

对于写业务的同学来说,学习汇编可能没必要,仅仅关注业务逻辑即可。
但是当你要深入去优化代码结构、系统架构,就不得不去深入了解golang这门语言,去了解golang内核实现:比如goroutine调度、io调度、map实现、string实现。当然,golang内核有go实现,也有汇编实现。
为了做更深入的优化,我们需要了解plan9汇编,有时候不得不去写汇编,甚至根据特定汇编指令集来做优化。(主要以x86/64架构)
比如我们去看strings.Index实现,其中有一段代码是汇编所写:
我们不禁会想,golang为何要用汇编来实现这种简单的Index函数?该如何理解?
<h2>plan9汇编简介</h2>主要包括:文件命名、指令集、寄存器、函数声明、全局变量声明、跳转、栈分布、调用栈、编译/反编译工具
<h2>文件命名</h2>由于不同的平台架构支持的汇编指令集不一样,需要针对不同的架构写不同的汇编实现。
通常文件命名格式:<i>功能名_arch.s</i>
比如:<i>indexbyte_386.s, indexbyte_arm64.s, indexbyte_s390x.s</i>
使用go build编译的时候,会自动根据当前arch平台使用对应的arch文件(或者使用 build tag)
这里自行去查找不同的架构指令集即可(cat /proc/cpuinfo | grep flags | head -1)
<h2>寄存器</h2>有4个核心的伪寄存器,这4个寄存器是编译器用来维护上下文、特殊标识等作用的:
FP(Frame pointer): arguments and locals
PC(Program counter): jumps and branches
SB(Static base pointer): global symbols
SP(Stack pointer): top of stack
所有用户空间的数据都可以通过FP/SP(局部数据、输入参数、返回值)和SB(全局数据)访问。 通常情况下,不会对SB/FP寄存器进行运算操作,通常情况以会以SB/FP/SP作为基准地址,进行偏移解引用 等操作。
其中1: SP有伪SP和硬件SP的区分:伪SP: 本地变量最高起始地址硬件SP: 函数栈真实栈顶地址
他们的关系是:
2: FP伪寄存器FP伪寄存器: 用来标识函数参数、返回值
和伪SP寄存器的关系是:
3: 参数/本地变量访问通过symbol /-offset(FP/SP)的方式进行使用
例如arg0 0(FP)表示第函数第一个参数其实的位置,arg1 8(FP)表示函数参数偏移8byte的另一个参数。arg0/arg1用于助记,但是必须存在,否则无法通过编译(golang会识别并做处理)。其中对于SP来说,还有一种访问方式: /-offset(FP)
这里SP前面没有symbol修饰,代表这硬件SP
4: PC寄存器
