
golang是一门非常适合开发高并发服务的语言,而goroutine是golang并行设计的核心。goruntine其实是语言级协程,它非常的轻量,只需要非常少的内存(4~5kb,当然会根据运行环境和数据进行伸缩)。也正因为它的轻量,使得golang的开发者能够通过简单的代码就能够搭起能支撑成千上万并发的web服务。而在golang并发编程中最核心的问题,就是如何进行goroutine间通信。
golang社区中有一句非常经典的话:不要通过共享内存来通信,而应该通过通信来共享内存。在并发场景下,通过共享内存进行进程间通信,需要解决数据的线程安全问题,要加大量的锁。当然在golang所提供的sync包中也提供了传统的锁机制,但程序中使用过多的锁,就会加大代码的复杂度,拉低web服务性能,还稍有不慎就会造成死锁,程序崩溃等等。而golang提供的channel机制,为开发者提供了一种优雅的方式,解决goroutine间通信问题。
channel的作用
channel可以理解为一块单独的内存,根据声明的channel类型不同,可以放1个或以上的数据值。如果channel中的数据已满,那数据的生产者的发送操作会被阻塞直到channel中的数据值被消费者取走。如果channel里没有数据时,那么消费者的读取操作会被阻塞直到生产者往channel中放入新的数据为止。
channel分类
channel 分两种:Unbuffered channels(无缓冲channel,也称为同步channel) 和 Buffered Channels (缓冲形channel)
Unbuffered channels
unbuffered channels用于多goroutine之间同步通信 必须使用make来创建channel,并指定channel中存放数据的类型 通过操作符 <- 来发送或读取channel中的数据
c1 := make(chan int) //用于放置int类型数据的channel
c2 := make(chan string) //用于放置string类型数据的channel
c1 <- 1 //发送数据到int类型的channel
ch := <-c1 //读取channel中的数据保存到变量ch中
Unbuffered channels示例
了解基本语法后,我们来看一个channel的应用例子:
package main
import "fmt"
func main() {
ch := make(chan int)
ch <- 1
fmt.Println(<-ch)
}
