
在进行golang项目开发过程中,虽然没有Java那么多多变成模式,但有一些实践经验可以总结下来,对形成良好的编程规范和解决bug是有一定的帮助的。
1.1 最佳实践总结
(1)尽量不要panic,而要返回错误给调用方处理
在生产环境中运行的代码必须避免出现 panic。panic 是 cascading failures 级联失败的主要根源 。如果发生错误,该函数必须返回错误,并允许调用方决定如何处理它。
panic/recover 不是错误处理策略。仅当发生不可恢复的事情(例如:nil 引用)时,程序才必须 panic。程序初始化是一个例外:程序启动时应使程序中止的不良情况可能会引起 panic。
不好的写法:
func foo(bar string) {
if len(bar) == 0 {
panic("bar must not be empty")
}
// ...
}
func main() {
if len(os.Args) != 2 {
fmt.Println("USAGE: foo <bar>")
os.Exit(1)
}
foo(os.Args[1])
}
推荐的写法:
func foo(bar string) error {
if len(bar) == 0 {
return errors.New("bar must not be empty")
}
// ...
return nil
}
func main() {
if len(os.Args) != 2 {
fmt.Println("USAGE: foo <bar>")
os.Exit(1)
}
if err := foo(os.Args[1]); err != nil {
panic(err)
}
}
(2)结构体嵌套时,外层结构体尽量定义为指针
嵌套的结构体,尽量把外层结构体定义为指针,这样当结构体中每个字段都是默认值时,指针的表示的结构体字段是nil,而不用单独判断给结构体中的每个字段是否是默认值。
nil只能赋值给指针、channel、func、interface、map或slice类型的变量,将nil赋值给其他类型的变量会引发panic。
在Golang中,如果将structObj==nil,不出意外的会得到一个编译错误cannot convert nil to type Person。
在golang中,包含切片([]byte、[]int等), map 等类型的struct是无法相互比较的。
Struct values are comparable if all their fields are comparable. Two struct values are equal if their corresponding non-blank fields are equal…
(3)默认值的使用
bool默认为false,如果前端默认不传字段,或者传空的bool字段,后端会认为为空。如果前端传的空bool字段有特定的含义,如想要表达true的意思,后端就需要对前端所传字段进行判断,对这种情况就需要对空字段先初始化为true,否则的话,后端存进数据库的就变成false,与原来要展示的功能相反。
int类型的枚举变量,尽量从1开始,以防默认值0的影响
(4)枚举从 1 开始
在 Go 中引入枚举的标准方式:声明一个自定义类型和一个使用了 iota 的 const 组。由于int变量的默认值为 0,因此通常应以非零值开头枚举。
在某些情况下,使用零值是有意义的(枚举从零开始),例如,当零值是理想的默认行为时。
type LogOutput int
const (
LogToStdout LogOutput = iota
LogToFile
LogToRemote
)
// LogToStdout=0, LogToFile=1, LogToRemote=2
(5)错误类型
Go 中有多种声明错误(Error) 的选项:
errors.New 对于简单静态字符串的错误
fmt.Errorf 用于格式化的错误字符串
实现 Error() 方法的自定义类型
用 “pkg/errors”.Wrap 的 Wrapped errors
返回错误时,请考虑以下因素以确定最佳选择:
这是一个不需要额外信息的简单错误吗?如果是这样,errors.New 足够了。
用户需要检测并处理此错误吗?如果是这样,则应使用自定义类型并实现该 Error() 方法。
是否要传播下游函数返回的错误?如果是这样,请查看本文后面有关错误包装 section on error wrapping 部分的内容。
否则 fmt.Errorf 就可以了。
如果客户端需要检测错误,并且已创建了一个简单的错误 errors.New,请使用一个错误变量。
如果您有可能需要客户端检测的错误,并且想向其中添加更多信息(例如,它不是静态字符串),则应使用自定义类型。
错误包装 (Error Wrapping)
一个(函数/方法)调用失败时,有三种主要的错误传播方式:
如果没有要添加的其他上下文,并且您想要维护原始错误类型,则返回原始错误。
添加上下文,使用 “pkg/errors”.Wrap 以便错误消息提供更多上下文 ,“pkg/errors”.Cause 可用于提取原始错误。
使用 fmt.Errorf ,如果调用者不需要检测或处理的特定错误情况。 specific error case.
