
当提到并发编程、多线程编程时,我们往往都离不开『锁』这一概念,Go 语言作为一个原生支持用户态进程 Goroutine 的语言,也一定会为开发者提供这一功能,锁的主要作用就是保证多个线程或者 Goroutine 在访问同一片内存时不会出现混乱的问题,锁其实是一种并发编程中的同步原语(Synchronization Primitives)。
MutexRWMutexWaitGroupOnceCondErrGroupSemaphoreSingleFlight基本原语
MutexRWMutexOnceWaitGroup 

MutexRWMutexOnceWaitGroupCondMapPoolMutex
syncstatesemastatesematype Mutex struct {
state int32
sema uint32
}
状态
int32mutexLockedmutexWokenmutexStarving
0mutexLocked1mutexWoken1mutexStarving饥饿模式
MutexLock
在饥饿模式中,互斥锁会被直接交给等待队列最前面的 Goroutine,新的 Goroutine 在这时不能获取锁、也不会进入自旋的状态,它们只会在队列的末尾等待,如果一个 Goroutine 获得了互斥锁并且它是队列中最末尾的协程或者它等待的时间少于 1ms,那么当前的互斥锁就会被切换回正常模式。
Mutex加锁
MutexLockLock0mutexLocked1func (m *Mutex) Lock() {
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
m.lockSlow()
}
LockMutex0lockSlowforfunc (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false
awoke := false
iter := 0
old := m.state
for {
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
old = m.state
continue
}
在这段方法的第一部分会判断当前方法能否进入自旋来等待锁的释放,自旋(Spinnig)其实是在多线程同步的过程中使用的一种机制,当前的进程在进入自旋的过程中会一直保持 CPU 的占用,持续检查某个条件是否为真,在多核的 CPU 上,自旋的优点是避免了 Goroutine 的切换,所以如果使用恰当会对性能带来非常大的增益。
Mutexruntime_canSpinPruntime_doSpinprocyieldPAUSEPAUSE30PAUSETEXT runtime·procyield(SB),NOSPLIT,$0-0
MOVL cycles+0(FP), AX
again:
PAUSE
SUBL $1, AX
JNZ again
RET
statemutexLockedmutexStarvingmutexWokenmutexWaiterShift new := old
if old&mutexStarving == 0 {
new |= mutexLocked
}
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
if awoke {
new &^= mutexWoken
}
atomicruntime_SemacquireMutex if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&(mutexLocked|mutexStarving) == 0 {
break // locked the mutex with CAS
}
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
if old&mutexStarving != 0 {
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
old = m.state
}
}
}
runtime_SemacquireMutexMutexMutexruntime_SemacquireMutexgoparkunlockLockstarvationThresholdNs(1ms)解锁
UnlockatomicAddInt320unlockSlowfunc (m *Mutex) Unlock() {
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
m.unlockSlow(new)
}
}
unlockSlowsync: unlock of unlocked mutexfunc (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
if new&mutexStarving == 0 {
old := new
for {
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else {
runtime_Semrelease(&m.sema, true, 1)
}
}
runtime_SemreleasemutexLockedmutexStarving0runtime_Semrelease小结
MutexmutexLockedmutexLockedPAUSE1msruntime_SemacquireMutexLock1ms互斥锁的解锁过程相对来说就比较简单,虽然对于普通模式和饥饿模式的处理有一些不同,但是由于代码行数不多,所以逻辑清晰,也非常容易理解:
UnlockmutexLockedruntime_SemreleaseRWMutex
syncRWMutex| 读 | 写 | |
|---|---|---|
| 读 | Y | N |
| 写 | N | N |
RWMutextype RWMutex struct {
w Mutex
writerSem uint32
readerSem uint32
readerCount int32
readerWait int32
}
readerCountreaderWait读锁
atomic.AddInt32readerCountruntime_SemacquireMutexfunc (rw *RWMutex) RLock() {
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
}
readerCountRUnlockfunc (rw *RWMutex) RUnlock() {
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
rw.rUnlockSlow(r)
}
}
readerCountrUnlockSlowreaderWaitwriterSemfunc (rw *RWMutex) rUnlockSlow(r int32) {
