

进阶之路第一步:GO的编码规范
1.什么算高质量编程? 易读易维护高质量在业内并没有一个十分标准的共识,它是一个偏主观的标准
编写的代码能够达到正确可靠、简洁清晰的目标,就是高质量的代码
在实际的业务场景中,经常并不是代码写的越高级就越好,各种边界条件是否考虑完备;异常情况处理;稳定性保证等细节更重要,在保证正确可靠的实现功能的前提下简洁清晰,可阅读性高的代码才是高质量的。
2.编程原则GO语言开发者 Dave Cheney 的观点:
1.简单性
消除“多余的复杂性”,以简单清晰的逻辑编写代码。
在实际开发中,对于一些复杂的逻辑,后来者基本上是不敢怎么动的。尤其是一些历史比较久远的代码,如果在最开始业务处理时没有考虑到后期的优化问题,那对后面进行维护的同学可能是一个灾难。同时对于这些不理解的代码,后接手的人无法修复改进,甚至出现问题无法定位。所以在实际业务开发过程中,简单向是必要要求。
2.可读性
代码是写给人看的,而不是写给机器看的
在不考虑到性能的情况下,只要你能够实现一个功能,那这段代码就是OK的。但是在后续项目迭代的过程中,大部分时间都是对于已有的功能进行完善,很少会有把一块业务整体下线的情况。所以只要不是毁灭性因素导致必须删掉你的代码,那么你写出来的代码的生命周期就会很长,会被不同的人阅读很多次,所以要尽量保证代码对于阅读者是友好的。
2.生产力
团队的工作效率非常重要
个人的力量是有极限的,所以在你的编程生涯中,大部分项目都是团队合作完成的。GO语言本身为了上手容易,就强制了GO开发者统一代码格式。编码在整个项目开发链路中的一个节点,遵循规范,避免常见缺陷的代码能够降低后续联调、测试、验证、上线等各个节点的出现问题的概率,就算出现问题也能快速排查定位,帮助提高整个团队的效率。
Google官方和大规模采用Go的公司,比如Uber(点击直达)都有开源的编码规范文档,这里从中选择比较重要的公共约定部分进行介绍