(6)类型断言先判断,成功正常处理,否则处理异常
type assertion 的单个返回值形式针对不正确的类型将产生 panic。因此,始终使用“comma ok”的惯用法先去判断类型推导是否成功,再去进行后面的处理,以免类型推导不成功引发panic。
1.2 规范
(1)相似的声明放在一组
Go 语言支持将相似的声明放在一个组内。
不良写法:
const a = 1
const b = 2
var a = 1
var b = 2
type Area float64
type Volume float64
type Operation int
const (
Add Operation = iota + 1
Subtract
Multiply
ENV_VAR = "MY_ENV"
)
好的规范:
const (
a = 1
b = 2
)
var (
a = 1
b = 2
)
type (
Area float64
Volume float64
)
type Operation int
const (
Add Operation = iota + 1
Subtract
Multiply
)
const ENV_VAR = "MY_ENV"
(2)包名
当命名包时,请按下面规则选择一个名称:
全部小写。没有大写或下划线。
大多数使用命名导入的情况下,不需要重命名。
简短而简洁。请记住,在每个使用的地方都完整标识了该名称。
不用复数。例如net/url,而不是net/urls。
不要用“common”,“util”,“shared”或“lib”。使用信息量不足的报名,是不好的。
(3)导入别名
如果程序包名称与导入路径的最后一个元素不匹配,则必须使用导入别名。
在所有其他情况下,除非导入之间有直接冲突,否则应避免导入别名。
import (
"net/http"
"runtime/trace"
nettrace "golang.net/x/trace"
client "example.com/client-go"
trace "example.com/trace/v2"
)
(3)对于未导出的顶层常量和变量,使用_作为前缀
在未导出的顶级vars和consts, 前面加上前缀_,以使它们在使用时明确表示它们是全局符号。
例外:未导出的错误值,应以err开头。
基本依据:未导出的顶级变量和常量具有包范围作用域(只能在本包中引用),导出的变量或常量(首字母大写)可以在其他包中引用。使用通用名称可能很容易在其他文件中意外使用错误的值。
不良使用方式:
// foo.go
const (
defaultPort = 8080
defaultUser = "user"
)
// bar.go
func Bar() {
defaultPort := 9090
...
fmt.Println("Default port", defaultPort)
// We will not see a compile error if the first line of
// Bar() is deleted.
}
规范使用:
// foo.go
const (
_defaultPort = 8080
_defaultUser = "user"
)
(4)不必要的 else
如果在 if 的两个分支中都设置了变量,则可以将其替换为单个 if。
不推荐使用:
var a int
if b {
a = 100
} else {
a = 10
}
规范用法:
a := 10
if b {
a = 100
}
(5)nil 是一个有效的 slice
nil 是一个有效的长度为 0 的 slice,这意味着,
不应明确返回长度为零的切片。应该返回nil 来代替。
要检查切片是否为空,请始终使用len(s) == 0。而非 nil。
零值切片(用var声明的切片)可立即使用,无需调用make()创建。
(6)变量作用域
如果有可能,尽量缩小变量作用范围。除非它与 减少嵌套的规则冲突。
如果需要在 if 之外使用函数调用的结果,则不应尝试缩小范围。
(7)初始化 Struct 引用
在初始化结构体引用时,使用&T{}代替new(T),以使其与结构体初始化一致。
(8)格式化输出
格式化字符串时,严格按照线上pipeline的语法检查执行:
格式化字符串,首字母不能大写;
格式化符号与输出字段对应;
这有助于go vet对格式字符串执行静态分析。
声明Printf-style 函数时,请确保go vet可以检测到它并检查格式字符串。
这意味着应尽可能使用预定义的Printf-style 函数名称。go vet将默认检查这些。有关更多信息,请参见 Printf 系列。
如果不能使用预定义的名称,请以 f 结束选择的名称:Wrapf,而不是Wrap。go vet可以要求检查特定的 Printf 样式名称,但名称必须以f结尾。
$ go vet -printfuncs=wrapf,statusf
1.3 性能
