
map是一种无序的键值对集合。 map集合
map可通过key来快速地检索数据,且可以方便地对其进行迭代访问(其返回顺序是未知的)。
定义
通过make关键字可方便地构建map:
// 声明变量,为nil,不能对其进行数据操作(不能存放键值对;只能获取长度,或for-range)
var mpValue map[keyType]ValueType
// 使用make声明,可对其进行数据操作
mpValue := make(map[keyType]ValueType)
mpValue := make(map[keyType]ValueType, cap)
// 定义并初始化
mpTest := map[string]int{
"second":2,
"third":3,
}
make中传递的第二个元素是容量大小建议值hint,实际大小为能放下hint的最小 2 B 2^B 2B值;为避免扩容,hint需考虑一定余量(扩为8/6.5倍)。
mpTest := make(map[string]int)长度
cap(mp)len(mp)设置值
通过key赋值可添加元素:
- 若key存在,则更新value;
- 若key不存在,则添加键值对;
mpTest["first"] = 1
mpTest["first"] += 1
删除
通过内置delete函数来删除元素(参数为键key):
- 若key存在,就删除对应的键值对;
- 若key不存在,则无操作直接返回;
delete(mpTest, key)清空
go中没有提供直接清空map的方法,可通过:
for k := range mpTest{
delete(mpTest, k)
}
查询
查询与遍历时获取的v:
- 若是指针类型结构,可直接修改v中字段(map中的值也会对应修改);
- 否则,修改v,不影响map中值;
通过键可获取对应的值,并判断是否存在:
if v, ok := mpTest["first"]; ok{
fmt.Println("Key found:", v)
}else{
fmt.Println("Key not found")
