
goroutine是非常轻量的,不会暂用太多资源,基本上有多少任务,我们可以开多少goroutine去处理。但有时候,我们还是想控制一下。
比如,我们有A、B两类工作,不想把太多资源花费在B类务上,而是花在A类任务上。对于A,我们可以来1个开一个goroutine去处理,对于B,我们可以使用一个协程池,协程池里有5个线程去处理B类任务,这样B消耗的资源就不会太多。
控制使用资源并不是协程池目的,使用协程池是为了更好并发、程序鲁棒性、容错性等。废话少说,快速入门协程池才是这篇文章的目的。
协程池指的是预先分配固定数量的goroutine处理相同的任务,和线程池是类似的,不同点是协程池中处理任务的是协程,线程池中处理任务的是线程。
最简单的协程池模型
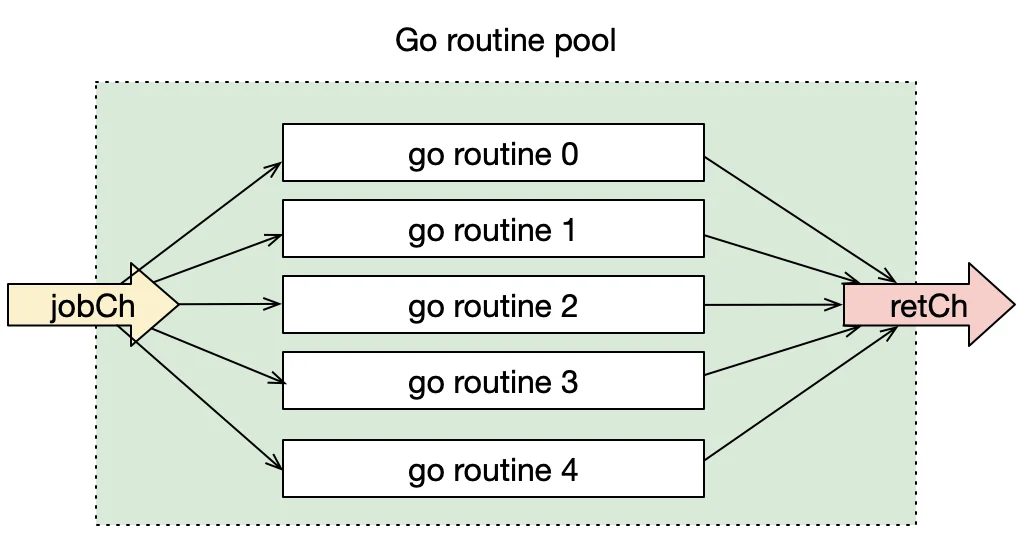
jobChretChjobChretCh示例
模型看懂了,看个小例子吧。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
func workerPool(n int, jobCh <-chan int, retCh chan<- string) {
for i := 0; i < n; i++ {
go worker(i, jobCh, retCh)
}
}
func worker(id int, jobCh <-chan int, retCh chan<- string) {
cnt := 0
for job := range jobCh {
cnt++
ret := fmt.Sprintf("worker %d processed job: %d, it's the %dth processed by me.", id, job, cnt)
retCh <- ret
}
}
workerPool()njobChretChworker()for-rangejobChjobChretCh1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func main() {
jobCh := genJob(10000)
retCh := make(chan string, 10000)
workerPool(5, jobCh, retCh)
time.Sleep(time.Second)
close(retCh)
for ret := range retCh {
fmt.Println(ret)
}
}
func genJob(n int) <-chan int {
jobCh := make(chan int, 200)
go func() {
for i := 0; i < n; i++ {
jobCh <- i
}
close(jobCh)
}()
return jobCh
}
main()genJobjobChretChworkerPoolretChretChgenJobjobChworker 21
2
3
4
5
6
7
8
9
10
11
➜ go run simple_goroutine_pool.go
worker 2 processed job: 4
worker 2 processed job: 5
worker 2 processed job: 6
worker 2 processed job: 7
worker 2 processed job: 8
worker 2 processed job: 9
worker 0 processed job: 1
worker 3 processed job: 2
worker 4 processed job: 3
worker 1 processed job: 0
回顾
最简单的协程池模型就这么简单,再回头看下协程池及周边由哪些组成:
jobChretCh协程池最简要(核心)的逻辑是所有协程从任务读取任务,处理后把结果存放到结果队列。
示例源码
Go并发系列文章
