
作为一名非科班的gophper,参加go面试时遭遇了滑铁卢,面试官特别关心底层的问题,有的东西感觉看过,一问就答不上来,遂以此贴记录面试遇到过的问题,打怪升级!!
第一个问题就慌了,知道怎么回事,就是不会表达!
1.函数体内嵌套另一个函数,并且返回值是函数体。
2.主函数体内的子函数被主题函数外变量引用时,就创建一个闭包。
3.不同的变量引用各自调用没有关系。
4.闭包函数不会被GC(垃圾回收机制)回收所占用资源,因此会出现外部调用时会接着上次调用的结果。
package main
import "fmt"
func test01(base int) (func(int) int, func(int) int) {
// 定义2个函数,并返回
// 相加
add := func(i int) int {
base += i
return base
}
// 相减
sub := func(i int) int {
base -= i
return base
}
// 返回
return add, sub
}
func main() {
f1, f2 := test01(10)
// base一直是没有消掉
fmt.Println(f1(1), f2(2))
// 此时base是9
fmt.Println(f1(3), f2(4))
}
我:map底层是用哈希表实现的
大佬:map的底层结构和实现原理巴拉巴拉
原文链接:https://blog.csdn.net/y1391625461/article/details/124407501
Golang中的Goroutine的特性:
Golang内部有三个对象: P对象(processor) 代表上下文(或者可以认为是cpu),M(work thread)代表工作线程,G对象(goroutine)。
正常情况下一个cpu对象启一个工作线程对象,线程去检查并执行goroutine对象。碰到goroutine对象阻塞的时候,会启动一个新的工作线程,以充分利用cpu资源。 所有有时候线程对象会比处理器对象多很多。
我们用如下图分别表示P、M、G:
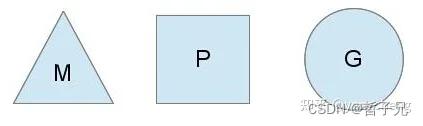
G(Goroutine) :我们所说的协程,为用户级的轻量级线程,每个Goroutine对象中的sched保存着其上下文信息.
M(Machine) :对内核级线程的封装,数量对应真实的CPU数(真正干活的对象).
P(Processor) :即为G和M的调度对象,用来调度G和M之间的关联关系,其数量可通过GOMAXPROCS()来设置,默认为核心数.
在单核情况下,所有Goroutine运行在同一个线程(M0)中,每一个线程维护一个上下文(P),任何时刻,一个上下文中只有一个Goroutine,其他Goroutine在runqueue中等待。
一个Goroutine运行完自己的时间片后,让出上下文,自己回到runqueue中(如下图所示)。
当正在运行的G0阻塞的时候(可以需要IO),会再创建一个线程(M1),P转到新的线程中去运行。
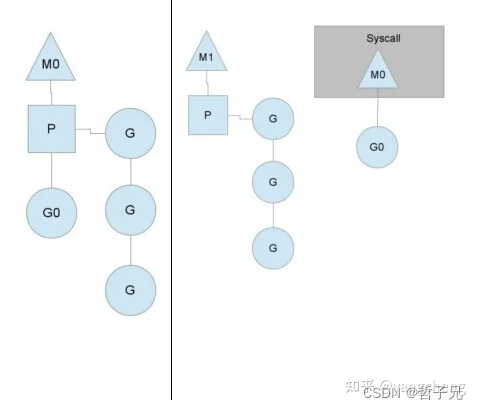
当M0返回时,它会尝试从其他线程中“偷”一个上下文过来,如果没有偷到,会把 Goroutine 放到 Global runqueue 中去,然后把自己放入线程缓存中。 上下文会定时检查 Global runqueue。
原文链接:https://zhuanlan.zhihu.com/p/399205141
协程是轻量级的线程,Go 协程会复用数量更少的 OS 线程。即使程序有数以千计的 Go 协程,也可能只有一个线程。协程和线程在调度和开销上有区别:
- 进程线程都是由操作系统进行调度,协程的调度与切换完全由用户控制
- 线程太重,资源占用太高,频繁创建销毁会带来严重的性能问题;一个协程几乎就是一个普通的对象,初始大小只有2k,切换开销很小。
goroutine是协程的go语言实现,与协程不同的是:
Golang在runtime,系统调用等多方面对goroutine调度进行了封装和处理,即goroutine不完全是用户控制,一定程度上由go运行时(runtime)管理,好处:当某goroutine阻塞时,会让出CPU给其他goroutine。
默认情况下,所有的goroutine都在同一个原生线程里跑,也就是只使用了一个CPU核。通过runtime.GOMAXPROCS(4),可以将goroutine调度到多个CPU上运行。
goroutine的切换方式有两种:
- 阻塞时,会自动让出,可阻塞的操作如io操作、time.sleep。
- 调用runtime.gosched函数,主动切换。
虽然读过源码,但是一问就答不好,再读!
