
文章转载自个人博客Bilibili 百度 社招烤面筋。写这篇主要是想复盘一下我从8月份以来的两次面试经历,一个是B站的后端开发岗,另一个是百度的搜索研发。文章涵盖了MySQL、Golang、 计算机网络、 Elasticsearch、 分布式、搜索的一些知识,码字不易,转载需注明来源。
写在前面
复习准备的跨度大概是1个月,面试前前后后花了1个月时间,总共投了两家,一个是B站,一个是百度,都过了简历关拿到了面试机会。B站一共是3面,两轮技术,一轮HR面,百度一共是4面,三轮技术面,一轮HRBP面。
投B站主要是因为B站文化氛围很好,很适合年轻人,而且小破站最近增长的势头非常猛啊,在B站工作应该很酷 嘿嘿,另外今年年初的Bilibili跨年晚会和五四青年节的“后浪”实在是让我路转粉,B站的破圈做的很成功啊,噢另外,入职即送永久大会员还有办公室里可以养猫并专门有人帮忙投食喂水还蛮吸引人的哈哈哈 ;投百度是因为我之前一直做的是搜索,想继续在这个领域深入,而百度的中文搜索世界第一毋庸置疑,而且技术氛围是非常好的,互联网业界的黄埔军校已经成为共识,在百度能接触到搜索领域最前沿的技术。
最后都通过了面试,拿到了Offer,Package给的都挺让人满意的(小破站竟然不用爱❤️发电了,竟然比百度还高一丢丢),最后在个人发展、兴趣爱好、技术分为当中权衡了一下还是选择了百度。三个原因:
1. 搜索的技术门槛更高,天花板也更高。
2. 百度作为国内搜索龙头,技术实力No1 毋庸置疑。只听过B站到处从百度挖人,没听过百度从B站挖人,从职业发展上来说,百度的含金量更高。工程师文化浓厚;b站主要是靠二次元文化起家的嘛,所以技术并不占主导
3. 研究了一年搜索以后,我对搜索引擎的兴趣还是挺大的。相比之下纯业务开发更容易遇到bottleneck和职业倦怠。
4. 百度面试比B站正规,而且难度更大,B站算法考察的不多,我喜欢跟算法底子好的人一起共事。
5. 最后,从Location上来说,百度处于张江那儿,比较人少偏僻,更适合静下心来写代码、研究东西。
所以综合考虑下来选择了百度,部门是搜索技术平台研发部。
Bilibili 面经
之前没有看到B站有搜索开发工程师的招聘需求,所以就投了一个普通的Golang高级后端工程师的岗位,所以面试内容也都集中在后端开发这里。
8月13日一面
难度:★★★☆☆ 面试官挺亲切的,在百度呆过五年来到的B站,整体面试题目很常规,正常准备都能答得出来。面试用的牛客网在线视频面试。
你之前是负责搜索的,那我想听一下你们搜索系统的大致流程
说实在还挺惊讶面试官会问这个的,因为对方是一个后端工程师,所以就没讲多细致,答的很general,大体来说就是, query分析 -> 粗排召回 -> 精排算特征 -> learning to rank 计算score -> 返回结果,每个再展开来说一些即可。面试官问这个相当于在问项目,确定简历的真实性,所以这个没啥参考性。
MySQL 的事务隔离级别有哪些?
总共是四大隔离级别,理解以后用自己的话答就好了
1. 读未提交(Read Uncommitted), 事务A修改了数据后还没有进行提交,此时事务B去读这个数据,却已经能读出了修改后的数据。也就是会产生“脏读”现象。
2. 读已提交(Read Committed), 事务B去读事务A中的数据D, 然后事务A修改了数据D,记作D', 并提交,此时事务B再去读事务A中的数据D,已经变成了D', 这解决了之前的脏读问题,但对于事务B来说,前后两次读到的数据不同,从而产生”不可重复读“问题,Oracle默认隔离级别就是这个
3. 可重复读(Repeatable Read), 还是拿上面那个类比, 事务B去读事务A中的数据D, 然后事务A修改了数据D,记作D', 并提交,此时事务B再去读事务A中的数据D,它仍然是D。也就是说,在同一次事务中,即便数据被其他事务所修改并提交了,但前后两次读到的数据相同,从而避免了“不可重复读”问题。MySQL 默认隔离级别就是这个。
4. 序列化(Serializable), 其实之前的三种隔离级别都没有解决一种问题,也就是“幻读”问题,所谓幻读问题就是, 事务A先查数据,发现只有10条数据,然后准备插入一个ID为11的数据,事务B这时候插入一个ID为11的数据,并且进行了提交,这时候A的这条记录就插不进去了,即便他查表没有发现ID为11的数据,仿佛出现了幻觉一般。序列化就是解决这种问题的,这种隔离级别“读-写”, “写-读”这样的并发操作,以牺牲并发速度,解决了“脏读”问题。
面试官还是比较满意这个答案的,但接下来面试官问:
以上事务隔离是如何实现的?
老实回答,这题我不会,面试官提示MVCC,我还是不会hhh。回去翻了一些资料,在这里补充一下答案。
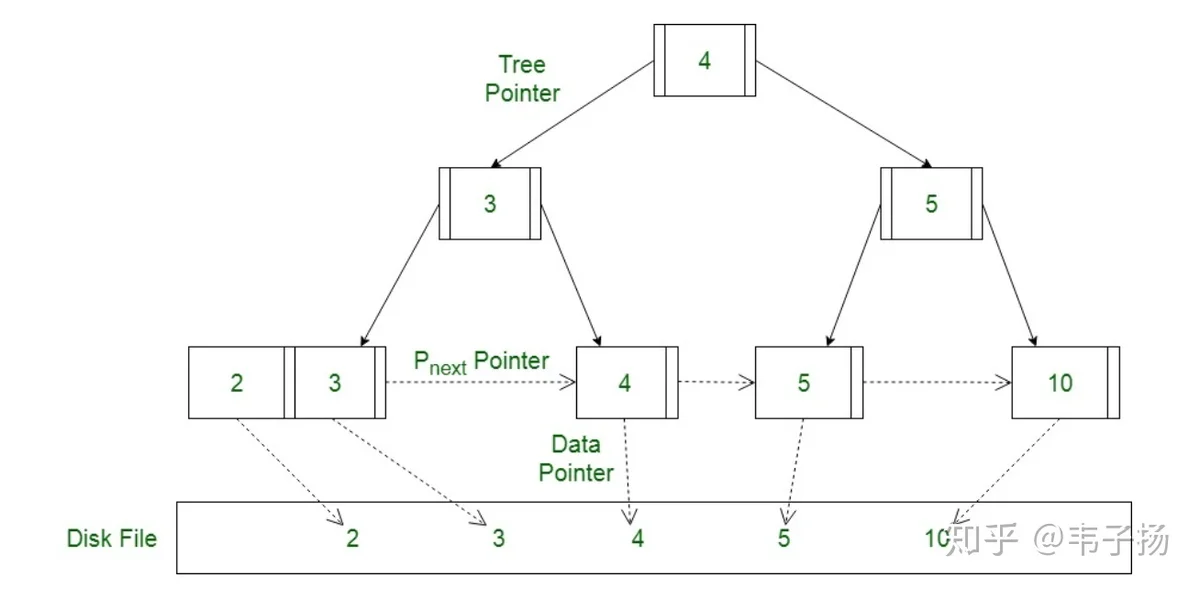
所谓的MVCC 就是MultipleVersion Concurrency Control, 多版本并发控制,从名字上也可以看出来,它是使用版本号来对数据进行并发控制的。实际上,在数据表的每一列,都存储两个隐藏列,一个是trx_id,代表事务的ID,另一个是roll_pointer,指向其上一个版本的记录,如此组成一个记录的版本链,如下图:
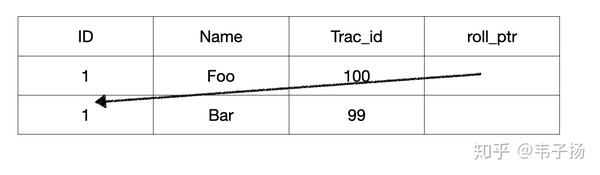
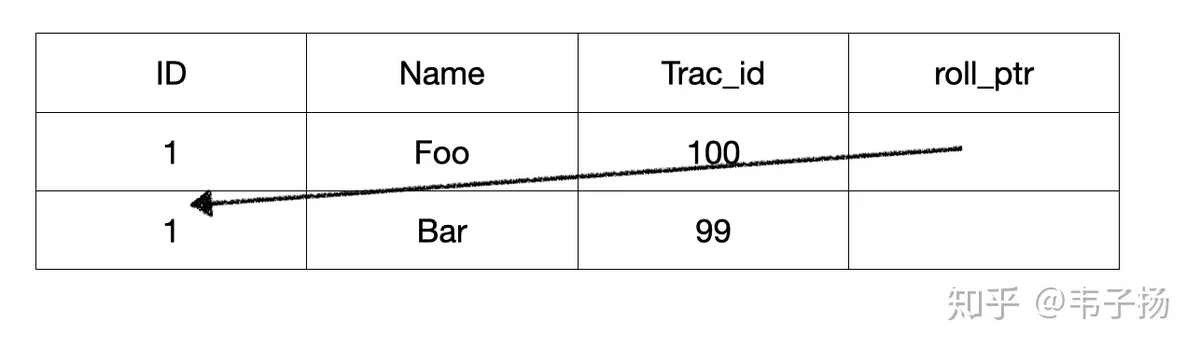
接下来就可以讲ReadView了,它存储着一种用来记录当前活跃状态的读写事务,用于判定该transaction可见到的数据版本。
up_limit_idlow_limit_idtrx_ids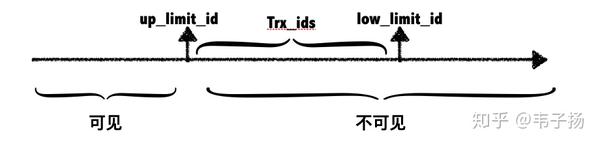
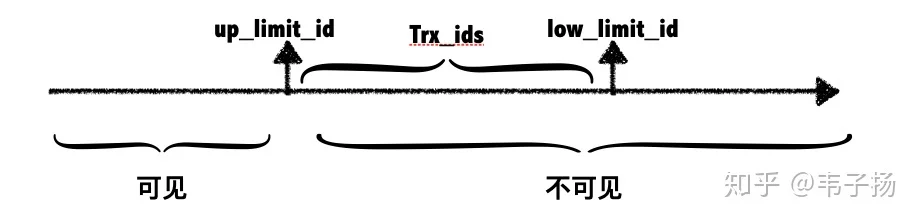
up_limit_idtrx_idup_limit_idup_limit_idMySQL 索引的原理是什么?
O(logN)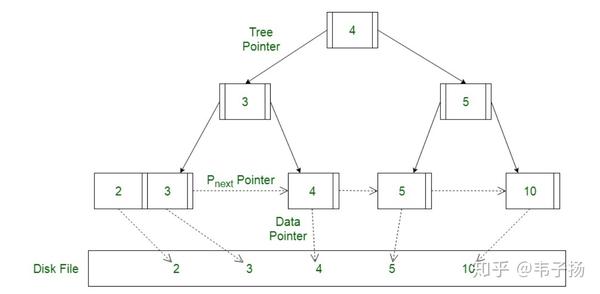
MySQL 建立索引时,应该注意什么?