(1)优先使用 strconv 而不是 fmt
将原语转换为字符串或从字符串转换时,strconv速度比fmt快。
(2)优先使用指针而不是反射判断结构体对象是否为空
指针的性能比映射或深拷贝的性能要高
nil 结构体是指结构体指针变量没有指向一个实际存在的内存。这样的指针变量只会占用 1 个指针的存储空间,也就是一个机器字的内存大小。
var c *Circle = nil
而零值结构体是会实实在在占用内存空间的,只不过每个字段都是零值。如果结构体里面字段非常多,那么这个内存空间占用肯定也会很大。
package main
import (
"fmt"
"reflect"
"time"
)
type Stu struct {
Name string
Age int
Phone string
Addr *Address
}
type Student struct {
Name string
Age int
Phone string
Addr Address
}
type Address struct {
Province string
City string
Area string
}
func main() {
var stu1 Student
stu2 := Student{
Name: "aaa",
Age: 23,
Phone: "123",
Addr: Address{},
}
//1.使用反射判断结构体是否为空
if reflect.DeepEqual(stu1, Student{}) {
fmt.Printf("1.struct %+v is empty\n", stu1)
}
if !reflect.DeepEqual(stu2, Student{}) {
fmt.Printf("2.struct %+v is not empty\n", stu2)
}
now1 := time.Now()
if reflect.DeepEqual(stu2.Addr, Address{}) {
fmt.Printf("3.struct %+v is empty\n", stu2.Addr)
}
cost1 := time.Now().Sub(now1)
fmt.Println("reflect.DeepEqual struct is empty cost time:", cost1)
//2.使用指针判断结构体是否为空
var stu3 *Student
if stu3 == nil {
fmt.Printf("4.struct %+v is empty\n", stu3)
}
stu4 := &Stu{}
if stu4 == nil {
fmt.Printf("5.struct %+v is empty\n", stu4)
}
stu5 := &Stu{
Name: "22",
Age: 20,
Phone: "236",
Addr: &Address{},
}
if stu5 != nil {
fmt.Printf("6.struct %+v is empty\n", stu5)
}
now2 := time.Now()
if stu5.Addr == nil {
fmt.Printf("7.struct %+v is empty\n", stu5.Addr)
}
cost2 := time.Now().Sub(now2)
fmt.Println("pointer struct is empty cost time:", cost2)
if stu5.Addr.Province == "" {
fmt.Printf("8.struct %+v is empty\n", stu5.Addr.Province)
}
}
运行结果如下:
1.struct {Name: Age:0 Phone: Addr:{Province: City: Area:}} is empty
2.struct {Name:aaa Age:23 Phone:123 Addr:{Province: City: Area:}} is not empty
3.struct {Province: City: Area:} is empty
reflect.DeepEqual struct is empty cost time: 3.306µs
4.struct <nil> is empty
6.struct &{Name:22 Age:20 Phone:236 Addr:0xc00006a270} is empty
pointer struct is empty cost time: 82ns
8.struct is empty
//微秒,符号μs,1,000 纳秒 = 1微秒
从运行结果,可以看出使用指针去判断结构体是否为空的方式比映射的方式性能要高。
func DeepEqual(a1, a2 interface{}) bool
