
函数的定义声明没有接收者。
方法的声明和函数类似,他们的区别是:方法在定义的时候,会在func和方法名之间增加一个参数,这个参数就是接收者,这样我们定义的这个方法就和接收者绑定在了一起,称之为这个接收者的方法。
Go语言里有两种类型的接收者:值接收者和指针接收者。
使用值类型接收者定义的方法,在调用的时候,使用的其实是值接收者的一个副本,所以对该值的任何操作,不会影响原来的类型变量。-------相当于形式参数
如果我们使用一个指针作为接收者,那么就会其作用了,因为指针接收者传递的是一个指向原值指针的副本,指针的副本,指向的还是原来类型的值,所以修改时,同时也会影响原来类型变量的值。
函数方法的参数,可以是任意多个,这种我们称之为可以变参数,比如我们常用的fmt.Println()这类函数,可以接收一个可变的参数。
可以变参数,可以是任意多个。我们自己也可以定义可以变参数,可变参数的定义,在类型前加上省略号…即可。
func main() {
print("1","2","3")
}
func print (a ...interface{}){
for _,v:=range a{
fmt.Print(v)
}
fmt.Println()
}
例子中我们自己定义了一个接受可变参数的函数,效果和fmt.Println()一样。
可变参数本质上是一个数组,所以我们向使用数组一样使用它,比如例子中的 for range 循环。
3. Golang导入包时,为什么可能使用’_’/’.'导入? 举例说明包前是下划线_
当导入一个包时,该包下的文件里所有init函数都会被执行,但是有时我们仅仅需要使用init函数而已并不希望把整个包导入(不使用包里的其他函数)
每个包都可以有任意多个init函数,这些init函数都会在main函数之前执行。init函数通常用来做初始化变量、设置包或者其他需要在程序执行前的引导工作。比如上面我们讲的需要使用_空标志符来导入一个包的目的,就是想执行这个包里的init函数。
我们以数据库的驱动为例,Go语言为了统一关于数据库的访问,使用databases/sql抽象了一层数据库的操作,可以满足我们操作MYSQL、Postgre等数据库,这样不管我们使用这些数据库的哪个驱动,编码操作都是一样的,想换驱动的时候,就可以直接换掉,而不用修改具体的代码。
这些数据库驱动的实现,就是具体的,可以由任何人实现的,它的原理就是定义了init函数,在程序运行之前,把实现好的驱动注册到sql包里,这样我们就使用使用它操作数据库了。
package mysql
import (
"database/sql"
)
func init() {
sql.Register("mysql", &MySQLDriver{})
}
因为我们只是想执行这个mysql包的init方法,并不想使用这个包,所以我们在导入这个包的时候,需要使用_重命名包名,避免编译错误。
import "database/sql"
import _ "github.com/go-sql-driver/mysql"
db, err := sql.Open("mysql", "user:password@/dbname")
包前是点.
import(.“fmt”)
这个点操作的含义就是这个包导入之后在你调用这个包的函数时,你可以省略前缀的包名,也就是前面你调用的fmt.Println(“hello world”)可以省略的写成Println(“hello world”)
在 Go 中,与 C 数组变量隐式作为指针使用不同,Go 数组是值类型,赋值和函数传参操作都会复制整个数组数据。假想每次传参都用数组,那么每次数组都要被复制一遍。如果数组大小有 100万,在64位机器上就需要花费大约 800W 字节,即 8MB 内存。这样会消耗掉大量的内存。
于是乎有人想到,函数传参用数组的指针。这样更加高效的利用内存,性能也比之前的好。
