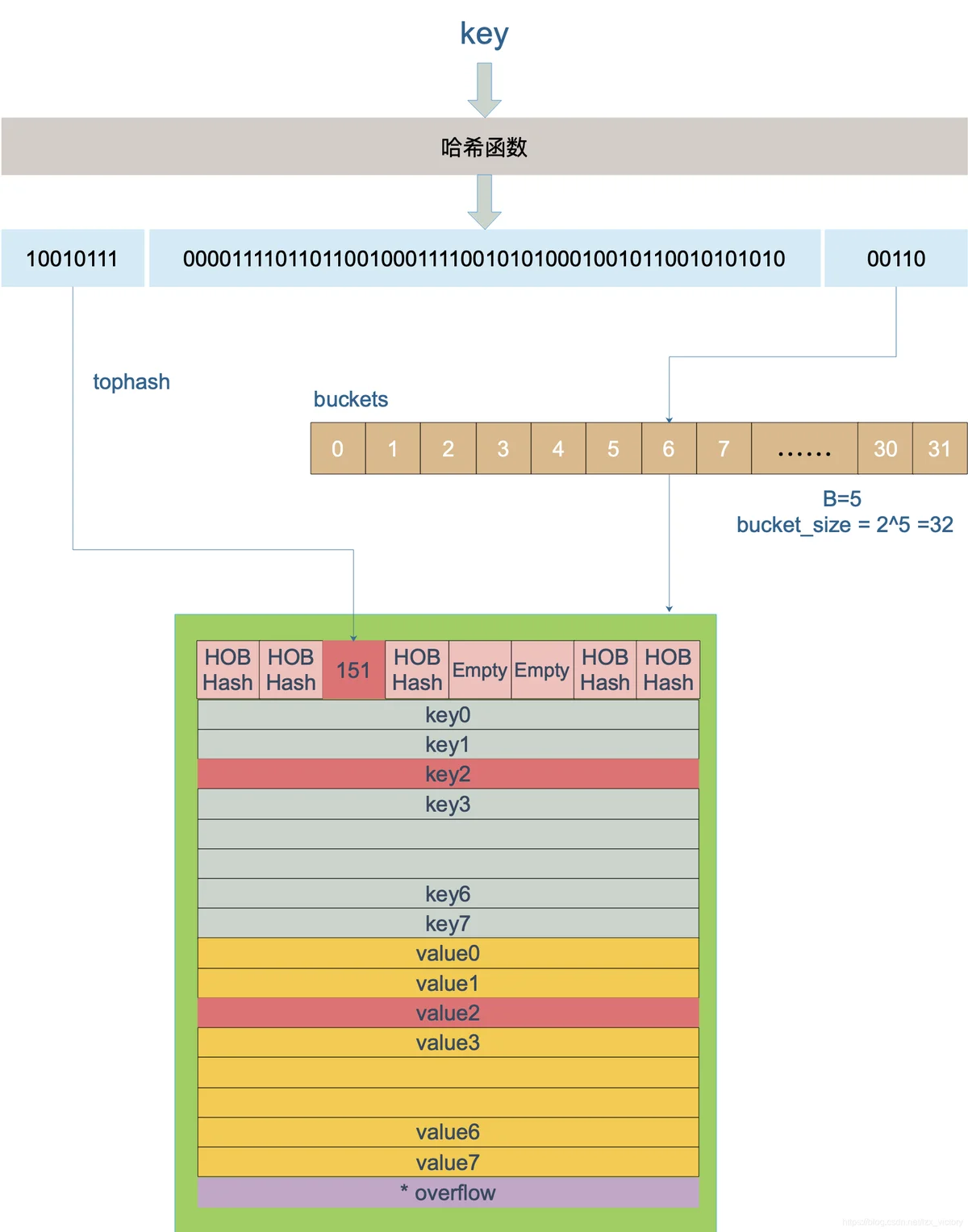
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
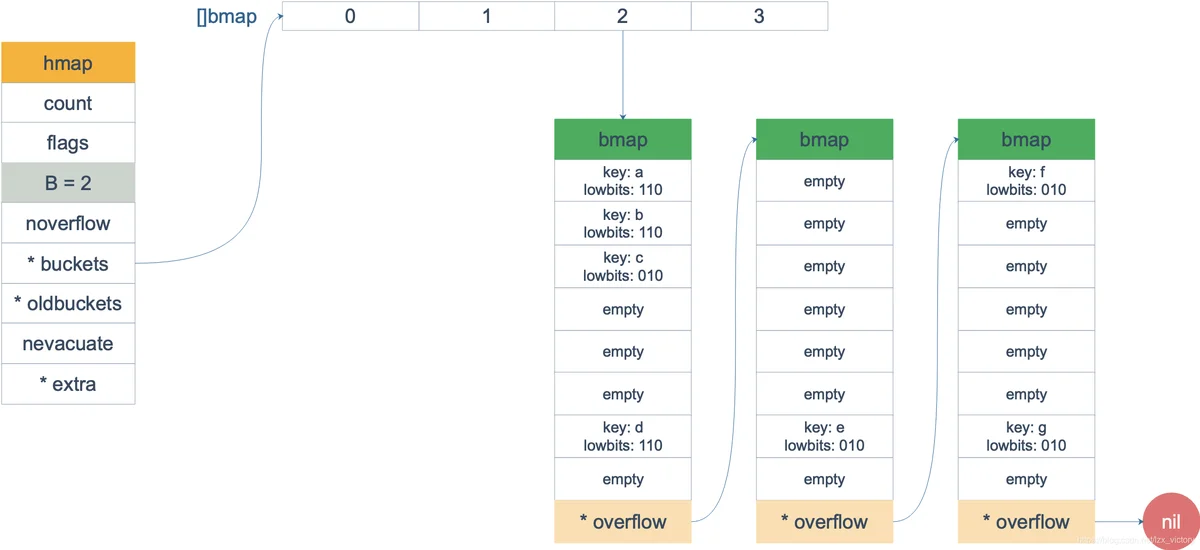
bmap数据结构:

key的访问
访问的key经过hahs计算得到高八位,用于在bucket内定位具体的cell,后x位用于定位buckets数组定位属于哪个bucket.如果overflow不为nil,那么会继续进行查找.如果没查找到会返回Value的零值.
map的遍历
遍历的随机性
// 生成随机数 r
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
// 从哪个 bucket 开始遍历
it.startBucket = r & (uintptr(1)<<h.B - 1)
// 从 bucket 的哪个 cell 开始遍历
it.offset = uint8(r >> h.B & (bucketCnt - 1))
遍历当中发生的扩容
tophash存在四种枚举值.
emptyRest = 0 // this cell is empty, and there are no more non-empty cells at higher indexes or overflows.
emptyOne = 1 // this cell is empty
evacuatedX = 2 // key/elem is valid. Entry has been evacuated to first half of larger table.
evacuatedY = 3 // same as above, but evacuated to second half of larger table.
evacuatedEmpty = 4 // cell is empty, bucket is evacuated.
minTopHash = 5 // minimum tophash for a normal filled cell.