1.代码格式
gofmt命令使用
Go高版本是自带go fmt的所以我们可以直接使用命令对单个文件进行格式化
gofmt xxx.go //对代码进行格式优化后输出结果
gofmt -w xxx.go //直接优化后保存到原来的代码文件 xxx.go 中
-s -rGoland使用
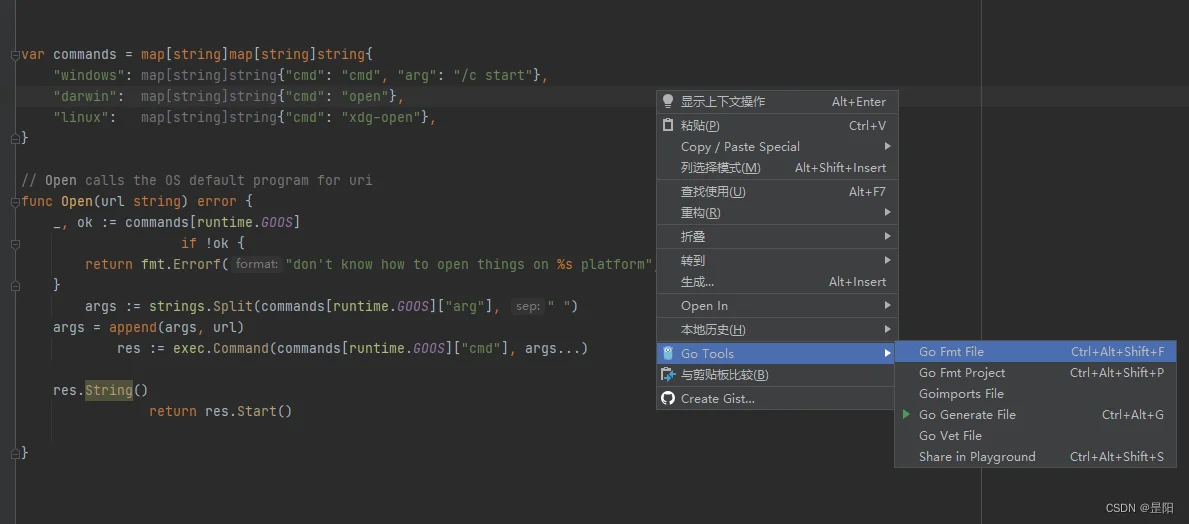
在GoLand中直接使用右键,在Go Tools 选项下你就可以看到两个选项,分别用于格式化单个文件和整个项目
这样虽然相对于命令行虽然快捷了一些,但是也不是很方便,所以懒人们选择安装格式化插件,ctrl+s保存时自动格式化。
先确认你的GoLand上有 file watchers
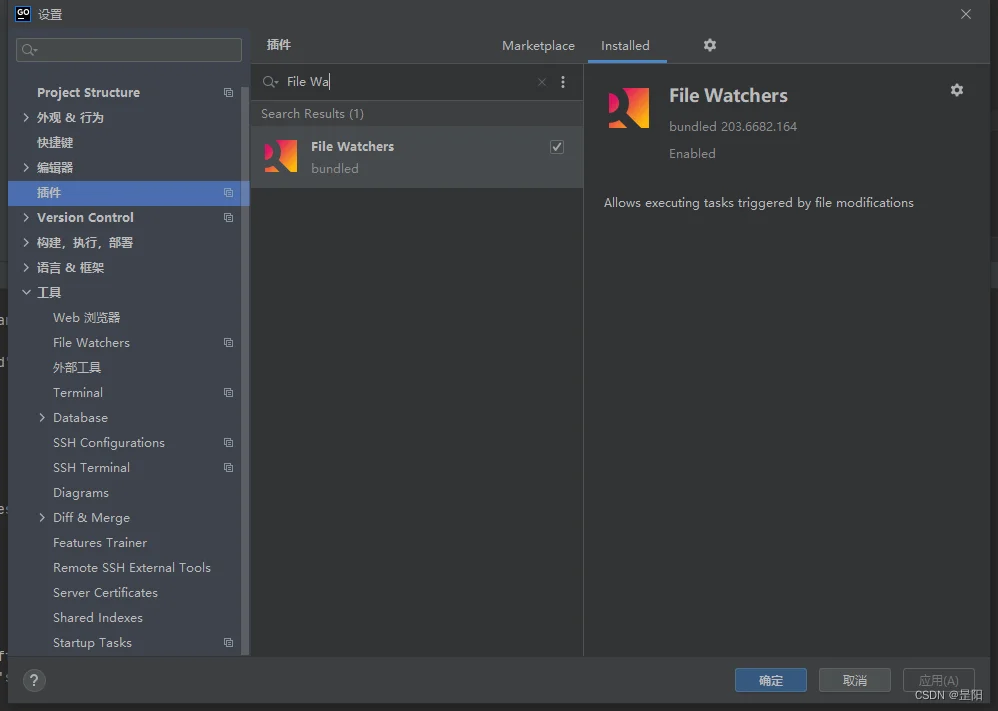
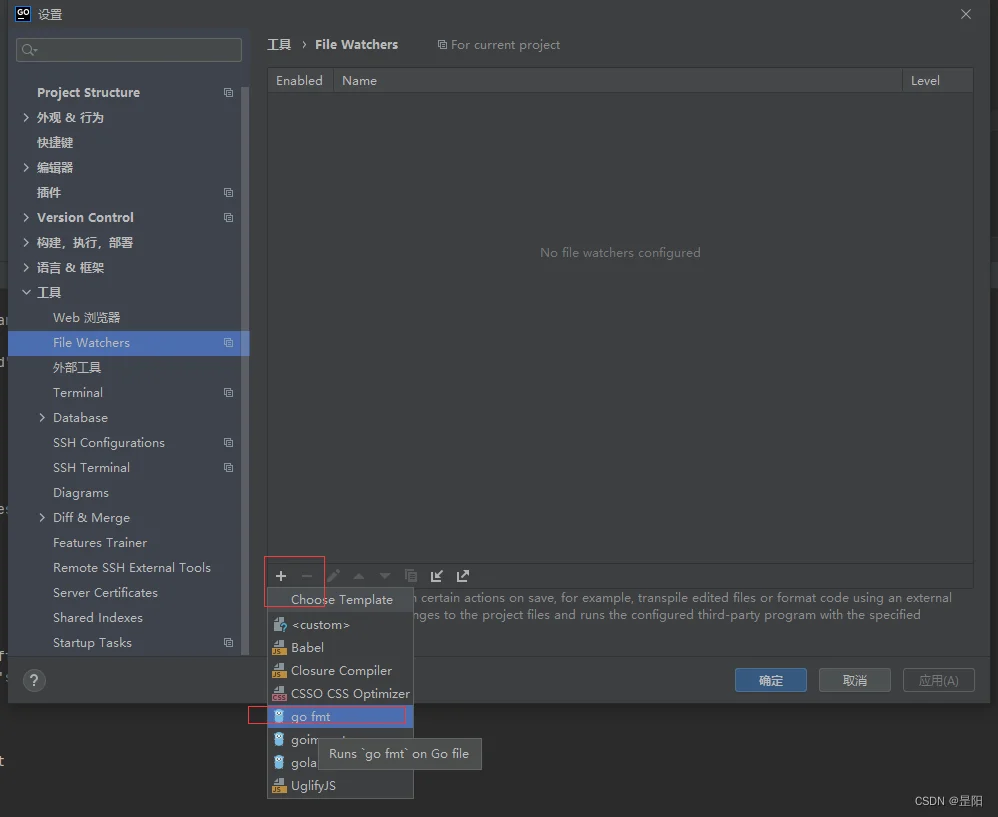
然后在工具找到它(一般情况下能右键看到格式化选项就是已经有了),点击加号选择go fmt
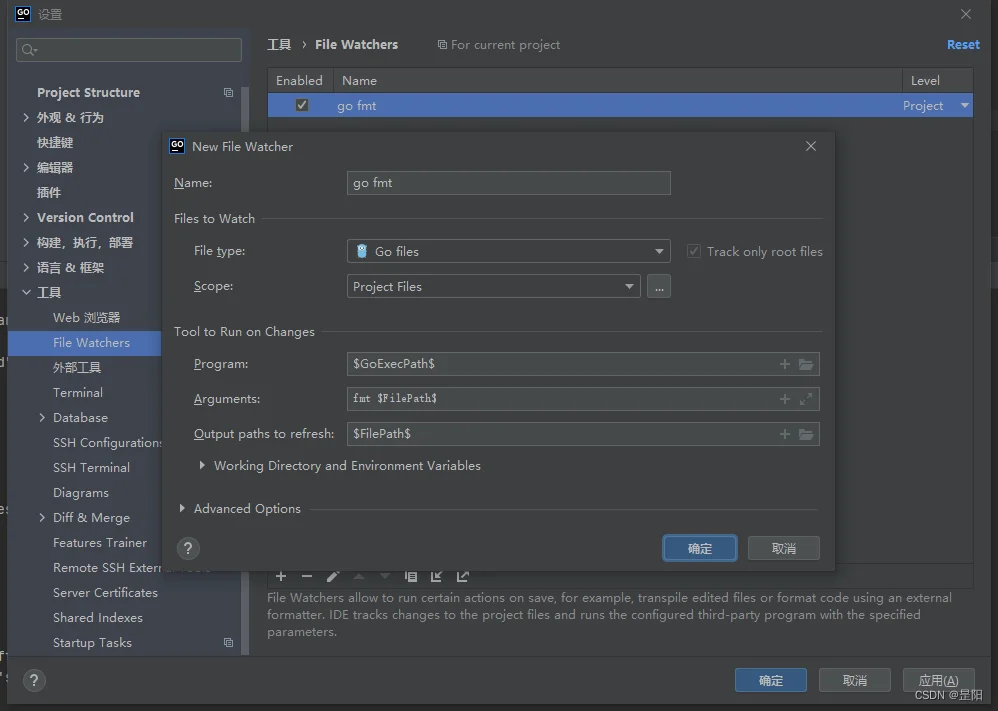
确定并应用就可以使用了,ctrl+s保存时自动格式化
除此之外,在go fmt 选项下面,有一个跟它很相似的选项,它就是另外一个官方的工具goimports
它的功能实际上等于 gofmt 加上 依赖包管理
自动增删依赖包的引用,并将依赖包按照字幕排序并分类。
goimports是需要下载的,首先确认你的GO modules配置了代理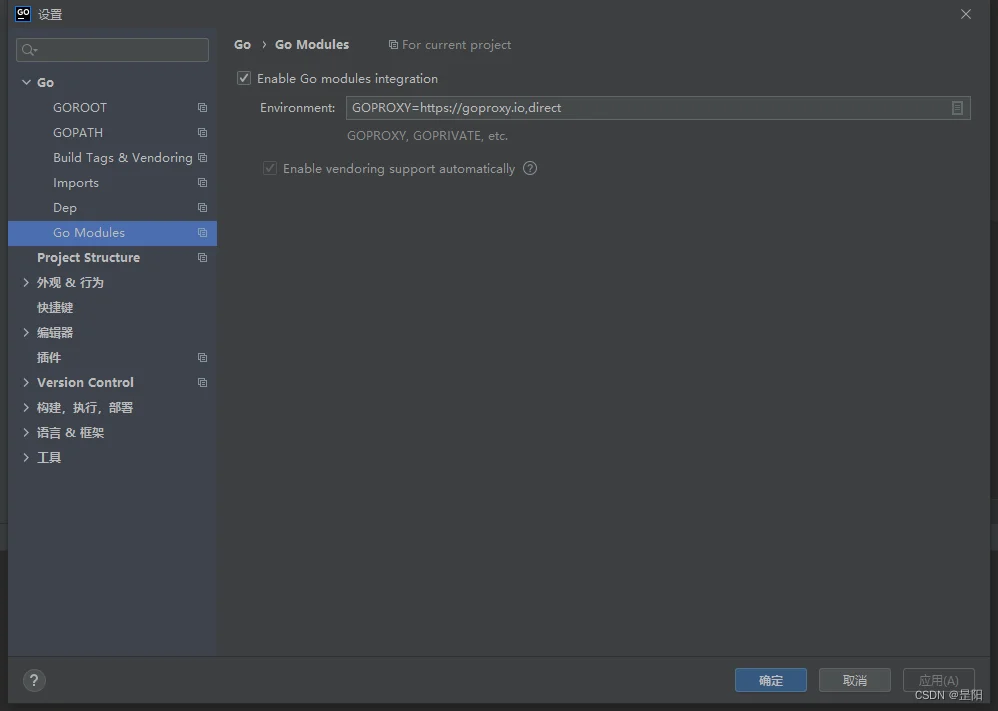
然后重复之前go fmt的操作安装goimports即可。
