
@
数据集合数组
数组(Array):拥有零个或多个相同数据类型元素的有序序列
1)数组属于静态数据结构(长度固定),且通过下标访问(从0开始);
2)数组的元素类型若是可比较的,则数组就是可比较的;
3)Go支持多维数组;
//len(数组名)可返回数组中元素的个数
数组的定义格式分为2种:var关键词、短变量
var 数组名 [长度]数据类型 = [长度]数据类型{初始值1,初始值N}1)若仅声明数组,可省略“=”以后的内容(包括等号);
2)等号前后的长度和数据类型需保持一致(且长度必须是常量表达式);
…4)未指定初始值的元素,默认为对应数据类型的零值;
5)可指定下标对特定的元素进行初始化;
数组名 := [长度]数据类型{初始值1,初始值N}…2)未指定初始值的元素,默认为对应数据类型的零值;
3)可指定下标对特定的元素进行初始化;
如:声明两个数组并传递给函数进行修改,并输出结果
1)编写程序;
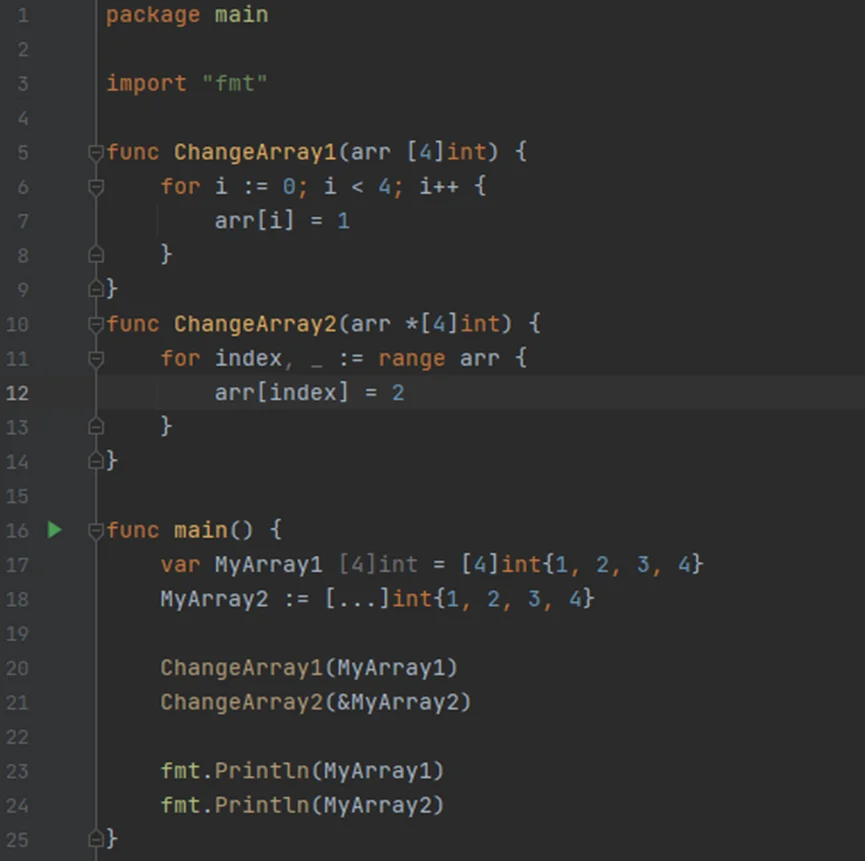
2)运行结果;

//数组在当成函数参数传递时,默认传递形式为值传递(可通过指针更改)
slice
切片(slice):拥有零个或多个相同数据类型元素的有序序列
1)本质:数组的部分或全部元素(底层由数组实现);
2)动态数据结构(长度不固定),且通过下标访问(从0开始);
3)多个Slice可共用同一个底层数组(存在修改对方数据的风险);
//Slice是不可做比较的,其零值是nil(代表其长度和容量均为0)
Slice的3个属性:指针、长度和容量
1)指针:指向底层数组中Slice的第一个元素(起始元素)
2)长度:Slice中的元素个数,不能超过容量
3)容量:Slice的底层数组长度
//len(切片名)获得Slice长度,cap(切片名)获得Slice容量
Slice的定义格式分为5种:
var 切片名 []数据类型1)该方式创建的切片称为“nil切片”(无需内存分配);
2)nil切片不等同于空切片,空切片无元素但占用内存;
3)创建多维切片时,仅需指定一次数据类型(最后指定,数组同理);
//需创建无元素切片时,应选择nil切片
切片名 := []数据类型{初始值1,初始值N}1)该方式创建切片的长度和容量等同于其指定的初始值个数;
切片名 := 其他数组或切片[索引1:索引2]1)该方式创建的切片将于基于对象共享底层数组;