搬迁的定义:
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > emptyOne && h < minTopHash
}
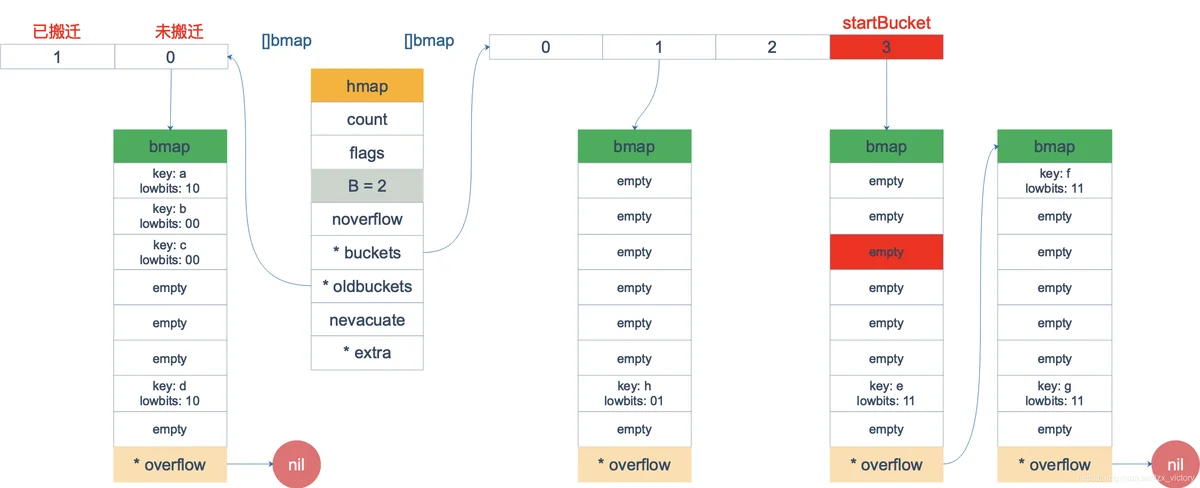
如果新扩容的Bit位是 0 ,分配到 X part;如果是 1,则分配到 Y part。据此决定是否取出 key,放到遍历结果集里。
遍历过程发现有的bucket已经被迁移,那么新的bucket中存储的是新的数据那么就直接遍历.
根据前面描述的拆分规则,老的bucket会拆分为两个部分,遍历到了新的bucket,如果数据存在于老的bucket找到还未搬迁的key,然后进行遍历.
扩容
Map的扩容容量和slice有很大的差别,首先扩容的容量,是源大小的两倍.触发扩容的条件不一样:
装载因子的定义:
loadFactor := count / (2^B)
count 就是 map 的元素个数,2^B 表示 bucket 数量。
扩容触发条件
overflowbuckets过多导致查询性能变为O(n)级别,因此需要压实.另一种bucket快被存储满,导致空间不够,也是为了基于以后查询性能的考略,尽快操作扩容.
1.装载因子超过阈值,源码里定义的阈值是 6.5。(标明buckets里的元素基本要被装满)
2.overflow 的 bucket 数量过多:当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B;当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15。(真实分配的 bucket 数量多,包括大量的 overflow bucket,有可能是不停的插入删除导致的)
解决:
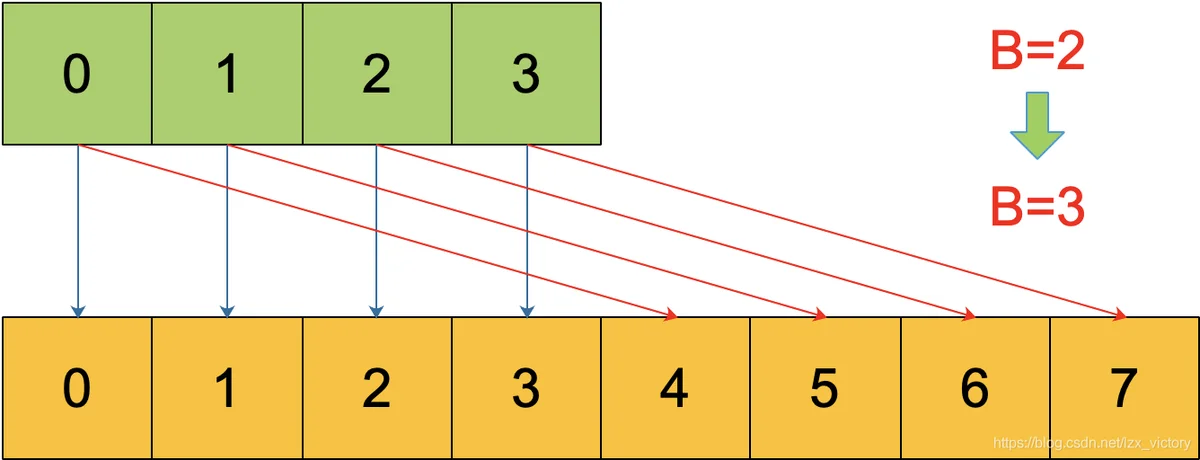
对于条件 1,元素太多,而 bucket 数量太少,很简单:将 B 加 1,bucket 最大数量(2^B)直接变成原来 bucket 数量的 2 倍。于是,就有新老 bucket 了。注意,这时候元素都在老 bucket 里,还没迁移到新的 bucket 来。而且,新 bucket 只是最大数量变为原来最大数量(2^B)的 2 倍(2^B * 2)。
对于条件 2,其实元素没那么多,但是 overflow bucket 数特别多,说明很多 bucket 都没装满。解决办法就是开辟一个新 bucket 空间,将老 bucket 中的元素移动到新 bucket,使得同一个 bucket 中的 key 排列地更紧密。这样,原来,在 overflow bucket 中的 key 可以移动到 bucket 中来。结果是节省空间,提高 bucket 利用率,map 的查找和插入效率自然就会提升。
条件1-扩充

条件2-压实

接口
底层结构
iface
iface 和 eface 都是 Go 中描述接口的底层结构体,区别在于 iface 描述的接口包含方法,而 eface 则是不包含任何方法的空接口:interface{}.
type iface struct {
tab *itab
data unsafe.Pointer
}
type itab struct {
inter *interfacetype
_type *_type
link *itab
hash uint32 // copy of _type.hash. Used for type switches.
bad bool // type does not implement interface
inhash bool // has this itab been added to hash?
unused [2]byte
fun [1]uintptr // variable sized
}
iface 内部维护两个指针,tab 指向一个 itab 实体, 它表示接口的类型以及赋给这个接口的实体类型。data 则指向接口具体的值,一般而言是一个指向堆内存的指针。
再来仔细看一下 itab 结构体:_type 字段描述了实体的类型,包括内存对齐方式,大小等;inter 字段则描述了接口的类型。fun 字段放置和接口方法对应的具体数据类型的方法地址,实现接口调用方法的动态分派,一般在每次给接口赋值发生转换时会更新此表,或者直接拿缓存的 itab。
type interfacetype struct {
typ _type
pkgpath name
mhdr []imethod
}
它包装了 _type 类型,_type 实际上是描述 Go 语言中各种数据类型的结构体。我们注意到,这里还包含一个 mhdr 字段,表示接口所定义的函数列表, pkgpath 记录定义了接口的包名。
eface
type eface struct {
_type *_type
data unsafe.Pointer
}
相比 iface,eface 就比较简单了。只维护了一个 _type 字段,表示空接口所承载的具体的实体类型。data 描述了具体的值。
type _type struct {
// 类型大小
size uintptr
ptrdata uintptr
// 类型的 hash 值
hash uint32
// 类型的 flag,和反射相关
tflag tflag
// 内存对齐相关
align uint8
fieldalign uint8
// 类型的编号,有bool, slice, struct 等等等等
kind uint8
alg *typeAlg
// gc 相关
gcdata *byte
str nameOff
ptrToThis typeOff
}
接口类型是不是nil
当声明一个接口类型的变量,变量初值的为nil,那么此时变量和nil判断为真,因为接口变量的Type和Value没有实际指向,而当接口变量指向一个结构体为nil的变量,此时接口变量的Type会被赋值,因此存在实际指向时,接口变量就不等于nil.