有一个小细节,如果你没有配置代理,安装失败了,再次应用时会发现红色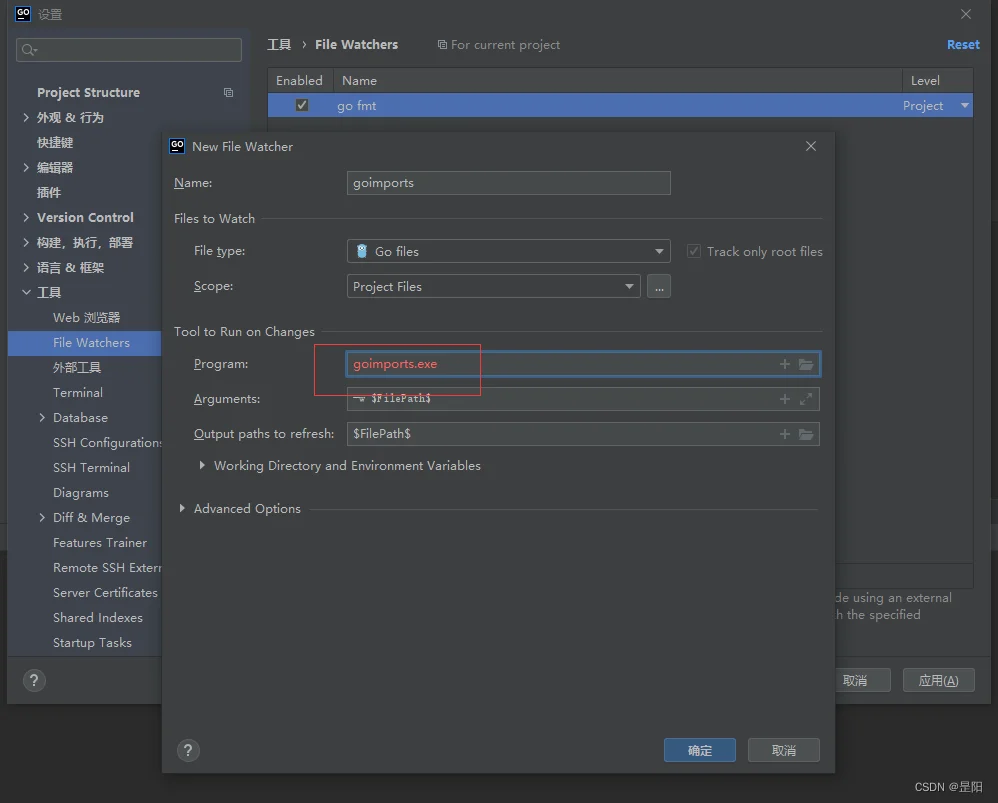
那么在配置代理后,直接在控制台安装后再用就可以了
go get golang.org/x/tools/cmd/goimports
2.注释

注释 可谓是一个老生常谈的问题了
我们在实际编码过程中,大多数时间都在关注代码实现,但是注释的重要性有时候甚至大于代码本身,不能忽略。
如果有人拿着几年前你写的代码来问你实现的功能是什么,你会庆幸自己当时写了含有足够信息的注释的。
那么在日常开发中,注释应该遵循那些规范呢?大致有以下四点
1.注释应该解释代码作用

GO语言的官方代码是十分规范的,这里四个点我随便点了点都能找到相应的注释。例如上方的注释,是来自于我们常用的time包的sleep方法,经常使用它的同学应该很熟悉,它的官方注释就是在说它的作用:Sleep将当前goroutine暂停至少一段时间d。一个负数或零持续时间会导致睡眠立即恢复。
2.注释应该解释代码是如何做的
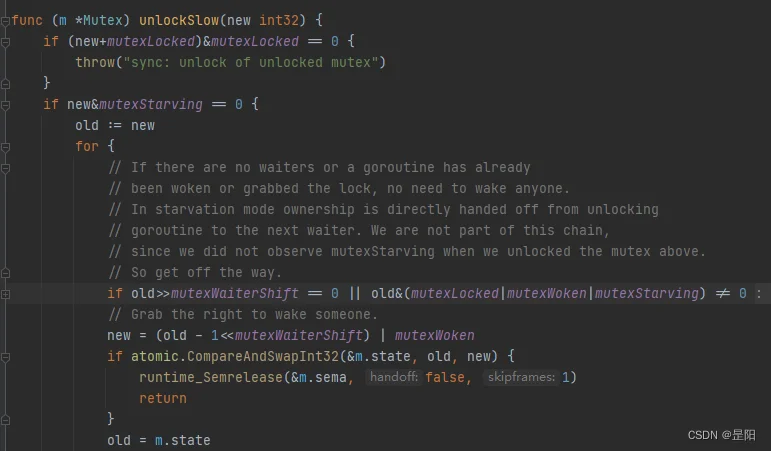
而这里,在go的不可重入的排他锁sync.Mutex的源代码中我们可以看到关于慢解锁函数,如果新的饥饿状态==0,也就是不处于饥饿模式时, 如果mutexLocked、mutexStarving、mutexWoken 都不等于0直接return。单看逻辑可能会有一些难理解,但是配合注释,你很快就可以明白,这里的逻辑是怎么做的
3.注释应该解释代码实现的原因
和我一样的英语渣也不用慌,直接百度翻译,配合上下文仍然能理解意思
如果没有注释的话,我们对于这一段代码的阅读就会很麻烦
4.注释应该解释代码什么情况下会出错
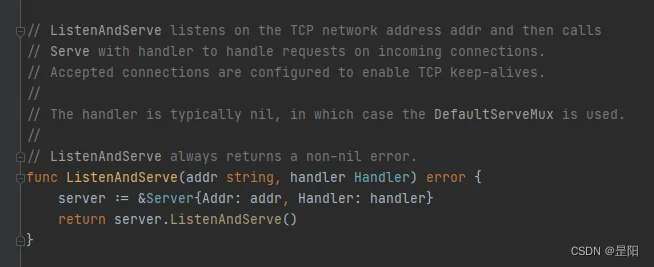