}
// 若不需要对应的值,可
_, ok := mpTest["first"]
// 直接获取时,若对应键不存在,则返回对应类型的零值
v := mpTest["notExist"]
遍历
通过for可方便遍历:
for k, v := range mpTest{
fmt.Println(k, "=", v)
}
for k := range mpTest{
fmt.Println(k, "=", mpTest[k])
}
map在底层是用哈希表实现的(hash数组+桶内的key-value数组+溢出的桶链表);hash表中的基本单位是桶,每个桶最多存8个键值对,超过了会链接到额外的溢出桶。hash表大小是2的指数。
所有的值会被Hash到不同的桶中:
struct Bucket
{
uint8 tophash[BUCKETSIZE]; // hash值的高8位....低位从bucket的array定位到bucket
Bucket *overflow; // 溢出桶链表,如果有
byte data[1]; // BUCKETSIZE keys followed by BUCKETSIZE values
};
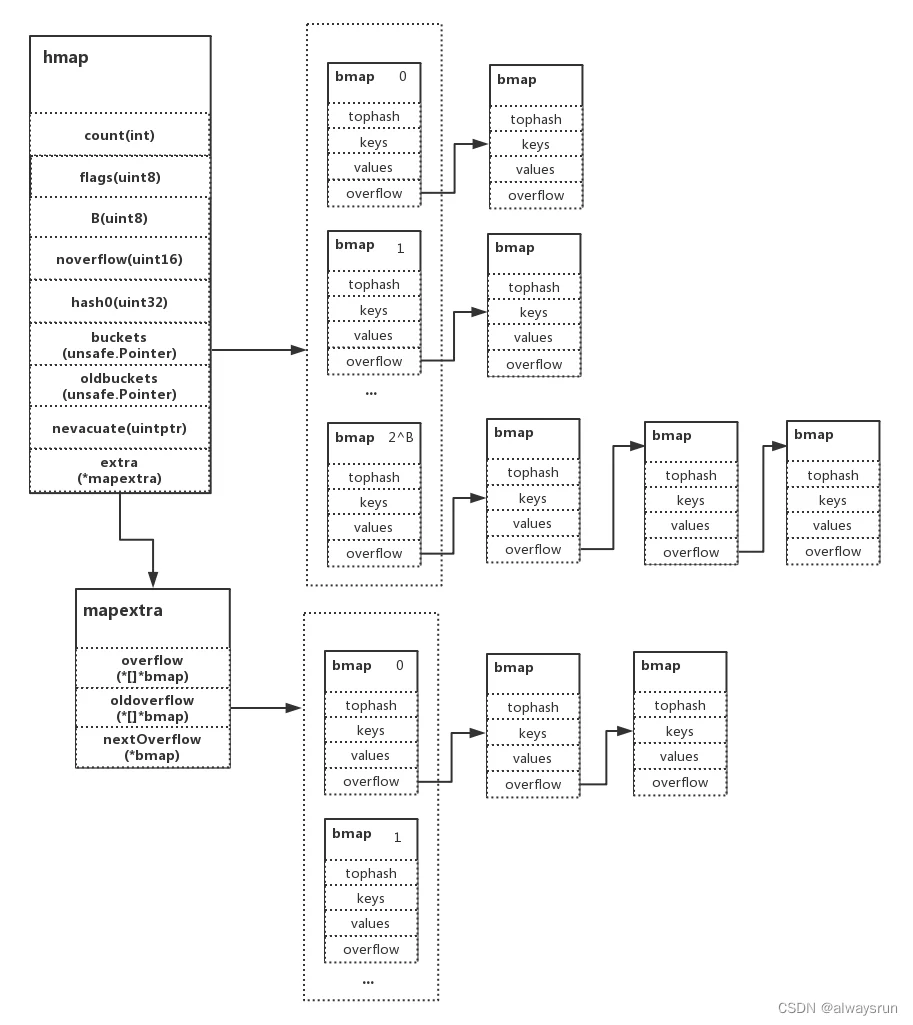
struct Hmap
{
uint8 B; // 可以容纳2^B个项
uint16 bucketsize; // 每个桶的大小
byte *buckets; // 2^B个Buckets的数组
byte *oldbuckets; // 旧的buckets,只有当正在扩容时才不为空
};
Bucket示意图:
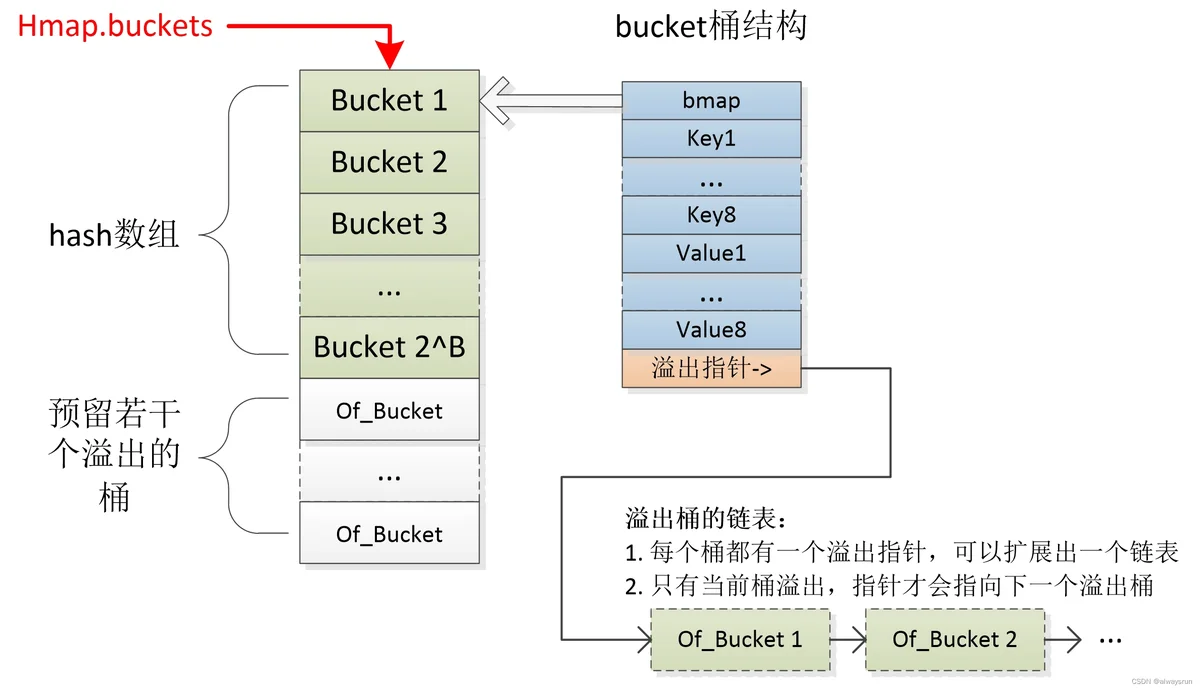
map底层创建时,会初始化一个hmap结构;并分配一个足够大的内存空间:前段用于hash数组;后段预留给溢出的桶。
整体结构示意图(各个桶在分配时是连在一起的):
Bucket中key/value的放置顺序是:keys放在一起(在前),values放在一起(在后);这样可避免不必要的对齐操作处理。
