重试与超时是并发系统必备的服务,重试是一种保障服务机制,利用重试可以解决网络波动、数据包丢失等问题导致的服务失败。超时则类似于一种兜底机制,如果服务端出现系统饱和的问题,我们应该在等待一个时间后停止运行,而不是无条件等待下去,此外超时还可以解决死锁问题,因为等待一段时间后,至少会有一方提前退出。
重试
基础重试
其实使用最简单的for-loop循环就可以完成重试,这是一种最原始的机制。利用一个计数器,如果函数成功运行了则提前退出,否则当函数超时或者已经重试设置的次数后就返回错误。
Context重试
我们还可以结合Context包与超时机制,进行重试。在不考虑协程切换时间的情况下,如果执行dosomething函数失败了,协程会等待五秒时间继续执行for循环,等到外部的ctx超时关闭为止。通过该模式,我们只要设定context.WithTimeout和time.after内的时间,就可以设置重试的次数
重试框架
其实,重试是一个研究时长较为悠久,也有比较完备算法的知识点。当我们编写重试框架,或者在程序中添加重试模块时,需要重点考虑的问题包括:
- 什么样的错误需要重试
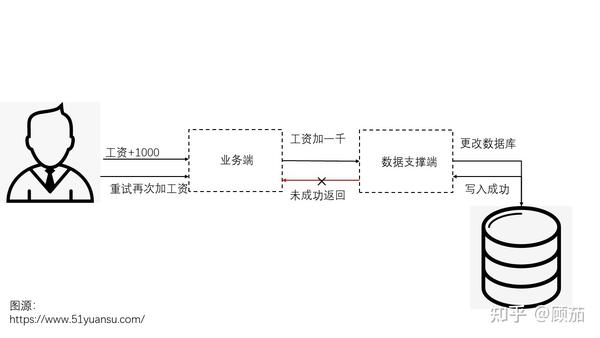
重试的本质就是在请求失败后,重新进行一次或者数次请求。但是如果是因为负载过大出现请求失败时,我们使用重试反而会适得其反,并且会有请求放大的现象。假设在一个系统中,我们请求获取用户数据,然后业务端调用rpc寻找下游的数据支撑服务端,数据服务端再调用更下游的数据库进行数据查找。如果此时的错误是数据库负载压力过大,且各端都带有重试机制,那么各端的重试次数都是10。业务端重试10次,rpc端就要重试100次,这样到数据库的请求就变成了一千次。已经难以承受负载的数据端就因为一次没有响应就要增加1000次的响应压力。