在函数有一些明确的调用条件时,对于一些预料内的错误,可以写入到注释,通过注意注释就可以避免一些使用错误。
同时要注意,在读其他人的代码时,可能会有注释与代码对不上的情况,这点需要注意;
公共符号始终需要注释
代码是最好的注释注释应该提供代码为未表达出的上下文信息3.命名规范
关于变量命名
- 简洁胜于冗长
- 缩略词全大写,但当其位于变量开头且不需要导出时,使用全小写
- 例如使用ServeHT TP而不是ServeHttp
- 使用XMLHTTPRequest或者xmlHTTPRequest
- 变量距离其被使用的地方越远,则需要携带越多的上下文信息
- 全局变量在其名字中需要更多的上下文信息,使得在不同地方可以轻易辨认出其含义
一些经验之谈:
1.命名要名副其实,避免误导理解,也要避免废话,例如在循环语句中使用index与i,index冗余的部分完无意义
2.对于相似部分命名要做有意义的区分,避免1,2,3数字系列
3.使用读得出来的名称,让你在讨论的时候显得不那么傻
4.使用可搜索的名称,让你在想修改的时候能迅速找到它
5.避免思维映射,命名要尽量准确,不应该让读者在脑海中把你的名称翻译为他们想到的数值名称,例如在for range时,你的v命名可以是range对象的实际含义对应数据字段。
6.结构体命名应该是名词或者名词短语,方法名应该是动词或者动词短语
7.别扮可爱,命名不要加入你的幽默,不要用双关语,明确是第一要义
8.每个概念对应一个词,也就是说函数名称要独一无二并贯彻一个命名的方法,一以贯之的命名方法是必要的。而且函数名不要携带包名的上下文信息,因为包名和函数名总是成对出现。
9.读你代码的只会是另一个程序员,所以尽可能的使用程序术语,
而当不能用程序员熟悉的术语来命名的时候,就要使用涉及到的业务领域的名称命名,至少在你的同事看不懂的时候回去问业务方,这玩意为啥这么叫
