
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴!《Go语言设计与实现》的纸质版图书已经上架京东,有需要的朋友请点击 链接 购买。
rangefor 循环能够将代码中的数据和逻辑分离,让同一份代码能够多次复用相同的处理逻辑。我们先来看一下 Go 语言 for 循环对应的汇编代码,下面是一段经典的三段式循环的代码,我们将它编译成汇编指令:
package main
func main() {
for i := 0; i < 10; i++ {
println(i)
}
}
"".main STEXT size=98 args=0x0 locals=0x18
00000 (main.go:3) TEXT "".main(SB), $24-0
...
00029 (main.go:3) XORL AX, AX ;; i := 0
00031 (main.go:4) JMP 75
00033 (main.go:4) MOVQ AX, "".i+8(SP)
00038 (main.go:5) CALL runtime.printlock(SB)
00043 (main.go:5) MOVQ "".i+8(SP), AX
00048 (main.go:5) MOVQ AX, (SP)
00052 (main.go:5) CALL runtime.printint(SB)
00057 (main.go:5) CALL runtime.printnl(SB)
00062 (main.go:5) CALL runtime.printunlock(SB)
00067 (main.go:4) MOVQ "".i+8(SP), AX
00072 (main.go:4) INCQ AX ;; i++
00075 (main.go:4) CMPQ AX, $10 ;; 比较变量 i 和 10
00079 (main.go:4) JLT 33 ;; 跳转到 33 行如果 i < 10
...
这里将上述汇编指令的执行过程分成三个部分进行分析:
AXiJMP 75iJLT 33JLT 33INCQ AX经过优化的 for-range 循环的汇编代码有着相同的结构。无论是变量的初始化、循环体的执行还是最后的条件判断都是完全一样的,所以这里也就不展开分析对应的汇编指令了。
package main
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
println(i)
}
}
JMP5.1.1 现象 #
forrange循环永动机 #
如果我们在遍历数组的同时修改数组的元素,能否得到一个永远都不会停止的循环呢?你可以尝试运行下面的代码:
func main() {
arr := []int{1, 2, 3}
for _, v := range arr {
arr = append(arr, v)
}
fmt.Println(arr)
}
$ go run main.go
1 2 3 1 2 3
上述代码的输出意味着循环只遍历了原始切片中的三个元素,我们在遍历切片时追加的元素不会增加循环的执行次数,所以循环最终还是停了下来。
神奇的指针 #
rangefunc main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
newArr = append(newArr, &v)
}
for _, v := range newArr {
fmt.Println(*v)
}
}
$ go run main.go
3 3 3
&arr[i]&v遍历清空数组 #
当我们想要在 Go 语言中清空一个切片或者哈希时,一般都会使用以下的方法将切片中的元素置零:
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
arr[i] = 0
}
}
依次遍历切片和哈希看起来是非常耗费性能的,因为数组、切片和哈希占用的内存空间都是连续的,所以最快的方法是直接清空这片内存中的内容,当我们编译上述代码时会得到以下的汇编指令:
"".main STEXT size=93 args=0x0 locals=0x30
0x0000 00000 (main.go:3) TEXT "".main(SB), $48-0
...
0x001d 00029 (main.go:4) MOVQ "".statictmp_0(SB), AX
0x0024 00036 (main.go:4) MOVQ AX, ""..autotmp_3+16(SP)
0x0029 00041 (main.go:4) MOVUPS "".statictmp_0+8(SB), X0
0x0030 00048 (main.go:4) MOVUPS X0, ""..autotmp_3+24(SP)
0x0035 00053 (main.go:5) PCDATA $2, $1
0x0035 00053 (main.go:5) LEAQ ""..autotmp_3+16(SP), AX
0x003a 00058 (main.go:5) PCDATA $2, $0
0x003a 00058 (main.go:5) MOVQ AX, (SP)
0x003e 00062 (main.go:5) MOVQ $24, 8(SP)
0x0047 00071 (main.go:5) CALL runtime.memclrNoHeapPointers(SB)
...