2)基于数组定义的切片,其从索引2到最后的中间位均作为切片的容量;
切片名 := 其他数组或切片[索引1:索引2:索引3]1)索引3用于指定新切片的容量(索引1到索引3中间的位);
2)若追加元素时超过容量,则会进行扩容(而不是覆盖原数组/切片);
3)仍共享部分底层数组,且该方式只有索引1可省略;
切片名 := make([]数据类型,长度,容量)1)若省略容量,则容量默认等同于长度
2)本质:由make()函数创建一个匿名数组,并返回基于该数组的Slice
如:声明个Slice并传递给函数进行修改,并输出结果
1)编写程序;
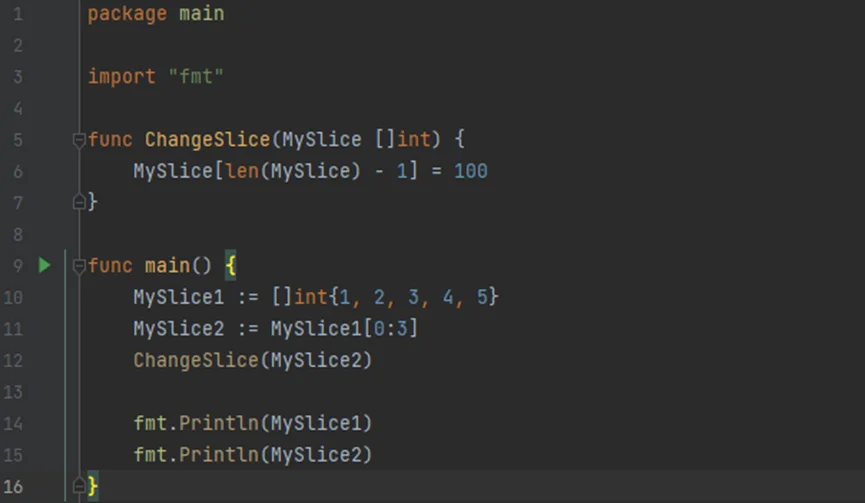
2)运行结果

//Slice在当成函数参数传递时,默认传递形式为引用传递
实现原理
runtime/slice.go中slice的数据结构定义:
type slice struct {
array unsafe.Pointer // 指向底层数组指针
len int // 切片长度
cap int // 切片容量
}
1)创建切片的本质:初始化slice结构体(内部调用make()函数实现);
2)调用len()和cap()函数查询切片的时间复杂度均为O(1);
3)切片间赋值的本质:更改对方的底层数组指针和长度;
//所以切片间赋值只能实现浅拷贝(但发生元素更改时会重建底层数组)
append
append():向指定Slice中添加元素
1)默认添加到该数据集合的末尾处;
2)若添加元素超过已有容量,则通过make()函数重新创建新的底层数组;
3)基于原数组重新创建Slice,且新容量遵守以下标准:
| 条件 | 结果 |
|---|---|
| 2 * 原容量 < 所需容量 | 新容量 = 所需容量 |
| 原容量 < 1024 | 新容量 = 2 * 原容量 |
| 原容量 > 1024 | 新容量 = 1.25 * 原容量 |
切片 = append(切片,元素1, 元素N)append(切片1, 切片2...)2)若只添加切片2的部分元素,可指定切片2的索引(规定区间)
...//通过切片添加时,每次仅能指定单个切片
使用append()函数在Slice中插入元素格式:
切片 = append(切片[:i], append([]数据类型{值1, 值N}, 切片[i:]...)...)1)插入位置为i;
2)Slice中插入元素会导致Slice的重新创建;
添加数据导致的扩容流程:
1)根据预估容量申请更大快内存用于创建底层数据;
2)将原切片中数据拷贝至新切片,并返回新切片;
3)将添加数据追加至新切片;
如:向Slice添加两次元素,观察其长度和容量的变化
1)编写程序;
package main
import (
"fmt"
)
func main() {
MySlice := make([]int, 5, 6)
fmt.Println(len(MySlice), cap(MySlice))
MySlice = append(MySlice, 5)
fmt.Println(len(MySlice), cap(MySlice))
MySlice = append(MySlice, 6)
fmt.Println(len(MySlice), cap(MySlice))
}
2)运行结果;

//建议每次创建切片时,指定其容量以减少切片扩容时内存分配和拷贝次数
//只要修改Slice的容量就会导致底层数组的重新创建和元素复制
copy
copy():将源Slice的元素复制到目标Slice中
1)仅能应用于拥有相同类型元素的Slice;
2)返回实际复制成功的元素个数(长度较小的Slice值);
3)若两个Slice的长度不一致,则默认按照长度较小的Slice进行复制;
//其他方式对Slice的复制均为浅复制(仅copy()函数为深复制)
copy(目标Slice, 源Slice)1)若目标Slice已存在数据,则会被源Slice数据会覆盖;
如:将已有的Slice复制到新Slice
1)编写程序;
package main
import (
"fmt"
)
func main() {
MySlice1 := []string{"ma", "wen", "long"}
MySlice2 := make([]string, 2)
num := copy(MySlice2, MySlice1)
fmt.Println(MySlice1, MySlice2, num)
}
2)运行结果;

map
字典(map):拥有零个或多个键值对类型的无序序列(Key-Value)
1)动态数据结构(长度不固定),且通过键访问;