10.添加有意义的语境,很少有名称是可以自我说明的,所以我们应该有良好的函数空间来放置名称,如果没有,则最好能人为添加语境,比如addr地址前缀
关于包名
- 只由小写字母组成,不包含大写字母和下划线等字符
- 简短并包含一定的上下文信息。例如schema、task等
- 不要与标准库同名。例如不要使用sync或者strings
尽量满足: - 不使用常用变量名作为包名。例如使用bufio而不是buf
- 使用单数而不是复数。例如使用encoding而不是encodings
- 谨慎地使用缩写。例如使用fmt在不破坏上下文的情况下比format更加简短

4.控制流程
避免嵌套,保持正常流程清晰
如果两个分支中都包含return语句,则可以取出冗余的else
if foo {
return x
} else {
return nil
}
//更改为
if foo {
return x
}
return nil
尽量保持正常代码路径为最小缩进
- 优先处理错误情况/特殊情况,尽早返回或继续循环来减少嵌套
错误示例:
func OneFunc() error {
err := doSomething()
if err := nil {
err := doAnotherThing()
if err == nil {
return nil //正常流程
}
return err
}
return err
}
可以看到,示例中正常流程在两个if里,必须仔细匹配大括号来发现,后续如果正常流程需要增加操作,则又会继续嵌套。
当然,我们一般见不到这么离谱的代码,那正常逻辑修改后,他应该是这样的:
func OneFunc() error {
if err := doSomething(); err != nil{
return err
}
