
内容提要
服务注册发现作为微服务的基础组件,它的稳定性和可用性备受考验。在之前的文章中,我们介绍了服务注册中心的基本原理和实现,具体参阅:
分布式集群架构原理 分布式数据复制技术
状态一致性协同算法
Golang 代码实现集群服务
集群待解决问题
要实现注册中心从单机版到分布式集群,有几个关键问题要解决:
集群成员间的关系与成员发现问题 集群成员间数据复制与一致性问题 数据副本机制和数据分区策略
针对上述问题会有不同解决方案,而不同方案会对集群的可用性、容错能力和数据一致性造成不同结果,著名的 CAP 理论就是对分布式问题的最好诠释。架构就是在不同的方案和结果中进行的折中,没有最好的方案,只有适合场景的最佳实践,权衡取舍也是架构之魅力所在。
节点关系与成员发现
架构模型
集群中节点关系可以分为两种:平等公平关系和非公平关系。
P2P (pear to pear)点对点架构就是平等公平关系,这种关系中各节点没有领导分工,大家分摊工作,共同努力完成目标。
技术选型
针对注册中心场景选择哪种架构呢?可以从以下几点分析。
主从架构一般是做读写分离,写主读从(当然也有同步写,后面会分析到),相对来说写性能有限,但可以通过多个从来提升读性能。
注册中心场景一般读多写少,这点上倒也没有绝对的优劣。
2.可用性
主从架构中主挂了会影响写,比如 MySQL 的 MHA,Redis 的 Sentinel 都是用来监控并实现切主,来保障高可用。而像 Zookeeper 支持半数以内的节点挂掉,超过半数就要触发重新选主了,此时不能写入。相比于点对点架构,整体可用性会差一点。
CAP 理论告诉我们,分布式系统在一致性(Consistency)、可用性(Availability) 和分区容错性 (Partition tolerance)三者只能选其二。在集群正常情况下,一致性和可用性都没问题(也就是 CA,网上大多数文章说 CA 模型不存在,其实说法并不准确,在正常情况下,一致性和可用性还是可以同时保障的)。但当集群出现异常,分区容错性必须保障(想想为什么?),那么一致性和可用性就要二选一,选 AP 还是 CP?
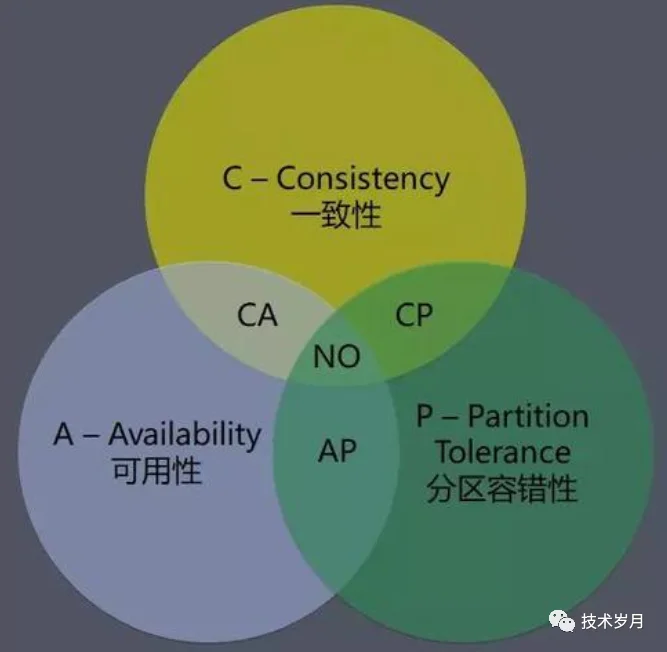
(CAP 理论 图片来自网络)
3.架构实现
点对点架构实现相对更简单,不用考虑选主或主从切换的问题,节点状态也只要考虑上线状态和下线状态即可;
而领导者协调者架构在实现实现选主时要应对复杂的一致性协同算法,维护更复杂的状态机。
集群架构设计
我们来看点对点集群架构图:

(注册中心集群点对点架构图)
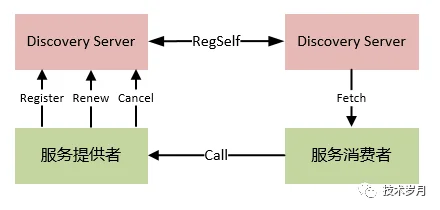
(注册中心集群节点自发)
代码实现
下面我们通过具体代码来展开讲解实现原理。首先我们定义节点的概念和结构体,一个节点就是一个独立的注册中心服务,集群由多个节点组成。结构体 Node 存储节点地址和节点状态,节点状态有两种:上线状态(可对外提供服务),下线状态(不对外服务)。
type Node struct {
config *configs.Config
addr string
status int
}
func NewNode(config *configs.GlobalConfig, addr string) *Node {
return &Node{
addr: addr,
status: configs.NodeStatusDown, //初始化设为下线状态
}
}(代码 model/node.go)
结构体 Nodes 用于存放所有节点列表和当前节点地址,方便节点初始化和节点感知。
type Nodes struct {
nodes []*Node
selfAddr string
}
//初始化默认从配置文件中加载节点信息
func NewNodes(c *configs.GlobalConfig) *Nodes {
nodes := make([]*Node, 0, len(c.Nodes))
for _, addr := range c.Nodes {
n := NewNode(c, addr)
nodes = append(nodes, n)
}
return &Nodes{
nodes: nodes,
selfAddr: c.HttpServer,
}
}
(代码 model/nodes.go)
type Discovery struct {
config *configs.GlobalConfig
protected bool
Registry *Registry
+ Nodes atomic.Value
}
func NewDiscovery(config *configs.GlobalConfig) *Discovery {
//...