实际上就是在体系结构的知识中常见的pc寄存器,在x86平台下对应ip寄存器,amd64上则是rip。除了个别跳转 之外,手写代码与PC寄存器打交道的情况较少。
5: SB寄存器
SP是栈指针寄存器,指向当前函数栈的栈顶,通过symbol offset(SP)的方式使用。offset 的合法取值是 [-framesize, 0),注意是个左闭右开的区间。假如局部变量都是8字节,那么第一个局部变量就可以用localvar0-8(SP) 来表示。
6: BP寄存器
还有BP寄存器,是表示已给调用栈的起始栈底(栈的方向从大到小,SP表示栈顶);一般用的不多,如果需要做手动维护调用栈关系,需要用到BP寄存器,手动split调用栈
7: 通用寄存器
在plan9汇编里还可以直接使用的amd64的通用寄存器,应用代码层面会用到的通用寄存器主要是: rax, rbx, rcx, rdx, rdi, rsi, r8~r15这14个寄存器。plan9中使用寄存器不需要带r或e的前缀,例如rax,只要写AX即可:
代码示例:
各个变量通过寄存器解引用如下:(伪FP=伪SP 16=硬件SP 24)
<ul><li>a:a 0(SP)或者a 16(SP)</li><li>b:b 8(SP)或者a 24(SP)</li><li>c:c 16(SP)或者a 32(SP)</li><li>sum:sum-8(SP)或者a-24(FP)</li></ul><h2>函数声明</h2>
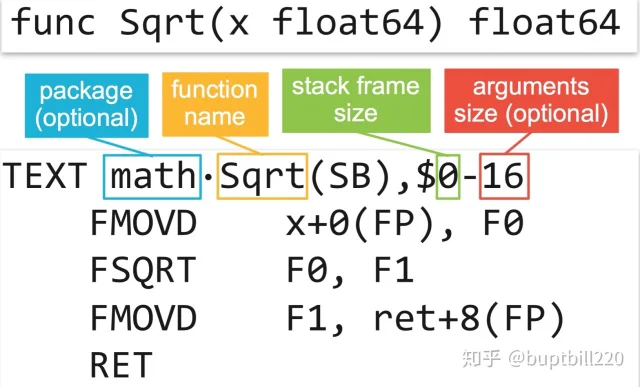
此处声明了一个函数sqrt,函数的声明以 TEXT 标识开头,以 {package}·{function} 为函数名。 如何函数属于本package时,通常可以不写{package},只留·{function}即可。· 在mac上可以用shift option 9 打出。$0表示该函数栈大小为0byte,计算栈大小时,需要考虑局部变量和本函数内调用其他函数时,需要传参的空间,不含函数返回地址和CALLER BP。 $16表示该函数入参和返回值一共有16byte。当有NOSPLIT标识时,可以不写输入参数、返回值占用的大小(这时候会强行插入CALLER BP)。
为了在golang代码里能引用这个函数我们需要做如下申明:
全局变量的数据部分采用DATA symbol offset(SB)/width, value格式进行声明。<>表示该变量只在该文件内全局可见。
跳转分为section跳转或者函数调用跳转