SELECT * FROM TABLE WHERE A=1 AND B=2 AND C=3MySQL 存储引擎由哪些?他们有什么区别?应用场景是怎样的
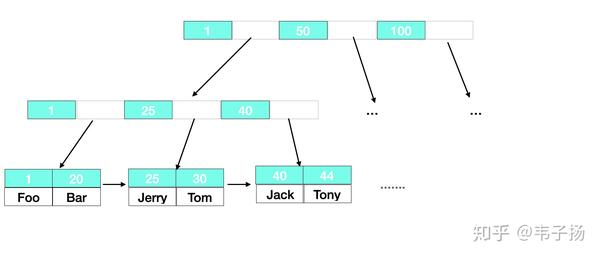
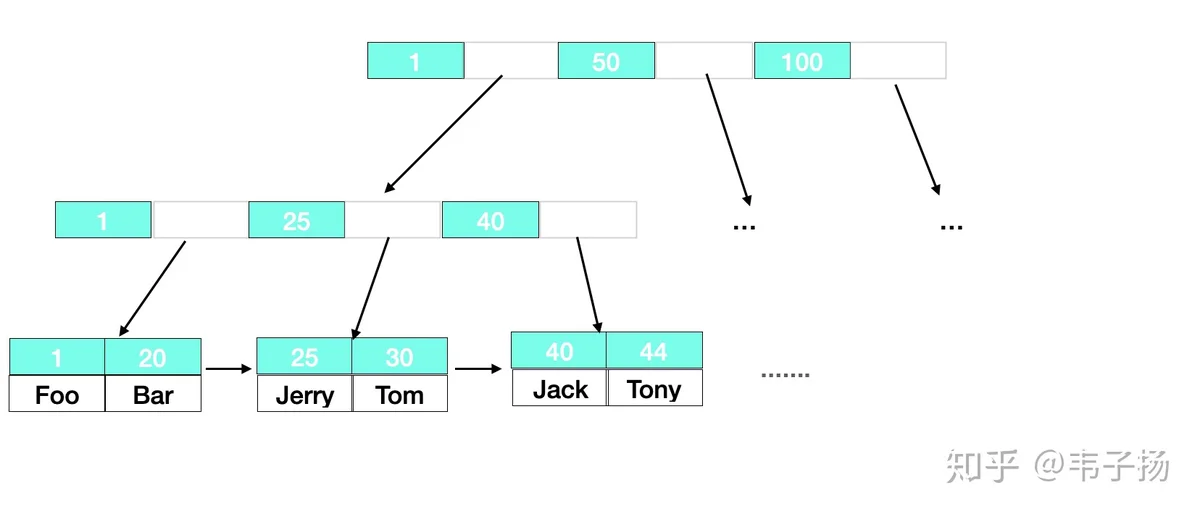
也是一道经典MySQL题了,主要分为Innodb 和 MyISAM,最主要的区别在于InnoDB 采用的簇集索引,MyISAM采用的是非簇集索引。
对于非簇集索引来说,叶子结点存放的值实际上是data域的地址,data 和 索引是完全分离的,如下图:
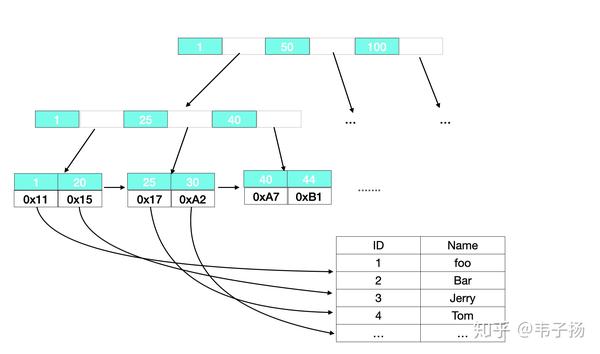
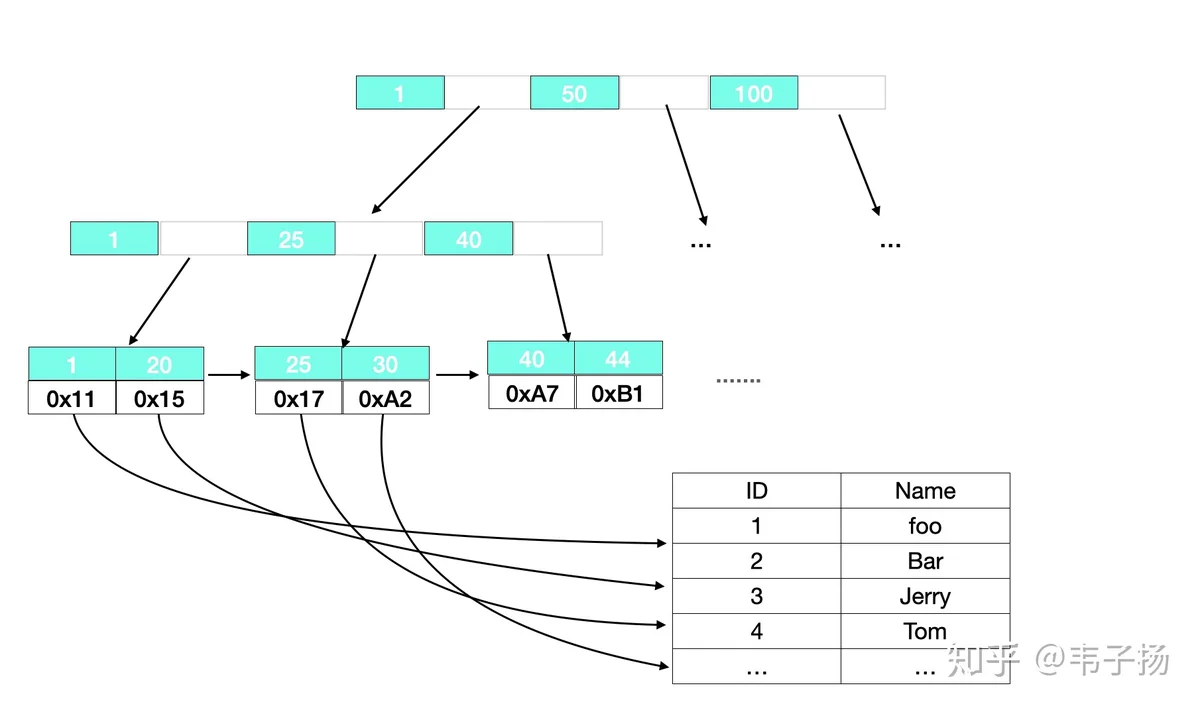
对于簇集索引来说,叶子结点直接存放了data中的所有数据,并按照主键进行排列,这要求其必须有一个主键,而其他索引则是辅助索引,叶子结点存放着主索引的主键。
另外InnoDB支持完整的事务,MyISAM不支持。但是MyISAM在插入、更改、删除操作上代价更小,速度更快,最后MyISAM 支持全文索引,而InnoDB不支持。
综上,适用场景也就显而易见了,InnoDB适合对于有事务要求的程序,,而MyISAM 适用于全文索引、读频繁的场景。
用户从输入URL 到看到浏览器展示结果,经过了哪些过程?越详细越好。
经典万能月经题了,这题目能拿来考所有的前端、移动端、后端。
首先,如果URL是例如.png的静态资源,浏览器会先检查本地是否存在,如果存在,则直接渲染
其次,进行DNS解析,也就是将域名转为IP地址。这部分也是老生常谈的问题了,首先查看本地有无该DNS记录,如果没有去访问本地DNS服务器, 本地DNS服务器如果没有,就去问根DNS服务器,根DNS服务器会告诉你顶级域名服务器的地址,本地DNS服务器去访问顶级域名服务器,顶级域名服务器会告诉本地DNS服务器二级域名服务器的地址...如此往复就可以得到最终DNS记录。
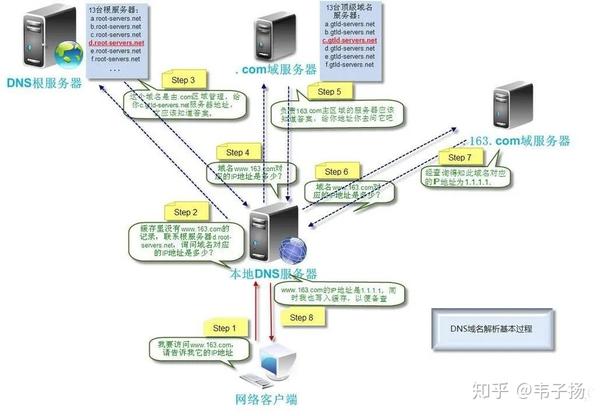
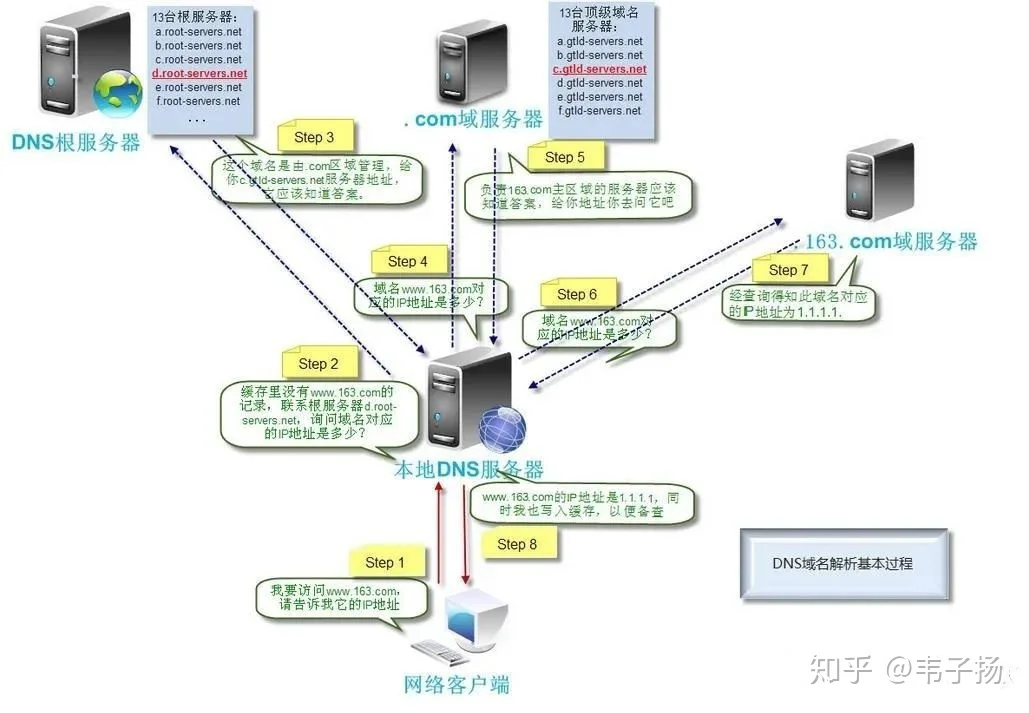
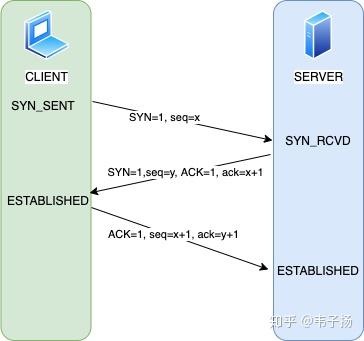
接着进行建立连接,http是基于TCP协议构建的,因此需要进行三次握手,顺着这张图讲就行了:
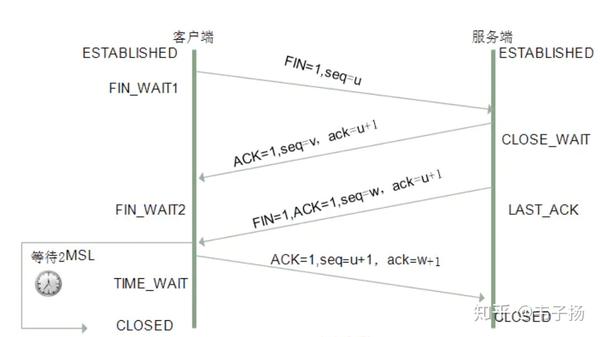
发送完数据以后,服务器进行处理后返回数据,关闭连接,进行四次挥手,四次挥手如下:
浏览器拿到数据以后进行页面的DOM树的渲染。完毕
redis 的数据类型有哪些?在哪些场景使用?
string, set, list, hash dict, zset
- string 就是经常用的key value 键值对;
- hash dict 可以表示一个对象,是一个field 和value 的映射表;
- set 就是集合, 用hash来实现的;
- list 本质上是个双端队列, 可以实现从左边add也可以从右边add
- zset 是有序集合, 用跳表来实现,可以用来实现实时排行榜。
redis 设置过期时间的原理是怎样的?
这个我没有看过,但是我猜了两种策略,给猜对了: 1. 惰性删除,像限流器那样,只有在get的时候去检查它是否expire, 如果过期,就删除。 2. 定时删除。 具体的我没想对,回去看了一下,官方给出的答案是这样的:
也就是说,每秒做10次这样的行为: 从所有设置过期时间的key中, 随机选择20个key,删除所有过期的key, 如果25%的key都过期了,就回到步骤1再做一次。
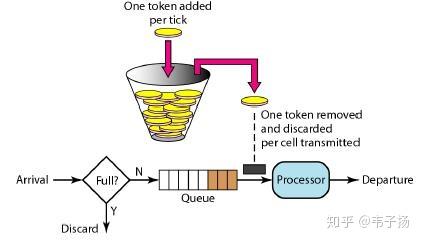
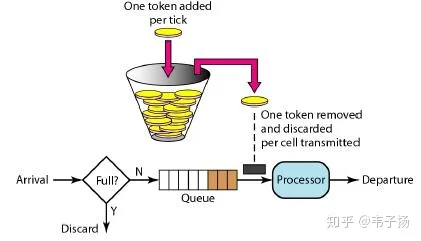
你刚才提到了限流器,如何实现一个限流器?
限流器的原理就是令牌桶,按照一定的时间往桶里加入Token,如果桶已经满了丢弃令牌。每个新请求就消耗一个token, 如果token没了就拒绝服务请求。新请求来临时,会请求从桶中拿走一个Token,如果没有Token可拿了就阻塞或者拒绝服务请求,它的所有计算本质上都是惰性计算。
Goroutine 为什么这么轻?
简单来说,因为它是发生在操作系统的用户态的,不需要进入内核态进行系统调用,操作系统的上下文切换会带来很大的开销,切goroutine和线程一样,共享堆,不共享栈。
Golang的垃圾回收是怎么做的?
