
导语 | 本文从简洁架构的理论出发,依托trpc-go目录规范,简单阐述了整体代码架构如何划分,具体trpc-go服务代码实现细节,和落地步骤,并讨论了和DDD的区别。文章源于我们组内发起的go微服务最佳实践的第一部分,希望从开发和阅读学习中总结出一套go微服务开发的方法论,互相分享一下在寻求最佳的实践过程中的思考和取舍的过程。本次主要讨论目录如何组织,目录的组织其实就是架构的设计,一套通用架构的设计,可以让开发专注于逻辑设计和具体场景的代码设计,好的架构设计可以预防代码的腐败,并且相关的规范操作简单,可以按步骤根据情况分步落地,可操作性强。
引言
现在有了高效的go语言和成熟的trpc-go框架和一系列的中台SDK,发布平台,一个新手也可以通过教程快速写出简单功能的微服务,以此入门,开始go的微服务开发,并应对大部分开发需求。
但是一旦开始了就会发现随着需求的增加我们常常不得不去花很多时间去维护代码,变更已有的逻辑,不断的抽象,提高部分常用能力的可扩展性,但往往随着多个人在同一份微服务代码里协作,维护这件事情越来越难做了,不仅仅是因为大家的抽象风格不同,对于抽象的标准,模块的分割,数据的流向,分层的逻辑都是不同的,看每个服务都像是一个新的生命,千姿百态。
千姿百态的代码库不是我们希望的,我们希望在代码的架构上保持易读性、可扩展性、可维护性,这样除了对于代码细节的一致性(代码标准)外,还希望有架构上的标准,让开发专注于逻辑设计和具体场景的代码设计,在海量之道的知识下把服务相关内容做好,而不是将时间和精力浪费在纠结如何重新组织和解乱麻、重构等工作上,如果每个服务的架构都足够简洁清晰,团队内部每个仓库都像是自己写的,上手也会很快,团队的效率就会几何的速度提升。
一、 开发现状
不同的业务场景不太一样,在增值的业务场景下,大部分的需求边界或者服务全部职能一开始并不能确定,一般就是一个小需求开始的微服务,后续可能随着业务的增长慢慢变得复杂的,仿佛是从一颗小树苗渐渐长成一颗枝繁叶茂的大树,可能一开始这个服务的职责很单一,很简单,一个service搭配一个logic就ok了,但后面加入了各种依赖,logic就开始变复杂,更可怕的是,因为来一个需求做一个需求(假设最坏的情况下无法预测产品的需求),对于落后的开发模式,或者没有架构概念来说,多一个需求,无非就是加个函数,加个分支,需要啥,import啥就完事了,渐渐地,绝大多数服务成为:
-
没有合理分包,或者仅逻辑职责分包(分目录)
-
面向过程编程,函数调用链很长,在各种包之间穿插。
-
没有依赖注入,依赖是以全局引入的方式存在,作用域很大,潜在的并发问题。
最终导致:
-
不通用,一切都不通用,每次修改一个逻辑部分可能要牵扯到多个函数调用的地方去修改参数关系。
-
测试用例难写,import进来的函数,是mock呢还是不mock呢,mock函数一个个写,monkey mock是否合理?