if err := doAnotherThing(); err != nil{
return err
}
return nil //正常流程
}
小结:
- 线性原理,处理逻辑尽量走直线,避免复杂的嵌套分支
- 正常流程代码沿着屏幕向下移动
- 提升代码可维护性和可读性
- 故障问题大多出现在复杂的条件语句和循环语句中
5.错误与异常处理
简单错误
- 简单错误指的是仅出现一次的错误,而且在其他地方不需要捕获该错误
- 优先使用errors.New来创建匿名变量来直接表示简单错误
- 如果有格式化的需求则使用fmt.Errorf
示例:
func defaultCheck(req *Request, via []Request) error{
if len(via) >= 10 {
return error.New("stopped after 10 redirects")
}
return nil
}
错误的Wrap和Unwrap
对于复杂的错误,go提供了错误的包装与解包功能,通过Wrap可以把应该错误嵌套到另一个错误,形成跟踪链,结合实际的错误判定方法来确认调用链中,是否有我们关注的错误出现。
我们每一层的调用方都可以补充错误的上下文信息,方便我们根据链路排查问题
- 错误的Wrap实际上是提供了一个error嵌套另一个error的能力,从而生成一个error的跟踪连
- 在fmt.Errorf中使用:%w关键字来将一个错误关联至错误链中
list,_,err := c.GetBytes(cache.Subkey(a.actionID,"srcfiles"))
if err != nil {
return fmt.Errorf("reading srcfiles list:%w"err)
}
错误判定
当我们使用错误链进行处理时,这个链路上可能包含很多类型的错误,直接使用"=="是无法判断的。