用来判断两个值是否深度一致:除了类型相同;在可以时(主要是基本类型)会使用==;但还会比较array、slice的成员,map的键值对,结构体字段进行深入比对。map的键值对,对键只使用==,但值会继续往深层比对。DeepEqual函数可以正确处理循环的类型。函数类型只有都会nil时才相等;空切片不等于nil切片;还会考虑array、slice的长度、map键值对数。
(3)结构体值拷贝(深拷贝)与指针拷贝(浅拷贝)
函数调用时参数传递结构体变量,Go 语言支持值传递,也支持指针传递。值传递涉及到结构体字段的浅拷贝,指针传递会共享结构体内容,只会拷贝指针地址,规则上和赋值是等价的。
golang中的apend和copy函数可以实现对切片的深拷贝
浅拷贝:拷贝对象与被拷贝对象指向同一个地址,一个对象值的改变会影响另一个对象的值。
深拷贝:拷贝对象与被拷贝对象指向不同的地址,其中一个对象值的改变不影响另一个。
在方法定义/调用过程中,结构体对象作为值传递时,传入的是结构体对象的一个副本(拷贝),对该结构体对象内部变量的任何改动,都将会失效(因为下一次访问的时候传入的是该结构体新的副本)。
在方法定义/调用过程中,结构体对象作为指针传参时,每一次传入的都是该结构体对应的指针(地址),指向的是同一个结构体,因此地址没有变化;且对内部变量做改动/赋值时,都是改动的该结构体的内容。
在Go语言中的这个差别可能是对OOP设计的一个坑,在Go语言中要想实现OOP的设计,在进行方法封装时,都采用传递结构体指针的方式。
package main
import "fmt"
type B struct {
Name string
}
// Test1 测试结构体拷贝,对结构体字段值的修改不改变其值,但是改变函数地址
// 每一次Test1的调用,都是传入的结构体b的一个副本(拷贝),在Test1中对内部变量的任何改动,都将会失效(因为下一次访问的时候传入的是b结构体新的副本)。
func (b B) Test1() {
fmt.Printf("Test1 addr:%p\n", &b)
fmt.Printf("Test1 name:%s\n", b.Name)
b.Name = "john"
}
// Test2 测试指针拷贝,对结构体字段值的修改,会改变其值,但是函数地址不会变化
// 指针传参时,每一次传入的都是b结构体的指针,指向的是同一个结构体,对内部变量做改动时,地址不会变化,都是改动的b结构体的内容。
func (b *B) Test2() {
fmt.Printf("Test2 addr:%p\n", b)
fmt.Printf("Test2 name:%s\n", b.Name)
b.Name = "john"
}
func main() {
b := B{}
b.Test1()
b.Test1()
b.Test2()
b.Test2()
}
运行结果:
Test1 addr:0xc0000661d0
Test1 name:
Test1 addr:0xc0000661e0
Test1 name:
Test2 addr:0xc0000661c0
Test2 name:
Test2 addr:0xc0000661c0
Test2 name:john
a.基本类型–名值存储在栈内存中,例如var a int =1;
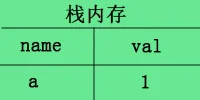
当你b=a复制时,栈内存会新开辟一个内存,例如这样:
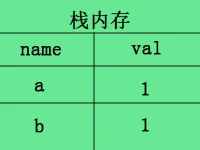
所以当你此时修改a=2,对b并不会造成影响,因为此时的b已自食其力,翅膀硬了,不受a的影响了。当然,let a=1,b=a;虽然b不受a影响,但这也算不上深拷贝,因为深拷贝本身只针对较为复杂的object类型数据。
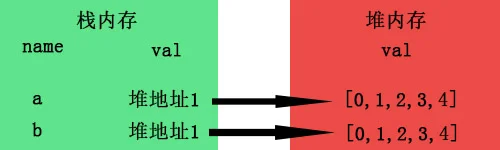
b.引用数据类型–名存在栈内存中,值存在于堆内存中,但是栈内存会提供一个引用的地址指向堆内存中的值,我们以上面浅拷贝的例子画个图:

当b=a进行拷贝时,其实复制的是a的引用地址,而并非堆里面的值。
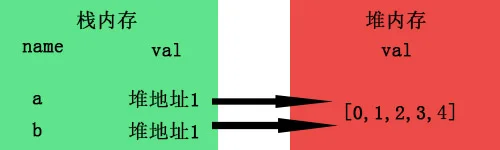
而当我们a[0]=1时进行数组修改时,由于a与b指向的是同一个地址,所以自然b也受了影响,这就是所谓的浅拷贝了。
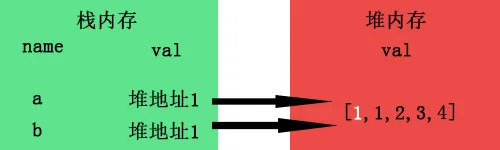
要是在堆内存中也开辟一个新的内存专门为b存放值,就像基本类型那样,是不是就达到深拷贝的效果了
深拷贝与浅拷贝的区别,实现深拷贝的几种方法 https://www.cnblogs.com/echolun/p/7889848.html
Go语言中结构体方法副本传参与指针传参的区别:https://www.jb51.net/article/130625.htm
golang结构体定义及参数传递:https://www.jianshu.com/p/f3d39daa2c4a