+ dis.Nodes.Store(NewNodes(config))
}
(代码 model/discovery.go)
func (dis *Discovery) regSelf() {
now := time.Now().UnixNano()
instance := &Instance{
Env: dis.config.Env,
Hostname: dis.config.Hostname,
AppId: configs.DiscoveryAppId, //Kavin.discovery
Addrs: []string{"http://" + dis.config.HttpServer},
Status: configs.NodeStatusUp,
RegTimestamp: now,
UpTimestamp: now,
LatestTimestamp: now,
RenewTimestamp: now,
DirtyTimestamp: now,
}
dis.Registry.Register(instance, now)
//注册后同步到其他集群,下面部分会展开讲解
dis.Nodes.Load().(*Nodes).Replicate(configs.Register, instance)
}
(代码 model/discovery.go)
func (dis *Discovery) renewTask(instance *Instance) {
now := time.Now().UnixNano()
ticker := time.NewTicker(configs.RenewInterval) //30 second
defer ticker.Stop()
for {
select {
case <-ticker.C:
_, err := dis.Registry.Renew(instance.Env, instance.AppId, instance.Hostname)
if err == errcode.NotFound {
dis.Registry.Register(instance, now)
dis.Nodes.Load().(*Nodes).Replicate(configs.Register, instance)
} else {
dis.Nodes.Load().(*Nodes).Replicate(configs.Renew, instance)
}
}
}
}
(代码 model/discovery.go)
节点如果要进行下线操作,会先进行节点注销操作,在项目 main() 中增加注销自己的代码,实现比较简单,可直接参考代码:Discovery.CancelSelf(),代码可通过本公众号“技术岁月”发送“注册发现”获取。
func main() {
//graceful restart
quit := make(chan os.Signal)
signal.Notify(quit, syscall.SIGINT, syscall.SIGTERM, syscall.SIGHUP, syscall.SIGQUIT)
<-quit
log.Println("shutdown discovery server...")