runtime.memclrNoHeapPointers随机遍历 #
rangefunc main() {
hash := map[string]int{
"1": 1,
"2": 2,
"3": 3,
}
for k, v := range hash {
println(k, v)
}
}
2 3 11 2 3$ go run main.go
2 2
3 3
1 1
$ go run main.go
1 1
2 2
3 3
Go 语言在运行时为哈希表的遍历引入了不确定性,也是告诉所有 Go 语言的使用者,程序不要依赖于哈希表的稳定遍历,我们在下面的小节会介绍在遍历的过程是如何引入不确定性的。
5.1.2 经典循环 #
OFORNinitLeftRightNBodyfor Ninit; Left; Right {
NBody
}
cmd/compile/internal/gc.state.stmtOFORfunc (s *state) stmt(n *Node) {
switch n.Op {
case OFOR, OFORUNTIL:
bCond, bBody, bIncr, bEnd := ...
b := s.endBlock()
b.AddEdgeTo(bCond)
s.startBlock(bCond)
s.condBranch(n.Left, bBody, bEnd, 1)
s.startBlock(bBody)
s.stmtList(n.Nbody)
b.AddEdgeTo(bIncr)
s.startBlock(bIncr)
s.stmt(n.Right)
b.AddEdgeTo(bCond)
s.startBlock(bEnd)
}
}
cmd/compile/internal/gc.state.stmt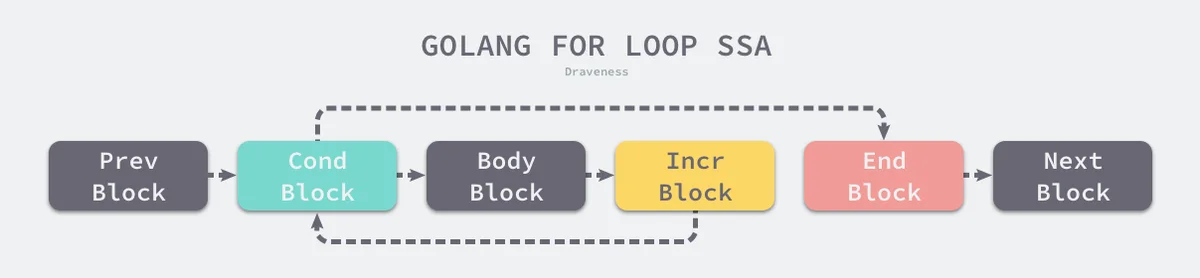
图 5-1 Go 语言循环生成的 SSA 代码
机器码生成阶段会将这些代码块转换成机器码,以及指定 CPU 架构上运行的机器语言,就是我们在前面编译得到的汇编指令。
5.1.3 范围循环 #
forrangeORANGEOFOR
图 5-2 范围循环、普通循环和 SSA
cmd/compile/internal/gc.walkrange数组和切片 #
cmd/compile/internal/gc.walkrangefor range a {}for i := range a {}for i, elem := range a {}func walkrange(n *Node) *Node {
switch t.Etype {
case TARRAY, TSLICE:
if arrayClear(n, v1, v2, a) {
return n
}
cmd/compile/internal/gc.arrayClear// 原代码
for i := range a {
a[i] = zero
}
// 优化后
if len(a) != 0 {
hp = &a[0]
hn = len(a)*sizeof(elem(a))
memclrNoHeapPointers(hp, hn)
i = len(a) - 1
}
runtime.memclrNoHeapPointersruntime.memclrHasPointersORANGELeftRight ha := a
hv1 := temp(types.Types[TINT])
hn := temp(types.Types[TINT])
init = append(init, nod(OAS, hv1, nil))
init = append(init, nod(OAS, hn, nod(OLEN, ha, nil)))
n.Left = nod(OLT, hv1, hn)
n.Right = nod(OAS, hv1, nod(OADD, hv1, nodintconst(1)))
if v1 == nil {
break
}
for range a {}v1 == nilha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
...