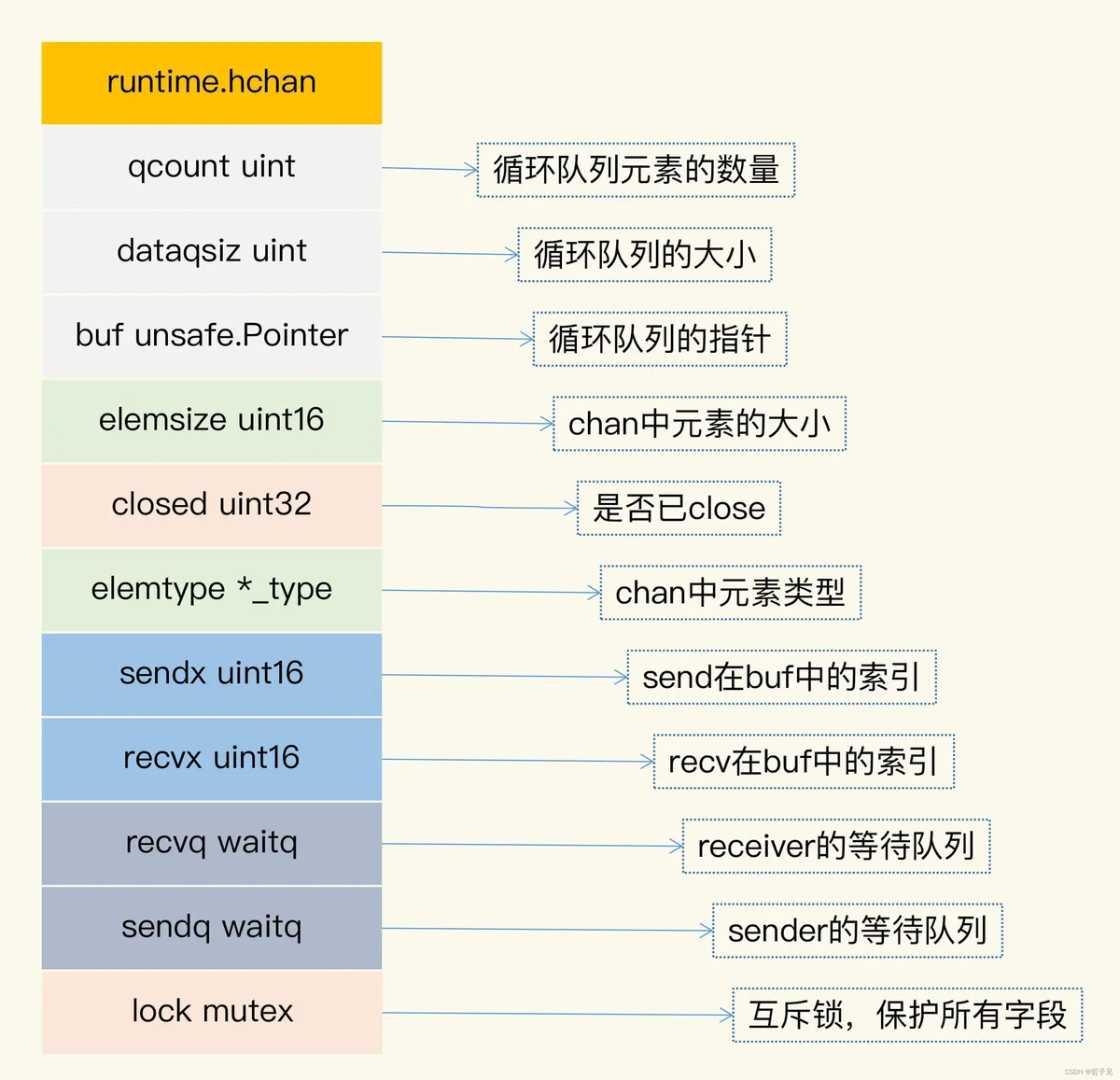
- qcount:代表 chan 中已经接收但还没被取走的元素的个数。内建函数 len可以返回这个字段的值。
- dataqsiz:队列的大小。chan 使用一个循环队列来存放元素,循环队列很适合这种生产者 -
消费者的场景(我很好奇为什么这个字段省略 size 中的 e)。 - buf:存放元素的循环队列的 buffer。
- elemtype 和elemsize:chan 中元素的类型和 size。因为 chan一旦声明,它的元素类型是固定的,即普通类型或者指针类型,所以元素大小也是固定的。
- sendx:处理发送数据的指针在 buf中的位置。一旦接收了新的数据,指针就会加上 elemsize,移向下一个位置。buf 的总大小是 elemsize 的整数倍,而且 buf是一个循环列表。
- recvx:处理接收请求时的指针在 buf 中的位置。一旦取出数据,此指针会移动到下一个位置。
- recvq:chan是多生产者多消费者的模式,如果消费者因为没有数据可读而被阻塞了,就会被加入到 recvq 队列中。
- sendq:如果生产者因为 buf满了而阻塞,会被加入到 sendq 队列中。
sync表有普通锁和读写锁,锁(Mutex)有两个字段:
-
state字段: state 是一个复合型的字段,一个字段包含多个意义,这样可以通过尽可能少的内存来实现互斥锁。前三个bit分别为持有锁的标记、唤醒标记、饥饿标记,剩余bit表示阻塞等待的waiter数量。

-