package main
import "fmt"
type Coder interface {
code()
}
type Gopher struct {
name string
}
func (g Gopher) code() {
fmt.Printf("%s is coding\n", g.name)
}
func main() {
var c Coder
fmt.Println(c == nil)
fmt.Printf("c: %T, %v\n", c, c)
var g *Gopher
fmt.Println(g == nil)
c = g
fmt.Println(c == nil)
fmt.Printf("c: %T, %v\n", c, c)
}
true
c: <nil>, <nil>
true
false
c: *main.Gopher, <nil>
方法接收者
如果方法的接收者是值类型,无论调用者是对象还是对象指针,修改的都是对象的副本,不影响调用者;如果方法的接收者是指针类型,则调用者修改的是指针指向的对象本身。
指针方法可以通过指针调用
值方法可以通过值或者指针调用
接收者是值的方法可以通过指针调用,因为指针会首先被解引用
接收者是指针的方法不可以通过值调用,因为存储在接口中的值没有地址。但是Go语言会自动将值类型转换为指针调用指针方法。因此Go中值和指针都可以调用任何方法。
Channel
底层结构
发送底层数据结构
type hchan struct {
// chan 里元素数量
qcount uint
// chan 底层循环数组的长度
dataqsiz uint
// 指向底层循环数组的指针
// 只针对有缓冲的 channel
buf unsafe.Pointer
// chan 中元素大小
elemsize uint16
// chan 是否被关闭的标志
closed uint32
// chan 中元素类型
elemtype *_type // element type
// 已发送元素在循环数组中的索引
sendx uint // send index
// 已接收元素在循环数组中的索引
recvx uint // receive index
// 等待接收的 goroutine 队列
recvq waitq // list of recv waiters
// 等待发送的 goroutine 队列
sendq waitq // list of send waiters
// 保护 hchan 中所有字段
lock mutex
}
buf 指向底层循环数组,只有缓冲型的 channel 才有。
sendx,recvx 均指向底层循环数组,表示当前可以发送和接收的元素位置索引值(相对于底层数组)。
sendq,recvq 分别表示被阻塞的 goroutine,这些 goroutine 由于尝试读取 channel 或向 channel 发送数据而被阻塞。
lock 用来保证每个读 channel 或写 channel 的操作都是原子的。
waitq 是 sudog 的一个双向链表,而 sudog 实际上是对 goroutine 的一个封装:
type waitq struct {
first *sudog
last *sudog
}
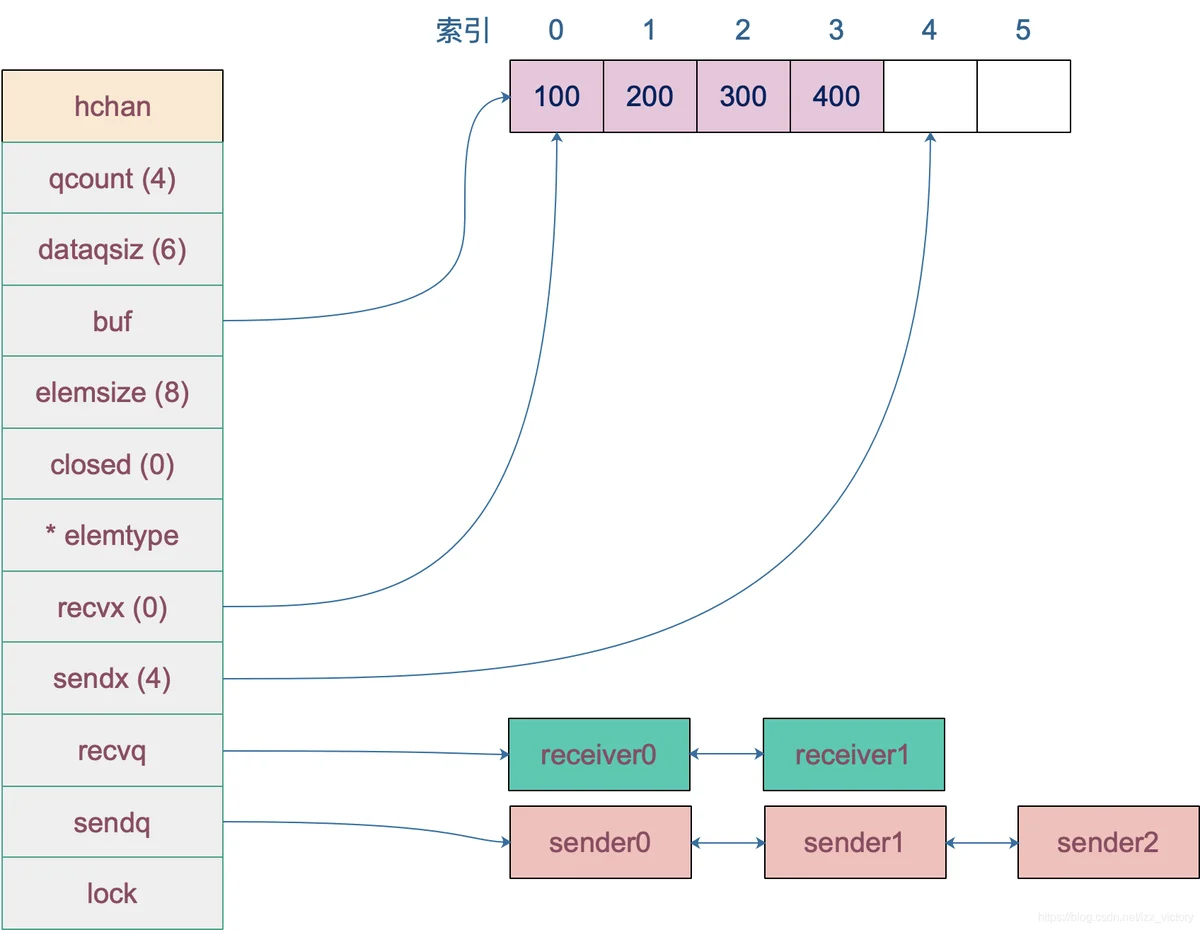
channel的发送策略
源码:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 如果 channel 是 nil
if c == nil {
// 不能阻塞,直接返回 false,表示未发送成功
if !block {
return false
}
// 当前 goroutine 被挂起
gopark(nil, nil, "chan send (nil chan)", traceEvGoStop, 2)
throw("unreachable")
}
// 省略 debug 相关……
// 对于不阻塞的 send,快速检测失败场景
//
// 如果 channel 未关闭且 channel 没有多余的缓冲空间。这可能是:
// 1. channel 是非缓冲型的,且等待接收队列里没有 goroutine
// 2. channel 是缓冲型的,但循环数组已经装满了元素
if !block && c.closed == 0 && ((c.dataqsiz == 0 && c.recvq.first == nil) ||
(c.dataqsiz > 0 && c.qcount == c.dataqsiz)) {
return false
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
// 锁住 channel,并发安全
lock(&c.lock)
// 如果 channel 关闭了
if c.closed != 0 {
// 解锁
unlock(&c.lock)
// 直接 panic
panic(plainError("send on closed channel"))
}
// 如果接收队列里有 goroutine,直接将要发送的数据拷贝到接收 goroutine
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// 对于缓冲型的 channel,如果还有缓冲空间
if c.qcount < c.dataqsiz {
// qp 指向 buf 的 sendx 位置
qp := chanbuf(c, c.sendx)
// ……
// 将数据从 ep 处拷贝到 qp
typedmemmove(c.elemtype, qp, ep)
// 发送游标值加 1
c.sendx++
// 如果发送游标值等于容量值,游标值归 0
if c.sendx == c.dataqsiz {
c.sendx = 0
}
// 缓冲区的元素数量加一
c.qcount++
// 解锁
unlock(&c.lock)
return true
}
// 如果不需要阻塞,则直接返回错误
if !block {
unlock(&c.lock)
return false
}
// channel 满了,发送方会被阻塞。接下来会构造一个 sudog
// 获取当前 goroutine 的指针
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.selectdone = nil
mysg.c = c
gp.waiting = mysg
gp.param = nil
// 当前 goroutine 进入发送等待队列
c.sendq.enqueue(mysg)
// 当前 goroutine 被挂起
goparkunlock(&c.lock, "chan send", traceEvGoBlockSend, 3)
// 从这里开始被唤醒了(channel 有机会可以发送了)
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
if gp.param == nil {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
// 被唤醒后,channel 关闭了。坑爹啊,panic
panic(plainError("send on closed channel"))
}
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
// 去掉 mysg 上绑定的 channel
mysg.c = nil