-
每个模块不独立,看似按逻辑分了模块,比如order_hanlder,conf,XXX_helper,database等,但没有明确的上下层关系,每个模块里可能都存在配置读取,外部服务调用,协议转换等。
先看目前的微服务代码状态,截几个常见的微服务目录组织风格:
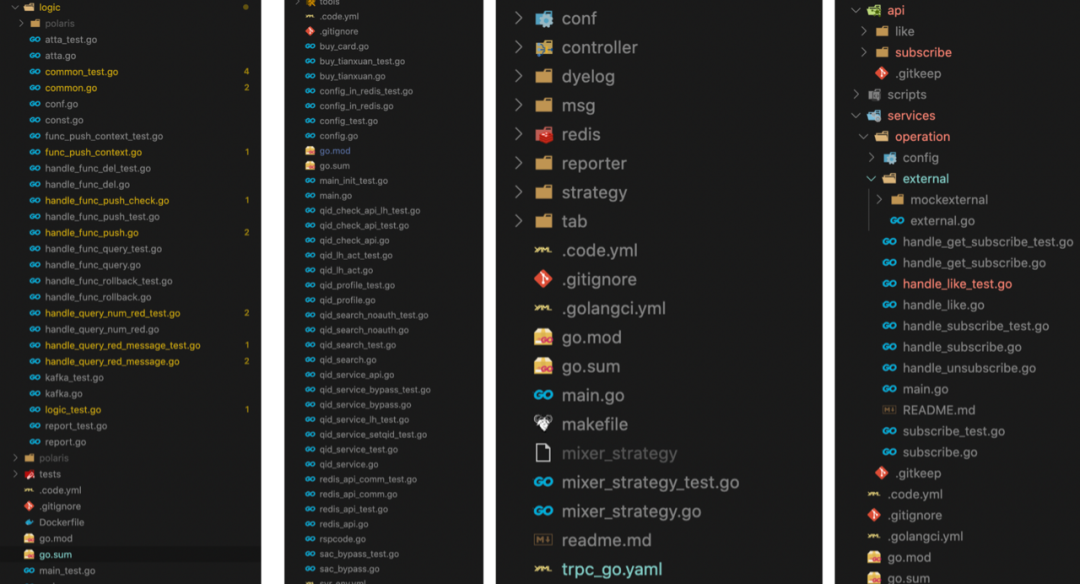
四种目前常见的微服务目录组织方式,从左至右分别为1,2,3,4,可以看到:
-
服务1除了main全部都放在logic中,logic实际上已经职责不清了。
-
服务2全部平铺式的,为什么作者要这么干,因为他写了很多monkey func mock,因为没有抽象,不同函数之间调用导致很多函数的mock需要复用,但测试文件中的内容不支持import,所以为了避免底层逻辑函数要重复在不同包里写mock,干脆平铺了。
-
服务3常见组织方式,以逻辑为单元进行模块分包解耦,基本符合单一职责原则,但这种微服务随着需求的增长会产生网状调用的问题。
-
服务4对外部调用有一定抽象的目录设计,但组织方式并不一眼清晰,没有合理的分包,逻辑代码写在接入层。