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
throw("sync: RUnlock of unlocked RWMutex")
}
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
writerSem读写锁
LockLockMutexLockatomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders)func (rw *RWMutex) Lock() {
rw.w.Lock()
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
}
runtime_SemacquireMutexwriterSematomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)func (rw *RWMutex) Unlock() {
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
if r >= rwmutexMaxReaders {
throw("sync: Unlock of unlocked RWMutex")
}
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
rw.w.Unlock()
}
RWMutex小结
MutexRWMutexMutexreaderSemwriterSemwreaderCountrwmutexMaxReadersreaderWaitLockRUnlockUnlockRWMutexMutexWaitGroup
WaitGroupsyncrequests := []*Request{...}
wg := &sync.WaitGroup{}
wg.Add(len(requests))
for _, request := range requests {
go func(r *Request) {
defer wg.Done()
// res, err := service.call(r)
}(request)
}
wg.Wait()
WaitGroupWait 

Done结构体
WaitGroupnoCopyWaitGrouptype WaitGroup struct {
noCopy noCopy
state1 [3]uint32
}
noCopysyncpackage main
import (
"fmt"
"sync"
)
func main() {
wg := sync.Mutex{}
yawg := wg
fmt.Println(wg, yawg)
}
$ go run proc.go
./prog.go:10:10: assignment copies lock value to yawg: sync.Mutex
./prog.go:11:14: call of fmt.Println copies lock value: sync.Mutex
./prog.go:11:18: call of fmt.Println copies lock value: sync.Mutex
fmt.PrintlnnoCopyWaitGroup
WaitGroupstatestate1操作
WaitGroupAddWaitDoneDonewg.Add(-1)func (wg *WaitGroup) Add(delta int) {
statep, semap := wg.state()
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32)
w := uint32(state)
if v < 0 {
panic("sync: negative WaitGroup counter")
}
if v > 0 || w == 0 {
return
}
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
}
AddWaitGroupcounterAddWaitGroupAddruntime_SemreleaseWaitGroupWait0waiterruntime_Semacquirefunc (wg *WaitGroup) Wait() {
statep, semap := wg.state()
for {
state := atomic.LoadUint64(statep)
v := int32(state >> 32)
if v == 0 {
return
}
if atomic.CompareAndSwapUint64(statep, state, state+1) {
runtime_Semacquire(semap)
if +statep != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
return
}
}
}
Add0小结
WaitGroupAddWaitWaitGroupWaitDoneAddAddWaitGroupOnce
syncOnceOnceDoonly oncefunc main() {
o := &sync.Once{}
for i := 0; i < 10; i++ {
o.Do(func() {
fmt.Println("only once")
})
}
}
$ go run main.go
only once
syncOnceOncedoneMutextype Once struct {
done uint32
m Mutex
}
OnceDoatomic.LoadUint32doSlowfunc (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
doSlowdeferdone1panicdone1小结
OnceatomicDopanicDoCond
CondCondCondLCondfunc main() {
c := sync.NewCond(&sync.Mutex{})
for i := 0; i < 10; i++ {
go listen(c)
}
go broadcast(c)
ch := make(chan os.Signal, 1)
signal.Notify(ch, os.Interrupt)
<-ch
}
func broadcast(c *sync.Cond) {
c.L.Lock()
c.Broadcast()
c.L.Unlock()
}
func listen(c *sync.Cond) {
c.L.Lock()
c.Wait()
fmt.Println("listen")
c.L.Unlock()
}
$ go run main.go
listen
listen
...
