
前言
感谢哔哩哔哩领导和同事对我的工作支持和配合!!!
也感谢业界各位大佬对这篇文章的喜爱与支持,以及对技术的追求与执着!!!
引言
随着对业务理解的不断深入和抽象,可以发现很多业务场景的功能(代码)都可以抽象成“规则+指标”的模式。这种模式,可以应用于很多场景,如:
1.风控场景,识别黑产,需要各种规则来进行判别;
2.流量(内容)分发场景,需要基于各种可收集的指标,组成规则,然后基于规则,来对用户进行定制化的内容分发;
3.推荐场景,推荐本身就是一个基于多指标的典型规则场景模式(或者说,机器学习就是一个收集数据指标,然后进行学习,最后进行推广的过程)。
4.数据清洗场景,有些业务数据需要使用规则进行打标、清洗、识别,最后落表使用。
有规则,有指标了,当然还需要一个可以执行规则的引擎。
一、规则引擎的发展历程
1.1 第一代规则引擎
仅支持逻辑运算符(&&, ||, !, 外加括号 ),主要是用来解析逻辑表达式,通过定义特定占位符,来绑定具体的子操作,然后使用子操作的结果来进行逻辑运算,并得到整个逻辑表达式的最终结果。
如,逻辑表达式规则: "$1 && $2", $1 和 $2 占位符(也叫指标), 接受规定个数的参数,然后分别输出 true 或 false,逻辑表达式再对占位符的结果进行完整的逻辑运算,并得到最终的结果。
第一代规则引擎特点:
a. 简单,因为简单,所以执行性能相当好;
b. 扩展能力弱,可以满足逻辑判别要求,但无法满足数值判别要求;
c. 工程需要重新发版,当添加新的占位符运算时,工程需要重新发版。
d. 不利于记忆,这种规则表现形式,不利于人记忆,时间久了,要搞清楚占位符代表的是什么,还要回头去看当初写的文档。
1.2 第二代规则引擎
基于某些解释型语言的规则引擎,如 java 支持的 javascript 的执行引擎,那么规则的编写语言就是 javascript,写规则就是在写 javascript。规则引擎就是 java 虚拟机支持的 javascript 执行引擎本身。
第二代规则引擎特点也很明显:
a. 表现能力强,所引入的解释型语言有多强,规则表现能力有多强。
b. 无需重新发版。
c. 执行性能略差。
d. 业务逻辑逃逸,业务逻辑从主语言"逃逸"到规则配置语言中,不利于逻辑梳理与迁移或反向迁移。
e. 接入成本高,使用复杂,使用者(常常是数据挖掘、数据分析、产品等人员,他们常常缺乏代码能力)为了配置几个规则,不得不花很多精力去学习一门语言,即使开发者自身,如果不熟悉规则配置语言,也一样要去学习。如此一来,规则的配置难度和使用成本极大,以致于难以推广;毕竟,如果都学会了这门语言,我何不直接撸代码呢?那样性能还高,也直接。
1.3 第三代规则引擎
为了延续规则的表现能力,同时为了降低规则的配置难度,且免于学习一门新语言的代价,第三代规则引擎将实现规则引擎自身的语言作为规则配置语言,同时还加入了一些有用的规则属性,如“规则名称”、“规则优先级”、“规则描述”等。
第三代规则引擎的典型代表是 java 实现的 drools。