上面的代码示例非常简单,创建一个存放int类型数据的channel,往channel中放入数据后,将channel读出并打印。看似完全符合语法逻辑,可当我们编译执行该go文件后,却得到了下面的报错:
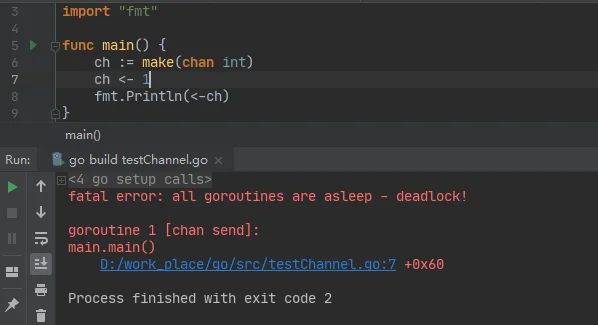
这是unbuffered channels应用中一个最经典的死锁。这个死锁是怎么造成的?要了解该死锁的原因,先了解操作unbuffered channels 发送/读取数据的两个原则:
数据的生产者必须在消费者准备就绪的情况下,才能够往channel中发送数据。channel中有数据时,写操作阻塞。 数据的消费者必须在生产者准备就绪且channel中有数据的情况下才能够读取数据。channel中无数据时,读操作阻塞。
而上图中的示例之所以会发生死锁,是因为生产者(第7行)往unbuffered channel中发送数据前,必须等待消费者(第8行)准备就绪。当程序执行到第7行时,由于消费者未就绪,生产者发送操作被阻塞。同时又因为main线程阻塞,无法执行到第8行,导致消费者永远无法就绪,相互等待导致死锁。要想解决死锁,必须将消息的发送和接收操作放在不同的goroutine中(也可以把其中一个放到main进程中),如下图的示例:
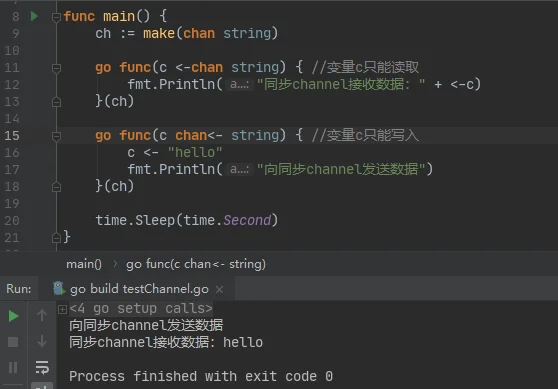
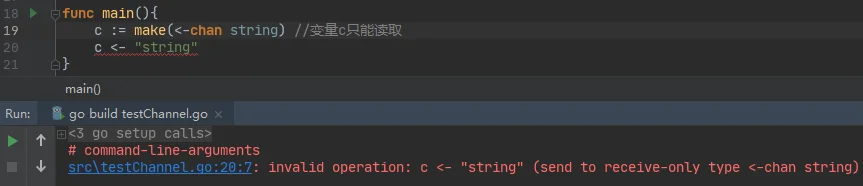
笔者建议初学者在刚进行channel开发时,可以在生产者/消费者的声明中指定对channel的操作方向,如上图中的"c <-chan string" 和 "c chan<- string"。"<-chan" 用于声明该变量只能用于读取,"chan<-"用于声明该变量只能用于写入。这样的强制声明有助于在开发复杂的程序逻辑时避免弄错操作方向,不慎造成死锁。如下方的示例:
Buffered Channels
1.buffered channel用于goroutine间的异步通信
2.必须使用make创建channel,同时指定channel中存放的数据类型和缓冲区大小
c1 := make(chan string, 10) //创建一个缓冲区大小为10的缓冲channel
c1 <- "hello" //发送数据到string类型的缓冲channel
ch := <-c1 //读取channel中的数据保存到变量ch中
Buffered Channels示例
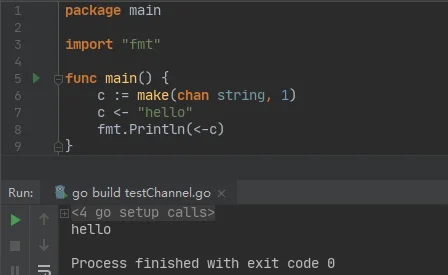