listen
WaitBroadcastBoardcast"listen"
结构体
CondnoCopycopyCheckerCondpanicLLockerLockUnlockNewCondtype Cond struct {
noCopy noCopy
L Locker
notify notifyList
checker copyChecker
}
notifyListCondGoroutinetype notifyList struct {
wait uint32
notify uint32
lock mutex
head *sudog
tail *sudog
}
headtailwaitnotify操作
CondWaitruntime_notifyListAdd+1runtime_notifyListWaitfunc (c *Cond) Wait() {
c.checker.check()
t := runtime_notifyListAdd(&c.notify)
c.L.Unlock()
runtime_notifyListWait(&c.notify, t)
c.L.Lock()
}
func notifyListAdd(l *notifyList) uint32 {
return atomic.Xadd(&l.wait, 1) - 1
}
notifyListWaitnotifyList
func notifyListWait(l *notifyList, t uint32) {
lock(&l.lock)
if less(t, l.notify) {
unlock(&l.lock)
return
}
s := acquireSudog()
s.g = getg()
s.ticket = t
if l.tail == nil {
l.head = s
} else {
l.tail.next = s
}
l.tail = s
goparkunlock(&l.lock, waitReasonSyncCondWait, traceEvGoBlockCond, 3)
releaseSudog(s)
}
goparkunlock 

CondSignalBroadcastWaitfunc (c *Cond) Signal() {
c.checker.check()
runtime_notifyListNotifyOne(&c.notify)
}
func (c *Cond) Broadcast() {
c.checker.check()
runtime_notifyListNotifyAll(&c.notify)
}
notifyListNotifyAllreadyWithTimegoreadyfunc notifyListNotifyAll(l *notifyList) {
s := l.head
l.head = nil
l.tail = nil
atomic.Store(&l.notify, atomic.Load(&l.wait))
for s != nil {
next := s.next
s.next = nil
readyWithTime(s, 4)
s = next
}
}
goreadynotifyListNotifyOnesudogsudog.ticket == l.notifyreadyWithTimefunc notifyListNotifyOne(l *notifyList) {
t := l.notify
atomic.Store(&l.notify, t+1)
for p, s := (*sudog)(nil), l.head; s != nil; p, s = s, s.next {
if s.ticket == t {
n := s.next
if p != nil {
p.next = n
} else {
l.head = n
}
if n == nil {
l.tail = p
}
s.next = nil
readyWithTime(s, 4)
return
}
}
}
WaitSignalBroadcast小结
MutexCondSignalBroadcastfor {}CondWaitL.LockpanicSignalBroadcast扩展原语
x/syncErrGroupSemaphoreSingleFlightSyncMapSyncMapsyncsync.Mapx/syncsync 

ErrGroupSemaphoreSingleFlightErrGroup
x/syncvar g errgroup.Group
var urls = []string{
"http://www.golang.org/",
"http://www.google.com/",
"http://www.somestupidname.com/",
}
for i := range urls {
url := urls[i]
g.Go(func() error {
resp, err := http.Get(url)
if err == nil {
resp.Body.Close()
}
return err
})
}
if err := g.Wait(); err == nil {
fmt.Println("Successfully fetched all URLs.")
}
GoWaitGonil结构体
errgroupGroupContextcancelcontextWaitGrouperrerrerrOncetype Group struct {