scheme字段: 是个信号量变量,用来控制等待 goroutine 的阻塞休眠和唤醒。
mutex通过cas指定判断当前gorutine是否可以获取锁(atomic.CompareAndSwapInt32),
Unlock 方法可以被任意的 goroutine 调用释放锁,即使是没持有这个互斥锁的 goroutine,也可以进行这个操作。这是因为,Mutex 本身并没有包含持有这把锁的 goroutine 的信息,所以,Unlock 也不会对此进行检查,可以使用defer让lock和Unlock成对出现。
等待一个 Mutex 的 goroutine 数最大可以支持 1<<(32-3) -1,以goroutine初始大小2k算,约1t空间。
7、tcp与udp的区别摘自极客时间《Go 并发编程实战课》
tcp和udp都是传输层协议。tcp面向连接的字节流模式,需要三次握手建立连接,开销很大,优点是安全,保证数据顺序,被广泛使用;udp不需要连接的数据报文模式,数据有可能丢失,不保证数据顺序。
| TCP | UDP | |
|---|---|---|
| 是否连接 | 面向连接 | 无连接 |
| 是否可靠 | 可靠传输,使用流量控制和拥塞控制 | 不可靠传输,不使用流量控制和拥塞控制 |
| 连接对象个数 | 只能是一对一通信 | 支持一对一,一对多,多对一和多对多交互通信 |
| 传输方式 | 面向字节流 | 面向报文 |
| 首部开销 | 首部最小20字节,最大60字节 | 首部开销小,仅8字节 |
| 适用场景 | 适用于要求可靠传输的应用,例如文件传输 | 适用于实时应用(IP电话、视频会议、直播等) |