2)map中所有的键拥有相同数据类型,且键具有唯一性;
3)map中所有的值拥有相同的数据类型,且可通过对应的键修改;
4)map类型的零值是nil,且map是不可比较的;
5)len()函数可返回包含的键值对数;
map的初始化格式分为两种:make()函数、map关键词
1)键的数据类型必须是可比较的;
2)也可使用var关键词定义(未初始化,值为nil);
(1)初始化map(make()函数):
字典名 := make(map[键数据类型]值数据类型)1)该格式仅用于创建空字典;
(2)初始化并定义map(map关键词):
字典名 := map[键数据类型]值数据类型 {
“键1”: “值1”,
“键N”: “值N”,
}
1)创建空字典(声明):省略指定的键值对(但不可省略{});
操作已有map的格式:
(1)调用map中值的格式:字典名[“键”]
1)若指定的键不存在,则默认返回对应值数据类型的零值;
(2)添加/修改键值对格式:字典名[“键”] = ‘值’
1)设置键值对之前,必须先初始化map;
2)若指定的键名已存在,则指定值会覆盖原有的值;
3)若值为值传递类型,则不可修改该类型(可通过指针间接修改);
使用map时需注意的事项:
1)map的键不是变量,获取不到其地址(map增长可能导致位置改变);
2)在使用for range循环遍历map时,默认返回形式为:键 值;
3)map中迭代顺序不固定(遍历时,必须显示地给键排序);
4)不可对值为nil的map添加元素(导致panic);
如:创建map,并修改其键值对
1)编写程序;
package main
import (
"fmt"
)
func main() {
MyMap := map[string]string{
"name": "mwl",
"adress": "China",
"School": "NSU",
}
MyMap["ages"] = "20"
MyMap["name"] = "MaWenlong"
delete(MyMap, "School")
for key, value := range MyMap {
fmt.Println(MyMap[key], value)
}
}
2)运行结果;

如:修改值类型为结构体的map
1)编写程序;
package main