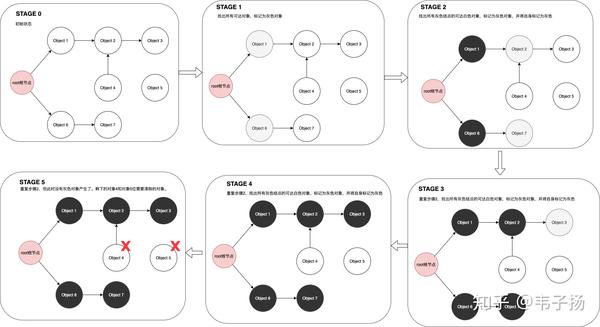
很早之前看过,刚好被问到了就答的比较顺利。三色并发标记,基本思想是把内存中的所有对象分为黑白灰三类,一开始所有对象都是白色对象,然后把所有可达对象标记为灰色,再从所有灰色对象出发,将所有触及到的对象标记为灰色,自身灰色标记为黑色对象,如此循环往复,直到没有灰色对象为止,由于每次标记剩下的都是不可达的白色对象,所以直接将白色对象删除即可。示意图如下:
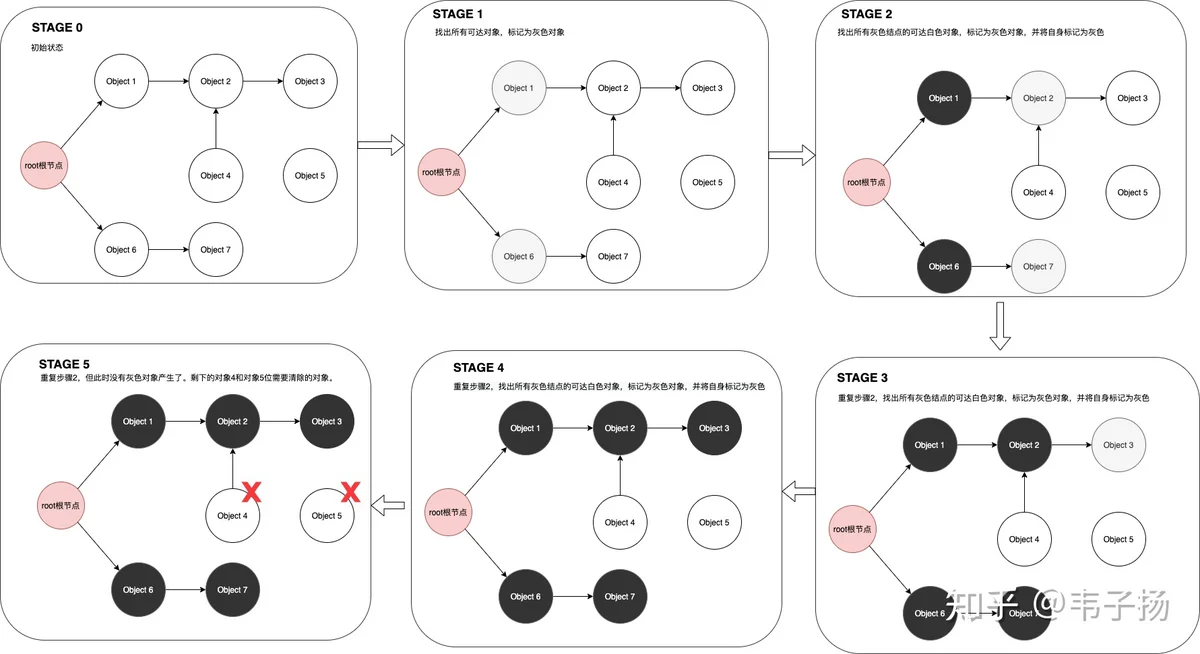
然而这样的做法,会导致较长的STW(stop the world)时间,但如果不STW,很有可能在标记的过程中,对象状态发生变化,从而导致一些不该被回收的对象被回收,我们考虑一下这种情况:
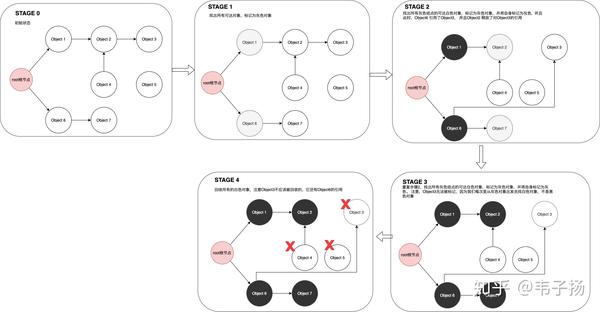
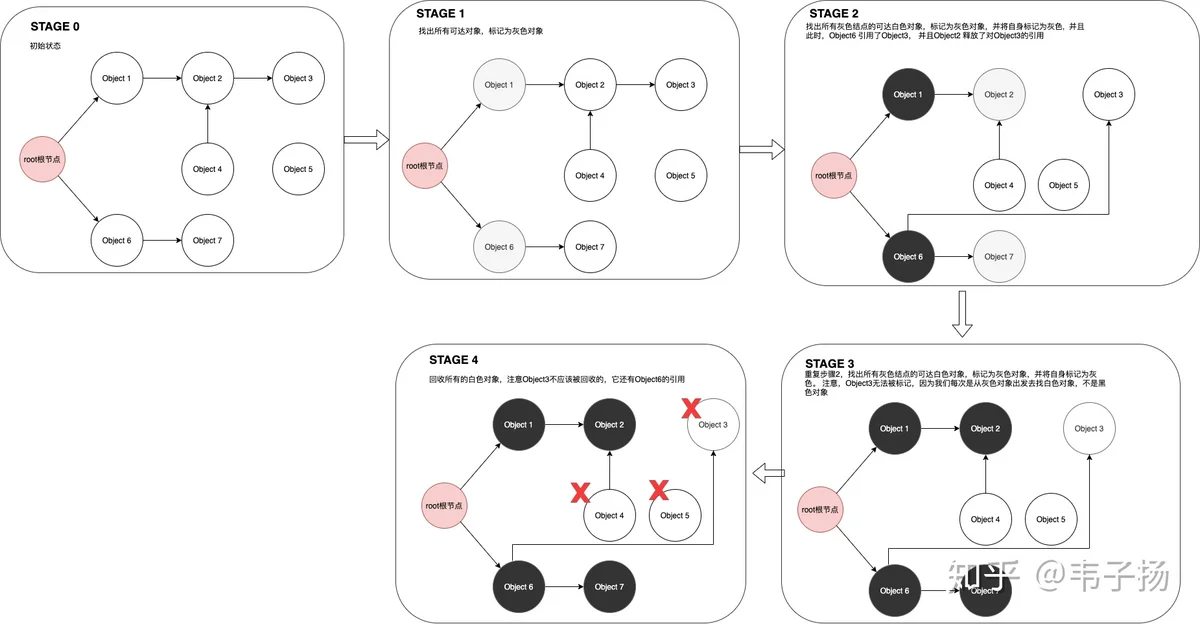
在STAGE2时,我们一边进行回收,对象的状态一边发生了改变,从而导致了对象3被错杀了。
那问题来了,如何在并发的情况下,进行垃圾回收?
从上面的情况来看,发生意外回收需要满足两个条件: 1. 出现了黑色对象引用了白色对象。 2. 出现了灰色对象引用白色对象这种关系被破坏,也就是灰色对象丢失了对白色对象的引用。
针对这两种情况,有两种方式可以规避这种错误: 1. 强三色不变式。 所谓强三色不变式,就是不允许黑色对象引用白色对象。这一点是为了规避情况1。
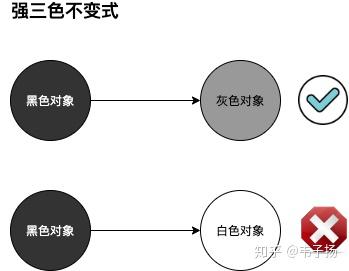
- 弱三色不变式。 所谓弱三色不变式,就是所有被黑色对象引用的白色对象,都需要被一个灰色对象直接或间接地引用。
基于此,我们引申出了写屏障和删除屏障。

噢,不好意思,放错图了。
写屏障: A对象挂载在B对象下时,B对象直接被标记为灰色。这一点是为了满足强三色不变式。
具体而言, 由于我们的内存分为堆内存和栈内存,栈内存存放一些小变量,速度快,所以写屏障不在这里起作用,只在堆内存起作用。堆内存回收完毕后,会进行短暂的STW, 用老方法回收栈内存,示意图如下:
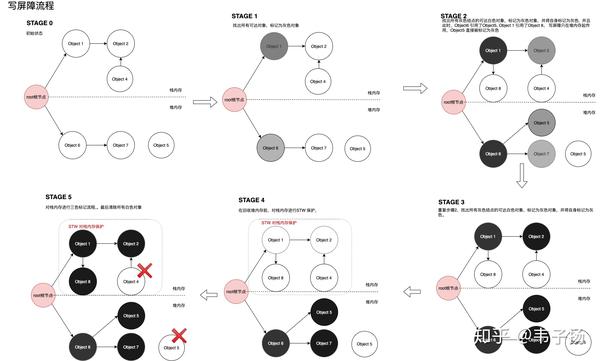
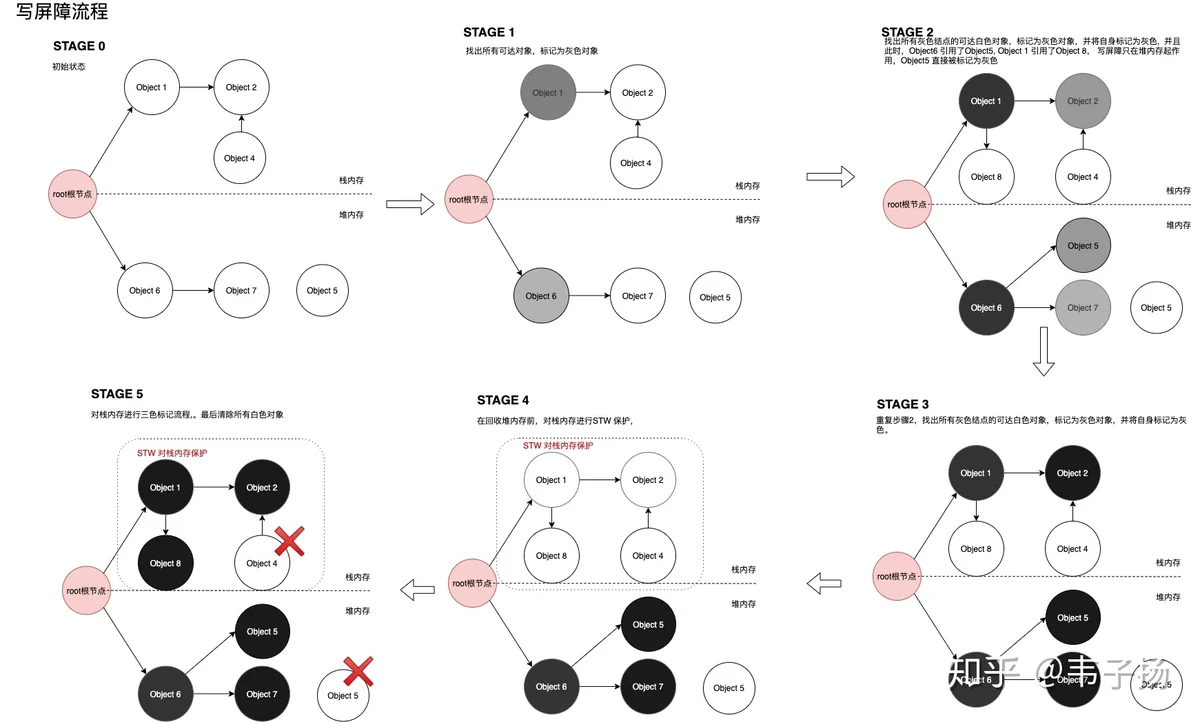
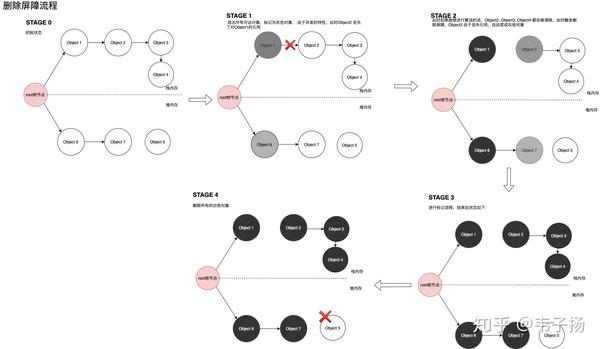
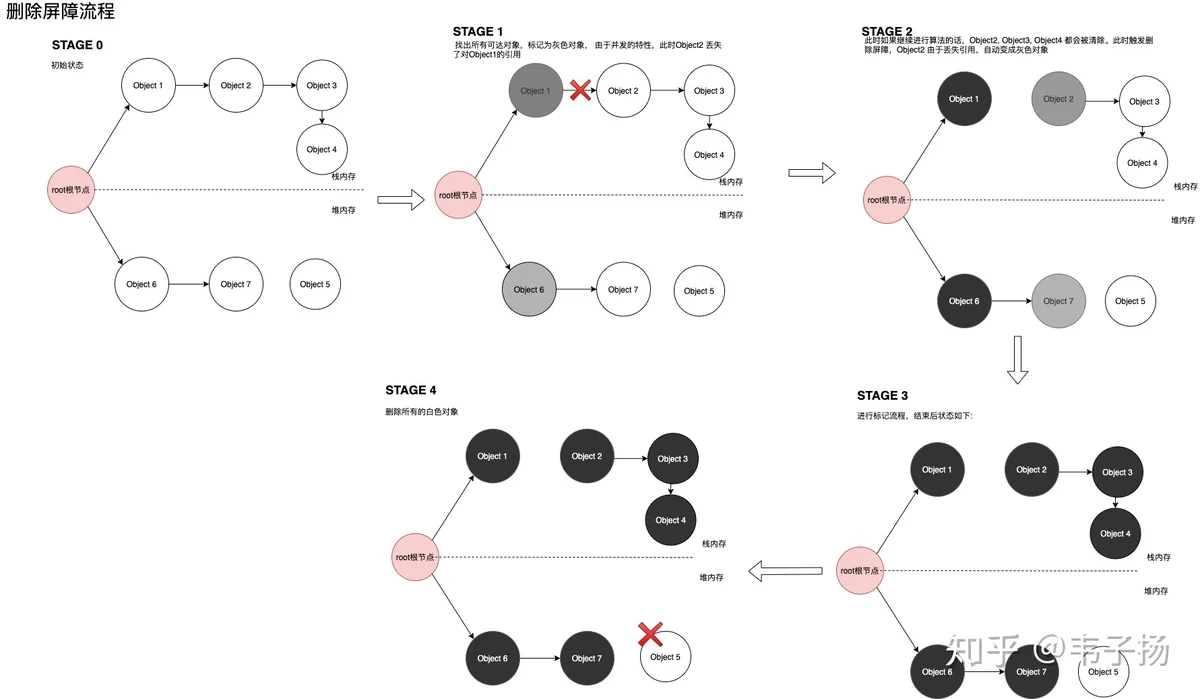
删除屏障: B对象失去A对象的引用时,如果B对象是个白色对象,那么它会变成灰色对象,这一点是为了满足弱三色不变式。
在这里,不用区分对象在堆内存还是在栈内存当中,示意图如下:
以上是Go1.5版本的做法,我说到这儿面试官就没让我继续说下去了,基本满意了这个答案,实际上Go1.8对这个还有进一步的优化,所以在这里继续写一下:
- 写屏障的问题在于,最后对于栈内存仍然需要没有办法避免地要进行STW。
- 删除屏障的问题在于,如果最后一个对象是孤立的白色对象,那么,它丢失引用后,理应被清除,但由于删除屏障的存在,它得以活了下来,需要到下一轮才会被清除。
因此在GoV1.8 版本,使用了混合写屏障机制,具体流程如下: 1. GC开始将栈上的对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需STW), 2. GC期间,任何在栈上创建的新对象,均为黑色。 3. 丢失引用的对象标记为灰色。 4. 新添加的对象标记为灰色。
这个版本几乎不需要进行STW, 栈上的对象始终为黑色对象,满足弱三色不变式。关于Golang GC 的演进有一篇很好的博客,我当初就是看完这篇博客跟面试管吹逼的,这里所有的配图,也都是根据这篇博客重新绘制的:https://studygolang.com/articles/27243
可以谈谈 Golang GMP 模型是怎样的吗?