cancel func()
wg sync.WaitGroup
errOnce sync.Once
err error
}
Group操作
errgroupWithContextContextGroupWithCancelGroupfunc WithContext(ctx context.Context) (*Group, context.Context) {
ctx, cancel := context.WithCancel(ctx)
return &Group{cancel: cancel}, ctx
}
GoWaitGroupcancelerrfunc (g *Group) Go(f func() error) {
g.wg.Add(1)
go func() {
defer g.wg.Done()
if err := f(); err != nil {
g.errOnce.Do(func() {
g.err = err
if g.cancel != nil {
g.cancel()
}
})
}
}()
}
func (g *Group) Wait() error {
g.wg.Wait()
if g.cancel != nil {
g.cancel()
}
return g.err
}
WaitWaitGroupContext小结
errgroupGroupContextcancelSemaphore
0Golang 的扩展包中就提供了带权重的信号量,我们可以按照不同的权重对资源的访问进行管理,这个包对外也只提供了四个方法:
NewWeightedAcquireTryAcquirefalseRelease结构体
NewWeightedWeightedfunc NewWeighted(n int64) *Weighted {
w := &Weighted{size: n}
return w
}
type Weighted struct {
size int64
cur int64
mu sync.Mutex
waiters list.List
}
Weightedwaiterscur[0, size] 

信号量中的计数器会随着用户对资源的访问和释放进行改变,引入的权重概念能够帮助我们更好地对资源的访问粒度进行控制,尽可能满足所有常见的用例。
获取
AcquireWeightedselectfunc (s *Weighted) Acquire(ctx context.Context, n int64) error {
s.mu.Lock()
if s.size-s.cur >= n && s.waiters.Len() == 0 {
s.cur += n
s.mu.Unlock()
return nil
}
if n > s.size {
s.mu.Unlock()
<-ctx.Done()
return ctx.Err()
}
ready := make(chan struct{})
w := waiter{n: n, ready: ready}
elem := s.waiters.PushBack(w)
s.mu.Unlock()
select {
case <-ctx.Done():
err := ctx.Err()
s.mu.Lock()
select {
case <-ready:
err = nil
default:
s.waiters.Remove(elem)
}
s.mu.Unlock()
return err
case <-ready:
return nil
}
}
TryAcquiretruefalsefunc (s *Weighted) TryAcquire(n int64) bool {
s.mu.Lock()
success := s.size-s.cur >= n && s.waiters.Len() == 0
if success {
s.cur += n
}
s.mu.Unlock()
return success
}
AcquireTryAcquire释放
ReleaseReleasewaitersfunc (s *Weighted) Release(n int64) {
s.mu.Lock()
s.cur -= n
for {
next := s.waiters.Front()
if next == nil {
break
}
w := next.Value.(waiter)
if s.size-s.cur < w.n {
break
}
s.cur += w.n
s.waiters.Remove(next)
close(w.ready)
}
s.mu.Unlock()
}
AcquireContext小结
带权重的信号量确实有着更多的应用场景,这也是 Go 语言对外提供的唯一一种信号量实现,在使用的过程中我们需要注意以下的几个问题:
AcquireTryAcquireReleaseReleaseSingleFlight
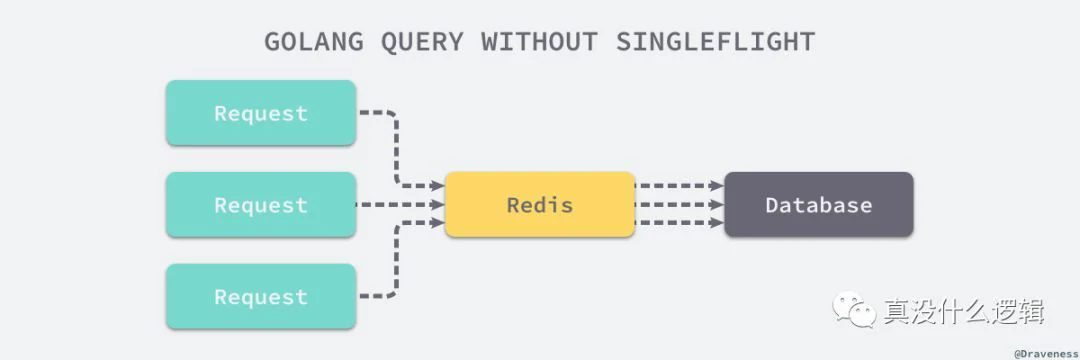
singleflight 是 Go 语言扩展包中提供了另一种同步原语,这其实也是作者最喜欢的一种同步扩展机制,它能够在一个服务中抑制对下游的多次重复请求,一个比较常见的使用场景是 — 我们在使用 Redis 对数据库中的一些热门数据进行了缓存并设置了超时时间,缓存超时的一瞬间可能有非常多的并行请求发现了 Redis 中已经不包含任何缓存所以大量的流量会打到数据库上影响服务的延时和质量。