<ul><li>section跳转 <ul><li>类似JNE,JBE,JE,JGE等;其中sp/bp不会变化;栈空间不变,不存在参数传递需求</li></ul></li></ul><ul><li>函数调用跳转 <ul><li>JMQ sp/bp不会变化;栈空间不变。通常需要调用者和被调用者协商好使用那些寄存传递参数,调用者将参数写入这些寄存器</li><li>CALL 栈空间会发生响应的变化,传递参数时,我们需要输入参数、返回值按之前将的栈布局安排在调用者的栈顶(低地址段),然后再调用CALL命令来调用其函数,调用CALL命令后,SP寄存器会下移一个WORD(x86_64上是8byte),然后进入新函数的栈空间运行</li></ul></li></ul><h2>栈分布</h2>如果没有本地变量,栈分布如下
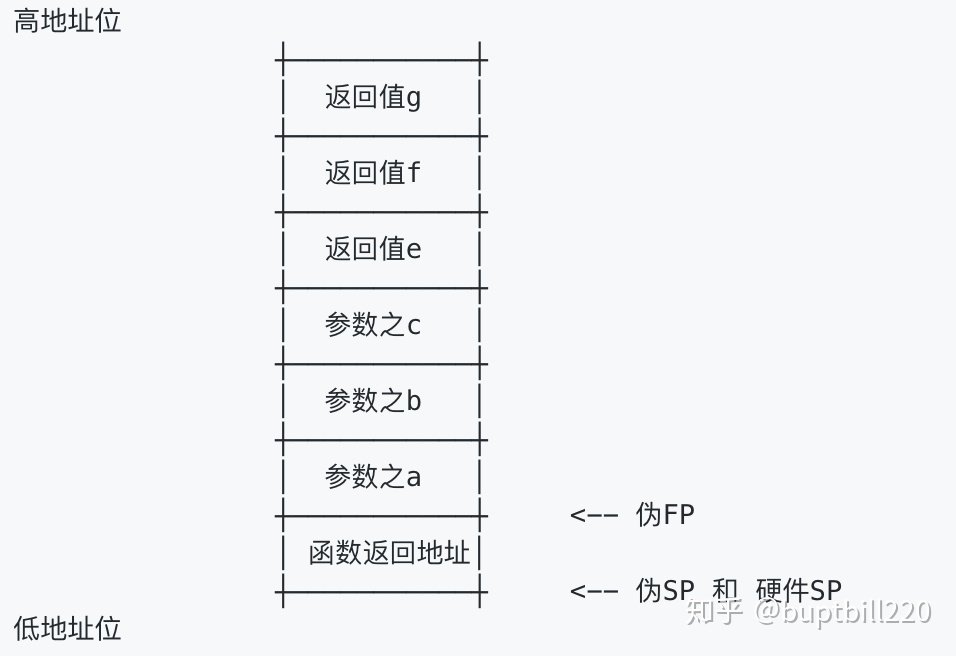
如果有本地变量,栈分布如下 ```javascript func zzz(a, b, c int) [3]int{ var d [3]int d[0], d[1], d[2] = a, b, c return d } ```

这里以一个函数调用过程A->B->C为例了来解释调用栈过程
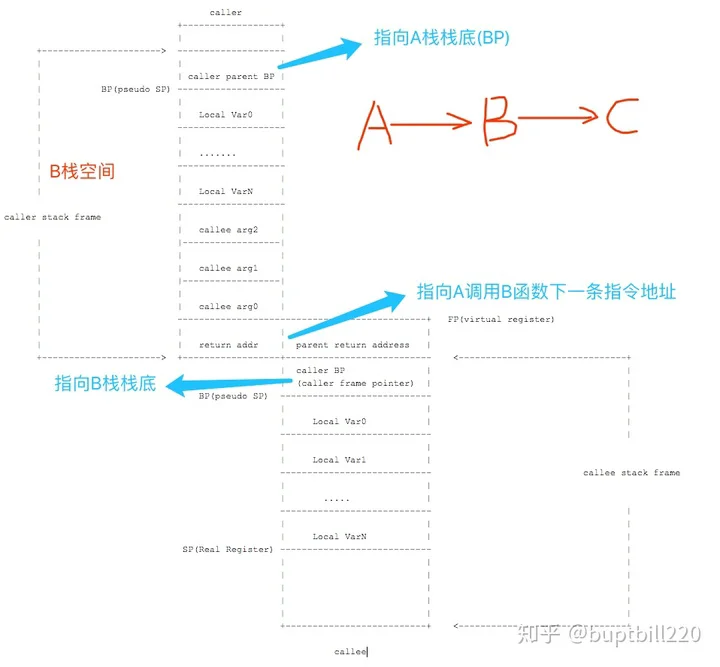
实践出真知,很多时候我们无法确定一块代码是如何执行的,需要通过生成汇编、反汇编来研究golang。这里给一些工具来帮助我们了解golang
纸上得来终觉浅,绝知此事要躬行。只有亲自写汇编代码才能帮助我们更好的了解汇编。
我们分别从2部分实践:
<ul><li>了解SP、FP的关系,输入、输出</li><li>做一个简单的函数,实现手动管理栈</li></ul><h2>练习一:分别获取当前伪SP、硬件SP、伪FP地址</h2>思路:使用LEA把各个寄存器的地址传出来即可
输出如下: <i>824634359232, 824634359232, 824634359240</i>
可以看到没有本地变量的情况下:伪SP=硬件SP=FP-8
思考:如果把中间的NOSPLIT去掉结果如何?如果把$0-24改成$8-24结果如下?
思路:使用递归调用;扩容栈16个字节用来存储递归调用所需的输入和输出
整个调用栈管理如下,这里用16字节是为了节省栈空间(2次调用输入输出参数共用同一块地址)
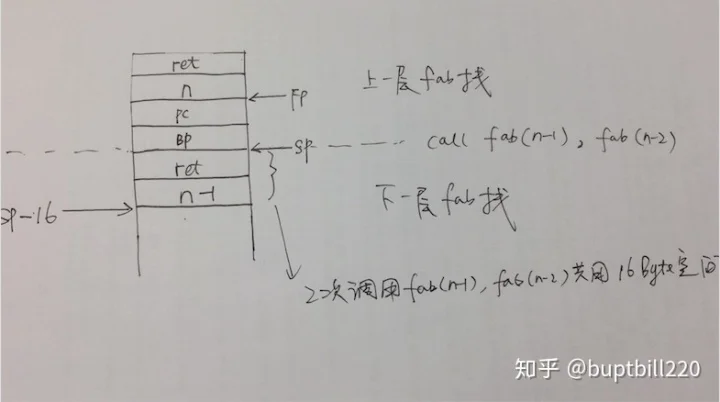
golang汇编难点在于掌握几个寄存器的关系以及栈分布以及调用栈的过程(无关今紧要的没讲)。想要深入理解,需要多实践。最终目的不一定要熟练写汇编代码,更多的是懂得golang底层机制以及学习人家优化思想。
<ul><li>相关参考文献(相关资料很少,主要参考下面,有些介绍不详细,文中都做了重点标注)https://lrita.github.io/images/posts/go/GoFunctionsInAssembly.pdfhttps://lrita.github.io/2017/12/12/golang-asm/#go函数调用</li><li>代码地址https://github.com/buptbill220/gotls/tree/master/interesting</li></ul>