应该对Go熟悉的人都可以答上来。GMP中G 代表一个Goroutine,它携带上下文运行的信息,是需要运行的任务;M代表Machine,即一个真正的系统线程,是真正的执行者;P代表Processor,是处理器,负责把Goroutine调度到M上, 是最核心的协调者,P的数量默认是由CPU核数来决定的。
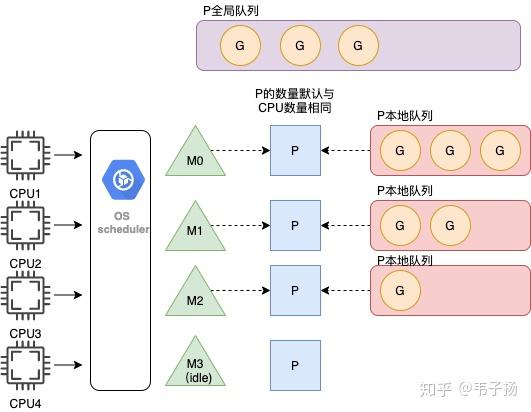
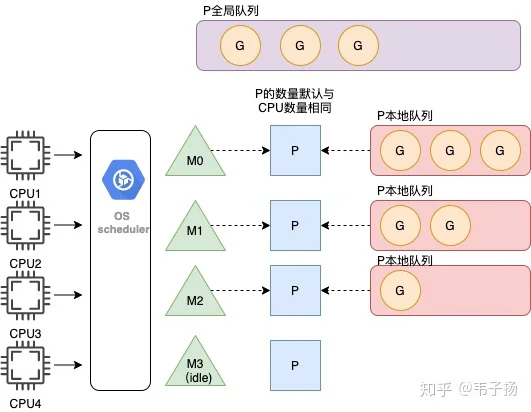
具体来说, 系统线程M想要执行任务的话,就需要获取P,或者说,P使用M 从P本地队列中,获取G来执行,因此P和M是1对1的关系。
新创建的G会被优先放在本地P队列里,如果放不下,就会将本地P队列的一半拿出来放在全局队列里。
另外,如果一个M在执行G的过程中,发生了阻塞,P就会毫不留情地抛弃掉这个M,然后创建一个新M或者复用一个空闲地M,去获取新的G任务执行,当阻塞完毕后,这个被抛弃的M就会优先去尝试获取先前抛弃它的这个P,如果这个P在忙,那M执行的G就会被放到全局队列中,M就会处于闲置状态, 这也就是hand-off 机制。
min(len(GQ)/GOMAXPROCS + 1, len(GQ/2))GMP模型看起来复杂,但其实是比三色并发更简单的东西。有一个博客写的特别清晰,并且插画也比我这个丰富,是我见过最深入浅出的版本:https://learnku.com/articles/41728
Golang map 的底层原理?
Golang的map是hmap(hash map), 一个hmap 结构如下:
buckets 指向一个一个长度为2^B的数组,每个数组指向一个bmap结构,结构如下:
经过hash运算后,取出后B位,计算出命中的桶,再计取出hash运算的前8位,去bucket结构下的topbits中去寻找这8位数的位置,如果找到,就结束了,如果没有找到还要去overflow buckets中去找。这里引用https://mp.weixin.qq.com/s/2CDpE5wfoiNXm1agMAq4wA的一张 图:
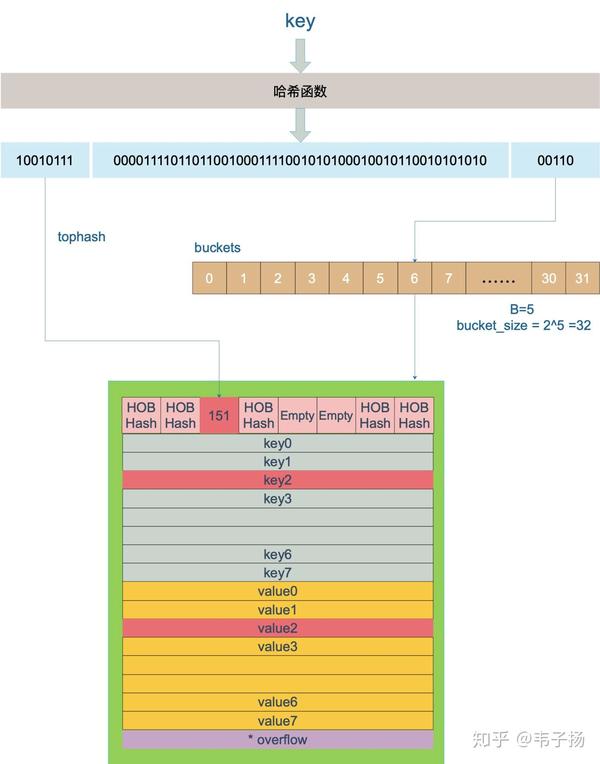

另外,如果元素数量超过了装载因子,就需要进行扩容。
那golang 的map 是线程安全的吗?
不是,如果想要线程安全的话,需要用golang提供的另一种数据结构sync.Map ,或者自己写一个锁,把需要在并发状态下用到map的地方变为临界区就行。
刷一道题吧,求任意一个二叉树的宽度和深度
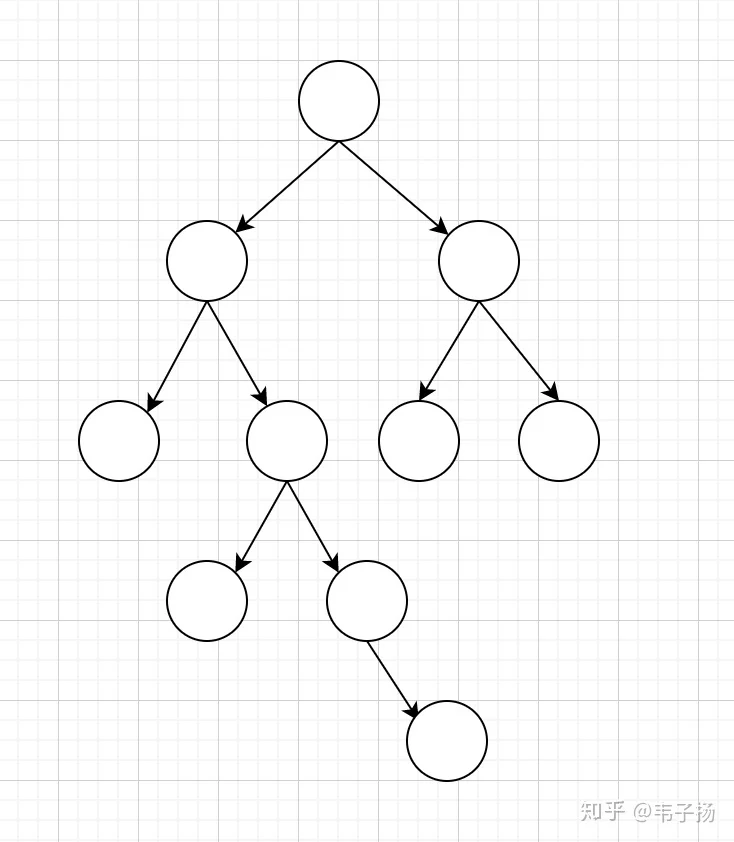
比如上面这个就是一个宽度为4,高度为5的树。 层次遍历就完了,5分钟写完交卷。
8月14日二面
难度:★★☆☆☆ 一面通过后10分钟,就收到了二面的预约电话,第二天进行了二面,二面以电话面形式进行的,侃了了很长时间的个人问题,比如问我是怎么入门计算机的?本科时除了上课之外的学习方式?喜欢看哪些书?读计科双学位的动机?出国读研的动机和收获?毕业后第一份工作是怎么考虑的?(聊了十几分钟差一点以为这是HR面),最后才开始问技术问题,技术问题主要着重于mysql。
以下查询你准备怎么去建索引和优化?
SELECT * FROM table WHERE A = 1 AND B = 2 AND C >3 ORDER BY D LIMIT 10000JOIN查询时,以下两种方法有什么区别?哪一个更快?
SELECT * FROM tableA LEFT JOIN tableBon tableA.id = tableB.idwhere tableA.id = tableB.id讲真这个我还真没仔细研究过,如果有人有找到这个方面的相关资料发我一份,但是我按照直觉回答给回答对了, on更快一些,因为where是在最后数据都查出来的时候去进行的筛选, 而on是在连表的时候进行的过滤,两者操作的数量级别就不一样,而且如果是用where来过滤的话,应该是逐个比较,时间复杂度应该是O(n^2), 用on的话,实际上是两个B+树索引在进行合并,或许可以利用B+树性质直接降低复杂度至O(logn)。 实际上这些都是我猜的,不过好像得到了面试官的认可hhh
有一个查询条件返回的有1000万条数据,那怎么把数据读出来?
可以通过offset 和 limit 的方式来进行分页查,并且利用子查询来提高分页效率
用过消息队列吗?能跟我说说消息队列是怎么用的吗?
用过,以前用Python的celery结合redis处理过异步任务,celery是一个Python分布式消息队列框架, redis充当一个broker的角色。在毕设里面当用户提交一个MRI脑图时,我们会把这个task丢给redis去发布,详细见我博客Predicting brain age from neuroimaging using machine learning 毕设项目梳理
redis为什么快?
- Redis单线程。
- 所有操作在内存中完成
- 采用的数据结构足够简单
k8s中pod和node是什么关系?
node 和 pod是一对多的关系,一个Node可以起多个pod,pod是k8s中的最小部署单元,是一个独立的环境;一个node则通常是一个主机,或者也可以是虚拟主机。
8月17日三面HR面
HR面就没啥了,问了下目前工作负责的项目、挑战点。目前的薪资、绩效考核的情况等等。最后问了下喜欢看B站吗?喜欢看B站的哪些视频?有哪些喜欢的Up主?
反正对着一对猛吹就是了,说B站懂年轻人的喜好啊,B站跨年晚会好看啊,B站的”后浪“宣传片牛逼啊,B站纪录片有教育意义啊,B站买了LOL三年的直播版权啊,B站有希望成为中国的youtube走向世界啊...balabala
百度面经
8月13日一面
难度:★★★★☆
考的比较活,需要面试者真的理解其原理,而不是背书,而且面试官一开始直接说,我看完了你博客里的所有文章,感觉很有意思,而且绘图、排版也很用心。这让我感觉很受重视,所以这面虽然进行了一个半小时,但感觉很愉快。 采用的是视频面试。
你负责你们组的搜索项目,那贵司ES集群是如何搭建的?如何优化的?