}
ORANGEfor i := range a {} if v2 == nil {
body = []*Node{nod(OAS, v1, hv1)}
break
}
v2 == nilfor i := range a {}v1 := hv1ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
v1 = hv1
...
}
上面两种情况虽然也是使用 range 会经常遇到的情况,但是同时去遍历索引和元素也很常见。处理这种情况会使用下面这段的代码:
tmp := nod(OINDEX, ha, hv1)
tmp.SetBounded(true)
a := nod(OAS2, nil, nil)
a.List.Set2(v1, v2)
a.Rlist.Set2(hv1, tmp)
body = []*Node{a}
}
n.Ninit.Append(init...)
n.Nbody.Prepend(body...)
return n
}
这段代码处理的使用者同时关心索引和切片的情况。它不仅会在循环体中插入更新索引的语句,还会插入赋值操作让循环体内部的代码能够访问数组中的元素:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
v2 := nil
for ; hv1 < hn; hv1++ {
tmp := ha[hv1]
v1, v2 = hv1, tmp
...
}
halenv2func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for i, _ := range arr {
newArr = append(newArr, &arr[i])
}
for _, v := range newArr {
fmt.Println(*v)
}
}
&v2&a[index]哈希表 #
runtime.mapiterinitruntime.mapiternextha := a
hit := hiter(n.Type)
th := hit.Type
mapiterinit(typename(t), ha, &hit)
for ; hit.key != nil; mapiternext(&hit) {
key := *hit.key
val := *hit.val
}
for key, val := range hash {}cmd/compile/internal/gc.walkrangeTMAP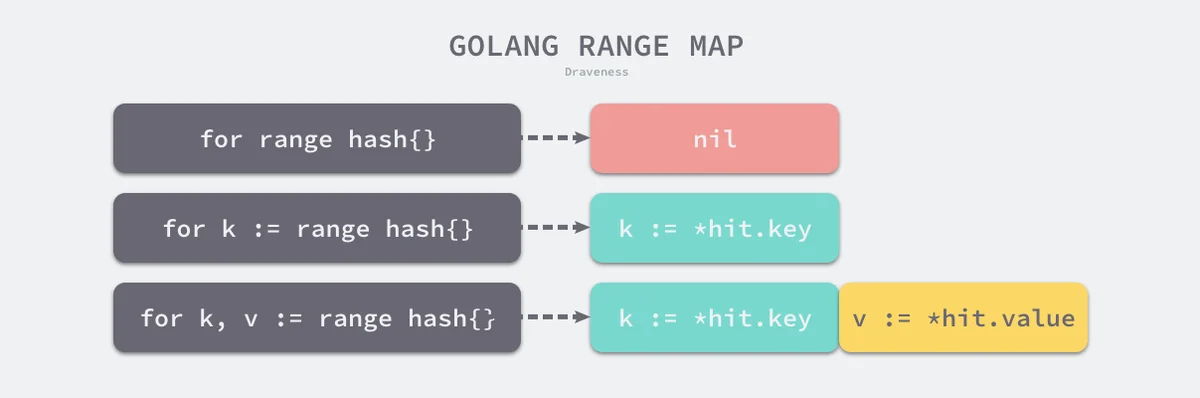
图 5-3 不同方式遍历哈希插入的语句
runtime.mapiterinitfunc mapiterinit(t *maptype, h *hmap, it *hiter) {
it.t = t
it.h = h
it.B = h.B
it.buckets = h.buckets
r := uintptr(fastrand())
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
it.bucket = it.startBucket
mapiternext(it)
}
runtime.hiterruntime.fastrandruntime.mapiternextfunc mapiternext(it *hiter) {
h := it.h
