
BNF 是一种 上下文无关文法,举个例子就是,人类的语言就是一种 上下文有关文法,我随时都可以讲一句 “以上说的都是废话”,戏弄一下读者阅读本文所花的时间(每当回忆起来,我都会坐在轮椅上大呼过瘾)。
关于 BNF 具体定义,这里摘抄一下维基百科,后面做详细解说:
BNF规定是推导规则(产生式)的集合,写为:
<符号> ::= <使用符号的表达式>
这里的 <符号> 是非终结符,而表达式由一个符号序列,或用指示选择的竖杠 &apos|&apos 分隔的多个符号序列构成,每个符号序列整体都是左端的符号的一种可能的替代。从未在左端出现的符号叫做终结符。
BNF规定是推导规则(产生式)的集合,写为:
<符号> ::= <使用符号的表达式>
这里的 <符号> 是非终结符,而表达式由一个符号序列,或用指示选择的竖杠 &apos|&apos 分隔的多个符号序列构成,每个符号序列整体都是左端的符号的一种可能的替代。从未在左端出现的符号叫做终结符。
暂且不用理解里面提到的 “终结符” 和 “非终结符”,在明白来龙去脉之前去查这些,说不定大脑会 stackoverflow。但是也别慌,所有术语和英文缩写都是纸老虎,其实他们都是很简单的概念,但是你需要一个合适的场景来理解它们起到的作用。
2.2 学科交叉:自然语言理解
上节我们说到,计算机语言多数是符合 BNF 的上下文无关语言,从表达能力上分为 DSL 和 GPL 两类;而人类语言属于上下文有关语言,其实正是由于这一点,才给在 NLP(自然语言理解)领域带来了不少困难。
好,知道了这些英文缩写,再去读那些专业文章会简单得多。
这些其实都是在 静态层面上对语言的描述,为了实际执行这些语言,就需要对其进行解析,还原出语言本身所描述的信息结构。这件事,在计算机领域的课程叫《编译原理》,在智能科学与技术的课程叫《自然语言理解》。
- 编译原理(一张图):
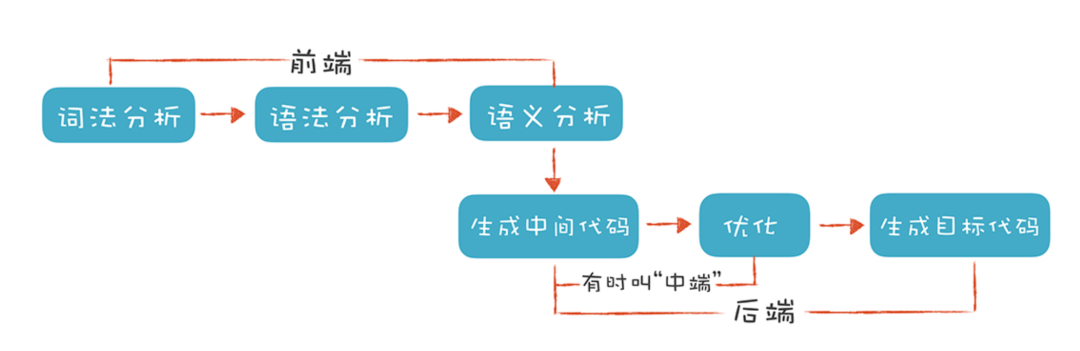
编译原理
- 自然语言理解(两张图):
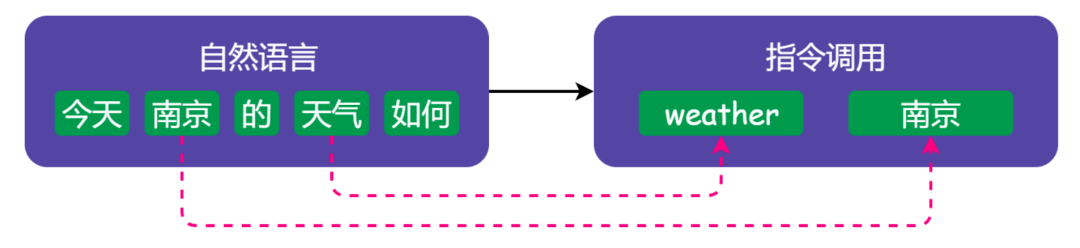
NLP
不难看出,两者的流程惊人的相似:
- 都需要先进行 tokenize 处理,编译器做的是词法分析(常用工具搜 lexer),NLP 做的是 分词(最常见的是 jieba 分词)
- 词法分析的产物是有含义的 token,下面都需要进行语法分析(即 parser),NLP 里通常会做 向量化(最常见的是 word2vec 方法)
- 这两步完成后,编译器前端得到的产物是 AST(Abstract Syntax Tree,抽象语法树),NLP 得到的产物是一段话的向量化表示
两者的共同点止步于此,鉴于 NLP 技术仍在高速发展(而编译原理早就是老生常谈了),向量化得到的产物难以处理同义词,所以后面的步骤也局限于分析一句话的意图、和提取有效信息(利用这些可以做一个简陋版的 Siri)。最新(其实是两年前了)的进展是 BERT 模型和衍生出来的许多研究上下文关系的方法,现在的 NLP 技术已经可以做阅读理解问题了。
此外,DSL 和 GPL 的共同点也止步于此。要记得,DSL 是面向特定用途的语言,以 JSON 为例,得到 AST 就已经有完整的信息结构了,在面向对象语言里无非再多一步:利用反射将其映射到一个 class 的所有字段里;以 HTML 为例,得到 AST 就已经有完整的 DOM 树了,浏览器已经具备渲染出整个网页所需的大部分信息。
最后,对 GPL 语言来说,编译型语言目的是生成机器可执行的代码,解释型语言的目的是生成虚拟机认识的中间代码。这部分职责由编译器后端承担,现代编译器领域的最佳拍档就是 Clang + LLVM。
2.3 别慌:英文缩写都是纸老虎