releaseSudog(mysg)
return true
}
// send 函数处理向一个空的 channel 发送操作
// ep 指向被发送的元素,会被直接拷贝到接收的 goroutine
// 之后,接收的 goroutine 会被唤醒
// c 必须是空的(因为等待队列里有 goroutine,肯定是空的)
// c 必须被上锁,发送操作执行完后,会使用 unlockf 函数解锁
// sg 必须已经从等待队列里取出来了
// ep 必须是非空,并且它指向堆或调用者的栈
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// 省略一些用不到的
// ……
// sg.elem 指向接收到的值存放的位置,如 val <- ch,指的就是 &val
if sg.elem != nil {
// 直接拷贝内存(从发送者到接收者)
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
// sudog 上绑定的 goroutine
gp := sg.g
// 解锁
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// 唤醒接收的 goroutine. skip 和打印栈相关,暂时不理会
goready(gp, skip+1)
}
// 向一个非缓冲型的 channel 发送数据、从一个无元素的(非缓冲型或缓冲型但空)的 channel
// 接收数据,都会导致一个 goroutine 直接操作另一个 goroutine 的栈
// 由于 GC 假设对栈的写操作只能发生在 goroutine 正在运行中并且由当前 goroutine 来写
// 所以这里实际上违反了这个假设。可能会造成一些问题,所以需要用到写屏障来规避
func sendDirect(t *_type, sg *sudog, src unsafe.Pointer) {
// src 在当前 goroutine 的栈上,dst 是另一个 goroutine 的栈
// 直接进行内存"搬迁"
// 如果目标地址的栈发生了栈收缩,当我们读出了 sg.elem 后
// 就不能修改真正的 dst 位置的值了
// 因此需要在读和写之前加上一个屏障
dst := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
memmove(dst, src, t.size)
}
- 如果recvq有等待的goroutine,那么直接拷贝数据到接收的goroutine
- 如果不存在等待队列针对缓冲型channel:将数据拷贝到buf数组
- 缓冲型channel buf已经满 && 阻塞channel:将当前goroutine放入发送等待队列,当前groutine被挂起等待机会被唤醒,唤醒后的逻辑说明消息发送成功了.
Go语言为了提高channel性能,直接将要处理的数据copy到goroutine的栈上,这样做的好处就是提高性能减少数据的拷贝,但是有个问题会影响GC,所以需要构建写屏障的策略保证GC的正确性.
channel的接收策略
源码
// 位于 src/runtime/chan.go
// chanrecv 函数接收 channel c 的元素并将其写入 ep 所指向的内存地址。
// 如果 ep 是 nil,说明忽略了接收值。
// 如果 block == false,即非阻塞型接收,在没有数据可接收的情况下,返回 (false, false)
// 否则,如果 c 处于关闭状态,将 ep 指向的地址清零,返回 (true, false)
// 否则,用返回值填充 ep 指向的内存地址。返回 (true, true)
// 如果 ep 非空,则应该指向堆或者函数调用者的栈
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// 省略 debug 内容 …………
// 如果是一个 nil 的 channel
if c == nil {
// 如果不阻塞,直接返回 (false, false)
if !block {
return
}
// 否则,接收一个 nil 的 channel,goroutine 挂起
gopark(nil, nil, "chan receive (nil chan)", traceEvGoStop, 2)
// 不会执行到这里
throw("unreachable")
}
// 在非阻塞模式下,快速检测到失败,不用获取锁,快速返回
// 当我们观察到 channel 没准备好接收:
// 1. 非缓冲型,等待发送列队 sendq 里没有 goroutine 在等待
// 2. 缓冲型,但 buf 里没有元素
// 之后,又观察到 closed == 0,即 channel 未关闭。
// 因为 channel 不可能被重复打开,所以前一个观测的时候 channel 也是未关闭的,
// 因此在这种情况下可以直接宣布接收失败,返回 (false, false)
if !block && (c.dataqsiz == 0 && c.sendq.first == nil ||
c.dataqsiz > 0 && atomic.Loaduint(&c.qcount) == 0) &&
atomic.Load(&c.closed) == 0 {
return
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
// 加锁
lock(&c.lock)
// channel 已关闭,并且循环数组 buf 里没有元素
// 这里可以处理非缓冲型关闭 和 缓冲型关闭但 buf 无元素的情况
// 也就是说即使是关闭状态,但在缓冲型的 channel,
// buf 里有元素的情况下还能接收到元素
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(unsafe.Pointer(c))
}
// 解锁
unlock(&c.lock)
if ep != nil {
// 从一个已关闭的 channel 执行接收操作,且未忽略返回值
// 那么接收的值将是一个该类型的零值
// typedmemclr 根据类型清理相应地址的内存
typedmemclr(c.elemtype, ep)
}
// 从一个已关闭的 channel 接收,selected 会返回true
return true, false
}
// 等待发送队列里有 goroutine 存在,说明 buf 是满的
// 这有可能是:
// 1. 非缓冲型的 channel
// 2. 缓冲型的 channel,但 buf 满了
// 针对 1,直接进行内存拷贝(从 sender goroutine -> receiver goroutine)
// 针对 2,接收到循环数组头部的元素,并将发送者的元素放到循环数组尾部
if sg := c.sendq.dequeue(); sg != nil {
// Found a waiting sender. If buffer is size 0, receive value
// directly from sender. Otherwise, receive from head of queue
// and add sender's value to the tail of the queue (both map to
// the same buffer slot because the queue is full).