//cancel
++ global.Discovery.CancelSelf()
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
}
节点的状态变更感知,用于维护集群节点的上下线,从节点注册表中拉取 AppId 为 Kavin.discovery 的数据,然后通过该数据中的实例信息来维护节点列表。
func (dis *Discovery) nodesPerception() {
var lastTimestamp int64
ticker := time.NewTicker(configs.NodePerceptionInterval)
defer ticker.Stop()
for {
select {
case <-ticker.C:
fetchData, err := dis.Registry.Fetch(dis.config.Env, configs.DiscoveryAppId, configs.NodeStatusUp, lastTimest
amp)
if err != nil || fetchData == nil {
continue
}
var nodes []string
for _, instance := range fetchData.Instances {
for _, addr := range instance.Addrs {
u, err := url.Parse(addr)
if err == nil {
nodes = append(nodes, u.Host)
}
}
}
lastTimestamp = fetchData.LatestTimestamp
config := new(configs.GlobalConfig)
*config = *dis.config
config.Nodes = nodes
ns := NewNodes(config)
ns.SetUp()
dis.Nodes.Store(ns)
}
}
}
(代码 model/discovery.go)
数据副本与数据一致性
数据模型一般会有副本和分区两种形式,分区我们等会讨论,先说说副本机制。
所谓副本机制 Replication,是指分布式系统在各节点上保存相同的数据拷贝,来达到备份的目的。
副本提供了几个好处:数据冗余;可伸缩性;改善数据局部性。在点对点架构中,每个节点都是一个独立的数据副本,这样某个节点出事不会影响别人,还可通过扩充节点提升可用性,抗住更大并发。
多副本最大的困扰,就是数据的一致性了,上面我们分析了 CAP,明确了使用 AP 模型,成员间数据虽然不能做到强一致性,但怎么保障最终一致性呢?这里考虑如下几点:
服务启动时当前节点数据为空,需要同步其他节点数据
某节点接收到服务最新数据变更,需要同步给其他节点
节点间数据不一致性如何“反熵”
节点启动时注册表初始化
节点首次启动时,其注册表是空的,那么就要想办法从其他节点同步数据。其逻辑就是遍历所有节点,获取注册表数据,依次注册到本地。这里注意只有当所有数据同步完毕后,该注册中心才可对外提供服务,切换为上线状态。
func (dis *Discovery) initSync() {
nodes := dis.Nodes.Load().(*Nodes)
for _, node := range nodes.AllNodes() {
if node.addr == nodes.selfAddr {
continue
}
uri := fmt.Sprintf("http://%s%s", node.addr, configs.FetchAllURL)
resp, err := httputil.HttpPost(uri, nil)
if err != nil {
log.Println(err)
continue
}
var res struct {
Code int `json:"code"`
Message string `json:"message"`
Data map[string][]*Instance `json:"data"`
}
err = json.Unmarshal([]byte(resp), &res)
if err != nil {
log.Printf("get from %v error : %v", uri, err)
continue
}
if res.Code != configs.StatusOK {
log.Printf("get from %v error : %v", uri, res.Message)
continue
}
dis.protected = false
for _, v := range res.Data {
for _, instance := range v {
dis.Registry.Register(instance, instance.LatestTimestamp)
}
}
}
nodes.SetUp()
}
(代码 model/discovery.go)
这里考虑到节点数据可能不一致,循环同步了所有节点数据来提高一致性,相应的会有网络 io 开销与浪费,在一致性和资源开销上做了取舍选择。
注册表数据变更时同步
Gossip 过程是由种子节点发起,当一个种子节点有状态需要更新到其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到消息。
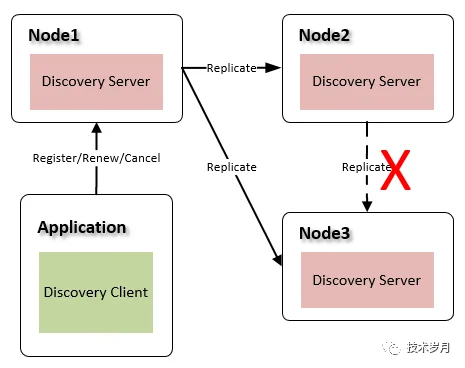
(当前节点发起广播同步数据)
关于数据更新还要多做一些说明,这里我们是更新完当前节点,即代表写入完成,此时可以通过该节点获取最新数据,而同步其他节点并没做检查,也就是说其他节点在同步完成前,获取的数据可能不一致。如果在同步前当前节点挂了,可能这次操作会丢失,我们并没有采用同步写模式,采用了弱一致性策略。
如果我们要强一致性怎么做呢?在数据写入当前节点并完成同步之前,所有节点数据不可读或仍读取之前版本数据(快照/多版本控制)。
在数据复制技术中,有同步复制、异步复制、半同步复制技术,对应的响应延迟时间(可用性)和一致性也会有差别。
来看具体代码实现,以服务注册为例,在 RegisterHandler 中,增加数据同步的逻辑,将数据变动同步给其他节点。
func RegisterHandler(c *gin.Context) {
//...