在上图示例中,我们创建了一个缓冲区长度为1的缓冲channel,然后往缓冲channel放入数据,最后读取出来并打印。这里我们可以看到Unbuffered channel和Buffered channel之间最大的区别。相似的代码逻辑,使用Buffered channel却不会造成死锁。也就是说即使Buffered channel声明的缓冲区长度为1(只能一次发送一个数据),但也不等同于Unbuffered channel。下面是Buffered channel的两个原则:
1.生产者在往Buffered channel放入数据时,不需要等待消费者就绪,只要channel缓冲区有位置即可放入。缓冲区满时写操作阻塞。
2.消费者读取Buffered channel中的数据时,不需要等待生产者就绪,只要channel缓冲区中有数据即可读取。缓冲区空时读操作阻塞。
为了更直观的对比Unbuffered channel和Buffered channel,笔者做了下面的对比:
| Unbuffered channel | Buffered channel | |
|---|---|---|
| 相同点 | 1.有数据时阻塞写操作 2.无数据时阻塞读操作 | 1.缓冲区满时阻塞写操作 2.缓冲区无数据时阻塞读操作 |
| 不同点 | 1.只能放一个变量 2.同步通信,通信双方必须都为就绪状态 | 1.可以放一个及以上变量 2.异步通信,通信时双方无需都为就绪状态 |
引用The Nature Of Channels In Go中的两张图来说明Unbuffered channels 和 Buffered channel:
Buffered channel:
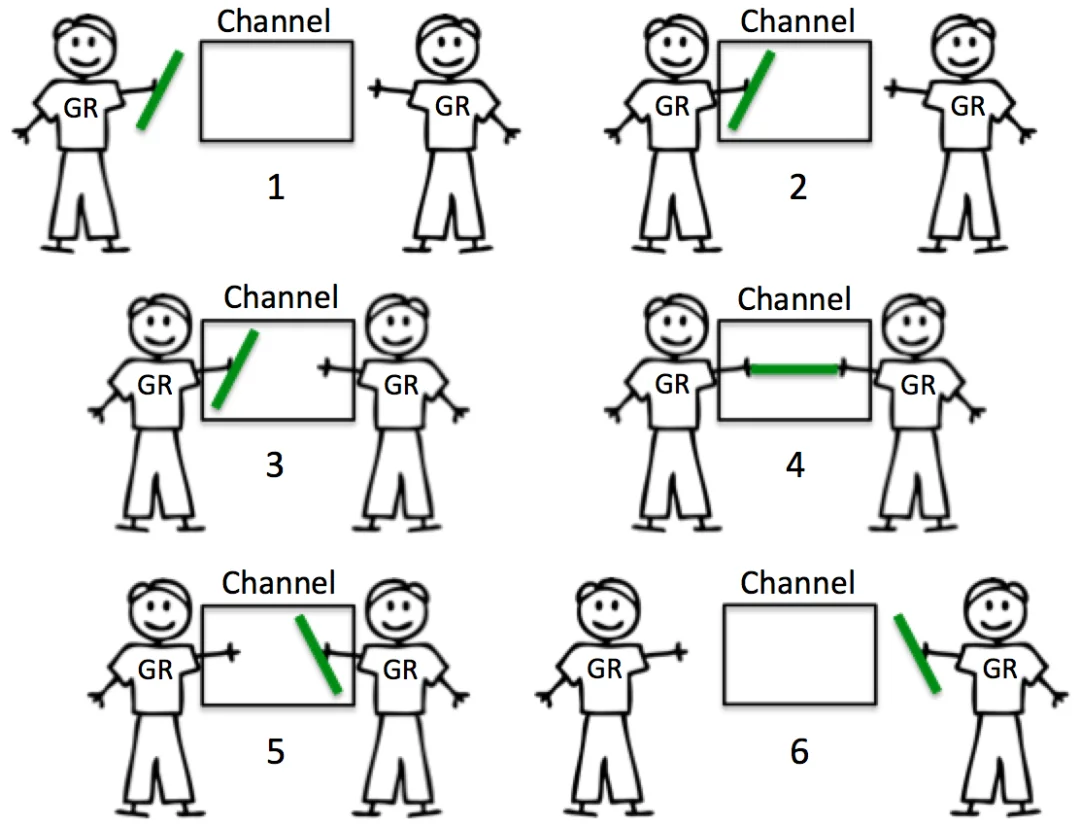
Unbuffered channels:
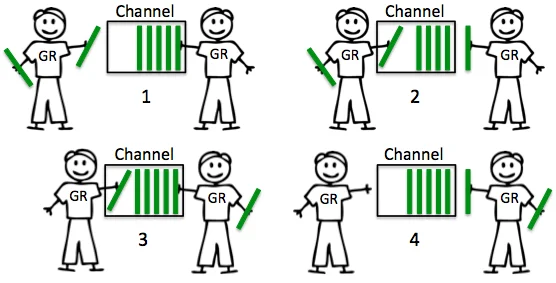
总结
1.使用Unbuffered channel通信就像是两个人在打电话,通话的双方都必须是准备就绪的状态,不能干别的事情,通话的内容也是实时交换的。
2.使用Buffered channel通信就像是两个人共用一个信箱通过写信来传递消息,写信的人不用关心收信人的状态,收信人收信的时候也不用关心写信人的状态。只要信箱装得下,写信人就可以一直塞信进去。同样只要信箱不空,收信人就可以一直收取新的信件。
对比完两种channel的不同点,我们再来讲讲channel还有哪些操作和特性:
1.两种channel都必须用make实例化。对于为nil的channel,读/写操作都阻塞。close一个nil的channel会导致panic。2.两种channel都可以重复使用,不断的读/写数据。开发过程中,可以使用普通的for循环或更灵活的range方式读取数据。使用range方式,能够不断的读取channel中数据,直到channel被显式的关闭。
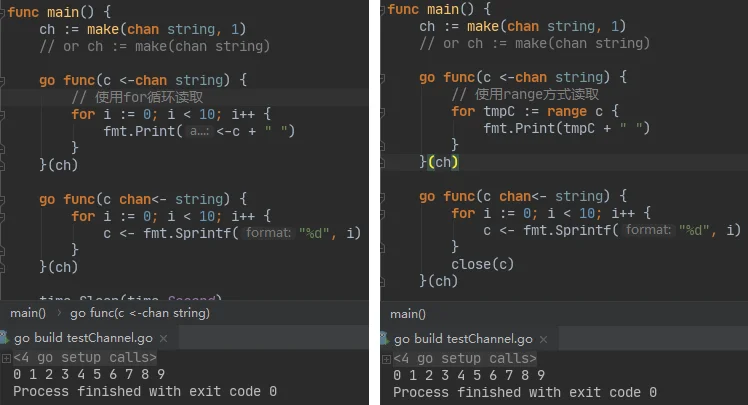
3.channel可以通过chose来关闭。但要注意的是:
已经被关闭的channel,生产者是无法再写入数据的(会导致panic),但关闭的channel依然可以被消费者读取。消费者可以通过 data,ok:=<-ch 的方式来获取通道中的数据和channel是否已被关闭(当ok==false时为关闭)。 当只有一个生产者时,channel应该有生产者发送完数据后或需要结束消费者的range操作时关闭。 有多个生产者时,如果生产者明确知道消息已经发送完且channel未被关闭的情况下,建议由生产者关闭channel。或者可以通过引入监控者监控生产者状态,最后负责关闭channel。close一个已经被关闭的生产者会导致panic,虽然可以使用recover panic的方式保证程序正常运行,但如此粗暴的处理方式,有强迫症的笔者表示可以用但不太建议。 close channel不是必须的,如果channel没有再被goroutine引用,最终也会被GC清理掉
4.可以通过select来管理多个channel的读/写操作。当有多个channel准备就绪时,会随机选择其中一个case操作执行。select类似平常用的switch,不同的case可用于监听不同channel的写入/读取操作,而当所有监听的channel都未准备就绪时,会默认执行default操作。
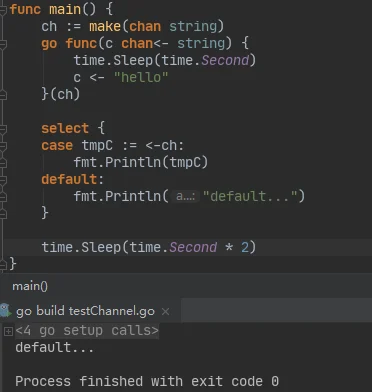
如上图,main线程监听ch的读取操作,由于子goroutine执行time.Sleep 1s操作,导致ch的生产者无法就绪,ch的读操作阻塞,main线程默认执行了default中定义的操作。如果想要保持持续监听的状态,可以用for{}将该select代码块包起来。
channel的典型应用
1.并发处理多任务,并收集处理执行结果
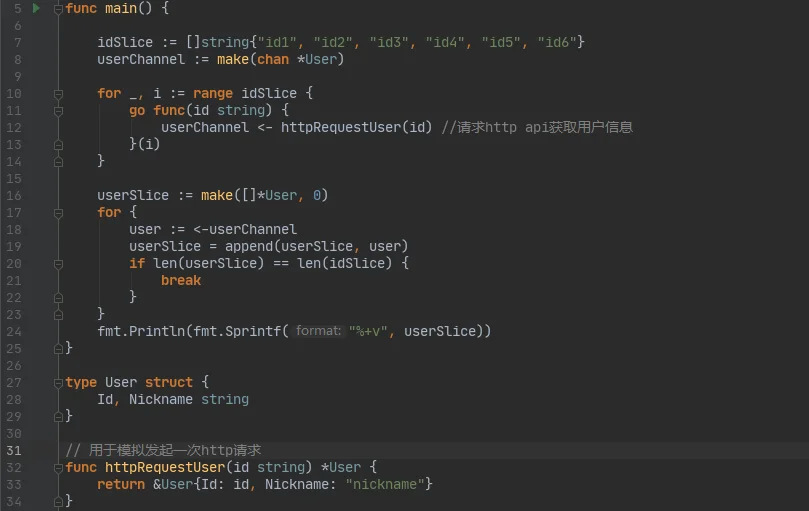
如上图示例所示,需要根据n个id查询n个用户的信息,并以最快的速度返回结果。这个时候就可以使用goroutine发起n个并发请求,并将请求的结果通过userChannel发送给main线程。main线程收集完n个用户信息后,再做其他业务处理。