第三代规则引擎的特点是:
a. 规则表现力强,可基于用户指定的规则优先级,来先后执行规则;
b. 配置简化,简化了一些复杂的且不必要的语法。
c. 对开发友好,对配置规则者不友好, 第三代规则引擎适合熟悉规则引擎开发语言自身的开发人员使用,但当推广至其他人员使用时,依旧免不了要让不熟悉此语言的人重新学习一门语言(规则配置复杂度并没有真正消除);
d. 性能偏弱,不能完全满足实时、高性能服务场景的需求(具体见下文举例)。
二、规则的执行模式
通过对各种业务场景的分析提炼,一个规则引擎至少应该满足 3 种执行模式。但实际上,规则执行模式至少有 5 种,具体执行模式,我归纳如下图所示:
2.1 顺序模式

如上图,规则的顺序模式(sort model)
规则优先级高越高的越先执行,规则优先级低的越后执行。这也是 drools 支持的模式。此模式的缺点很明显:随着规则链越来越长,执行规则返回的速度也越来越慢。
2.2 并发执行模式
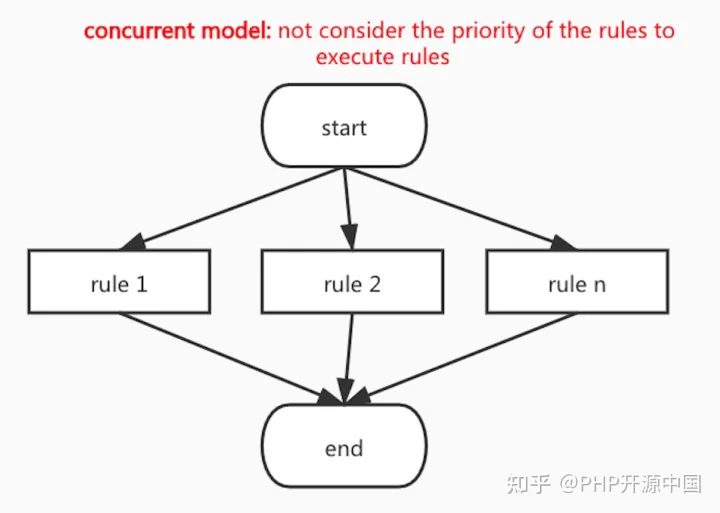
如上图,规则的并发执行模式(concurrent model)
在此执行模式下,多个规则执行时,不考虑规则之间的优先级,规则与规则之间并发执行。规则执行的返回的速度等于所有规则中的执行时间最长的那个规则的速度(逆木桶原理)。执行性能优异,但无法满足规则优先级。
2.3 混合执行模式
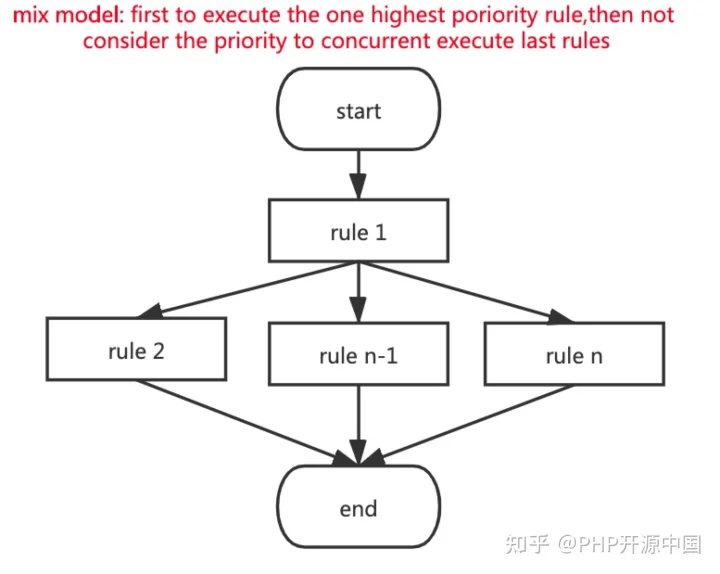
如上图,规则的混合执行模式(mix model)
规则引擎选择一个优先级最高规则的最先执行,剩下的规则并发执行。规则执行返回耗时= 最高优先级的那个规则执行时间 + 并发执行中执行时间最长的那个规则耗时;此模式兼顾优先级和性能,适合于有豁免规则(或前置规则)的场景。
2.4 逆混合模式
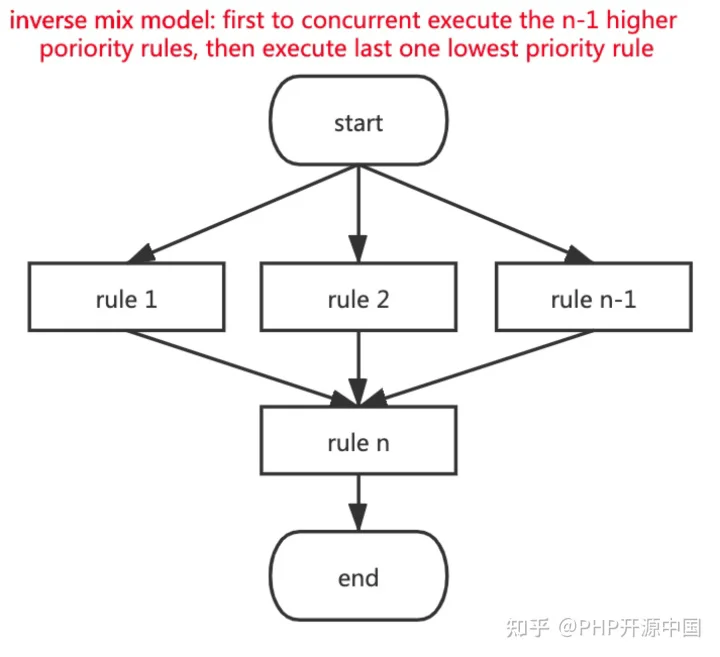
如上图,规则的逆混合执行模式(inverse mix model)
优先级最高的 n-1 个规则并发执行,执行完毕之后,再执行剩下的一个优先级最低的规则。这种模式适用于有很多前导判断规则的场景。其特性与混合模式类似,兼顾性能和优先级。
2.5 桶模式
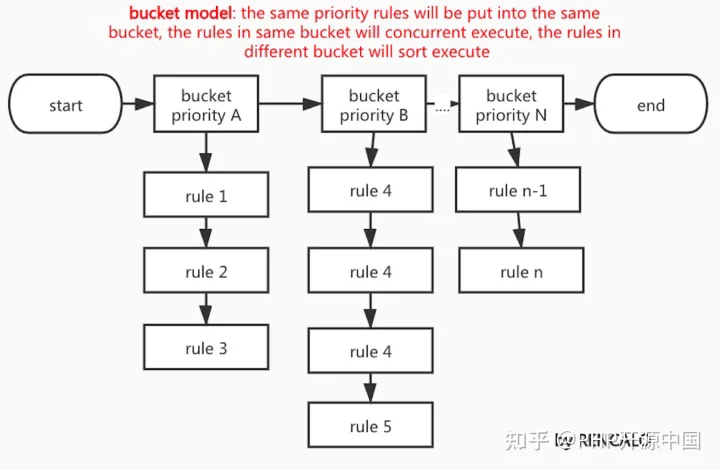
如上图,规则执行的桶模式
名字源于《算法导论》中的桶排序。规则引擎基于规则优先级进行分桶,优先级相同的规则置于同一个桶中,桶内的规则并发执行,桶间的规则基于规则优先级顺序执行。
一个小故事:
我当年考研究生(跨专业)的时候,研究生的卷子上有一个桶排序的考题,因为自己复习不到位,导致自己没做出来。后来考完了,去翻《算法导论》才搞清楚这个算法是怎么回事。从此以后,我就记住了有这么一种排序,叫桶排序。只是当初没有想到的是,它曾经绊倒过我,但也会在未来的某一天,激发我创造出新的东西。
三、B 站新一代规则引擎设计实现
3.0 起个名字
以 golang 开发,以引擎(engine)为核心,所以就叫 gengine 吧!