t := it.t
bucket := it.bucket
b := it.bptr
i := it.i
alg := t.key.alg
next:
if b == nil {
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.value = nil
return
}
b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize)))
bucket++
if bucket == bucketShift(it.B) {
bucket = 0
it.wrapped = true
}
i = 0
}
这段代码主要有两个作用:
(nil, nil)runtime.mapiternextruntime.mapaccessK for ; i < bucketCnt; i++ {
offi := (i + it.offset) & (bucketCnt - 1)
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.keysize))
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+uintptr(offi)*uintptr(t.valuesize))
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.reflexivekey() || alg.equal(k, k)) {
it.key = k
it.value = v
} else {
rk, rv := mapaccessK(t, h, k)
it.key = rk
it.value = rv
}
it.bucket = bucket
it.i = i + 1
return
}
b = b.overflow(t)
i = 0
goto next
}
runtime.bmap.overflow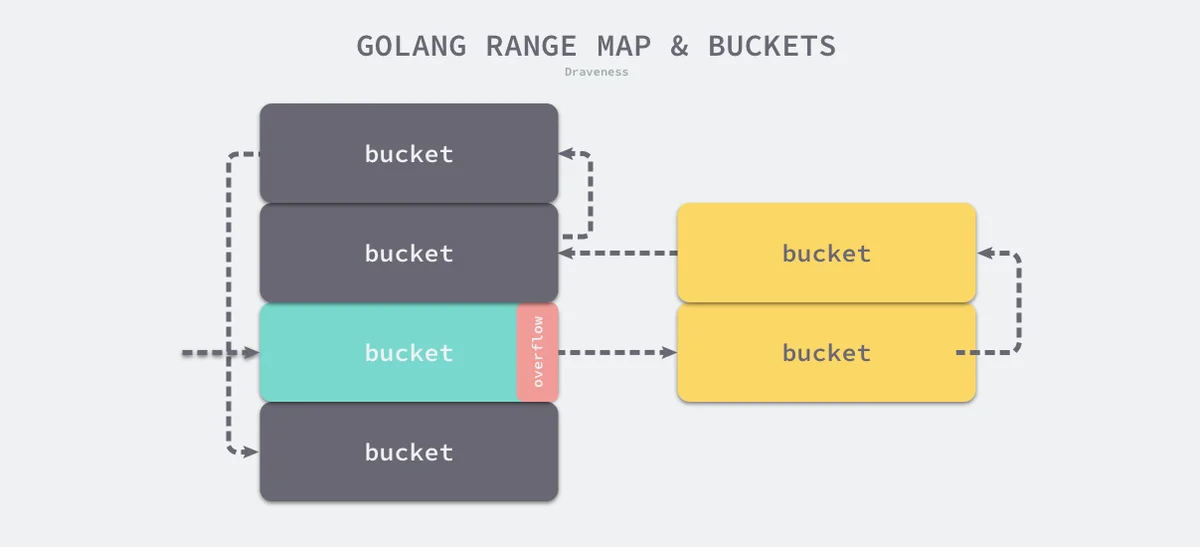
图 5-4 哈希表的遍历过程
简单总结一下哈希表遍历的顺序,首先会选出一个绿色的正常桶开始遍历,随后遍历所有黄色的溢出桶,最后依次按照索引顺序遍历哈希表中其他的桶,直到所有的桶都被遍历完成。
字符串 #
runerunefor i, r := range s {}ha := s
for hv1 := 0; hv1 < len(ha); {
hv1t := hv1
hv2 := rune(ha[hv1])
if hv2 < utf8.RuneSelf {
hv1++
} else {
hv2, hv1 = decoderune(ha, hv1)
}
v1, v2 = hv1t, hv2
}
在前面的字符串一节中我们曾经介绍过字符串是一个只读的字节数组切片,所以范围循环在编译期间生成的框架与切片非常类似,只是细节有一些不同。
runeruneruneruntime.decoderune通道 #
for v := range ch {}ha := a
hv1, hb := <-ha
for ; hb != false; hv1, hb = <-ha {
v1 := hv1
hv1 = nil
...
}
<-chruntime.chanrecv2runtime.chanrecv2hbv1hv15.1.4 小结 #
forrange上一节 下一节