+ if req.Replication {
+ global.Discovery.Nodes.Load().(*model.Nodes).Replicate(c, configs.Register, instance)
+ }
}(代码 api/handler/register.go)
在 Replicate 方法中,遍历所有的节点,依次执行注册操作。
func (nodes *Nodes) Replicate(c *gin.Context, action configs.Action, instance *Instance) error {
if len(nodes.nodes) == 0 {
return nil
}
for _, node := range nodes.nodes {
if node.addr != nodes.selfAddr {
go nodes.action(c, node, action, instance)
}
}
return nil
}
func (nodes *Nodes) action(c *gin.Context, node *Node, action configs.Action, instance *Instance) {
switch action {
case configs.Register:
go node.Register(c, instance)
case configs.Renew:
go node.Renew(c, instance)
case configs.Cancel:
go node.Cancel(c, instance)
}
}
(代码 model/nodes.go)
func (node *Node) Register(c *gin.Context, instance *Instance) error {
return node.call(c, node.registerURL, configs.Register, instance, nil)
}
func (node *Node) call(c *gin.Context, uri string, action configs.Action, instance *Instance, data interface{}) error {
params := make(map[string]interface{})
params["env"] = instance.Env
params["appid"] = instance.AppId
params["hostname"] = instance.Hostname
params["replication"] = true //broadcast stop here
switch action {
case configs.Register:
params["addrs"] = instance.Addrs
params["status"] = instance.Status
params["version"] = instance.Version
params["reg_timestamp"] = strconv.FormatInt(instance.RegTimestamp, 10)
params["dirty_timestamp"] = strconv.FormatInt(instance.DirtyTimestamp, 10)
params["latest_timestamp"] = strconv.FormatInt(instance.LatestTimestamp, 10)
case configs.Renew:
params["dirty_timestamp"] = strconv.FormatInt(instance.DirtyTimestamp, 10)
case configs.Cancel:
params["latest_timestamp"] = strconv.FormatInt(instance.LatestTimestamp, 10)
}
resp, err := httputil.HttpPost(uri, params)
if err != nil {
return err
}
res := Response{}
err = json.Unmarshal([]byte(resp), &res)
if err != nil {
return err
}
if res.Code != configs.StatusOK {
json.Unmarshal([]byte(res.Data), data)
return errcode.Conflict
}
return nil
}(代码 model/node.go)
如果是续约事件丢失,可以在下一次续约时补上; 如果是注册事件丢失,也可以在下次续约时发现并修复(NotFound 逻辑);
如果是取消事件丢失,长时间不续约会有剔除。
最终一致性保障
自测方案
我们准备 3 个配置,搭建 3 个节点,通过静态配置集群节点列表。
nodes: ["localhost:8881", "localhost:8882", "localhost:8883"]http_server: "localhost:8881" //其他节点配置8882和8883hostname: "sd1" //其他节点配置sd2和sd3
数据分区策略
分区有不同的描述,如 Kafka 叫分区 Partitioning,而 MySQL 中叫分表,在 MongoDB、Elasticsearch 又叫分片 Shard,HBase、Tidb 中叫 Region,虽然实现原理可能不尽相同,但底层数据分区的思想却是一致性的。
注册中心可以实现划分区域 zone 的机制,zone1 保存服务 A、B、C,zone2 保存服务 D、E、F,来实现数据分区治理。
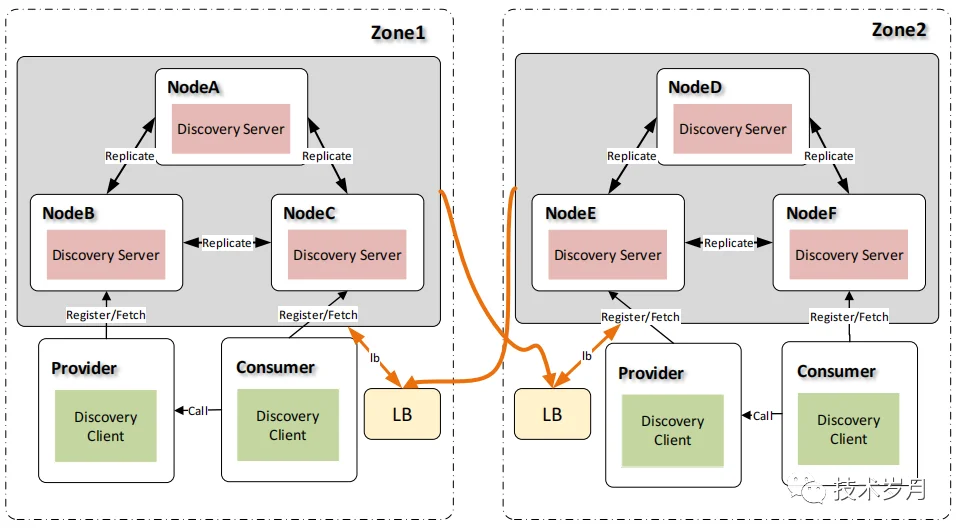
(多注册中心数据分区)
总结
本文实现了注册中心的集群版,在集群实现过程中,先明确了点对点的平等架构方式,并通过复制技术实现各副本间一致性问题,也说明了在可用性和一致性问题上做的取舍。
感谢您的阅读,欢迎点赞、转发