key比较
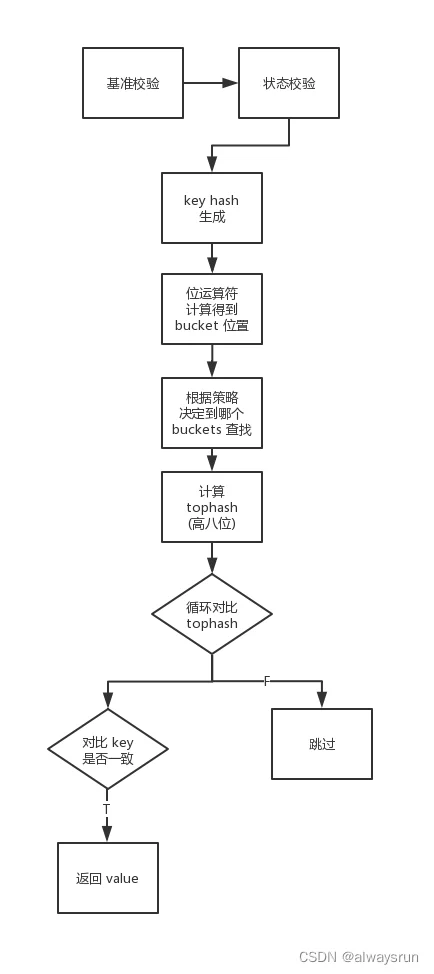
在查询、插入时key需要先计算出hash值:
- hash值的低位当作Hmap结构体中buckets数组的index,找到key所在的bucket;
- hash值的高8位存储在了bucket的tophash中;在查找时,对tophash数组的每一项进行顺序匹配:
- 先比较hash值高位与bucket的tophash[i]是否相等;若相等则再比较bucket的第i个的key与所给的key是否相等;若相等,则返回其对应的value;
- 否则继续下一项比较(bucket完成后,还需在overflow buckets中继续);
扩容
hmap扩容的负载因子是6.5,即count/( 2 B 2^B 2B)>6.5时就会发生扩容(扩容为原来两倍,即 2 B + 1 2^{B+1} 2B+1)。从旧数组将数据迁移到新数组时,不是一次全量拷贝完成的,而是在每次读写Map时以桶为单位做动态搬迁。从而避免了扩容时长时间的停顿。
在负载因子没有超标,但noverflow较多(B<=15时,noverflow>= 2 B 2^B 2B;B>15时,noverflow>= 2 15 2^{15} 215)的情况下,会发生等量扩容:创建和旧桶数目一样多的新桶,把旧桶中的数据放进去。发生这样的情况,一般是大量键值对被删除,通过等量扩容,可减少溢出桶的数量。
注意:map只会扩容,不会收缩;若map中删除元素太多,可通过申请新的map,把旧map复制过去的方式来收缩。
结论在使用map时:
- 带有容量的map初始化,可以有效的减少内存分配的次数,进而减少每次操作的耗时;
- 每次扩容hash表增大1倍,hash表只增不减;
- delete操作只置删除标志位,释放溢出桶的空间依靠触发等量扩容来实现;
- map不支持并发。插入、删除、搬迁等操作会置writing标志,检测到并发直接panic;
- 内置类型用值,构造的struct类型用指针;
- 指针类型会影响golang.gc的速度;