
在讲变量逃逸之前,我们首先要先熟悉堆(Heap)和栈(Stack)这两个概念
- 程序内存布局场景下,堆与栈表示两种内存管理方式;
- 数据结构场景下,堆与栈表示两种常用的数据结构。
本次我们要用到的是程序内存布局的场景,因此先对这种情况进行简单说明。
(想详细的了解可以去看看下面这篇文章)
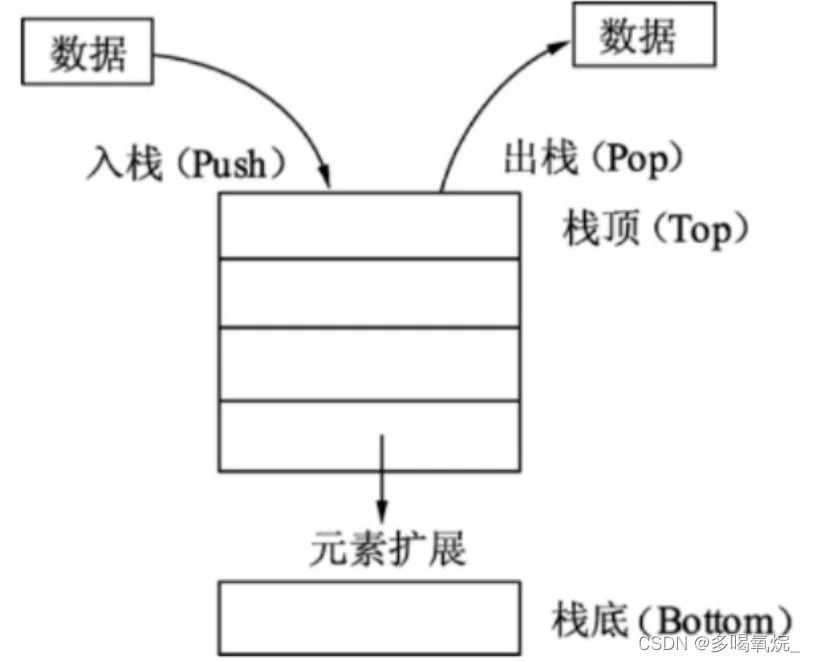
栈只允许从线性表的同一端放入和取出数据,按照后进先出(LIFO,Last InFirst Out)的顺序,如下图:
对于堆在内存中的分配,我们可以类比成一个房间,分配内存时,需要找一块足够装下家具的空间来摆放家具。经过反复摆放和腾空家具后,房间里的空间会变得乱七八糟,此时再往这个空间里摆放家具会发现虽然有足够的空间,但各个空间分布在不同的区域,没有一段连续的空间来摆放家具。此时,内存分配器就需要对这些空间进行调整优化,如下图:

❝对比栈和堆可知,在编译时,一切无法确定大小或大小可以改变的数据,最好放到堆上,堆适合不可预知大小的内存分配。但是为此付出的代价是分配速度较慢,而且会形成内存碎片。 ❞
函数中申请一个新的对象:
-
如果分配在栈中,则函数执行结束可自动将内存回收;
-
如果分配在堆中,则函数执行结束可交给GC(垃圾回收)处理;
减少逃逸,将变量限制在栈上
变量逃逸一般发生在如下几种情况:
- 变量较大(栈空间不足)
- 变量大小不确定(如 slice 长度或容量不定)
- 返回地址
- 返回引用(引用变量的底层是指针)
- 返回值类型不确定(不能确定大小)
- 闭包
- 其他
知道变量逃逸的原因后,我们可以有意识地控制变量不发生逃逸,将其控制在栈上,减少堆变量的分配,降低 GC 成本,提高程序性能。
「逃逸分析」就是程序运行时内存的分配位置(栈或堆),是由编辑器来确定的,而非开发者。
编译器会根据变量是否被外部引用来决定是否逃逸:
-
如果函数外部没有引用,则优先放到栈中;
-
如果函数外部存在引用,则必定放到堆中;
-
如果栈上放不开,则必定放到堆上;
指针逃逸
我们知道Go可以返回局部变量指针,这种情况下,函数虽然退出了,但是因为指针的存在,对象的内存不能随着函数结束而回收,因此只能分配在堆上。
函数 PersonRegister() 内部 p 为局部变量,其值通过函数返回值返回, p 本身为一指针,其指向的内存地址不会是栈而是堆,这就是典型的逃逸案例。
-gcflag=-m代码第9行显示”escapes to heap”,表示该行内存分配发生了逃逸现象。
栈空间不足逃逸
上面代码 Slice() 函数中分配了一个1000个长度的切片,是否逃逸取决于栈空间是否足够大。直接查看编译提示,如下:
s := make([]int, 10000, 10000)发现当切片长度扩大到10000时就会逃逸。当栈空间不足以存放当前对象时或无法判断当前切片长度时会将对象分配到堆中。
动态类型逃逸
在 Go 中,空接口 interface{} 可以表示任意的类型,如果函数参数为 interface{},编译期间很难确定其参数的具体类型,也会发生逃逸。
因为 fmt.Println() 的参数类型定义为 interface{},因此也发生了逃逸。
闭包引用对象逃逸
回Fibonacci数列的函数:
Fibonacci()函数中原本属于局部变量的a和b由于闭包的引用,不得不将二者放到堆上,以致产生逃逸:
-
栈上分配内存比在堆中分配内存效率更高
-
栈上分配的内存不需要 GC 处理,而堆需要
-
逃逸分析目的是决定内分配地址是栈还是堆
-
逃逸分析在编译阶段完成
传值 VS 传指针
「函数传递指针真的比传值效率高吗?如果拷贝的数据量小,由于指针传递会产生逃逸,可能会使用堆,增加垃圾回收(GC)的负担,所以传递指针不一定 是高效的。」