- 判断一个错误是否为特定错误使用errors.Is
- 不同于使用==,使用该方法可以判断错误链上所有错误是否含有特定错误
data,err = lockedfile.Read(targ)
if errors.Is(err, fs.ErrNotExist) {
return []byte{},nil
}
return data, err
除了判断是否含有错误外,有时候我们还需要获取错误内容
- 在错误链上获取特定种类的错误,使用errors.As
eg:
if _,err := os.Open("non-existing");err != nil {
var pathError *fs.PathError
if errors.As(err,&pathError) {
//日志输出真正出错的path,方便定位问题
fmt.Println("Failed at path:",pathError.Path)
} else {
fmt.Println(err)
}
}
Painc
- 不建议在业务代码中使用painc
- 调用函数不包含recover会造成程序崩溃
- 若问题可以被屏蔽或解决,建议使用error代替panic
- 当程序启动阶段发生不可逆转的错误时,可以在init或main函数中使用painc
recover
- recover只能在被defer的函数中使用
- 嵌套无法生效
- 只有当前goroutine生效
- defer语句是后进先出的
recover的意义在于如果需要更多的上下文信息,可以在recover后在log中记录当前的调用栈,去定位问题。
小结:
- error 尽可能提供简明的上下文信息链,方便定位问题
- panic 用于真正的异常范围
- recover 生效范围,在当前goroutine的被defer的函数中生效。