import (
"fmt"
)
type student struct {
Name string
Age int
}
func main() {
m := make(map[string]*student)
stus := []student{
{Name: "zhou", Age: 24},
{Name: "li", Age: 23},
{Name: "wang", Age: 22},
}
// 遍历结构体数组,依次赋值给map
for i := 0; i < len(stus); i++ {
m[stus[i].Name] = &stus[i]
}
//打印map
for k, v := range m {
fmt.Println(k, "=>", v.Name)
}
}
2)运行结果;

实现原理
runtime/map.go中map的数据结构定义:
type hmap struct {
count int // 包含键值对个数
flags uint8
B uint8 // bucket数组的大小
noverflow uint16
hash0 uint32 // Hash种子
buckets unsafe.Pointer // bucket数组(数组的长度位2的B次方)
oldbuckets unsafe.Pointer // 老bucket数组(用于扩容)
nevacuate uintptr // 负载因子计数器
extra *mapextra // 可选字段
}
1)map基于Hash表作为底层实现;
2)Hash表可有多个bucket(哈希桶),而每个bucket存储map中的键值对;
3)map的操作并非原子性的,不支持并发读写(可选用sync. map);
bucket的数据结构定义:
type bmap struct {
tophash [bucketCnt]uint8 // 存储Hash值的高8位
data []byte // 键值对数据
overflow *bmap // 指向溢出bucket地址的指针
}
1)每个bucket可存储8个键值对(bucketCnt值为8);
2)tophash:当Hash值相同键存储bucket时,会存储Hash值的高位;
3)data:以格式“key1/keyN/value1/valueN”存储数据(节省空间);