现在我们知道了事情的来龙去脉,也就明白了开头的需求属于哪种问题。对工程师来说,解决问题的第一步就是先知道你面对的是什么问题:使用编译原理的知识来解析开头的表达式,相当于定义一个简陋的 DSL 语言,并编写词法解析器和语法解析器(lexer & parser)来将其转换成 AST(抽象语法树),进而对其进行处理。
在进行工程实践之前,还有些术语不得不先行了解。
首先是前面提到的终结符和非终结符,重复一下上面解释 BNF 时举的抽象表达式:<符号> ::= <使用符号的表达式> 。可以这样来理解:
- 由词法解析器生成的符号,也叫 token,是终结符。终结符是最小表义单位,无法继续进行拆解和解析
- 规则左侧定义的符号,是非终结符。非终结符需要进行语法解析,最终由终结符构成其表示形式
其次是 NFA 和 DFA,FA 表示 Finite Automata(有穷状态机),即根据不同的输入来转换内部状态,其内部状态是有限个数的。而 NFA 和 DFA 分别代表 有穷不确定状态机 和 有穷确定状态机。运用子集构造法可以将 NFA 转换为 DFA,让构造得到的 DFA 的每个状态对应于 NFA 的一个状态的集合。
词法分析器(lexer)生成终结符,而语法分析器(parser)则利用自顶向下或自底向上的方法,利用文法中定义的终结符和非终结符,将输入信息转换为 AST(抽象语法树)。也就是我们在此次需求中需要获得的东西。
三、工程实践
我们的案例是使用 golang 来编写 lexer 和 parser。
如果使用 Antlr 的话,可以将 lexer 和 parser 一同搞定,用得好的话,可以实现诸如像 JS 和 Swift 语言互相转换的特技。不在本文实践范围内。
3.1 goyacc 的安装
Golang 1.8 之前自带 goyacc 工具,由于使用量太少,之后版本就需要手动安装了。
go%uA0get%uA0-u%uA0github.com/golang/tools/tree/master/cmd/goyacc
使用起来参数如下:
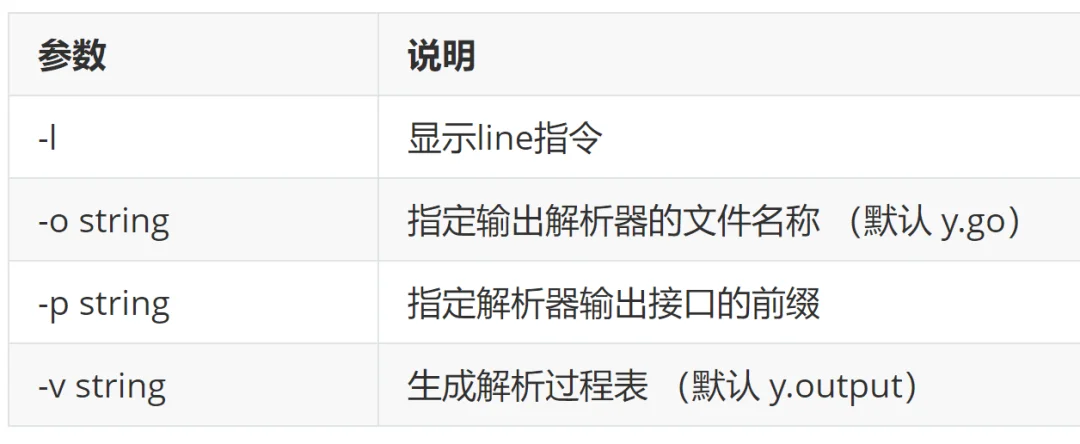
然后我们需要搞定词法分析器和语法分析器。
3.2 使用 goyacc 的思路
yacc 类工具的共同特点就是,通过编写 .y 格式的说明文件定义语法,然后使用 yacc 命令行工具生成对应语言的源代码。
所以尝起来就比较像 protobuf,proto 文件就像 .y 文件一样本身不可执行,需要用一些 protogen 工具来生成对应每种语言的源代码文件。
在 goyacc 中,lexer 本身相对简单,自己编写 go 代码实现就够了,parser 部分所需的文法约定,需要我们编写 .y 文件,也就需要了解 yacc 的文法约定。goyacc 会在生成好的 go 源代码中提供 yyParse 、yyText 、yyLex 等接口,最后我们自己编写调用 parser 的文件,就能把流程跑起来了。
我们的目的,就是给定如下示例输入,然后输出能代表 AST 的数据结构:
#%uA0示例输入avg(teams[*].maxPlayers)%uA0*flatten(rules[red].players.playerAttributes[exp])#%uA0示例输出parsed%uA0obj:%uA0[map[avg:[map[teams:*]%uA0map[maxPlayers:]]]%uA0map[flatten:[map[rules:red]%uA0map[players:]%uA0map[playerAttributes:exp]]%uA0last_operator:*]][%uA0%uA0%uA0%uA0{%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0"avg":%uA0[%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