但在实际的应用场景中,往往第三方api或网络环境并不是100%可靠的。在上图的示例中,只要有一个goroutine超时,mian线程会由于未收集完所有用户信息而一直等待造成阻塞。为了解决这个问题,我们可以上述例子中引入time.After。
如下图红框所示,再创建一个二级的goroutine和一个临时的tmpChannel。二级的goroutine用于请求api并将结果放入tmpChannel。一级goroutine使用select监听tmpChannel是否有数据,有数据的情况下将数据发送给main线程。如果监听超过1s(认为api超时),则将nil发送给main线程,作为获取该id用户信息失败的标识。
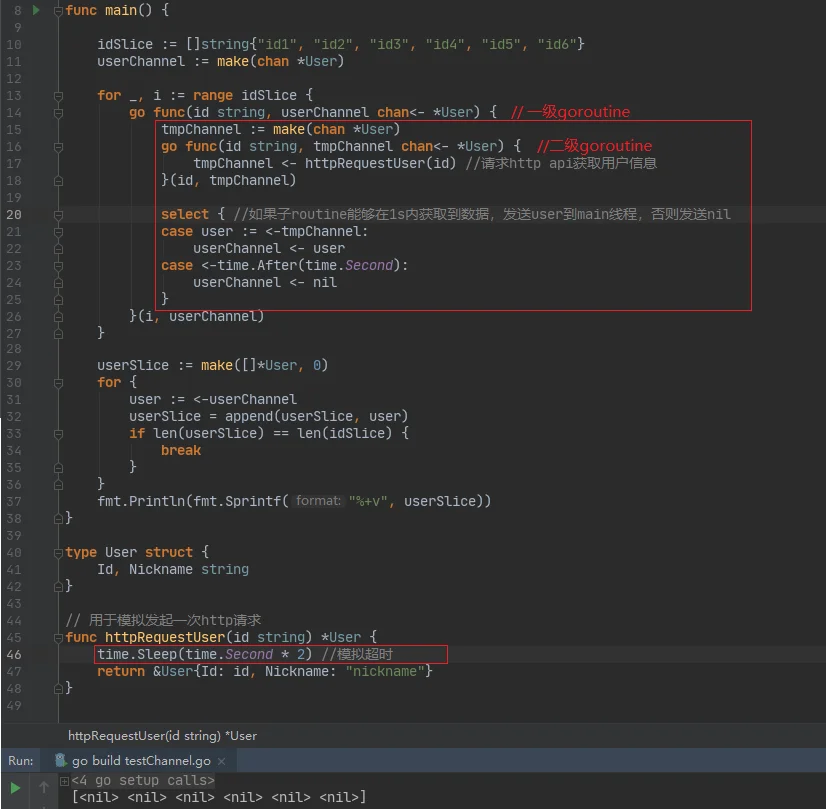
上图的示例,其实就是一个最初级版本的“隔离熔断器”模型。将不可靠的外部依赖交由子goroutine执行,并监控其执行情况。在外部依赖故障的情况下,执行“降级操作”(case <-time.After部分),以降低故障的外部依赖对main逻辑的影响。这些外部依赖可以是各种各样的网络/io请求:mysql/redis/http等等。
而在“降级操作”中,我们还可以再添加channel用于发送错误统计数据,并使用一个单独的master goroutine接收错误统计数据并作分析:
在n秒内外部依赖超时m次时,可以标识该外部依赖不可用,下一次需要请求api时,跳过请求逻辑直接执行“降级操作” 间隔k秒后再将该外部依赖标识为可用,反复监控其状态。
以上都是一个完备的隔离熔断器所具备的功能点,读者有兴趣的也可以找一些相关的源码来看,这里不再展开赘述。
2.并发控制
一个能处理并发请求的web服务通常都不可避免的需要将请求压力下方至基础服务层。但基础服务往往承载n多个上层业务,基础服务一旦抗不住down掉了极有可能导致一连串的上层服务雪崩。除了基础业务本身应提高自身可支撑的并发量外,其实上层业务也有义务在尽可能的情况下,控制下放到基础服务的并发请求量,起消峰填谷的作用。下面的示例,是一个简单的并发控制器,用到了同步锁和channel。
// 1.定义并发控制器
type ConcurrentCtrl struct {
lock *sync.Mutex //操作本示例同步锁
maxNum int //最大同时执行任务数
currentNum int //当前执行任务数
jobNum int //任务等待队列长度
jobQueueStart *jobNode //队列头