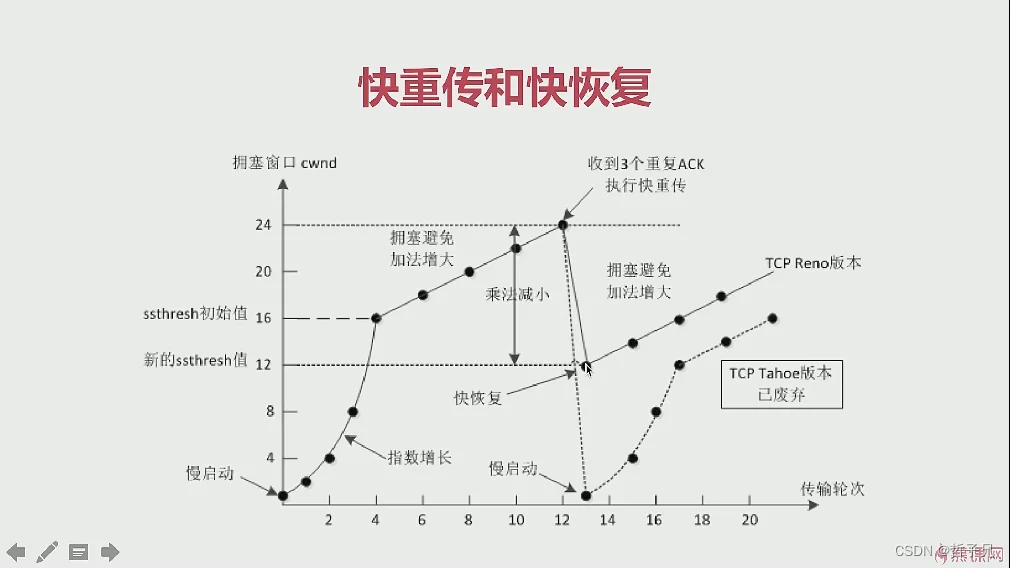
拥塞控制是调整网络的负载。接收方因未及时相应ACK导致发送方重传大量数据,会导致网络更加拥堵,拥塞控制会动态调整win大小,。
拥塞控制的原则:如果网络没有出现拥塞,则增大拥塞窗口。只要网络出现拥塞,就减小拥塞窗口。
拥塞控制机制主要是以下四种机制:慢开始、拥塞避免、快速重传、快速恢复
使用二叉树层级太高,查询数据需要多次访问磁盘,效率低;B+树索引的树根结构只保存索引,所有数据均存储在叶子节点,而且数据是按照顺序排列的,在范围查找,排序查找,分组查找以及去重查找更简单;B树的树根结构也会保存数据,相同的数据量,B+树更矮壮,也是就说,相同的数据量,B+树数据结构,查询磁盘的次数会更少。
10、InnoDB一棵B+树可以存放多少行数据?这个问题的简单回答是:约2千万行。
在计算机中,磁盘存储数据最小单元是扇区,一个扇区的大小是512字节。
文件系统中,最小单位是块,一个块大小就是4k;
InnoDB存储引擎最小储存单元是页,一页大小就是16k。在这里插入图片描述

因为B+树叶子存的是数据,内部节点存的是键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中找到需要的数据;
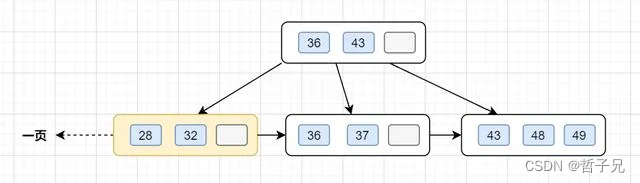
假设B+树的高度为2的话,即有一个根结点和若干个叶子结点。这棵B+树的存放总记录数为=根结点指针数*单个叶子节点记录行数。
如果一行记录的数据大小为1k,那么单个叶子节点可以存的记录数 =16k/1k =16.