这块内容涉密了,不在博客里谈。
什么是ES脑裂?如何防止脑裂?
当ES集群里出现两个master主结点时,整个集群被分为了两个集群,即为脑裂。防止脑裂就是将zen.discovery.minimum_master_nodes 这项设置成 “有资格当选master node的节点数量//2 + 1"
如果你有一个50 个node的ES集群,你该怎么优化?
分为冷集群和热集群,热集群即为较新的数据,也是最经常被访问的,采用较高配置,比如SSD硬盘,大容量内存等;冷集群为老数据,不经常被访问,采用低配置,例如机械硬盘。查询时,在业务逻辑层面上,进行分开查询。(其实这道题目我是经过面试官提醒以后才答出来的)
ES的写入效率怎么提升?
- 自动生成docID
- 合理设计mappings,在不需要进行分词的字段,采用keyword类型
- 降低refresh频率,频繁地refresh会导致频繁段合并,段合并会占用大量系统资源,影响写入速度
- 降低flush频率,flush是将内存写入磁盘的过程,ES默认是每次都flush,实际上,如果能够容忍丢失的话,这个是可以更改的,可以更改为固定频率,或者调高阈值。
- 使用bulk api 进行批量插入
如果bulk 写入超时了应该怎么办?
这个我不会..因为没碰到过,面试官说,可以适当提高线程池最大线程数量
在kibana看到的search rate跟你在外面调用测出来的search rate一样吗?为什么不一样?
不一样,kibana 上的search rate 明显高于实际的search rate,因为kibana观察的是内部单个node的search rate, 只占实际search rate一部分
ES shards 在什么时候处于unassigned状态?如何解决?
当有节点脱离集群时,需要进行reallocate, 此时有一个延迟拷贝机制,这时候就会出现结点unassigned状态,集群状态变黄。
还有一种情况是,使用shrink API时,如果执行完shrink, 不恢复索引至多node状态, 就会出现replica unassigned状态。
解决方案要不然就是直接删除unassigned shard,要不然就是把unassgined shard给分配了
redis-cluster 原理?
忘记是怎么聊到redis-cluster了, 我也完全没怎么用过redis-cluster, 所以就用elasticsearch cluster的原理答了一下还就答对了,一个 redis 集群包含若干个哈希槽,也就相当于若干个shards, 集群中的每个 redis 节点,分配到一部分槽。而集群使用公式 CRC16(key) % 16384 来计算每次请求的键 key 属于哪个槽
Golang defer的原理
deferruntime.deferprocdeferruntime.deferreturnruntime.deferprocruntime._deferruntime.deferreturnruntime._deferdefer 跟Python的什么有点像?
跟Python的上下文管理器with有点像,可以在类里面定义 exit方法来实现defer一样的功能
Python的装饰器怎么用?
如果你想在一个函数执行前或者执行后,固定执行一些逻辑的话,就可以用装饰器,例如,对函数进行计时
在任意需要用到的函数上装饰即可:
装饰器对应了Python语言的什么思想?
万物皆对象..
Goroutine 为什么轻?
bilibili 一面原题,往上翻就行
goroutine和系统线程是一对一的关系吗?
不是,是M对N的关系,系统线程M和P才是一对一的关系
一个goroutine它会一直在一个线程上面跑吗?它会不会切换?
一旦一个goroutine陷入阻塞或者系统调用的时候,P和M就会脱离这个goroutine, 阻塞结束时,接管这个goroutine的可能就是另一个M了
你有10000个url要请求,但是只想同一时刻有10个goroutine同时在跑,如何限制goroutine的数量?
写过goroutine的应该都遇到过这个问题,利用channel控制并发的数量即可,写个demo:
如何等待子goroutine全部执行结束再进行后续逻辑?
两种方法,第一种是信号量的方法, WaitGroup, 另一种是管道的方法,用一个channel来接收结果.
求一个字符串内最长不重复的子串。
剑指offer原题,利用双指针,右指针不断向前进,并把遍历到的字符放入set中,并更新最大值,一旦发现一个存在的字符,就查看左指针对应的字符是否在集合中,如果存在就删除,左指针向右前进。
8月17日二面
难度:★★★★☆ 同样也是视频面,在线编程。总体面试感觉很多不会的,尤其操作系统方面,真是问到了知识盲区。
贵司ES集群状况?
同上,涉密,不在博客里写。
ES查询优化的方法有哪些?
- 指定返回需要的字段,不返回全部字段;
- 定期对只读索引进行段合并;
- 使用SSD替换机械硬盘;
- shards 数量调优(单个shard 控制在20G-50G) ;
- 优化文档模型,避免使用nested 结构,能使用keyword的不使用text;
- 预热cache,将部分文件提前载入内存中
- 禁用swap内存交换
段合并的底层原理是什么?
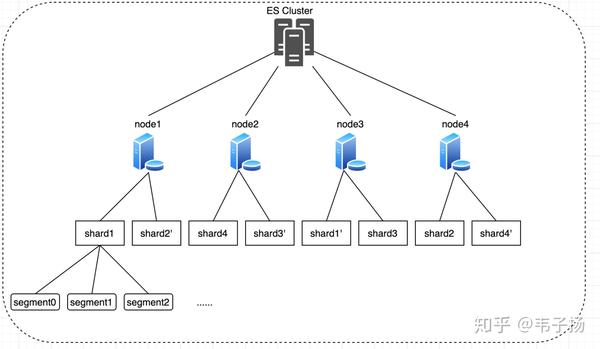
一个index的所有数据在一个集群中是分布在不同的nodes上的,而一个node又是由若干shards来组成的,一个shard就是一个lucene实例,是一个基本的搜索单元,发送给es的查询请求,最终会打到所有的lucene实例中去进行搜索,并进行聚合。而对于一个lucene实例来说,索引文件又是由大量的segments来组成的,每次查询,lucene实例都会打开所有的segments分段来进行搜索,而打开segments又需要维持响应数量的文件句柄、上下文环境等,所以底层的segments的数量会影响到搜索效率。
lucene底层是如何实现查询的?
这部分我答的不是很好,只能回答的很general,具体的实现很复杂,我看完也没完全记住。Generally speaking, 底层本质上是倒排表,倒排表就分为字典文件和正排信息和倒排信息。字典文件包含所有的term, 并包含一个指向倒排信息的地址。 Term index用的底层数据结构式FST,Finite-State-Transducer, 有限状态机,我理解是一个升级版的字典树(不知道理解的对不对),查询时,将其倒排信息取出来做拉链归并,当然,lucene的拉链归并根本没那么简单.. 以后专门写文章讲lucene
看过ES底层data目录下的文件吗?里面都有些什么?
看过,只能记得一个大概,具体的全给忘了Hhh ♂️,只能凭印象来说,data下是若干个文件夹,每个文件夹都是一个index,每个index下又有若干个segments, .dvd, .tip 等等七八种类型的文件。总之这里我答的非常不好,以后专门写文章来填坑(主要我到现在自己都没搞懂,没法跟你们讲哈哈)
ES用的是哪种分布式一致性算法?还有哪些分布式一致性算法?
ES用的PacificA算法, 还有两种常见的分布式算法包括paxos,和raft算法,PacificA算法的实现比较简单。
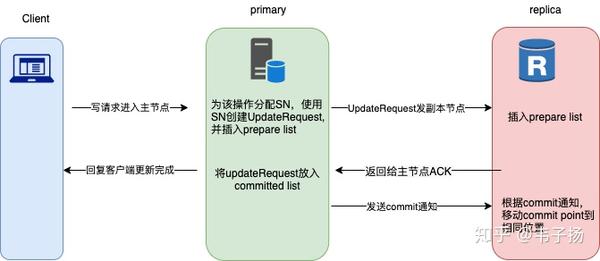
PacificA的数据副本策略是这样的: 1. 写请求进入主节点,主节点为该操作分配一个Serial Number(SN), 代表一个写操作的顺序,这个Serial Number 会递增, 然后使用这个SN创建一个UpdateRequest结构,将UpdateRequest 插入自己的prepareList; 2. 将这个插入请求发给所有的副本结点,副本结点将UpdateRequest 插入它们自身的prepareList, 并回复给主节点一个ACK; 3. 主节点收到所有从副本结点的响应以后,认为所有的副本节点都已经被正确写入,此时将UpdateRequest 插入到自己的commitList里面,commit List向前移动 4. 主节点回复客户端更新已完成,对每个prepare消息,主节点向所有副本节点发送一个commit通知,告诉它们committed point的位置,从副本结点收到后,移动commit point到指定位置。
和Raft不同的是,Raft在第三步时,只需要收到一半以上的确认即可,不需要全部确认,因此pacificA 是强一致性的,适用于单个机房局域网内。
Paxos没自习研究过,据说实现很复杂, 以后填坑
ES内部是如何给文档打分的?
ES底层lucene 用的是BM25F算法来给文档进行评估相关性,以前的Lucene采用的是TF-IDF来进行评估的,BM25F 公式如下:


BM25F相比TF-IDF来说,在计算TF时,可以把控制TF的增长使其随着TF的增加而逐渐逼近于一个k+1,从而控制TF不会无限制地增长, 这就是公式里面的saturatedTF, 两者相比如下图所示:
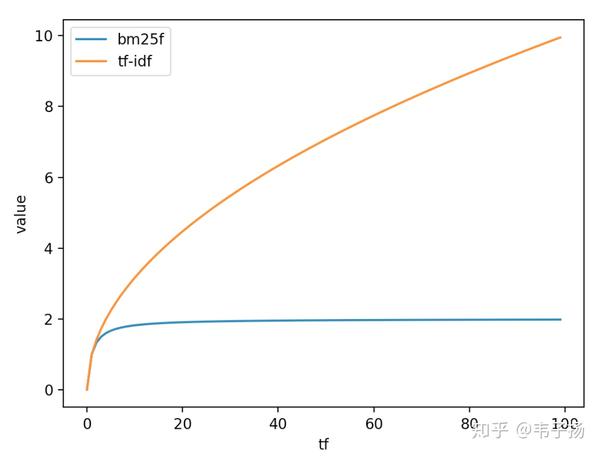
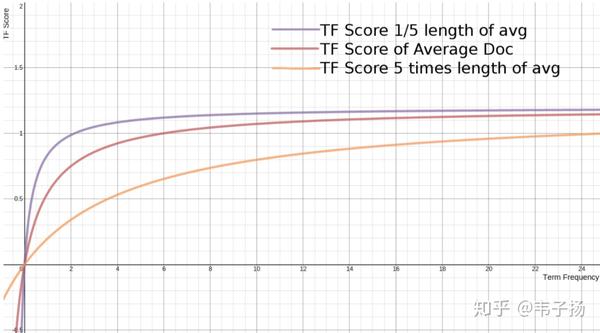
TF Score = ((k + 1) * tf) / (k * (1.0 - b + b * L) + tf)如果我们调整L,看文档长度是如何在其中起作用的,就可以发现,如果L越小,也就是文档越小,它的上升速度就越快,如果L越大,上升速度则越慢,这很好解释,对于短文章,比如TITLE或者微博,我们只需要匹配少量词,就可以确定其是否和我们的query相关,但是对于长文章,我们倾向于希望匹配更多的词才能知道它是否匹配,这非常合理, 这也就是公式里面的weightedTF。常数b决定这个文档长度的影响因子起多大作用,如果忽略文档长度这个影响因子,就设置为0即可。

你们的搜索系统的精排用了哪些特征?
- BM25F ,就是之前提到的,Lucene底层计算相关性的算法,在精排阶段我们会重新算一遍,但是常数k和b都会进行调整。
- HTR(Hit Tightness Ratio),HTR 用于衡量命中query的term的紧密度的得分,直观含义为对每个命中,计算其周围词中对query的紧密命中情况。
- CHR (Continuous Hit Ratio),计算doc连续命中query的term的得分
- CQR(Cover Query Ratio), 计算doc覆盖了query中多少个term
- TimeScore, 发布时间和当前query时间的差
LTR部分是怎么做的?