不过传指针会有一个弊端,万一原数组的指针指向更改了,那么函数里面的指针指向都会跟着更改。
切片的优势也就表现出来了。用切片传数组参数,既可以达到节约内存的目的,也可以达到合理处理好共享内存的问题。打印结果第二行就是切片,切片的指针和原来数组的指针是不同的。
并非所有时候都适合用切片代替数组,因为切片底层数组可能会在堆上分配内存,而且小数组在栈上拷贝的消耗也未必比 make 消耗大。
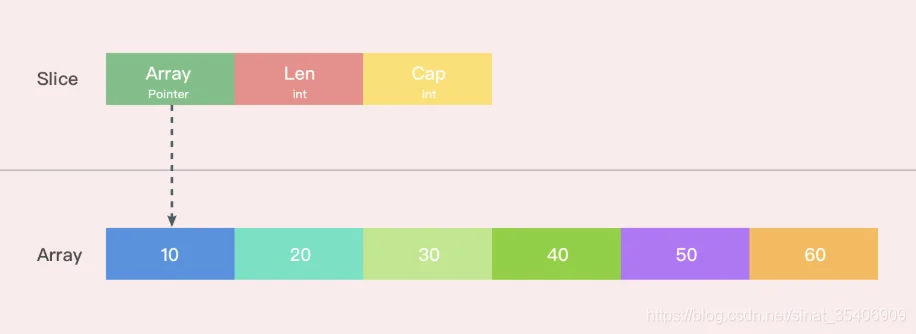
5. Golang Slice的底层实现切片是基于数组实现的,它的底层是数组,它自己本身非常小,可以理解为对底层数组的抽象。因为基于数组实现,所以它的底层的内存是连续分配的,效率非常高,还可以通过索引获得数据,可以迭代以及垃圾回收优化。
切片本身并不是动态数组或者数组指针。它内部实现的数据结构通过指针引用底层数组,设定相关属性将数据读写操作限定在指定的区域内。切片本身是一个只读对象,其工作机制类似数组指针的一种封装。
切片对象非常小,是因为它是只有3个字段的数据结构:
- 指向底层数组的指针
- 切片的长度
- 切片的容量
这3个字段,就是Go语言操作底层数组的元数据。
Go 中切片扩容的策略是这样的:
- 首先判断,如果新申请容量大于2倍的旧容量,最终容量就是新申请的容量
- 否则判断,如果旧切片的长度小于1024,则最终容量就是旧容量的两倍
- 否则判断,如果旧切片长度大于等于1024,则最终容量从旧容量开始循环增加原来的 1/4, 直到最终容量大于等于新申请的容量
- 如果最终容量计算值溢出,则最终容量就是新申请容量
伪代码:
if cap > 2*oldCap {
newCap = cap
} else if cap < 1024 {
newCap = 2*oldCap
} else {
newCap = oldCap
while (newCap < cap && !overflow) {
newcap += newcap/4
}
if overflow {
newCap = cap
}
}
扩容前后的Slice是否相同?
情况一:
原数组还有容量可以扩容(实际容量没有填充完),这种情况下,扩容以后的数组还是指向原来的数组,对一个切片的操作可能影响多个指针指向相同地址的Slice。
情况二:
原来数组的容量已经达到了最大值,再想扩容, Go 默认会先开一片内存区域,把原来的值拷贝过来,然后再执行 append() 操作。这种情况丝毫不影响原数组。
要复制一个Slice,最好使用Copy函数。
7. Golang的参数传递、引用类型Go语言中所有的传参都是值传递(传值),都是一个副本,一个拷贝。因为拷贝的内容有时候是非引用类型(int、string、struct等这些),这样就在函数中就无法修改原内容数据;有的是引用类型(指针、map、slice、chan等这些),这样就可以修改原内容数据。
Golang的引用类型包括 slice、map 和 channel。它们有复杂的内部结构,除了申请内存外,还需要初始化相关属性。内置函数 new 计算类型大小,为其分配零值内存,返回指针。而 make 会被编译器翻译成具体的创建函数,由其分配内存和初始化成员结构,返回对象而非指针。
8. Golang Map底层实现Golang中map的底层实现是一个散列表,因此实现map的过程实际上就是实现散表的过程。在这个散列表中,主要出现的结构体有两个,一个叫hmap(a header for a go map),一个叫bmap(a bucket for a Go map,通常叫其bucket)。hmap如下所示:
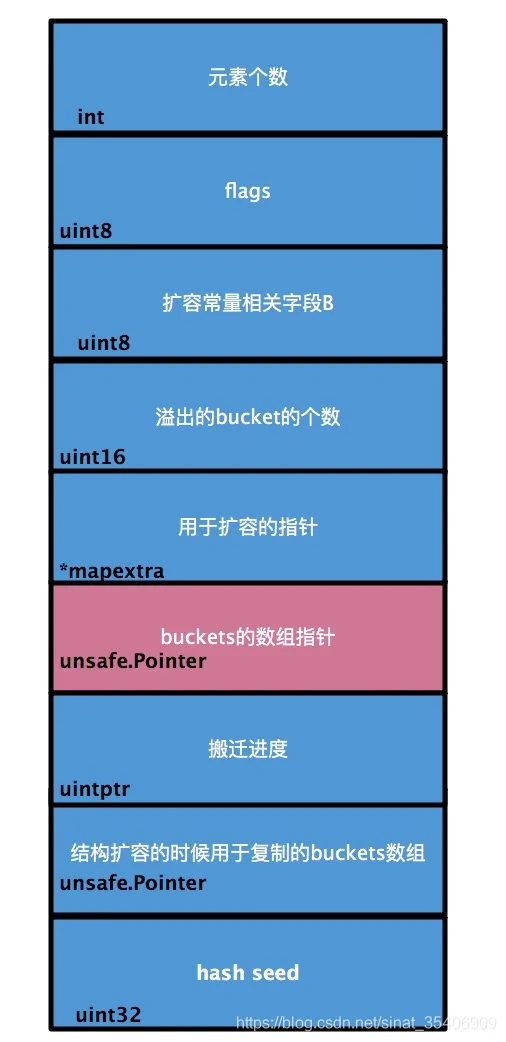
图中有很多字段,但是便于理解map的架构,你只需要关心的只有一个,就是标红的字段:buckets数组。Golang的map中用于存储的结构是bucket数组。而bucket(即bmap)的结构是怎样的呢?