非叶子节点内存放多少指针呢?我们假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,所以就是8+6=14字节,16k/14B =16*1024B/14B = 1170
因此,一棵高度为2的B+树,能存放1170 * 16=18720条这样的数据记录。同理一棵高度为3的B+树,能存放1170 *1170 *16 =21902400,也就是说,可以存放两千万左右的记录。B+树高度一般为1-3层,已经满足千万级别的数据存储。
大佬传送门:https://baijiahao.baidu.com/s?id=1692469218111984631
tinyint:储存大小1字节,1字节8位,可储存2^8-1个数据,即0-255。
smallint:储存大小2字节,可储存2^16-1 个数据, 从 -2^15 (-32,768) 到 2^ 15 – 1 (32,767) 的整型数据。
int:储存大小4字节,可储存2^32-1 个数据, 从 -2^31 (-2,147,483,648) 到 2^31 – 1 (2,147,483,647) 的整型数据(所有数字)。
bigint:储存大小8字节,可储存2^64-1 个数据, 从 -2^63 (-9223372036854775808) 到 2^63-1 (9223372036854775807) 的整型数据(所有数字)。
slince是引用传递,array是值传递。slince的底层有三个字段,分别是指向array的指针、长度和容量。
type slice struct {
array unsafe.Pointer //指向数组的指针
len int //slince的长度
cap int //slince的容量,可以自动扩容
}
slince扩容方式:小于1024个元素扩容=len2,超过1024,扩容=len1.25
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
Golang Runtime 是 go 语言运行所需要的基础设施
- 协程调度, 内存分配, GC;
- 操作系统及 CPU 相关的操作的封装(信号处理, 系统调用, 寄存器操作, 原子操作等), CGO;
- pprof, trace, race 检测的支持;
- map, channel, string 等内置类型及反射的实现.
runtime包常用的方法:
- Gosched:让当前线程让出 cpu 以让其它线程运行,它不会挂起当前线程,因此当前线程未来会继续执行
- NumCPU:返回当前系统的
- CPU 核数量
- GOMAXPROCS:设置最大的可同时使用的 CPU 核数
- Goexit:退出当前goroutine(但是defer语句会照常执行)
- NumGoroutine:返回正在执行和排队的任务总数
- GOOS:目标操作系统
原文链接:https://ld246.com/article/1610696930954
14、map为什么是无序的for range map在编译器底层是通过runtime的两个函数实现的,分别是:
- runtime.mapiterinit
- runtime.mapiternext
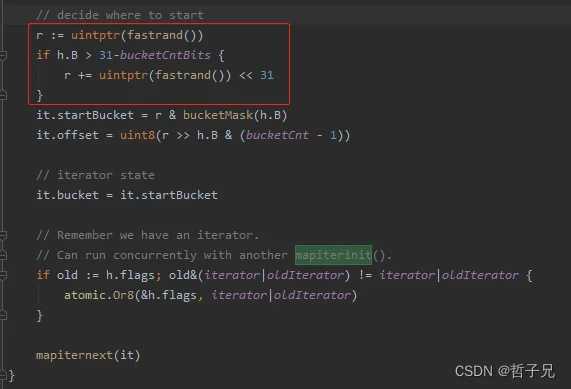
在这段代码中,它生成了随机数。用于决定从哪里开始循环迭代。更具体的话就是根据随机数,选择一个桶位置作为起始点进行遍历迭代
因此每次重新 for range map,你见到的结果都是不一样的。那是因为它的起始位置根本就不固定!