(一)没有架构
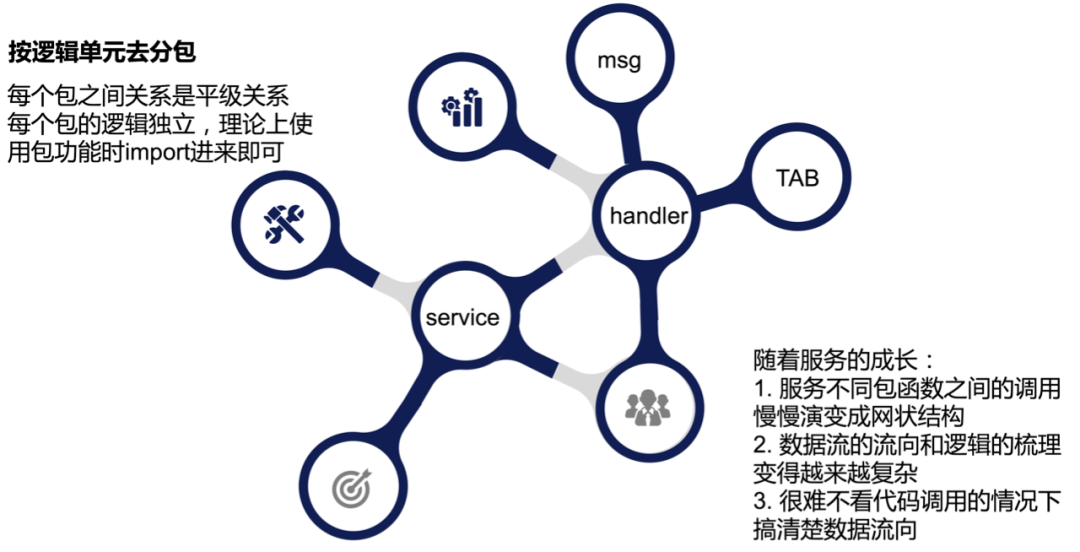
如上述例子中,大多数服务没有架构上的概念,多数业务是以逻辑单元的方式去分包(分目录),每个包之间关系是平级关系,每个包的逻辑独立,理论上使用包功能时import进来即可,随着服务的成长:
-
服务不同包函数之间的调用慢慢演变成网状结构。
-
数据流的流向和逻辑的梳理变得越来越复杂。
-
很难不看代码调用的情况下搞清楚数据流向。
这是目前常见的一个实际问题,业务增长过程中,微服务很容易长成一个垃圾山,开发心累,改不动的情况出现。
所谓的代码腐败即在代码增量到一定程度后,服务内部的函数调用组织是网状结构,没有层级结构,即使微观上可能是解耦的,但宏观上是乱成一团的,DDD等设计思想都是为了解决这样的问题。
(二)没有分层
常见的微服务只有分包没有分层的概念,数据流没有分层,因为没有合理的分层,自然没有上下调用的关系,最多就是逻辑上分个包而已,用到啥import进来就完善,没有层次的系统就是一盘散沙,一盘散沙的接口,互相随意调用,关系乱成一团,这就是日后维护和调试的噩梦。