4)overflow:指向下个bucket(以链表形式连接所有冲突键);
//data和overflow并没显示在bmap结构体中声明(通过指针偏移访问虚拟成员)
负载因子:衡量Hash表中Hash冲突的情况
负载因子 = 键数量 / bucket数量2)负载因子过小:空间利用率较低(数据过于分散);
3)负载因子过大:Hash冲突过于严重(存取效率低);
rehash:负载因子过大时,申请更多的buckcet并重新组织键值对的行为
1)rehash可保证键值对均匀地分布在所有bucket;
2)Go中map的负载因子达到6.5时会触发rehash;
map扩容:申请原bucket长度2的bucket进行键值对的逐步搬迁
22)触发扩容的条件(每次对map添加新键值对时,都会进行触发检测):
| 触发条件 |
|---|
| 负载因子大于6.5 |
| overflow的数量大于2的15次方(32768) |
map扩容执行流程:
1)使hmap数据结构中的oldbuckets指向原bucket;
2)申请新bucket(原bucket的2倍);
3)使hmap数据结构中的buckets指向新bucket;
4)对oldbuckets进行逐步搬迁策略,待搬迁完毕后释放该内存;
逐步搬迁时,若对map进行查询/添加
1)查询:优先从oldbuckets中开始查找,再去buckets;
2)添加:新键值对直接添加到新的buckets;
如:map扩容时进行逐步搬迁的流程
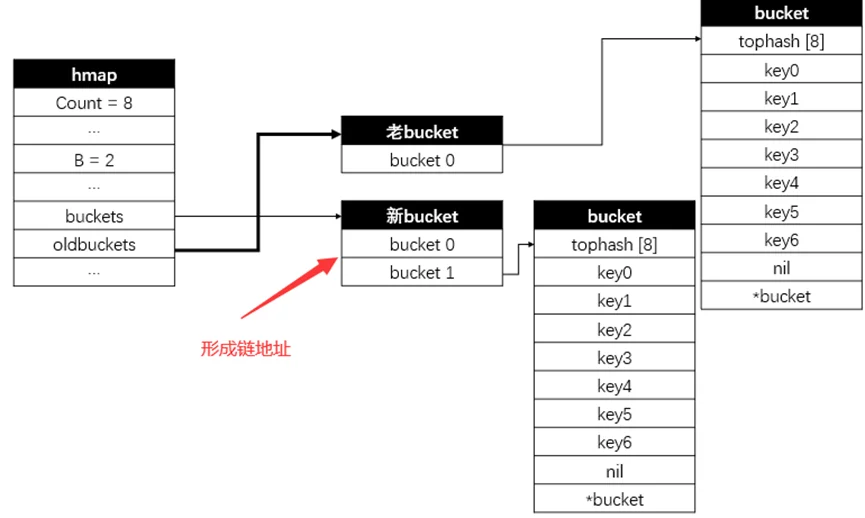
//后续搬迁过程种老bucket的部分数据也会转移至bucket1
delete
delete():删除字典中指定的键值对
1)即使指定的键不存在,执行该语句也不会报错(空操作);
//会返回值数据类型对应的零值
delete(字典名, “键”)如:创建map,并删除特定键
1)编写程序;
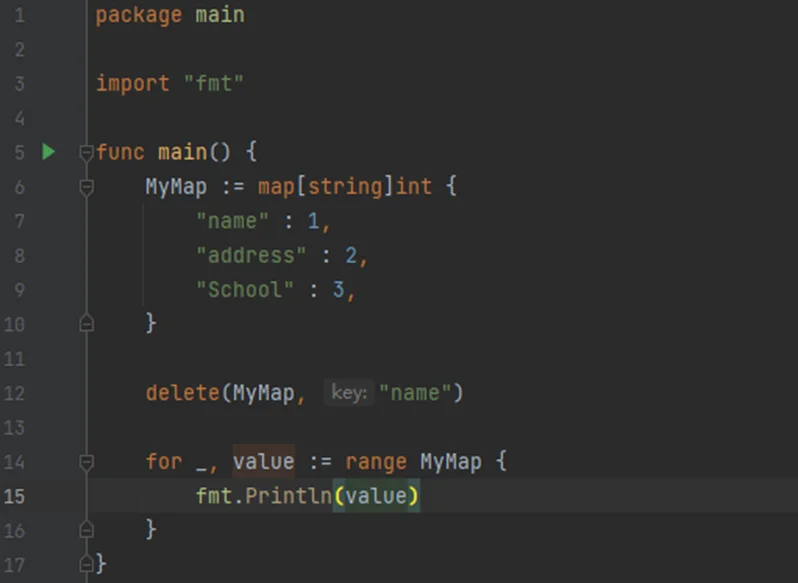
2)运行结果;

结构体
结构体类型(继承):包含零或多个任意类型的命名变量组合成的聚合数据类型
1)空结构体类型:没有任何成员变量的结构体;
2)结构体类型的零值由其成员变量的零值组成;
3)若结构体类型的所有成员变量均可比较,则该结构体类型就是可比较的;
结构体类型定义的格式:
type 结构体名 struct {
成员变量1 数据类型
成员变量N 数据类型
}
1)相同数据类型的成员可写在同一语句中,使用“,”分隔;
2)不能定义结构体本身类型的成员变量(可创建包含本身指针类型的);
3)可在定义结构体成员时,指定其Tag以记录额外属性(反引号括起来);
结构体成员的Tag注意事项:
key:“value”2)key必须是非空字符串,且不能包含控制字符、空格、引号和冒号;
3)value:必须被双引号括起来(用于标识控制指令);
4)冒号前后无空格,且多个内容之间使用空格分隔;
//若指定key为json,则在解析时仅将value代替成员变量
结构体对象定义格式分为2种:仅声明、定义
var 对象名 结构体名对象名 := 结构体名{初始值1, 初始值N}1)第一种方式创建的成员变量的值默认为对应数据类型的零值;
2)第二种方式必须为每个成员指定初始值(未指定的为对应类型零值);
结构体对象.成员//成员变量的初始值方式分为:默认顺序指定、通过成员变量名称指定
//两种方法不可混用(多个赋值操作之间使用“,”分隔)
如:定义两个结构体对象并传递给函数进行修改,并输出结果
1)编写程序;
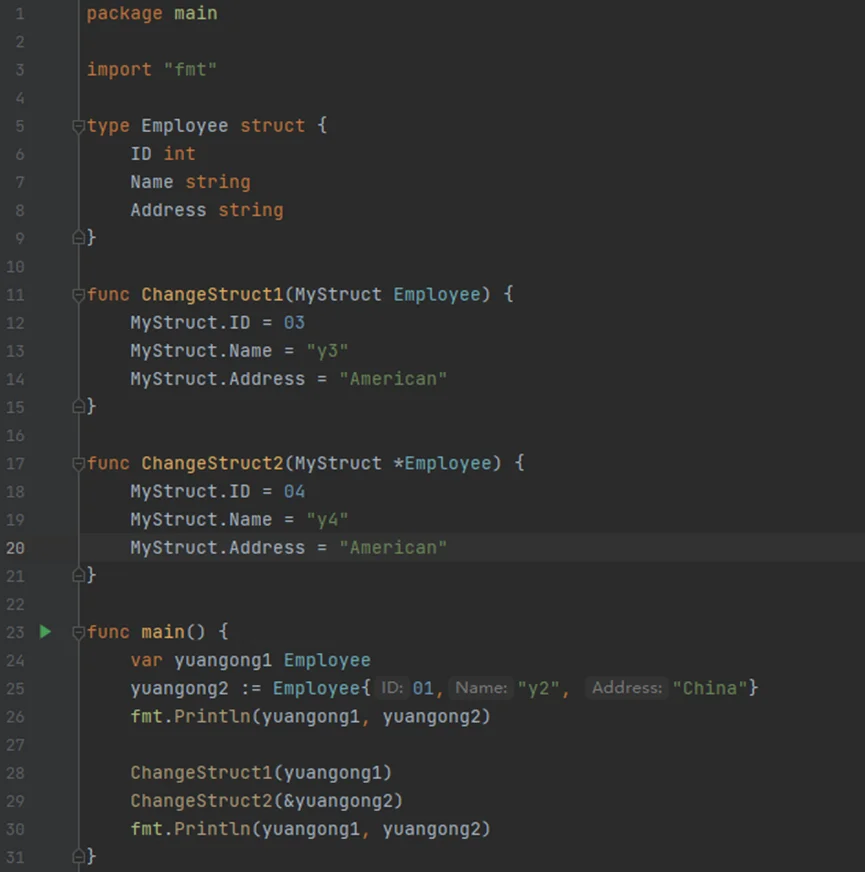
2)运行结果;

//结构体类型在当成函数参数传递时,默认传递形式为值传递(可通过指针更改)
嵌套结构体
嵌套结构体(继承):一个结构体类型中调用其他结构体类型定义成员变量
1)父结构体:被调用的结构体
2)子结构体:调用其他结构体
3)匿名子结构体:子结构体中仅指定结构体名未定义其结构体对象
//匿名子结构体拥有隐式名字(由其数据类型决定,导出性同理)
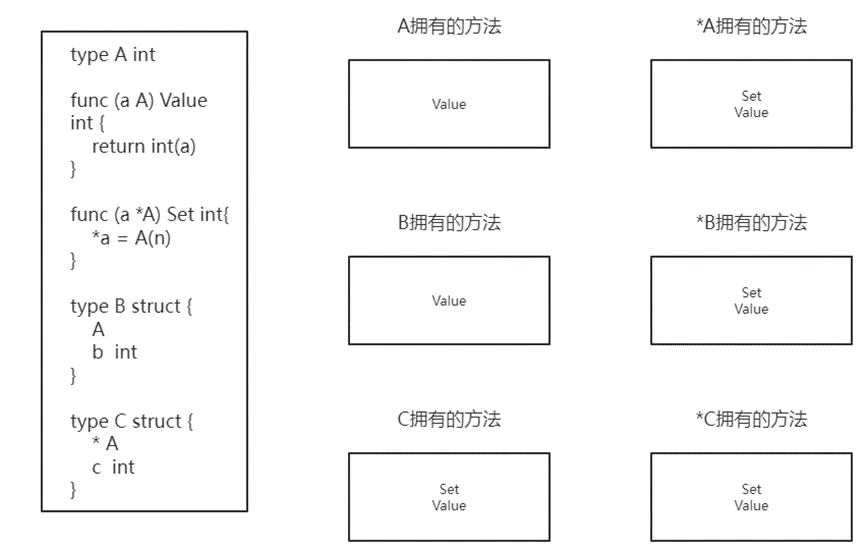
子结构体/匿名子结构体继承父结构体全部成员变量和方法;
1)编译器会拷贝父结构体的方法,但其方法接收者为子结构体
2)子结构体的指针类型接收者会同时继承父结构体的指针类型接收者的方法;
如:定义普通结构和指针类型的父结构体,观察其各拥有的方法
如:定义嵌套结构体,并在其中定义匿名结构体成员变量
1)编写程序;
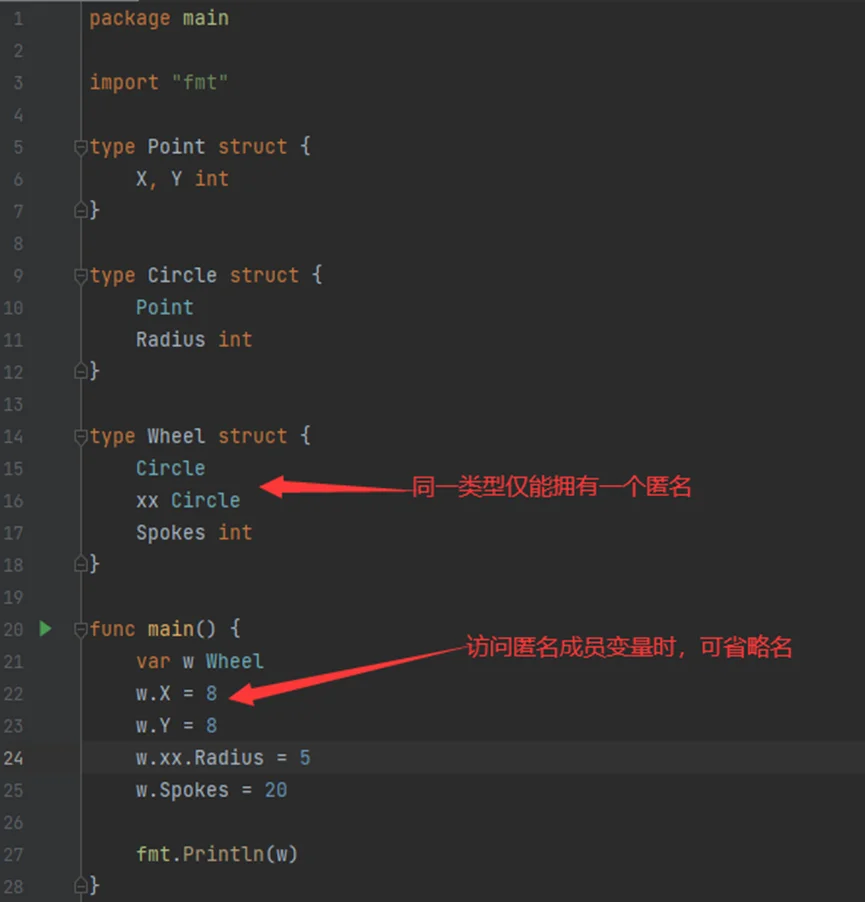
2)运行结果;

//结构体类型中同一数据类型的仅能拥有一个匿名成员变量