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
// 缓冲型,buf 里有元素,可以正常接收
if c.qcount > 0 {
// 直接从循环数组里找到要接收的元素
qp := chanbuf(c, c.recvx)
// …………
// 代码里,没有忽略要接收的值,不是 "<- ch",而是 "val <- ch",ep 指向 val
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 清理掉循环数组里相应位置的值
typedmemclr(c.elemtype, qp)
// 接收游标向前移动
c.recvx++
// 接收游标归零
if c.recvx == c.dataqsiz {
c.recvx = 0
}
// buf 数组里的元素个数减 1
c.qcount--
// 解锁
unlock(&c.lock)
return true, true
}
if !block {
// 非阻塞接收,解锁。selected 返回 false,因为没有接收到值
unlock(&c.lock)
return false, false
}
// 接下来就是要被阻塞的情况了
// 构造一个 sudog
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// 待接收数据的地址保存下来
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.selectdone = nil
mysg.c = c
gp.param = nil
// 进入channel 的等待接收队列
c.recvq.enqueue(mysg)
// 将当前 goroutine 挂起
goparkunlock(&c.lock, "chan receive", traceEvGoBlockRecv, 3)
// 被唤醒了,接着从这里继续执行一些扫尾工作
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
closed := gp.param == nil
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, !closed
}
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// 如果是非缓冲型的 channel
if c.dataqsiz == 0 {
if raceenabled {
racesync(c, sg)
}
// 未忽略接收的数据
if ep != nil {
// 直接拷贝数据,从 sender goroutine -> receiver goroutine
recvDirect(c.elemtype, sg, ep)
}
} else {
// 缓冲型的 channel,但 buf 已满。
// 将循环数组 buf 队首的元素拷贝到接收数据的地址
// 将发送者的数据入队。实际上这时 revx 和 sendx 值相等
// 找到接收游标
qp := chanbuf(c, c.recvx)
// …………
// 将接收游标处的数据拷贝给接收者
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 将发送者数据拷贝到 buf
typedmemmove(c.elemtype, qp, sg.elem)
// 更新游标值
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx
}
sg.elem = nil
gp := sg.g
// 解锁
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// 唤醒发送的 goroutine。需要等到调度器的光临
goready(gp, skip+1)
}
func recvDirect(t *_type, sg *sudog, dst unsafe.Pointer) {
// dst is on our stack or the heap, src is on another stack.
src := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
memmove(dst, src, t.size)
}
- channel关闭,且数组buf里没有元素:直接返回.
- 如果sendq存在goroutine(说明非缓冲型阻塞&缓冲型已满):
- 非缓存类型 直接从sender 拷贝到receiver.
- 缓冲型的 channel,但 buf 满了,接收到循环数组头部的元素,并将发送者的元素放到循环数组尾部
- 如果缓冲型buf里不为空:将ep指向buf数组中出队的元素,修改buf相关的数值.
- 缓冲型channel buf没有数据 && 阻塞channel无数据:将当前goroutine进入接收等待队列,当前groutine被挂起等待机会被唤醒,唤醒后的逻辑说明消息发送成功了.
channel的关闭
func closechan(c *hchan) {
// 关闭一个 nil channel,panic
if c == nil {
panic(plainError("close of nil channel"))
}
// 上锁
lock(&c.lock)
// 如果 channel 已经关闭
if c.closed != 0 {
unlock(&c.lock)
// panic
panic(plainError("close of closed channel"))
}
// …………
// 修改关闭状态
c.closed = 1
var glist *g
// 将 channel 所有等待接收队列的里 sudog 释放
for {
// 从接收队列里出队一个 sudog
sg := c.recvq.dequeue()
// 出队完毕,跳出循环
if sg == nil {
break
}
// 如果 elem 不为空,说明此 receiver 未忽略接收数据
// 给它赋一个相应类型的零值
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// 取出 goroutine
gp := sg.g
gp.param = nil
if raceenabled {
raceacquireg(gp, unsafe.Pointer(c))
}
// 相连,形成链表
gp.schedlink.set(glist)
glist = gp
}
// 将 channel 等待发送队列里的 sudog 释放
// 如果存在,这些 goroutine 将会 panic
for {
// 从发送队列里出队一个 sudog
sg := c.sendq.dequeue()
if sg == nil {
break
}
// 发送者会 panic
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = nil
if raceenabled {
raceacquireg(gp, unsafe.Pointer(c))
}
// 形成链表
gp.schedlink.set(glist)
glist = gp
}
// 解锁
unlock(&c.lock)
// Ready all Gs now that we've dropped the channel lock.
// 遍历链表
for glist != nil {
// 取最后一个
gp := glist
// 向前走一步,下一个唤醒的 g
glist = glist.schedlink.ptr()
gp.schedlink = 0
// 唤醒相应 goroutine
goready(gp, 3)
}
}
源码当中描述了,关闭一个已经关闭的channel会抛出异常,对发送者会抛出panic,关闭 channel 后,对于等待接收者而言,会收到一个相应类型的零值.
happend-before
1.第 n 个 send 一定 happened before 第 n 个 receive finished,无论是缓冲型还是非缓冲型的 channel。
2.对于容量为 m 的缓冲型 channel,第 n 个 receive 一定 happened before 第 n+m 个 send finished。
3.对于非缓冲型的 channel,第 n 个 receive 一定 happened before 第 n 个 send finished。
4.channel close 一定 happened before receiver 得到通知。
标准库
Context
type Context interface {
// 当 context 被取消或者到了 deadline,返回一个被关闭的 channel
Done() <-chan struct{}
// 在 channel Done 关闭后,返回 context 取消原因
Err() error
// 返回 context 是否会被取消以及自动取消时间(即 deadline)
Deadline() (deadline time.Time, ok bool)
// 获取 key 对应的 value
Value(key interface{}) interface{}
}
Context取消
type cancelCtx struct {
Context
// 保护之后的字段
mu sync.Mutex
done chan struct{}
children map[canceler]struct{}
err error
}
cancelCtx首先需要挂载到,可取消的父节点当中,如果没找得到会启动协程监控当前节点的取消.
源码如下:
func propagateCancel(parent Context, child canceler) {
// 父节点是个空节点
if parent.Done() == nil {
return // parent is never canceled
}
// 找到可以取消的父 context
if p, ok := parentCancelCtx(parent); ok {
p.mu.Lock()
if p.err != nil {
// 父节点已经被取消了,本节点(子节点)也要取消
child.cancel(false, p.err)
} else {
// 父节点未取消
if p.children == nil {
p.children = make(map[canceler]struct{})
}
// "挂到"父节点上
p.children[child] = struct{}{}
}
p.mu.Unlock()
} else {
// 如果没有找到可取消的父 context。新启动一个协程监控父节点或子节点取消信号
go func() {
select {
case <-parent.Done():
child.cancel(false, parent.Err())
case <-child.Done():
}
}()
}
}
取消流程源码,节点取消会触发递归调用子节点的取消.
func (c *cancelCtx) cancel(removeFromParent bool, err error) {
// 必须要传 err
if err == nil {
panic("context: internal error: missing cancel error")
}
c.mu.Lock()
if c.err != nil {
c.mu.Unlock()
return // 已经被其他协程取消
}
// 给 err 字段赋值
c.err = err
// 关闭 channel,通知其他协程
if c.done == nil {
c.done = closedchan
} else {
close(c.done)
}
// 遍历它的所有子节点
for child := range c.children {
// 递归地取消所有子节点
child.cancel(false, err)
}
// 将子节点置空
c.children = nil
c.mu.Unlock()
if removeFromParent {
// 从父节点中移除自己
removeChild(c.Context, c)
}
}
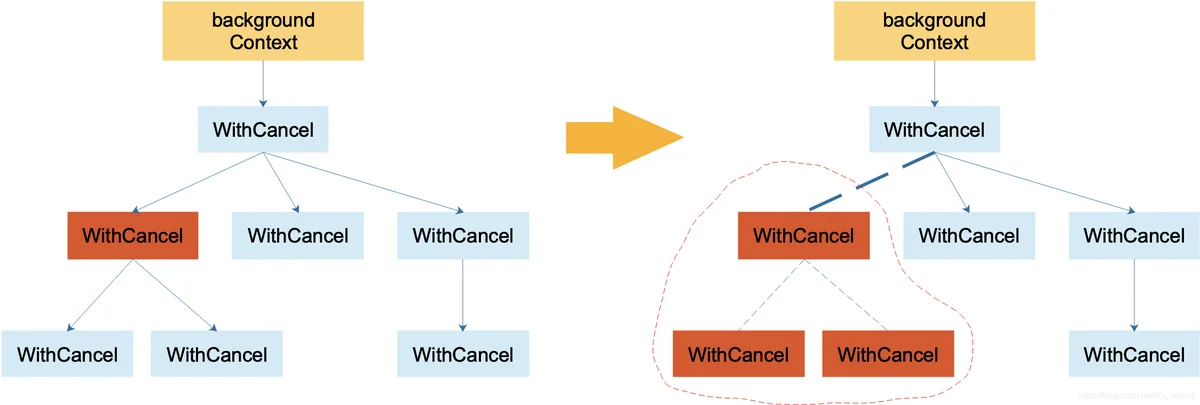
timerCtx
timer基于cancelCtx,只不过内部存在定时器.