singleflightKeyKey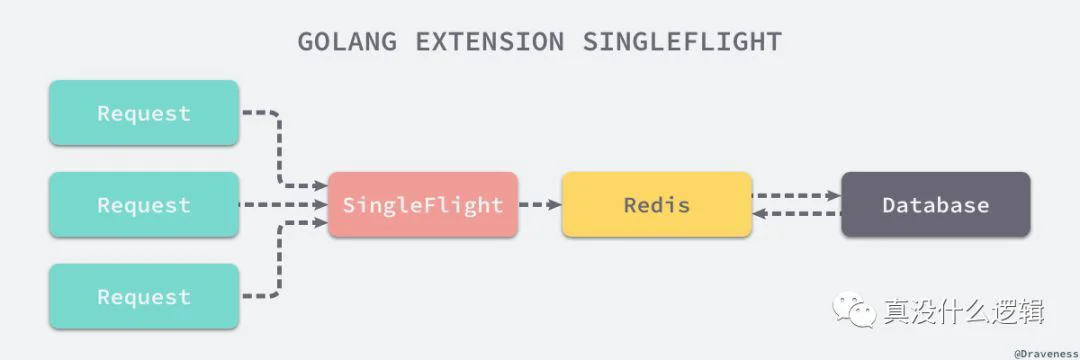 

singleflightsingleflightsingleflight.Group{}GroupDotype service struct {
requestGroup singleflight.Group
}
func (s *service) handleRequest(ctx context.Context, request Request) (Response, error) {
v, err, _ := requestGroup.Do(request.Hash(), func() (interface{}, error) {
rows, err := // select * from tables
if err != nil {
return nil, err
}
return rows, nil
})
if err != nil {
return nil, err
}
return Response{
rows: rows,
}, nil
}
Do结构体
GroupMutexKeycallcalltype Group struct {
mu sync.Mutex
m map[string]*call
}
type call struct {
wg sync.WaitGroup
val interface{}
err error
dups int
chans []chan<- Result
}
callvalerrWaitGroupdupschanssingleflight操作
singleflightDoDoChanDoGroupkeycallcallWaitGroupcallMutexdoCallcalldupsMutexWaitGroup.Waitfunc (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok {
c.dups++
g.mu.Unlock()
c.wg.Wait()
return c.val, c.err, true
}
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
g.doCall(c, key, fn)
return c.val, c.err, c.dups > 0
}
valerrdoCalldoCallWaitGroup.WaitDofunc (g *Group) doCall(c *call, key string, fn func() (interface{}, error)) {
c.val, c.err = fn()
c.wg.Done()
g.mu.Lock()
delete(g.m, key)
for _, ch := range c.chans {
ch <- Result{c.val, c.err, c.dups > 0}
}
g.mu.Unlock()
}
doCallfnc.valc.errWaitGroup.DonecalldoCallDoChanfunc (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result {
ch := make(chan Result, 1)
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok {
c.dups++
c.chans = append(c.chans, ch)
g.mu.Unlock()
return ch
}
c := &call{chans: []chan<- Result{ch}}
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
go g.doCall(c, key, fn)
return ch
}
DoChanDodoCallcallchanschan Result小结
singleflightGroupDoDoChanForgetsingleflight总结
我们在这一节中介绍了 Go 语言标准库中提供的基本原语以及扩展包中的扩展原语,这些并发编程的原语能够帮助我们更好地利用 Go 语言的特性构建高吞吐量、低延时的服务,并解决由于并发带来的错误,到这里我们再重新回顾一下这一节介绍的内容:
MutexmutexLockedmutexLockedPAUSE1msruntime_SemacquireMutexLock1msUnlockmutexLockedruntime_SemreleaseRWMutexreaderSemwriterSemwreaderCountrwmutexMaxReadersreaderWaitLockRUnlockUnlockWaitGroupAddWaitWaitGroupWaitDoneAddAddWaitGroupOnceDopanicDoCondWaitL.LockpanicSignalBroadcastErrGroupContextcancelSemaphoreAcquireTryAcquireReleaseReleaseSingleFlightDoDoChanForgetsingleflight这些同步原语的实现不仅要考虑 API 接口的易用、解决并发编程中可能遇到的线程竞争问题,还需要对尾延时进行优化避免某些 Goroutine 无法获取锁或者资源而被饿死,对同步原语的学习也能够增强我们队并发编程的理解和认识,也是了解并发编程无法跨越的一个步骤。