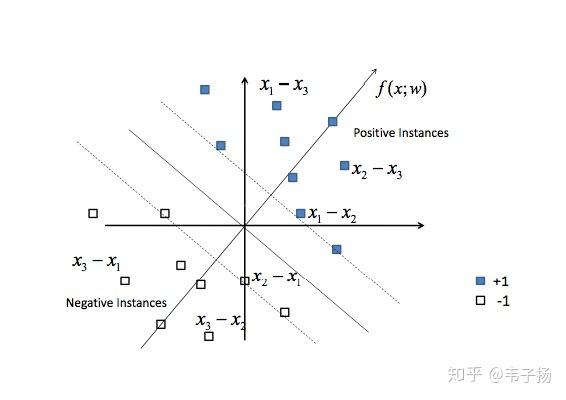
其实我上家公司的做法是简单的线性加权,权重是直接拍脑袋定的,用模型的方法很麻烦,要标数据,所以就没有用模型。但作为一个有追求的人,不知道模型的方法怎么跟面试官吹逼呢,所以之前我也看了一些关于LTR的文章,就跟面试官扯了扯这个: 1. Pointwise, 将精排阶段的各特征得分算出以后,也就有了feature, 而target可以看做是相关度,我们手动去标注相关度后,就有了训练集, 可以把这个当做一个回归模型来进行预测, 如果相关度只有“相关”“不相关“两个选项的话,就可以作为一个普通的分类模型。 2. Pairwise, 给定query返回的若干doc, doc1, doc2, doc3, doc4, 我们手工标记得出它们的相关性为doc1>doc2>doc3>doc4, 那么,我们定义新的训练样本, 令x1-x2, x1-x3, x2-x3为正样本,令x2-x1, x3-x1, x3-x2为负样本, 然后训练一个二分类器(支持向量机)来对这些新的训练样本进行分类,代表模型为SVM Ranking
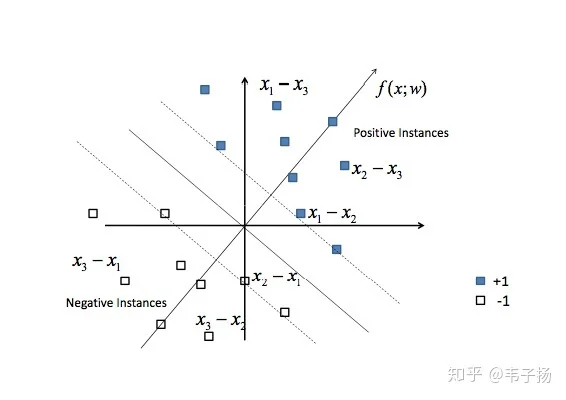
3. Listwise, 假设返回的搜索结果集合里包含A、B和C三个文档,3个文档顺序共有6种排列组合方式:ABC、ACB、BAC、BCA、CAB和CBA,每种排列组合都是一种可能的搜索结果排序方法,我们可以把函数g设想成最优评分函数(人工打分),对查询Q1来说:文档A得6分,文档B得4分,文档C得3分;目的是寻找到一个函数f,可以使得搜索结果打分顺序尽可能的接近标准函数g.损失函数为两个分布之间的KL散度。
ES node 分为哪几种角色?
- master node, 代表该结点具有充当master结点的资格,但最后是否能当上master node 还需要进行选举。最后当选master的结点负责维护整个集群的状态。
- data node, 负责保存数据、处理数据、搜索数据的节点,这种节点对机器的性能要求较高。
- ingest node, 预处理结点,ES允许文档在写入前,定义一个pipeline去对这些数据进行预处理。
ES是实时的吗?为什么不是实时的?
ES是近实时的,并不是实时的,数据被写入后,它首先存在内存暂存区中,无法被检索到,只有触发refresh(默认是1秒)后,它才会在内存中形成一个segment,可以被检索到,而只有flush后,它才会从内存写到磁盘中持久化。为什么要做成近实时?因为只有形成segment才能被检索到,而如果是实时的话,每次提交都要形成一个段,过多地段会消费过多的资源,因此为了控制segments的数量,ES是近实时查询。
如何给ES进行内存分配?给jvm最多多少内存?
留一半内存给jvm ,另一半给cache 缓存。但是注意给jvm的内存不能超过32G, 超过32G jvm将不使用压缩指针,平白无故地增加了内存的损耗和GC开销。
ES采用的是那种锁来处理并发的?
采用乐观锁,乐观锁本质上并不是锁,而是采用了版本号的方法来控制的,例如有两个线程要更改商品的数量扣除一个,线程1读取商品数量c, 版本为v1, 线程2也读取商品数量c,版本为v1, 接着线程1更改商品数量为c-1, 此时版本为v2, 线程2也更改商品数量为c-1, 但发现此时版本为v2了,线程2就会选择重试。读取到当前版本v2的商品数量再-1。
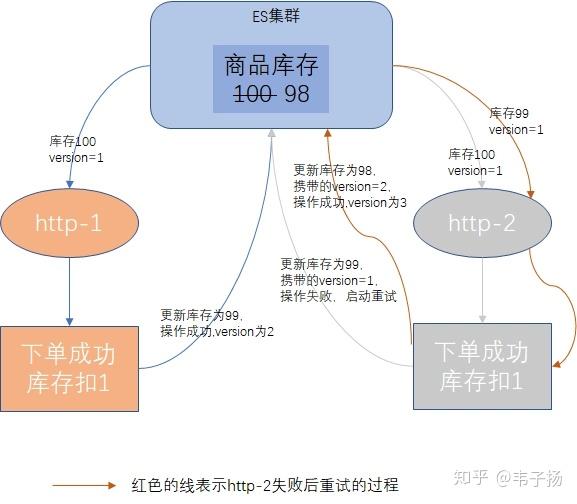
乐观锁适用于并发场景不多的情况下,比悲观锁的代价要小。
操作系统中的虚拟内存是什么?
用自己的话来讲了,就是当内存不够时,将一部分不使用的内存转移至外存,再将需要用的信息从外存装载到内存中,从操作系统的角度来看,用户似乎有了一个比物理内存大的多的内存,这就是虚拟内存。 (被面试官指出理解片面了,我说的是swap,只是虚拟内存可实现的功能之一) 虚拟内存是相对于物理内存来说的,它通过一个页表,建立一个虚拟内存到物理内存的映射,使得程序申请内存时感觉申请了一个连续内存,但实际在物理内存中被分成了若干个page,进程访问内存时,操作系统都会把进程提供的虚拟内存地址转换为物理地址,再去对应的物理地址上获取数据,CPU 的内存管理单元 MMU(Memory Management Unit)就是专门做这个事情的。swap只是虚拟内存的好处之一,虚拟内存还可以很方便地实现共享内存。
操作系统中的缓冲是什么?
用于协调CPU和IO速度不一致的一种机制。当我们要写入到磁盘数据的时候,我们先把数据写到一个内存的buffer中,而后再一次性地写入,这样的批量操作可以提高数据的读写速率。
什么是用户态?什么是内核态?
程序一旦进入系统调用,就会进入内核态,否则就是用户态。所谓系统调用,就是例如分配内存、读写IO等。
”零拷贝“是什么?
讲真这个是真滴不会.学习以后,在这里补充一下答案:
比如我们有个服务的功能是要求从硬盘中读取文件,然后返回给用户以供下载。那这个过程经历了哪些阶段呢:
1. 程序向OS发出read()系统调用,触发上下文切换,从用户态切换到内核态。
2. 从硬盘中读取文件内容,通过直接内存访问(DMA)存入内核地址空间的缓冲区。
3. 将数据从内核缓冲区拷贝到用户空间缓冲区,read()系统调用返回,并从内核态切换回用户态。
4. 程序OS发出write()系统调用,触发上下文切换,从用户态切换到内核态。
5. 将数据从用户缓冲区拷贝到内核中与目的地Socket关联的缓冲区。
6. 数据最终经由Socket通过DMA传送到硬件(如网卡)缓冲区,write()系统调用返回,并从内核态切换回用户态。 整个过程的时序图如下:
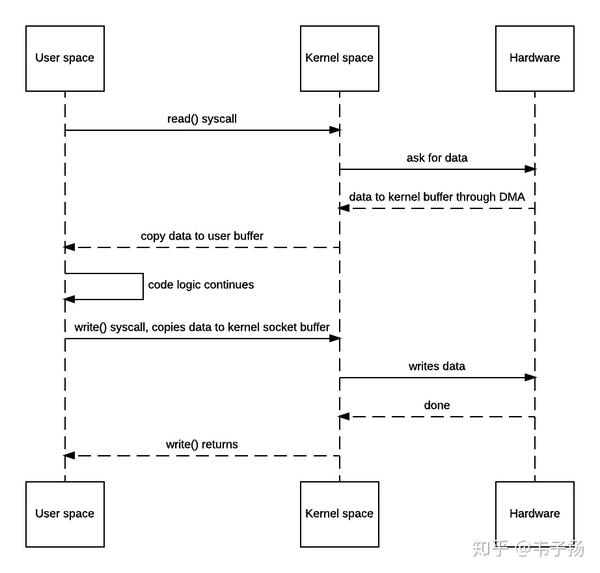
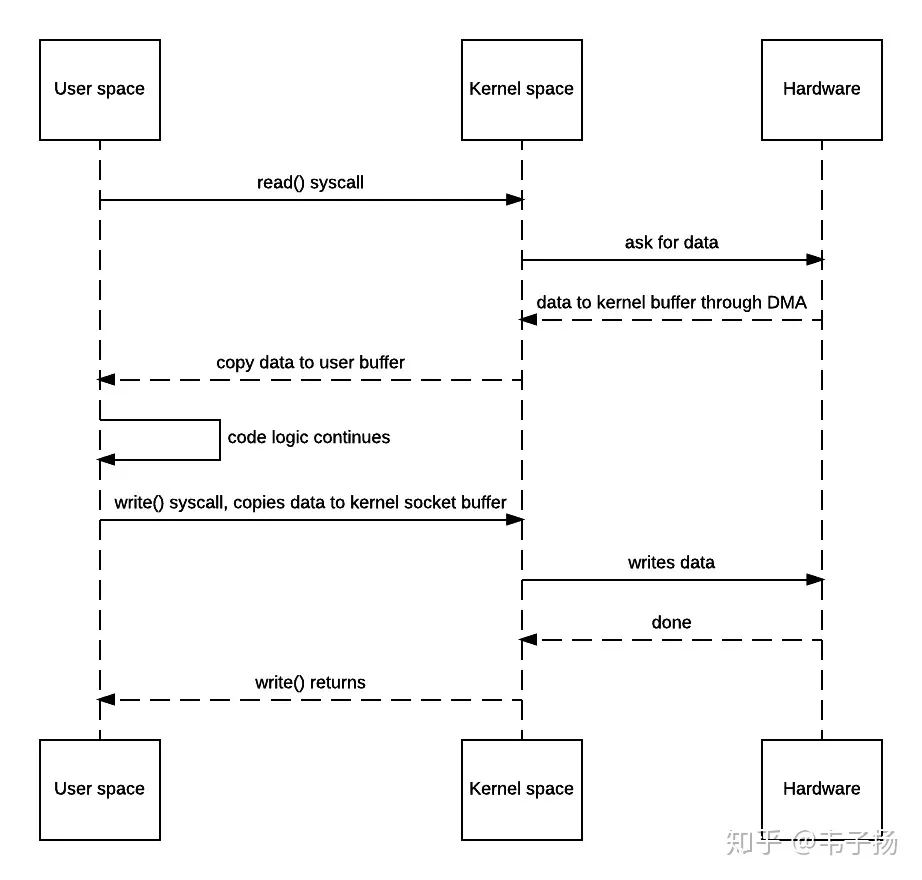
不难发现,以上一共发生了两次用户态向内核态的切换,两次内核态向用户态的切换,数据来来回回被拷贝了四次,其中从内核缓冲区向用户空间的复制是完全没有必要的,数据应该可以直接从内核缓冲区直接送入Socket缓冲区。“零拷贝”就是用于实现这一功能,以上的时序图如下:
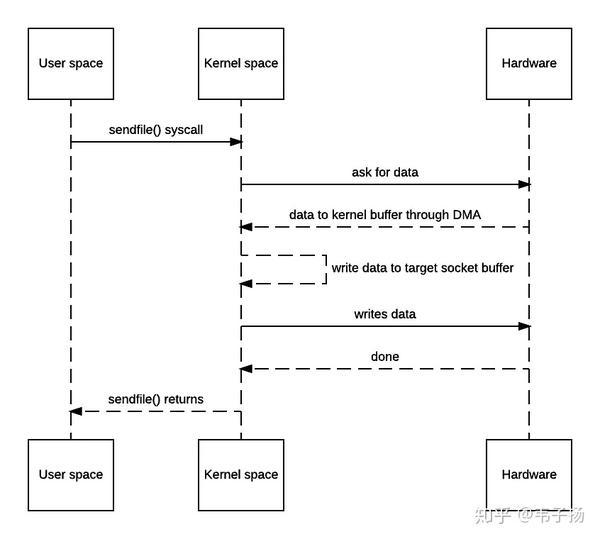
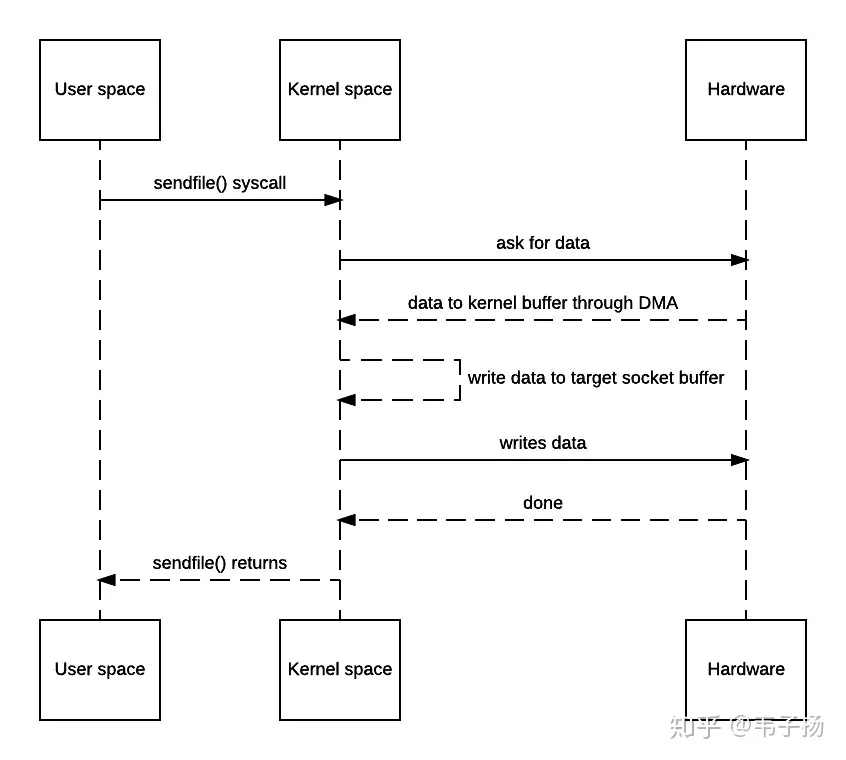