bucket:
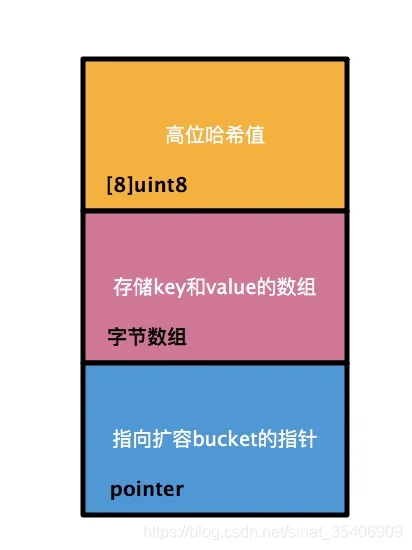
相比于hmap,bucket的结构显得简单一些,标红的字段依然是“核心”,我们使用的map中的key和value就存储在这里。“高位哈希值”数组记录的是当前bucket中key相关的“索引”,稍后会详细叙述。还有一个字段是一个指向扩容后的bucket的指针,使得bucket会形成一个链表结构。
整体的结构应该是这样的:
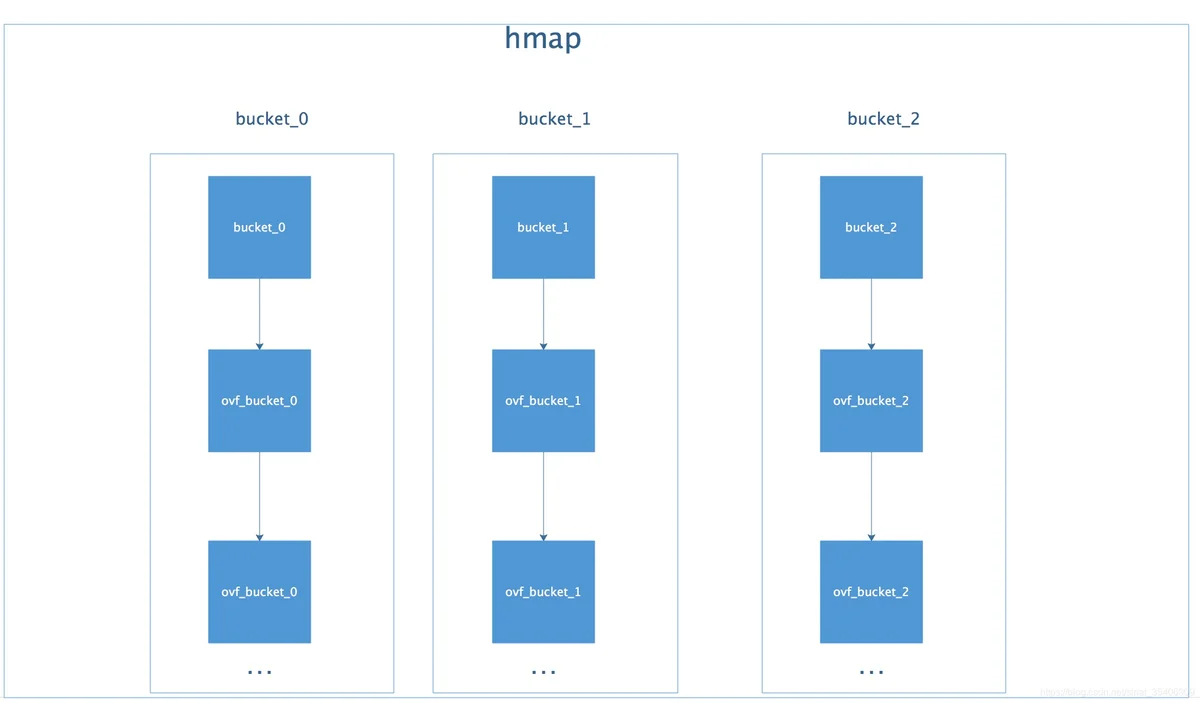
Golang把求得的哈希值按照用途一分为二:高位和低位。低位用于寻找当前key属于hmap中的哪个bucket,而高位用于寻找bucket中的哪个key。
需要特别指出的一点是:map中的key/value值都是存到同一个数组中的。这样做的好处是:在key和value的长度不同的时候,可以消除padding带来的空间浪费。

Map的扩容:
当Go的map长度增长到大于加载因子所需的map长度时,Go语言就会将产生一个新的bucket数组,然后把旧的bucket数组移到一个属性字段oldbucket中。
注意:并不是立刻把旧的数组中的元素转义到新的bucket当中,而是,只有当访问到具体的某个bucket的时候,会把bucket中的数据转移到新的bucket中。
实体类型以值接收者实现接口的时候,不管是实体类型的值,还是实体类型值的指针,都实现了该接口。
实体类型以指针接收者实现接口的时候,只有指向这个类型的指针才被认为实现了该接口
| Methods Receivers | Values |
|---|---|
| (t T) | T and *T |
| (t *T) | *T |
向 defer 关键字传入的函数会在函数返回之前运行。假设我们在 for 循环中多次调用 defer 关键字,会倒序执行所有向 defer 关键字中传入的表达式。
defer 传入的函数不是在退出代码块的作用域时执行的,它只会在当前函数和方法返回之前被调用。
预计算参数
Go 语言中所有的函数调用都是传值的,defer 虽然是关键字,但是也继承了这个特性。假设我们想要计算 main 函数运行的时间,可能会写出以下的代码:
func main() {
startedAt := time.Now()
defer fmt.Println(time.Since(startedAt))
time.Sleep(time.Second)
}
$ go run main.go
0s