jobQueueEnd *jobNode //队列尾
addJob chan *jobNode //添加任务channel通知
finishJob chan bool //完成任务channel通知
}
// 2.使用的时候,对控制器初始化并创建启用一个master的goroutine
func NewConcurrentCtrl(maxNum int) *ConcurrentCtrl {
pool := &ConcurrentCtrl{
maxNum: maxNum,
addJob: make(chan *jobNode),
finishJob: make(chan bool),
lock: new(sync.Mutex),
}
go pool.startMaster() //管理控制器的独立goroutine
return pool
}
// 3.管理器逻辑
func (p *ConcurrentCtrl) startMaster() {
for {
select {
case newJob := <-p.addJob:
// 收到一个新任务, 先检查是否可以创建新goroutine
if p.addCurrentNum() {
go p.runJob(newJob)
} else {
//不能创建goroutine,排队
p.pushNode(newJob)
}
case <-p.finishJob:
//一个任务结束, 检查队列中是否有任务; 有, 创建goroutine执行; 没有, 减currentNum
if node := p.popNode(); node != nil {
go p.runJob(node)
} else {
p.subCurrentNum()
}
}
}
}
管理器通过监听addJob和finishJob两个channel, 控制正在执行的任务数。当控制器goroutine监听到添加任务的消息时,先检查正在执行的任务数,正在执行任务数小于最大任务数时,正在执行任务数+1,并创建子goroutine处理任务逻辑。当子goroutine执行完任务逻辑后,发送finishJob通知控制器。控制器监听到完成任务的消息时,检查是否有正在排队的任务,如果有,直接执行,否则执行任务数-1。如下图所示,红色部分为master逻辑。
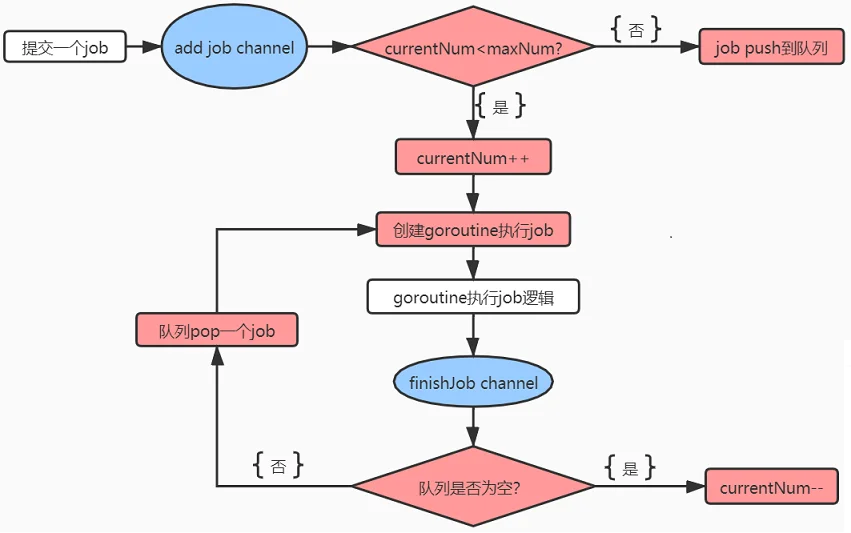
上面的基础模型,除了可以管理并发任务外,还可以作为长连接管理,例如mysql长连接池(当然具体逻辑要复杂许多)。有兴趣的读者也可以尝试阅读这些源码深度体验channel的应用。