如此一来,拷贝的次数被减少到了三次,上下文切换的次数也减少到了2次,但这还不够完美,因为其中存在一个内核缓冲区到bucket 缓冲区的一次回环拷贝,为什么需要这次拷贝?因为在一般的Block DMA方式中,源物理地址和目标物理地址都得是连续的,所以一次只能传输物理上连续的一块数据,每传输一个块发起一次中断,直到传输完成,所以必须要在两个缓冲区之间拷贝数据。
Scatter/Gather DMA方式就是用于解决这一问题的,它会预先维护一个物理上不连续的块描述符的链表,描述符中包含有数据的起始地址和长度。传输时只需要遍历链表,按序传输数据,全部完成后发起一次中断即可。此时,硬件可以直接从内核缓冲区读取数据,不需要再从socket buffer里面读取了,时序流程图简化如下:
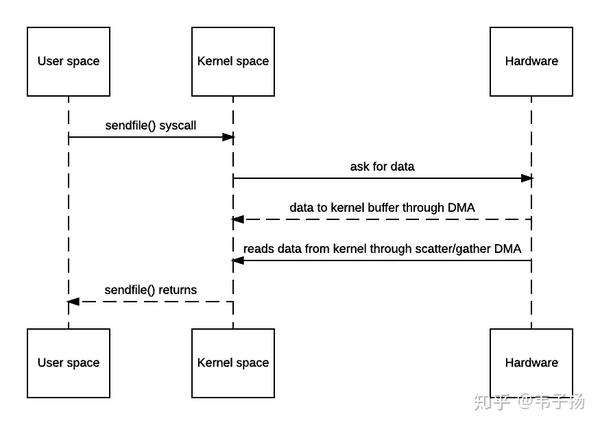
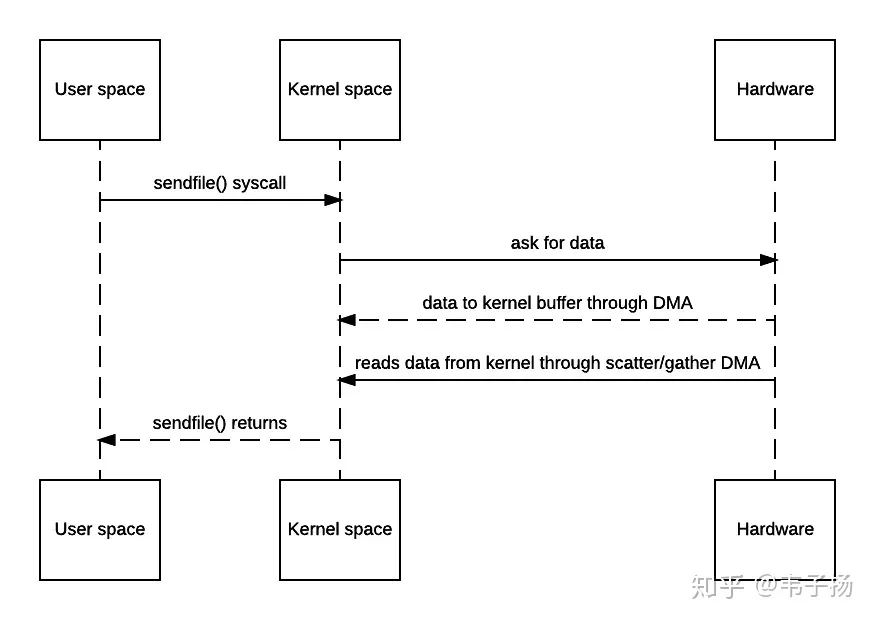
至此,只需要两次拷贝即可。所谓的零拷贝并不是一次都不需要拷贝,而是减少用户态和内核态之间的拷贝。
C中如何分配释放内存?堆内存栈内存分别存什么?
因为面试官提到说我进来是要转C++的,而我写过C,所以面试官问了一些相关知识。 用malloc分配内存,free释放内存,堆内存存放对象,栈内存存放临时变量、参数值等。
new 和malloc区别是什么?
malloc分配在堆上,new是分配在自由存储区上(虽然自由存储区大多数情况下等于堆);new可以定义一个类生成时的构造函数,malloc不可以;malloc需要声明申请的内存大小,new是编译器自动计算的。
野指针是什么?
函数返回了一个局部变量的指针,这时候,由于函数结束以后,所有的临时变量会被回收,指针会指向一个垃圾内存,此时对于该指针的操作(例如解引用),都会导致不可预期的事情发生。比如这段代码:
Golang如何避免野指针问题的?
Golang会在返回局部变量的指针时,进行“逃逸分析”, 如果它分析出来返回的是指针的话,分配内存的时候,就不会在栈上分配,而是逃逸到堆上去分配,从而避免被垃圾回收。
一道算法题,链表相加的题目
给定两个链表,每个链表代表一个数字,链表的头结点对应数字的高位,尾结点对应数字的地位,要求返回一个链表,这个链表代表输入的两个链表所表示的数字相加之和。
比如说: 输入: 3 -> 2 -> 8, 7 -> 6 -> 4 返回 1 -> 0 -> 9 -> 2
把链表转成数字后相加,然后逐个写到新链表里面再反转就行了,直接写代码:
再考一道,有1亿个数字,计算出前TOP 10大的数字
TOP N问题通通用堆来解决,口述了一下思路正确,就没让在屏幕上写了,之前写过一篇关于堆的文章可以看这类问题的通用解法: 详解数据结构——堆
8月19日三面
难度:★★★☆☆ 这是部门leader面,没想到leader是一个严肃的大姐姐,语速很慢,逻辑清晰。问题的问题比较general.
介绍一下搜索引擎通常有哪些部分组成,你们负责的项目,负责的搜索项目的规模、搜索集群的配置、用户量、并发量等等。
同上,涉密不在博客里面谈..
说说Elasticsearch的应用场景,它的优点和缺点都有哪些?
缺点:
1. 近实时性。刚索引的doc需要refresh后形成段,才能被检索。
2. 不准确性。在获得一些termVector,或者统计信息的时候,ES往往只会随机获取一个shard的统计信息来进行估算,并且,会记入已经删除的文档。
3. 无法进行深分页查询。当你需要查第1000000个文档开始的10个文档时,它需要建立一个优先级队列把前1000010个文档全部计算出来再进行过滤,效率非常慢,这也是为什么ES查询时,越往后面查询越慢的原因。
优点:
1. 易横向拓展,分布式架构可以很容易地向集群中添加节点来增大集群的数据处理能那里。
2. 文档结构灵活。作为一个NoSQL,可以存储嵌套结构的数据,并且不需要显示声明字段的格式。
3. 全文检索,这个不用多说了,倒排索引就是做这个的。
应用场景: 日志系统、搜索引擎。
微服务架构的利弊?
把一个服务根据功能拆解为不同的服务,服务之间彼此独立,各司其职。 好处就是降低业务耦合度,逻辑清晰,简化部署开发,并且可扩展性好,还可以灵活组合到其他业务。 缺点的话,我说了一个服务之间交互需要通过http或者rpc进行通信,效率慢,且相对来说运维更加复杂。
使用k8s的好处?
因为我不是做inf的,但上份工作所有的服务都是部署在k8s上的,所以多少页了解一些. 1. 减少管理和运营负担,部署更快且安全。 2. 可以控制服务申请的资源,随时可以拓展,或者限制使用的CPU, Memory等等。 3. 可以对服务进行更好的监控和检查。 4. 便于进行CI/CD 5. 松耦合,天然适合微服务架构。
刷一道题,给定一个数组,找出其中的三个数,要求这三个数的和为0。
例如: 输入[2,4,3,-3,-6,0]输出: [(2,4,-6),(3,-3,0)]
典型的3sum问题,解决3sum问题首先要解决2sum问题: 也就是给定一个数组,找出其中两个数,要求这两个数之和为target_num, 两种方法:
O(n)O(n^2)O(N)O(NlogN)O(1)O(N^2)O(1)给你一个上百亿数量的URL, 请问如何对它们进行去重?
印象中看过有博客介绍过使用布隆过滤器来对URL进行去重,所以就介绍了一下布隆过滤器,(话说每次说到这个玩意儿,我脑海里面都会冒出LOL里的布隆拿个盾牌过滤女枪大招的场景 :


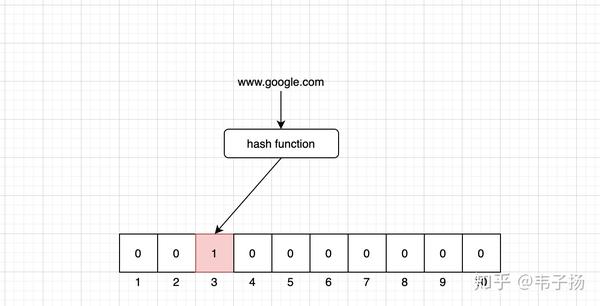
通常我们对元素去重,一般都用set,set的原理就是hash 嘛,谁不会,如图:
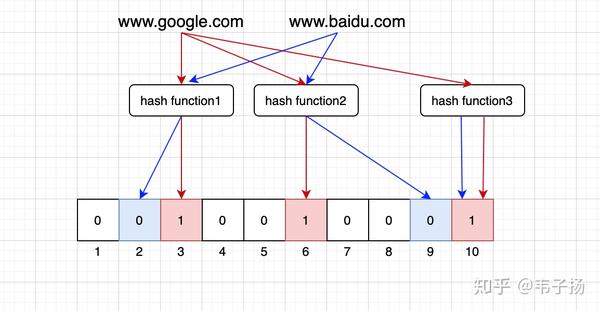
O(N)这时候我们的布隆过滤器就登场了,本质上是由长度为 m 的位图,每一位只占一个bit,与hash set不同的是,我们使用多个哈希函数,把输入的字符串转换成多个索引值,如果所有的索引值全部被占,那就说明是重复了。但是也会有刚好多个哈希函数全部碰撞的情况,造成假阳性的误判,只是这种概率很小。
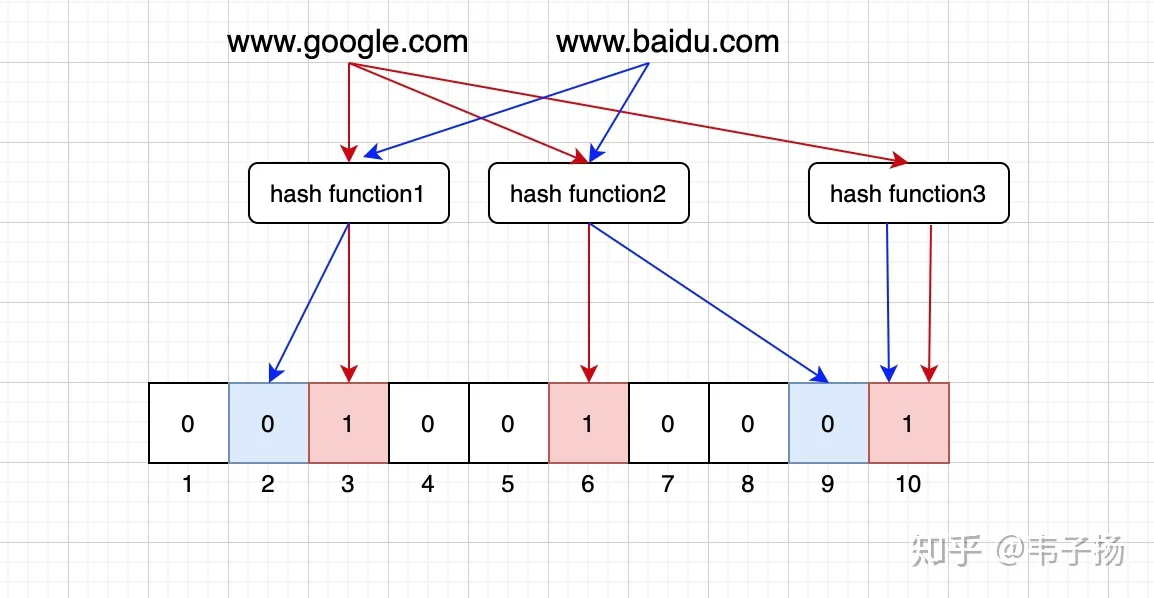
hhh,我本以为面试官会满意我这个答案,但她停顿了一下,她说希望我用分布式的方法来解决这类大数据问题。
后来查了一下,我的天,解法比hadoop中最简单的demo wordCount还要简单,只是我没用过hadoop,所以就没有往这map-reduce方面想。map 的 就是 ,value为空就行,然后reduce就直接汇总输出就完事了,啥也不用处理,因为reduce会自动把key相同的部分去重,而去重的原理就是hash表。。我哭
讲一下搜索的评价指标?