然而上述代码的运行结果并不符合我们的预期,这个现象背后的原因是什么呢?经过分析,我们会发现调用 defer 关键字会立刻对函数中引用的外部参数进行拷贝,所以 time.Since(startedAt) 的结果不是在 main 函数退出之前计算的,而是在 defer 关键字调用时计算的,最终导致上述代码输出 0s。
想要解决这个问题的方法非常简单,我们只需要向 defer 关键字传入匿名函数.
底层实现
runtime._defer 结构体是延迟调用链表上的一个元素,所有的结构体都会通过 link 字段串联成链表。

defer 关键字的实现主要依靠编译器和运行时的协作:
- 编译期;
将 defer 关键字被转换 runtime.deferproc;
在调用 defer 关键字的函数返回之前插入 runtime.deferreturn; - 运行时:
runtime.deferproc 会将一个新的 runtime._defer 结构体追加到当前 Goroutine 的链表头;
runtime.deferreturn 会从 Goroutine 的链表中取出 runtime._defer 结构并依次执行;
我们在前面提到的两个现象在这里也可以解释清楚了:
- 后调用的 defer 函数会先执行:
后调用的 defer 函数会被追加到 Goroutine _defer 链表的最前面;
运行 runtime._defer 时是从前到后依次执行; - 函数的参数会被预先计算;
调用 runtime.deferproc 函数创建新的延迟调用时就会立刻拷贝函数的参数,函数的参数不会等到真正执行时计算;
sync.Once 是 Golang package 中使方法只执行一次的对象实现,作用与 init 函数类似。但也有所不同。
init 函数是在文件包首次被加载的时候执行,且只执行一次
sync.Onc 是在代码运行中需要的时候执行,且只执行一次
当一个函数不希望程序在一开始的时候就被执行的时候,我们可以使用 sync.Once 。
package main
import (
"fmt"
"sync"
)
func main() {
var once sync.Once
onceBody := func() {
fmt.Println("Only once")
}
done := make(chan bool)
for i := 0; i < 10; i++ {
go func() {
once.Do(onceBody)
done <- true
}()
}
for i := 0; i < 10; i++ {
<-done
}
}
# Output:
Only once