3.1 背景
目前大部分业务线,尤其是以 golang 为开发语言的业务线,基本上使用的是第一代规则引擎,此中原因,无非是因为当前的 golang 生态不够完善,如果基于其他语言创造相同的轮子,golang 又没有相应的语言的某些特性支持,抑或开发人员对其他语言的某些框架根本不甚了了。
公司的少部分以 java 为主要开发语言的业务线,使用的规则引擎是 drools。
在业务发展的初期,业务少且简单(无需复杂的规则),并发量也不高,所以选择使用第一代规则引擎或者 drools,基本是合情合理的。
但随着业务发展,业务日趋复杂,业务请求并发的显著提升,基于第一代引擎的规则迭代周期长、开发新规则(新指标)的就要重新编码开发,指标难以复用、且每次上线规则必须重启(增加了服务的不稳定性和崩溃率)。因此有必要开发出一套能满足业务快速迭代、健壮、高性能的规则引擎。
3.2 我们预期的规则引擎的样子
1.支持规则优先级 新的同类型的产品,不应该丢掉老版产品的优点,这些优点不仅是优点,还是一种业务开发财产。
2.使用足够简单、灵活。这个要求,对规则在配置上的难易程度提出了要求。本质上是提出了规则 与具体代码之间的界限划分。
第一代规则引擎,足够简单,但没有包含规则表现业务的必要成分,所以注定要被代替。
第二代和第三代规则引擎,很灵活多了,但没有划分清楚规则与具体的代码语言之间的界限,导致他们使用起来注定过于复杂。尤其是你将规则配置工作交给产品、数据分析、数据挖掘的同学,让他们(代码真的不是他们的强项:不要对外界条件给予过高期望;不要相信用户输入)来使用规则和指标来表现他们所做的工作的时候,注定会导致各种个样的问题发生。
所以,如果要足够简单,且足够灵活,我们的目标不仅是让程序员觉得使用简单,还要让无代码开发经验的产品、运营、数据挖掘、数据分析的同学也能觉得使用简单,让他们几乎不需要学习,便能自主配置规则,以此来完成不同领域的业务需求。
通过对代码的分析与抽象,我们发现,所有的代码逻辑由这四种成分构成:逻辑运算,四则运算,if..else 选择分支结构,接口 API 调用。
3.可选择的规则执行模式。因为通过观察各个场景发现,没有一种执行模式是万能的,无论是基于性能考量,还是基于业务本身考量,不同的场景需要不同的执行模式。
4.高性能。这当然是最重要的,如果不能满足高性能,高并发的需求,最终还是会被扔到历史的垃圾堆中。
5.和 golang 的无缝对接。因为 B 站业务开发是以 golang 为主要开发语言,因此,开发的规则引擎必须要要能和 golang 无缝对接才行。
6.其他的小确幸:支持注释,变量...等等
3.3 基于 golang 与 AST 的规则引擎实现
第一代规则引擎解析简单的逻辑表达式,有的是基于正则实现,有的是基于简单的 AST(抽象语法树)实现的。如果是简单的逻辑表达式,正则是足够用的。如果仅用 AST 来解析逻辑表达式,显然有点大材小用。
为了不让抽象语法树(AST)屈才,也受此启发,我们最终选用了基于 AST 来方式来解析和执行具体的规则语法。我们实现规则引擎时所用到的具体技术如下:
a.基于 Antlr4 来自定义规则的语法,最终生成语法树结构
b.基于 golang 的反射技术来实现对用户自定义 API 的调用
c.基于 golang 的并发编程技术来实现高性能的规则执行能力