type timerCtx struct {
cancelCtx
timer *time.Timer // Under cancelCtx.mu.
deadline time.Time
}
func (c *timerCtx) cancel(removeFromParent bool, err error) {
// 直接调用 cancelCtx 的取消方法
c.cancelCtx.cancel(false, err)
if removeFromParent {
// 从父节点中删除子节点
removeChild(c.cancelCtx.Context, c)
}
c.mu.Lock()
if c.timer != nil {
// 关掉定时器,这样,在deadline 到来时,不会再次取消
c.timer.Stop()
c.timer = nil
}
c.mu.Unlock()
}
reflect
Type
reflect结构实现与eface一模一样
type rtype struct {
size uintptr
ptrdata uintptr
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8
alg *typeAlg
gcdata *byte
str nameOff
ptrToThis typeOff
}
type emptyInterface struct {
typ *rtype
word unsafe.Pointer
}
TypeOf 转换.
func TypeOf(i interface{}) Type {
eface := *(*emptyInterface)(unsafe.Pointer(&i))
return toType(eface.typ)
}
func toType(t *rtype) Type {
if t == nil {
return nil
}
return t
}
仔细阅读源码会发现,反射转将rtype转为Type,Type接口中的方法实际就是对rtype的操作.
Value
unc ValueOf(i interface{}) Value {
if i == nil {
return Value{}
}
// ……
return unpackEface(i)
}
// 分解 eface
func unpackEface(i interface{}) Value {
e := (*emptyInterface)(unsafe.Pointer(&i))
t := e.typ
if t == nil {
return Value{}
}
f := flag(t.Kind())
if ifaceIndir(t) {
f |= flagIndir
}
return Value{t, e.word, f}
}
e.word就是对应的数据指针.Value读取到对应的数据后会根据rtype的类型将数据指针进行转换成对应的类型,然后进行访问操作.
unsafe
底层结构
type ArbitraryType int
type Pointer *ArbitraryType
type uintptr uintptr

任何类型的指针和 unsafe.Pointer 可以相互转换。
uintptr 类型和 unsafe.Pointer 可以相互转换。
uintptr 并没有指针的语义,意思就是 uintptr 所指向的对象会被 gc 无情地回收。而 unsafe.Pointer 有指针语义,可以保护它所指向的对象在“有用”的时候不会被垃圾回收.
修改私有成员变量
type Programmer struct {
name string
age int
language string
}
func main() {
p := Programmer{"stefno", 18, "go"}
fmt.Println(p)
lang := (*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&p)) + unsafe.Sizeof(int(0)) + unsafe.Sizeof(string(""))))
*lang = "Golang"
fmt.Println(p)
}
GMP
基础数据结构
type g struct {
// goroutine 使用的栈
stack stack // offset known to runtime/cgo
// 用于栈的扩张和收缩检查,抢占标志
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
// 当前与 g 绑定的 m
m *m // current m; offset known to arm liblink
// goroutine 的运行现场
sched gobuf
syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
stktopsp uintptr // expected sp at top of stack, to check in traceback
// wakeup 时传入的参数
param unsafe.Pointer // passed parameter on wakeup
atomicstatus uint32
stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
goid int64
// g 被阻塞之后的近似时间
waitsince int64 // approx time when the g become blocked
// g 被阻塞的原因
waitreason string // if status==Gwaiting
// 指向全局队列里下一个 g
schedlink guintptr
// 抢占调度标志。这个为 true 时,stackguard0 等于 stackpreempt
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
paniconfault bool // panic (instead of crash) on unexpected fault address
preemptscan bool // preempted g does scan for gc
gcscandone bool // g has scanned stack; protected by _Gscan bit in status
gcscanvalid bool // false at start of gc cycle, true if G has not run since last scan; TODO: remove?
throwsplit bool // must not split stack
raceignore int8 // ignore race detection events
sysblocktraced bool // StartTrace has emitted EvGoInSyscall about this goroutine
// syscall 返回之后的 cputicks,用来做 tracing
sysexitticks int64 // cputicks when syscall has returned (for tracing)
traceseq uint64 // trace event sequencer
tracelastp puintptr // last P emitted an event for this goroutine
// 如果调用了 LockOsThread,那么这个 g 会绑定到某个 m 上
lockedm *m
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
// 创建该 goroutine 的语句的指令地址
gopc uintptr // pc of go statement that created this goroutine
// goroutine 函数的指令地址
startpc uintptr // pc of goroutine function
racectx uintptr
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
cgoCtxt []uintptr // cgo traceback context
labels unsafe.Pointer // profiler labels
// time.Sleep 缓存的定时器
timer *timer // cached timer for time.Sleep
gcAssistBytes int64
}
// m 代表工作线程,保存了自身使用的栈信息
type m struct {
// 记录工作线程(也就是内核线程)使用的栈信息。在执行调度代码时需要使用
// 执行用户 goroutine 代码时,使用用户 goroutine 自己的栈,因此调度时会发生栈的切换
g0 *g // goroutine with scheduling stack/
morebuf gobuf // gobuf arg to morestack
divmod uint32 // div/mod denominator for arm - known to liblink
// Fields not known to debuggers.
procid uint64 // for debuggers, but offset not hard-coded
gsignal *g // signal-handling g
sigmask sigset // storage for saved signal mask
// 通过 tls 结构体实现 m 与工作线程的绑定
// 这里是线程本地存储
tls [6]uintptr // thread-local storage (for x86 extern register)
mstartfn func()
// 指向正在运行的 goroutine 对象
curg *g // current running goroutine
caughtsig guintptr // goroutine running during fatal signal
// 当前工作线程绑定的 p
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
id int32
mallocing int32
throwing int32
// 该字段不等于空字符串的话,要保持 curg 始终在这个 m 上运行
preemptoff string // if != "", keep curg running on this m
locks int32
softfloat int32
dying int32
profilehz int32
helpgc int32
// 为 true 时表示当前 m 处于自旋状态,正在从其他线程偷工作
spinning bool // m is out of work and is actively looking for work
// m 正阻塞在 note 上
blocked bool // m is blocked on a note
// m 正在执行 write barrier
inwb bool // m is executing a write barrier
newSigstack bool // minit on C thread called sigaltstack
printlock int8
// 正在执行 cgo 调用
incgo bool // m is executing a cgo call
fastrand uint32
// cgo 调用总计数
ncgocall uint64 // number of cgo calls in total
ncgo int32 // number of cgo calls currently in progress
cgoCallersUse uint32 // if non-zero, cgoCallers in use temporarily
cgoCallers *cgoCallers // cgo traceback if crashing in cgo call
// 没有 goroutine 需要运行时,工作线程睡眠在这个 park 成员上,
// 其它线程通过这个 park 唤醒该工作线程
park note
// 记录所有工作线程的链表
alllink *m // on allm
schedlink muintptr
mcache *mcache
lockedg *g
createstack [32]uintptr // stack that created this thread.