0{%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0"teams":%uA0"*"%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0},%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0{%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0"maxPlayers":%uA0""%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0}%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0]%uA0%uA0%uA0%uA0},%uA0%uA0%uA0%uA0{%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0"flatten":%uA0[%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0{%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0"rules":%uA0"red"%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0},%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0{%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0"players":%uA0""%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0},%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0{%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0"playerAttributes":%uA0"exp"%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0}%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0],%uA0%uA0%uA0%uA0%uA0%uA0%uA0%uA0"last_operator":%uA0"*"%uA0%uA0%uA0%uA0}] 3.3 词法分析器
lexer 我们选择自己用 golang 编写。lexer 的基本功能是通过一个 buffer reader 不断读取文本,然后告诉 goyacc 遇到的是什么符号。
Lex 函数的返回值类型(即词法分析器的实际产物)需要在后面的 yacc 文件的 token 部分定义。
为了与 goyacc 结合,我们需要定义和实现以下接口:
type%uA0Scanner%uA0struct%uA0{%uA0buf%uA0%uA0%uA0*bufio.Readerꃚta%uA0%uA0interface{}%uA0err%uA0%uA0%uA0errorꃞbug%uA0bool}func%uA0NewScanner(r%uA0io.Reader,ꃞbug%uA0bool)%uA0*Scanner%uA0{%uA0return%uA0&Scanner{%uA0%uA0buf:%uA0%uA0%uA0bufio.NewReader(r),%uA0ꃞbug:ꃞbug,%uA0}}func%uA0(sc%uA0*Scanner)%uA0Error(s%uA0string)%uA0{%uA0fmt.Printf("syntax%uA0error:%uA0%s\n",%uA0s)}func%uA0(sc%uA0*Scanner)%uA0Reduced(rule,%uA0state%uA0int,%uA0lval%uA0*yySymType)%uA0bool%uA0{%uA0if%uA0sc.debug%uA0{%uA0%uA0fmt.Printf("rule:%uA0%v%uA0state%uA0%v%uA0lval:%uA0%v\n",%uA0rule,%uA0state,%uA0lval)%uA0}%uA0returnꃺlse}func%uA0(s%uA0*Scanner)%uA0Lex(lval%uA0*yySymType)%uA0int%uA0{%uA0return%uA0s.lex(lval)}
我们可以定义私有函数完成 lex 的实际工作。
3.4 语法分析器
上节我们有说,yacc 文件最终会生成 go 源代码文件,里面包含了 yyParse 、yyText 、yyLex 等接口的具体实现。
而 yacc 只包含定义文法的语法,不含各类编程语言的语法,所以聪明的你肯定能猜到,yacc 文件中免不了会出现类似宏定义的东西,会直接嵌入各类编程语言的代码片段。
有了这个心理预期,我们看一下 yacc 文件的结构:
{%嵌入代码%}文法定义%%文法规则%%嵌入代码%uA0(golang代码,通常忽略此部分直接在写在代码头中)

其文法定义如下:

我们自己编写 yacc 实现 parser,最少需要知道的就是前面四种描述符。一开始我们只实现最简单的语法规则,后面自己就会逐渐了解更高级的文法规则了。
3.5 参考工程
goyacc 的示例工程不多,不推荐用 yacc 实现计算器的例子,参考性比较差。
如下工程实现了用 golang 解析 JSON 数据,只需要补一个 go.mod 和 main 函数就能拿来边调试边参考着实现自己的需求了,十分推荐:https://github.com/sjjian/yacc-examples
module%uA0example.com/mgo%uA01.14require%uA0github.com/pkg/errors%uA0v0.9.1 package%uA0mainimport%uA0(%uA0"encoding/json"%uA0"fmt"%uA0"io/ioutil"%uA0"example.com/m/yacc_parseJson")func%uA0check(e%uA0error)%uA0{%uA0if%uA0e%uA0!=%uA0nil%uA0{%uA0%uA0panic(e)%uA0}}func%uA0main%uA0{ꃚt,%uA0err%uA0:=%uA0ioutil.ReadFile("json.txt")%uA0check(err)%uA0fmt.Printf("raw%uA0str:%uA0%s\n",%uA0string(dat))%uA0jsonobj,%uA0err%uA0:=%uA0yacc_parseJson.ParseJson(string(dat),%uA0true)%uA0fmt.Printf("parsed%uA0obj:%uA0%+v\n",%uA0jsonobj)%uA0jsonStr,%uA0_%uA0:=%uA0json.Marshal(jsonobj)%uA0fmt.Printf(string(jsonStr))}
四、参考文献
- 编译原理(基础篇)
- golang 实现自定义语言的基础
- 什么是 NFA 和 DFA
- 从 antlr 扯淡到一点点编译原理
- How to Write a Parser in Go
收藏