在这种情况下,熔断、超时等手段是更好的解决方案。
2.重试的间隔如何选择
如果请求失败了,我们该在何时选择重试呢?立即重试和延后固定时间重试是最容易想到的方案,无论是网络问题还是服务拥塞,立即重试大概率还是失败。延后固定时间重试能解决网络问题,但是面对服务拥塞问题却无能为力。因为这等价于将大量请求延后固定时间继续执行,这样在一段时间后,服务器仍然会收到大量请求。另一种解决方案是在延后一个随机时间。这个随机事件有许多经典的算法,指数回避是其中的代表算法。
这里罗列出两个go语言的经典重试框架,供大家参考。
retry-go
retry-go是一个较轻量级且非常简洁的框架。在do函数中传入重试函数并传递一系列重试的配置就可以执行
backoff则是Google提供的指数回避算法的java实现版,整体设计较为复杂。
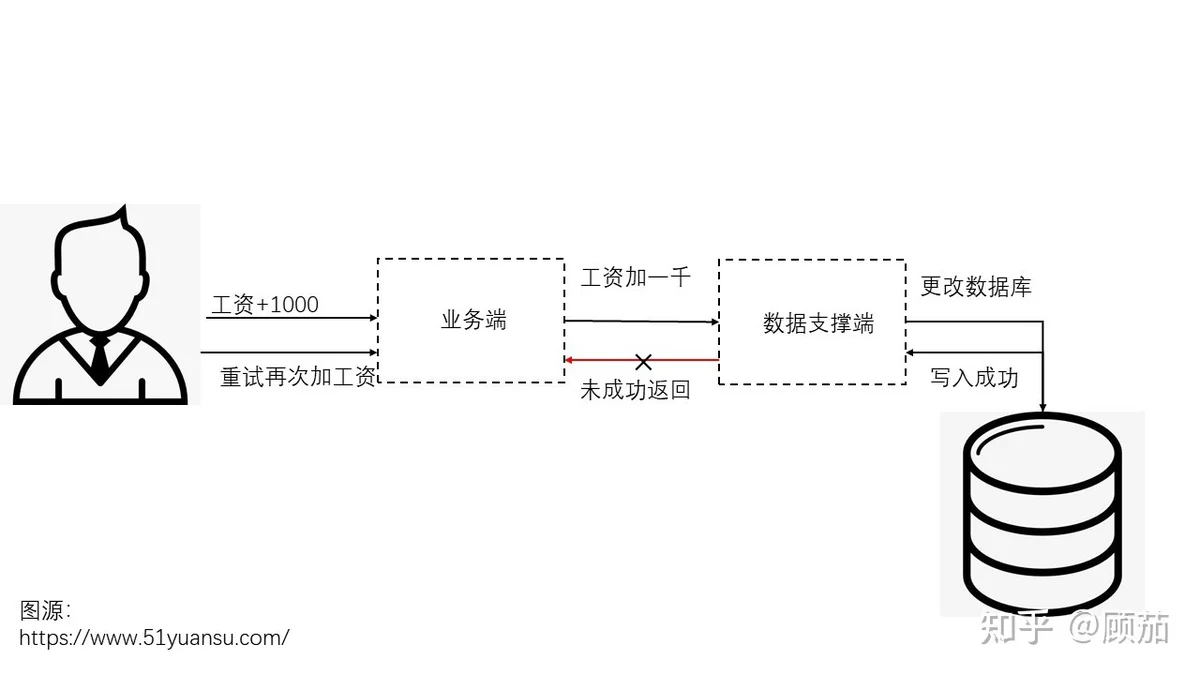
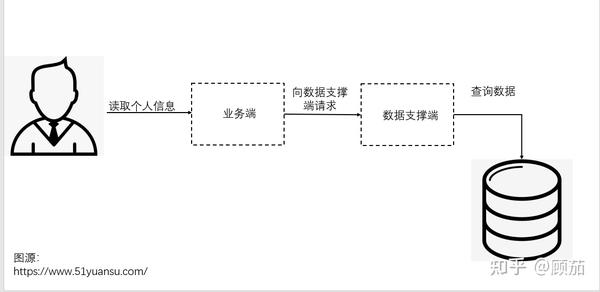
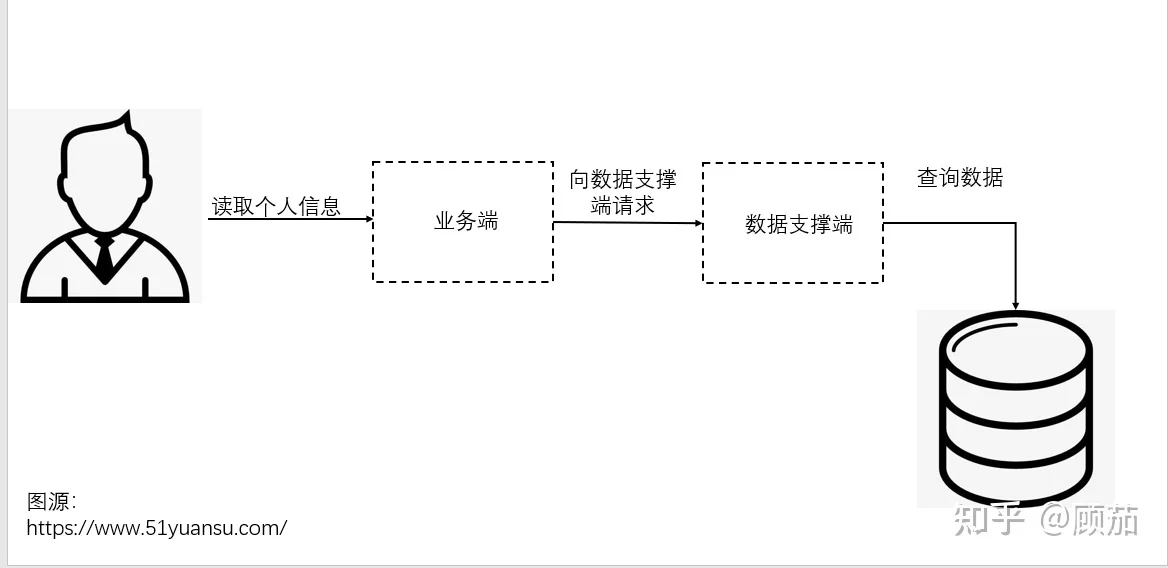
重试还需要考虑许多其他元素,比如幂等性的保证。比如下图,可能数据库已经成功返回了正确的信息,但是由于网络问题没有成功传递到上游,这时候就得保证操作可以回退。因此,使用重试时结合操作是否幂等和系统的支持程度来综合考虑。