freglo [16]uint32 // d[i] lsb and f[i]
freghi [16]uint32 // d[i] msb and f[i+16]
fflag uint32 // floating point compare flags
locked uint32 // tracking for lockosthread
// 正在等待锁的下一个 m
nextwaitm uintptr // next m waiting for lock
needextram bool
traceback uint8
waitunlockf unsafe.Pointer // todo go func(*g, unsafe.pointer) bool
waitlock unsafe.Pointer
waittraceev byte
waittraceskip int
startingtrace bool
syscalltick uint32
// 工作线程 id
thread uintptr // thread handle
// these are here because they are too large to be on the stack
// of low-level NOSPLIT functions.
libcall libcall
libcallpc uintptr // for cpu profiler
libcallsp uintptr
libcallg guintptr
syscall libcall // stores syscall parameters on windows
mOS
}
// p 保存 go 运行时所必须的资源
type p struct {
lock mutex
// 在 allp 中的索引
id int32
status uint32 // one of pidle/prunning/...
link puintptr
// 每次调用 schedule 时会加一
schedtick uint32
// 每次系统调用时加一
syscalltick uint32
// 用于 sysmon 线程记录被监控 p 的系统调用时间和运行时间
sysmontick sysmontick // last tick observed by sysmon
// 指向绑定的 m,如果 p 是 idle 的话,那这个指针是 nil
m muintptr // back-link to associated m (nil if idle)
mcache *mcache
racectx uintptr
deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go)
deferpoolbuf [5][32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
// 本地可运行的队列,不用通过锁即可访问
runqhead uint32 // 队列头
runqtail uint32 // 队列尾
// 使用数组实现的循环队列
runq [256]guintptr
// runnext 非空时,代表的是一个 runnable 状态的 G,
// 这个 G 被 当前 G 修改为 ready 状态,相比 runq 中的 G 有更高的优先级。
// 如果当前 G 还有剩余的可用时间,那么就应该运行这个 G
// 运行之后,该 G 会继承当前 G 的剩余时间
runnext guintptr
// Available G's (status == Gdead)
// 空闲的 g
gfree *g
gfreecnt int32
sudogcache []*sudog
sudogbuf [128]*sudog
tracebuf traceBufPtr
traceSwept, traceReclaimed uintptr
palloc persistentAlloc // per-P to avoid mutex
// Per-P GC state
gcAssistTime int64 // Nanoseconds in assistAlloc
gcBgMarkWorker guintptr
gcMarkWorkerMode gcMarkWorkerMode
runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point
pad [sys.CacheLineSize]byte
}
运行流程
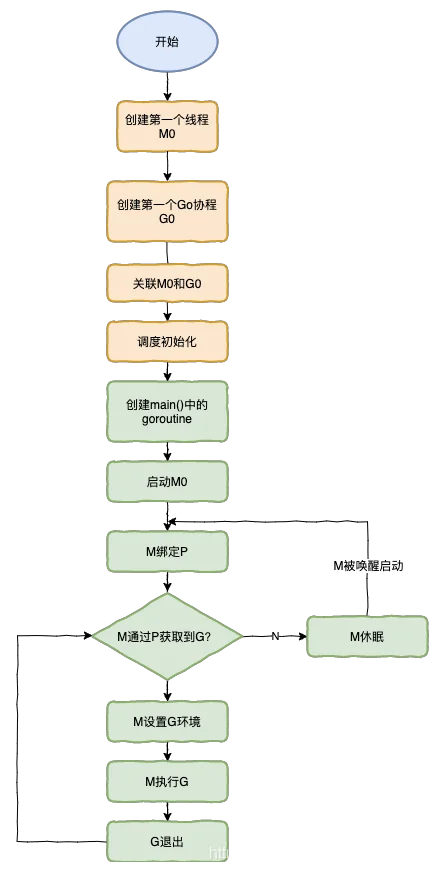
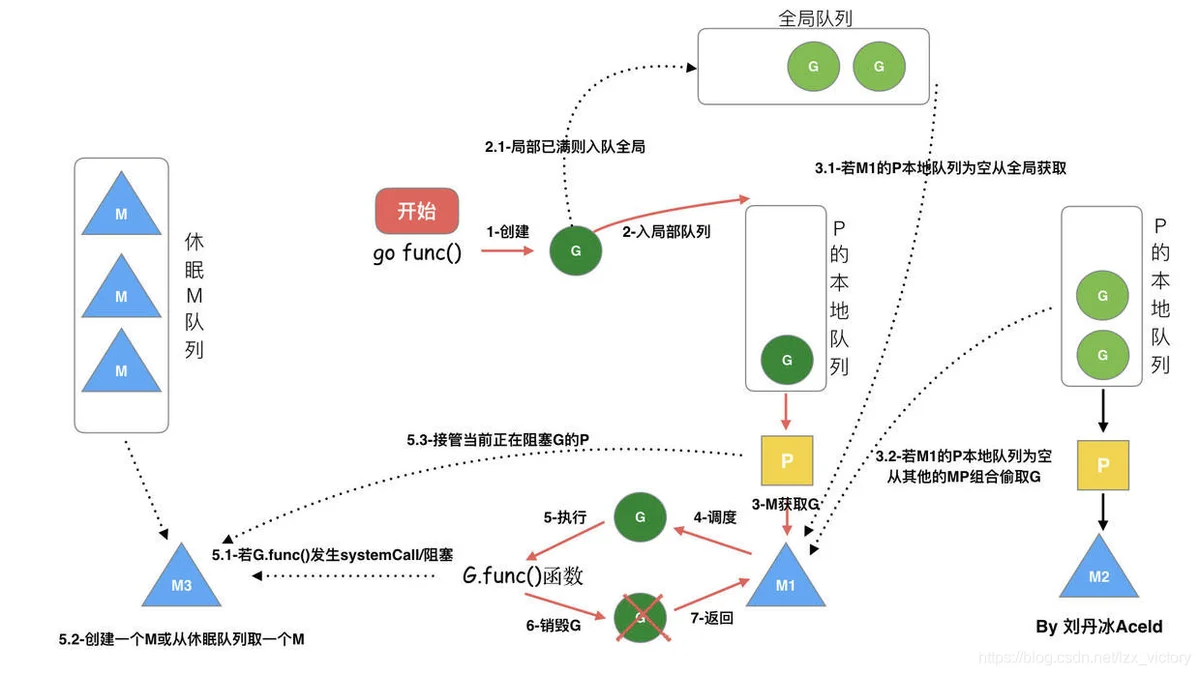
抢占
为了提升运行效率,Machine对应P的队列为空时且全局队列为空时,回去其它的队列偷取提升效率.如果没有找到可以运行的Goroutine,就会进入idle状态.