因为之前几次面试考的都是工程上的东西,算法上的东西我没怎么细看,没想过面试官会问这个,所以答的很不好,很后悔当时没有把F1 score讲出来,这个measurement我是很熟的,是机器学习里非常常用的评价指标,以前打kaggle的时候经常用这个作为评分标准,作业里也都用过。不过现在来看doesn't matter了,反正也拿到offer了。BTW,作为一名即将去百度做搜索的工程师,还是有必要把这个吃透的。
1.F-Score 关于搜索,两个最重要的指标: 召回率(Recall Ratio):返回结果中相关的数目/所有相关文档的数目, 图情档专业叫它查全率。 正确率(Precision Ratio): 返回结果中相关的数目/返回结果的总数目,图情档专业叫它查准率。
用混淆矩阵(confusion matrix)来说明:


所以正确率公式就是:


召回率公式就是:
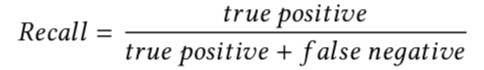
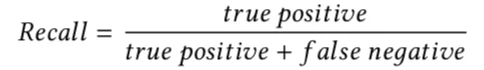
而F-score是综合考虑了两者的分数

其中的λ为正确率的权重,取值[0,1],如果我们希望给正确率和召回率相同的比重,那就是F-1 score:
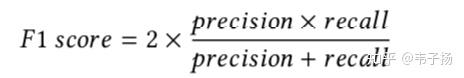
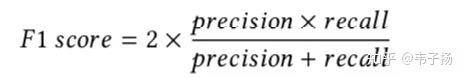
F-score用于评价无序检索结果,但是如果我们更关注返回结果的顺序,那就需要换一种评价指标
- MAP(mean average precision)平均正确率均值
上面F-score是一种通用的分类问题的评价指标,对于搜索来说,返回结果是有顺序的,MAP 是反映系统在全部相关文档上性能的单值指标。系统检索出来的相关文档越靠前(rank 越高),MAP就应该越高。如果系统没有返回相关文档,则准确率默认为0。
之前在英国上Biometrics,也就是一门计算机图像的实际应用的一门课里面,有学习过P-R曲线和ROC曲线,即以precision 和 recall 作为 纵、横轴坐标 的二维曲线,通过不断调整阈值时对应的精度和召回率即可画出:
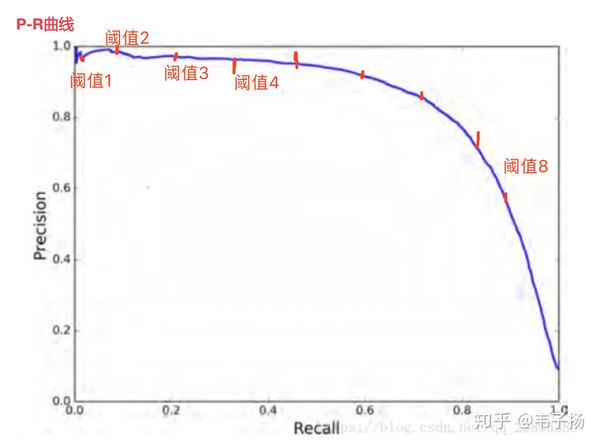
稍微转变一下思路, 我们把这里面的阈值,换成取查询结果的TOP N算出的P以及R就可以变成在信息检索领域中的P-R了。
举个栗子,比如对于一个query来说,总共召回4个文章,rank为分别为1, 2, 4, 7;那么其平均正确率计算为: (1/1 + 2/2 + 3/4 + 4/7 )/4=0.83
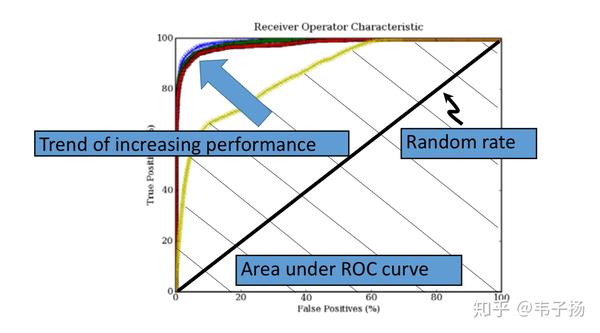
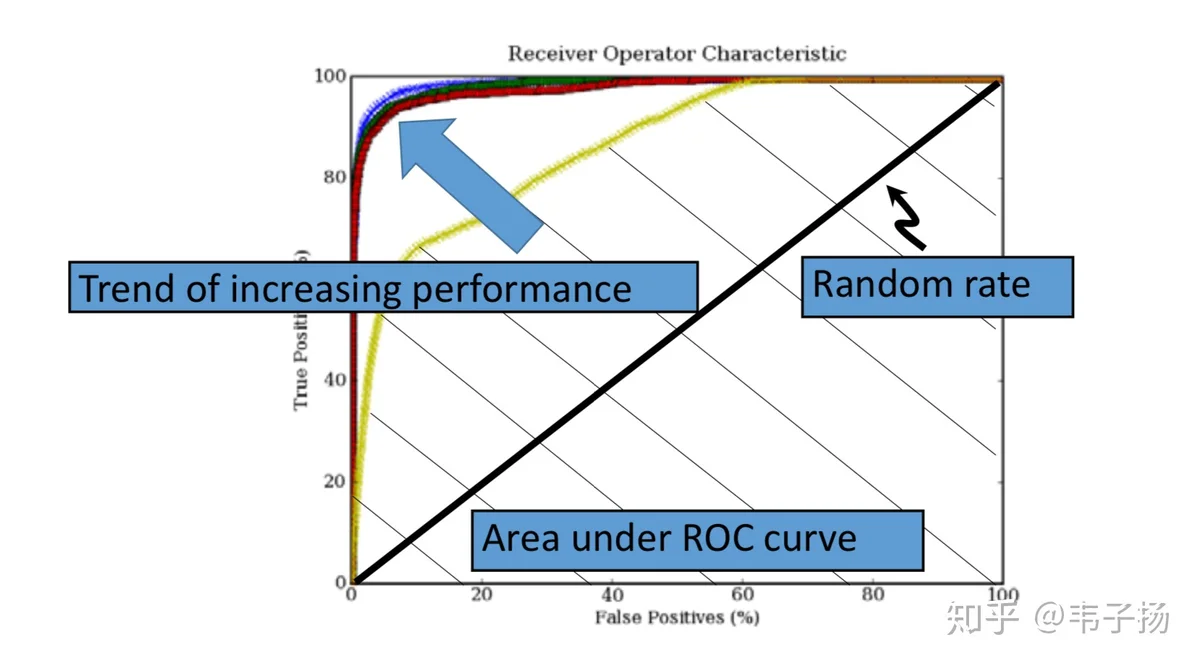
- ROC
这个指标不常用,但是在信息检索导论里也提到过,其实就是把P-R曲线的横纵坐标的定义换成横坐标为false positive ,纵坐标为true positive即可,贴一张以前在英国上学时的slides, ROC曲线下的面积能代表系统的表现:
如果让你实现百度搜索框的的搜索提示功能,例如搜索”北京”的时候,提示“北京大学”“北京天气”等等?
先前还真没思考过,不过现场想了一个超级简单的,基于ES的思路。 离线部分上,收集用户的搜索日志,整理为的格式,将query按字分词,即每个字为一个term, 并在每个query下加一个score字段,score为用户的搜索频率。 在线部分,将用户输入的query按字分词,然后使用match query的AND operator,要求用户所有输入的term全部被包含,并在order上按照score降序排列即可。
如果没有搜索日志呢?
那离线部分,就在百度收录的所有网页的内容里,进行较粗粒度分词,将文章分为若干个词组,一个词组作为一个query,计算每个词组的TF-IDF作为score,其他不变.
emmm,我知道这么做肯定有问题,百度肯定不是这么做的,但这已经是我能想出来的最优解了。
如何评价自己?最近在看什么书?
如何评价自己就不说了,都懂得,夸夸自己再嘲讽嘲讽自己。 然后跟面试官说在看 《lucene原理》(其实这是我两个多月前看的,最近在看的其实是《剑指offer》hhh),话说感觉BAT TMD 终面好像都喜欢问这个问题。
8月25日HR面
你知道你的这个部门负责哪些内容嘛?你的职业规划是什么?倾向于管理还是技术?你怎么看待B站和百度的关系?
把百度一顿吹就完事了.
最后
其实拿到offer以后心情挺平静的,没有太开心,毕竟先前准备的周期也挺长,每天八点半拖着疲惫的身躯下班回来,就需要挑灯夜战继续看书刷题,好不容易控制下去的体重两个月内瞬间反弹,又得重新锻炼咯。
最后再分享一下复习的思路吧,我个人觉得根据你的个人简历画张脑图出来,按照上面的知识点一个一个过,过完三遍我觉得就差不多了,比如我复习的时候图长这样:
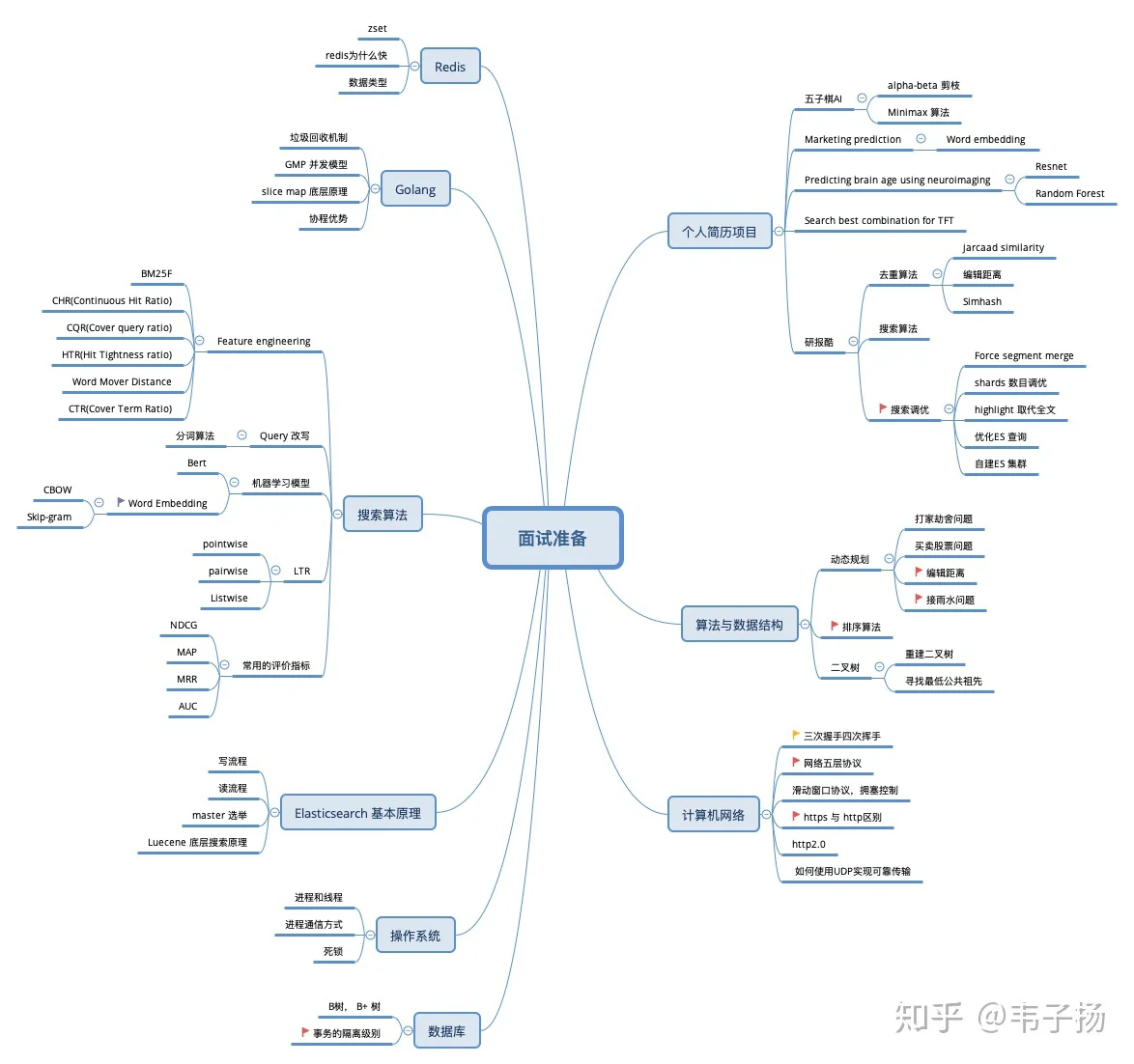
事实证明,基本能命中70%的题目吧hhh,另外算法方面,刷个三四百道就差不多了,然后每个星期日都去leetcode上面去打周赛练练手感就好了。很遗憾这次面试没有碰到动态规划的题目,我个人认为,其他数据结构算法的题目都是熟能生巧就行,只有动态规划才真正考的是智力。
其实写这么多不是为了啥,就是喜欢在写博客的时候努力把问题向读者说清楚的过程,陶醉在这种好为人师的感觉中还是挺棒的hhh