
堆排序思想
利用最大堆、最小堆 堆顶元素最大、最小,每次获得一个最大最小值
关键点
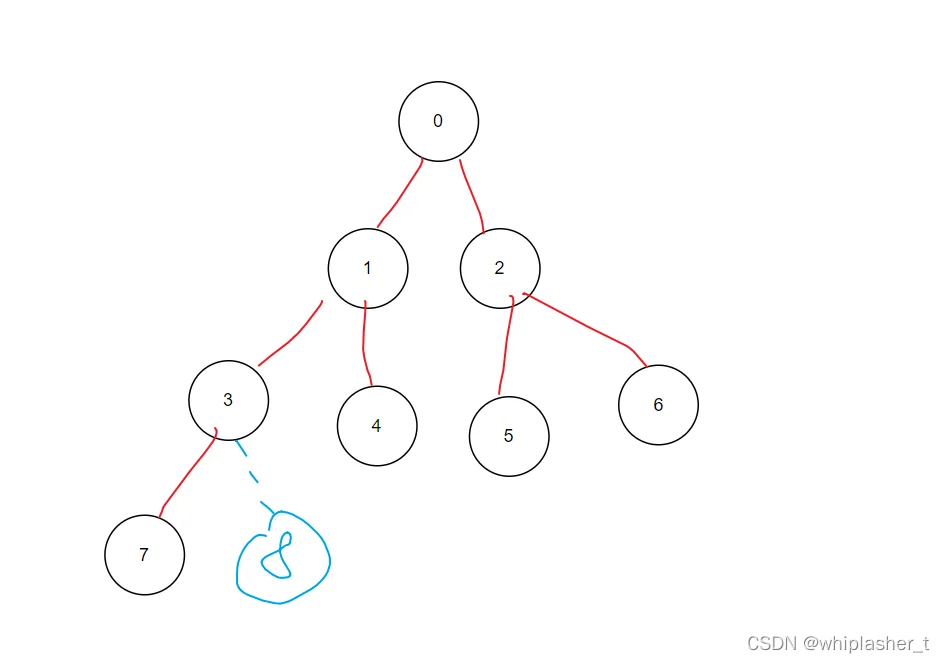
如代码注释中所示
A. 数组长度/2,从这个下标开始的原因是:
上图的例子中,就是从4这个节点开始(9/2或8/2)都是4,这保证所有 有子节点的节点都能进行down这个操作,这由二叉树的性质决定的
B down这个操作,每一次递归的作用是,保证每一个单元,比如最小堆,每一个如3,7,8组成的三节点都满足最小堆的性质,就是父节点值最小。down操作进行直到左儿子节点下标超过数组长度了就结束。
从底层有儿子节点的第一个节点开始,都做一遍down操作,那么就将整棵树heapfy也就是堆化了。
一遍down操作就是保证从某个节点开始,它所有的子节点都满足最小堆
B1 二叉树性质决定 左儿子的下标为2p+1, 右孩子 2p+2
C 堆排序
先堆化,以最小堆为例,堆化后最顶层的节点就是最小的
然后将它和最后一个(最下最右),即数组中的最后一个元素进行交换。交换后,祖先节点不满足最小堆,从它开始down,不考虑数组最后一个元素。以此类推。
(堆排序完成后会破坏堆结构)
D.维持堆性质进行堆的插入
堆排序用不上,但一般实现堆的包都有pop和push接口,push就是默认在插入的同时维持堆的性质。插入到最后一个元素,并进行up操作。
代码
func heapfy(data []int,dataLen int){
for i:=dataLen/2;i>=0;i--{ //关键点A
down(data,i,dataLen)
}
}
func down(data []int,p,dataLen int){ //B
left ,right,min := 2*p+1,2*p+2,p //B1
if left<dataLen{
if data[left]<data[min]{
min = left
}
}
if right<dataLen && data[right]<data[min]{
min = right
}
if min != p{
data[p],data[min] = data[min],data[p]
if min*2 < dataLen{
down(data,min,dataLen)
}
}
}
func HeapSort(data []int){ //C
dataLen := len(data)
heapfy(data,dataLen)
for tail:=dataLen-1;tail>0;tail--{
data[0],data[tail]=data[tail],data[0]
down(data,0,tail)
}
}
func Insert(data *[]int){ //D
dataLen := len(*data)
heapfy((*data),dataLen)
*data = append((*data), 0)
up(*data,len(*data)-1)
}
func main(){
data:=[]int{4,2,5,1,3}
//HeapSort(data)
Insert(&data)
fmt.Println(data)
}
func up (data []int,p int){
if p>0{
parent := (p+1)/2-1
if data[parent]>data[p]{
data[parent] ,data[p] = data[p],data[parent]
up(data,parent)
}
}
}