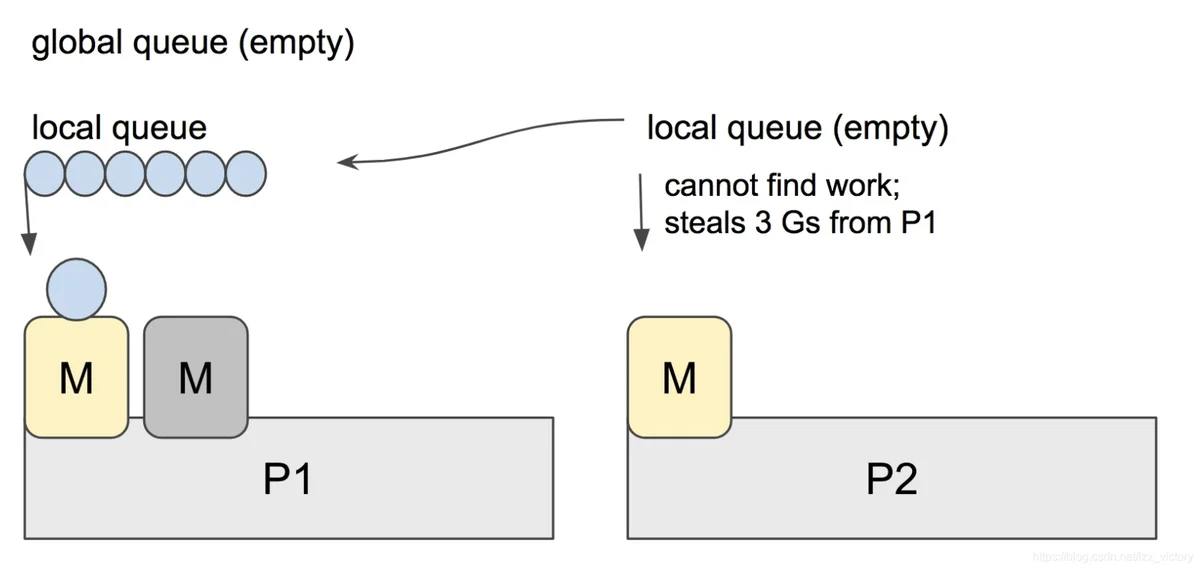
sysmon作用
sysmon是我们的保洁阿姨,它是一个M,又叫监控线程,不需要P就可以独立运行,每20us~10ms会被唤醒一次出来打扫卫生,主要工作就是回收垃圾、回收长时间系统调度阻塞的P、向长时间运行的G发出抢占调度等等。
- 抢占处于系统调用的 P,让其他 m 接管它,以运行其他的 goroutine。
- 将运行时间过长的 goroutine 调度出去,给其他 goroutine 运行的机会。
P的限制设置
GOMAXPROCS:设置P的运行的数量.(M的数量是不定的,当前的goroutine阻塞后,会创建一个新的M或其他的M)
GC机制
三色标记法
根对象
-
根对象在垃圾回收的术语中又叫做根集合,它是垃圾回收器在标记过程时最先检查的对象,包括:
-
全局变量:程序在编译期就能确定的那些存在于程序整个生命周期的变量。
执行栈:每个 goroutine 都包含自己的执行栈,这些执行栈上包 - 含栈上的变量及指向分配的堆内存区块的指针。
寄存器:寄存器的值可能表示一个指针,参与计算的这些指针可能指向某些赋值器分配的堆内存区块。
实现
理解三色标记法的关键是理解对象的三色抽象以及波面(wavefront)推进这两个概念。三色抽象只是一种描述追踪式回收器的方法,在实践中并没有实际含义,它的重要作用在于从逻辑上严密推导标记清理这种垃圾回收方法的正确性。也就是说,当我们谈及三色标记法时,通常指标记清扫的垃圾回收。
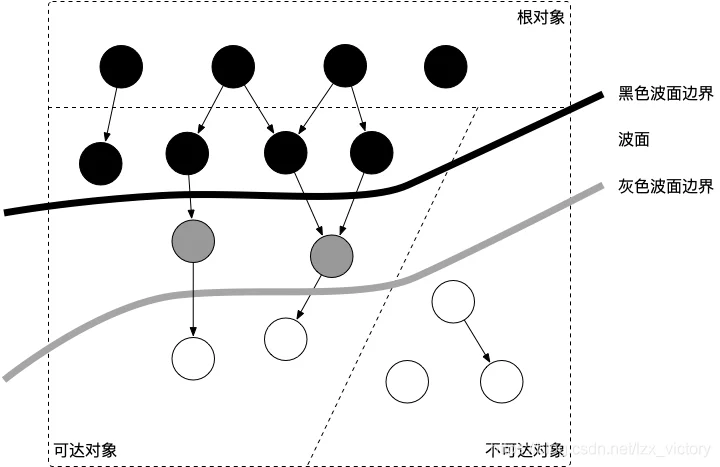
从垃圾回收器的视角来看,三色抽象规定了三种不同类型的对象,并用不同的颜色相称:
- 白色对象(可能死亡):未被回收器访问到的对象。在回收开始阶段,所有对象均为白色,当回收结束后,白色对象均不可达。
- 灰色对象(波面):已被回收器访问到的对象,但回收器需要对其中的一个或多个指针进行扫描,因为他们可能还指向白色对象。
- 黑色对象(确定存活):已被回收器访问到的对象,其中所有字段都已被扫描,黑色对象中任何一个指针都不可能直接指向白色对象。
这样三种不变性所定义的回收过程其实是一个波面不断前进的过程,这个波面同时也是黑色对象和白色对象的边界,灰色对象就是这个波面。
当垃圾回收开始时,只有白色对象。随着标记过程开始进行时,灰色对象开始出现(着色),这时候波面便开始扩大。当一个对象的所有子节点均完成扫描时,会被着色为黑色。当整个堆遍历完成时,只剩下黑色和白色对象,这时的黑色对象为可达对象,即存活;而白色对象为不可达对象,即死亡。这个过程可以视为以灰色对象为波面,将黑色对象和白色对象分离,使波面不断向前推进,直到所有可达的灰色对象都变为黑色对象为止的过程。如下图所示:
强弱三色不变式
条件1: 一个白色对象被黑色对象引用白色被挂在黑色下
条件2: 灰色对象与它之间的可达关系的白色对象遭到破坏灰色同时丢了该白色
这样一定程度上减少STW时间且保证了GC机制的正确性,当以上两个条件同时满足时, 就会出现对象丢失现象!
强三色不变式
强三色不变式:不存在黑色对象引用到白色对象的指针,破坏条件1.
构建插入插入屏障:
具体操作: 在A对象引用B对象的时候,B对象被标记为灰色。(将B挂在A下游,B必须被标记为灰色).
栈空间的特点是容量小,但是要求相应速度快,因为函数调用弹出频繁使用, 所以“插入屏障”机制,在栈空间的对象操作中不使用. 而仅仅使用在堆空间对象的操作中.
缺点:当栈空间并发情况下,发生黑色对象引用了白色色对象时,就有可能导致不一致,因此需要STW对栈空间执行三色标记法.
弱三色不变式
弱三色不变式:所有被黑色对象引用的白色对象都处于灰色保护状态,破坏条件2.
构建删除屏障:具体操作: 被删除的对象,如果自身为灰色或者白色,那么被标记为灰色。不用执行STW就可以保证GC的正确执行.
缺点:这种方式的回收精度低,一个对象即使被删除了最后一个指向它的指针也依旧可以活过这一轮,在下一轮GC中被清理掉。
混合写入屏障
1、GC开始将栈上的对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需STW)
2、GC期间,任何在栈上创建的新对象,均为黑色。
3、被删除的对象标记为灰色。
4、被添加的对象标记为灰色。
满足: 变形的弱三色不变式.
Golang中的混合写屏障满足弱三色不变式,结合了删除写屏障和插入写屏障的优点,只需要在开始时并发扫描各个goroutine的栈,使其变黑并一直保持,这个过程不需要STW,而标记结束后,因为栈在扫描后始终是黑色的,也无需再进行re-scan操作了,减少了STW的时间。
相关链接
Go Question
How does GMP scheduler work
GMP工作模型
Golang三色标记+混合写屏障GC模式全分析