二、 探索最佳架构实践
(一)简洁架构
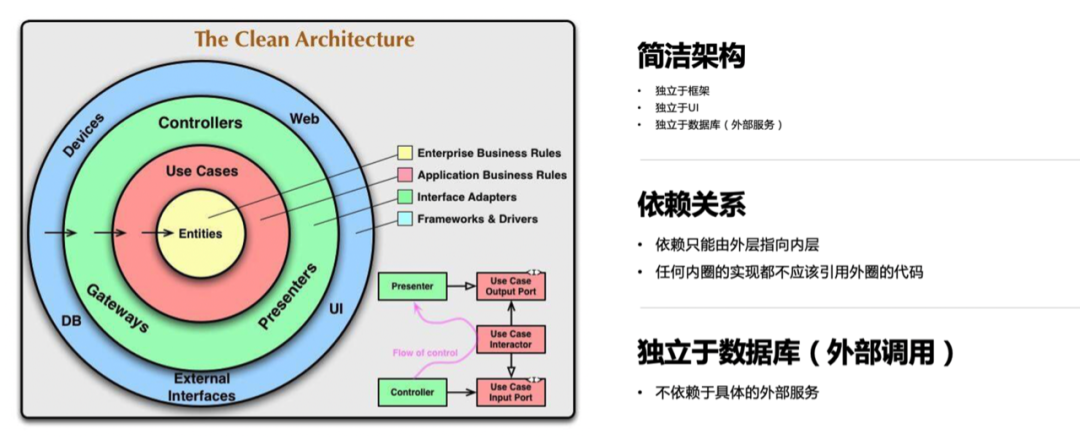
出自《架构整洁之道》,此架构模型是不区分前后端的广义上的抽象架构我们希望每个微服务的代码在微观上也是符合简洁架构。
在后台服务的场景下,以trpc-go目录规范可以抽象出一种金字塔结构的架构:

这种结构的优势体现在:
-
标准结构:层+模块
-
结构分层,每层之间划分模块。
-
数据流向固定,自上而下单一方向。
-
架构清晰,需求代码增长是结构化的,组织关系不是网状。
-
一致性
-
架构通用,可以统一规范。
-
协作开发时不同服务的架构一样,无理解成本。
-
易于操作
-
相关概念简单,易于操作,符合开发直觉,便于正确分类代码。
-
不涉及领域建模等额外问题。
-
减缓代码膨胀
-
分层将代码上升或下层,以三层的结构可以一定程度上降低每一层的代码膨胀的速度。
(二)目录规范
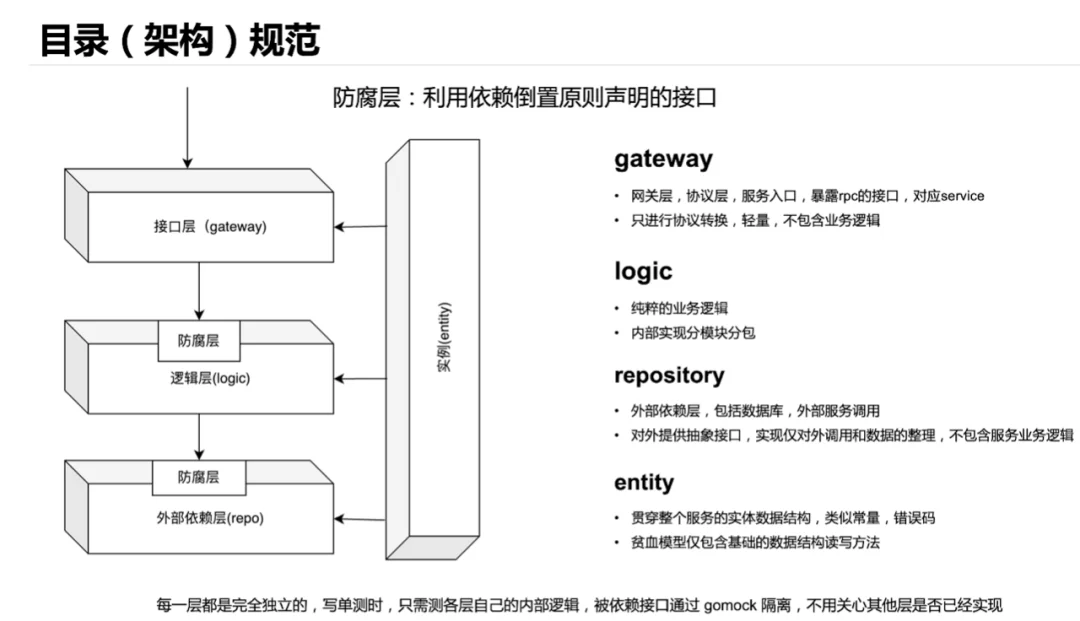
分层按数据流向分为接口层(网关层)、逻辑层,外部依赖层,划分方式和理解成本都不会很高,详细如下:
-
gateway
-
接口实现的地方,服务接口入口处,对应trpc-go的service。
-
只进行协议解析转换,协议的整理,不涉及业务逻辑。
-
logic
-
服务核心业务逻辑实现的地方。
-
内部实现分模块分包。
-
repo
-
外部依赖层,包括外部数据库、RPC调用等。
-
每个包提供抽象接口,将外部数据调用并整理后以接口的方式提供给logic。
-
仅做外部调用和数据整理,不包含业务逻辑。
-
entity
-
贯穿整个服务的数据结构,类似常量,错误码。
-
贫血模型,即仅包含数据结构读写方法的对象。
-
防腐层
-
每层对外暴露的都以抽象接口方式,用依赖倒置的方式实现每层之间的防腐。
-
抽象接口天然可以gomock生成桩代码,上层单测时只需要用下层对应的桩代码mock下层依赖即可。
三、 实现规范

在实践过程将代码目录按标准划分归类只是第一步,重要的是层与层之间的隔离和模块与模块之间的解耦,所以需要用到依赖倒置、依赖注入、封装、测试规范来实现具体的代码,其中测试规范是反向校验代码设计是否合格的一把尺子,如果每个接口无法使用gomock打桩,那么依赖倒置就是没有做好。
(一)依赖倒置、接口隔离
-
依赖倒置
-
上层模块不应该依赖底层模块,它们都应该依赖于抽象。
-
抽象不应该依赖于细节,细节应该依赖于抽象。
-
接口隔离
-
客户端不应该依赖它不需要的接口。
-
模块间的依赖应该建立在最小的接口之上。
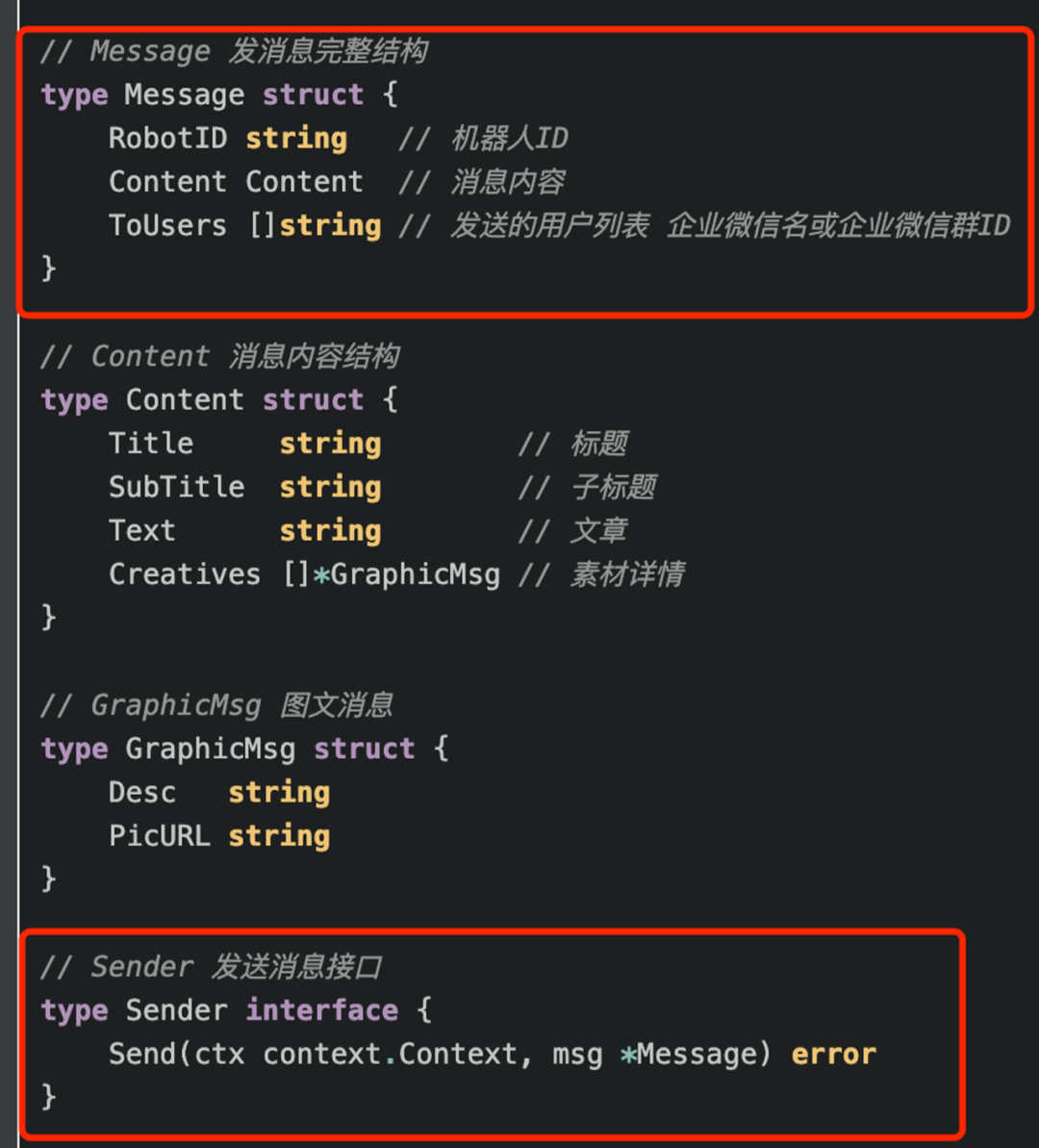
实现要求:不同层之间对外的接口一律以interface的方式提供,并且单一职责的设计,接口尽可能简单清晰,接口文件单独存放,不放在具体实现的文件中,依赖参数定义和接口声明放在一起。
例,msg包下api.go定义消息接口:
(二)依赖注入
依赖注入(DI,Dependency Injection)指的是实现控制反转(IOC,Inversion of Control)的一种方式,其实很好理解就是内部依赖什么,不要在内部创建,而是通过参数由外部注入。例:
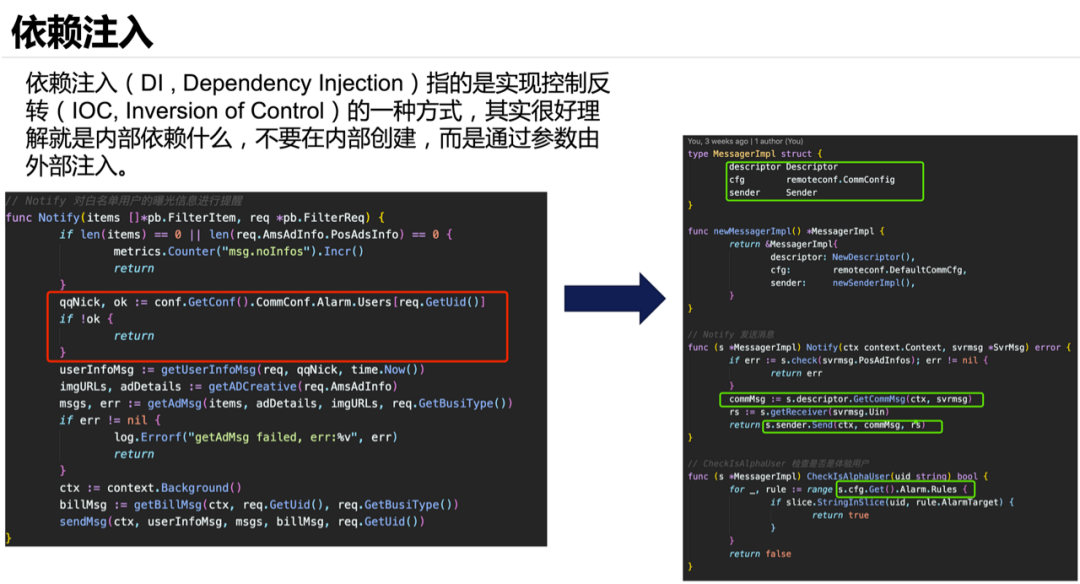
-
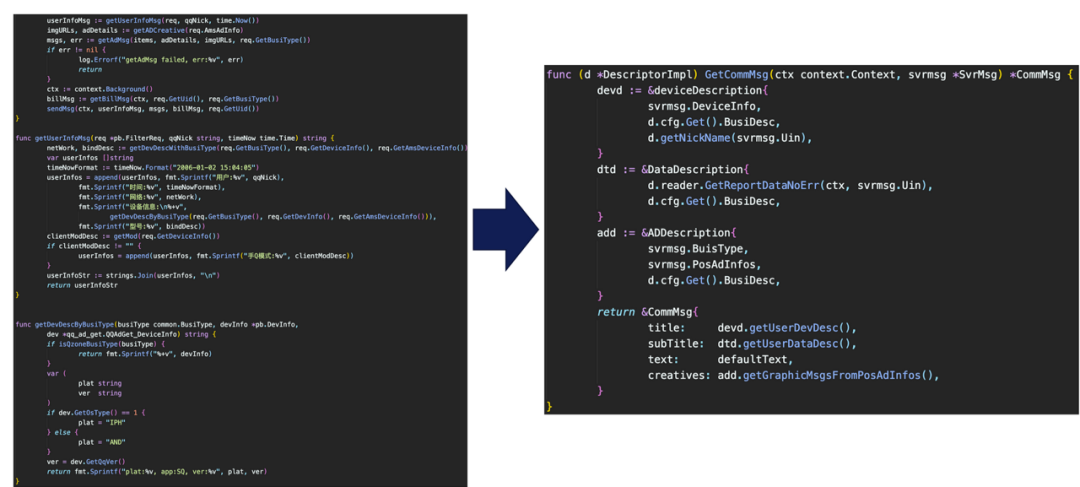
内部封装
-
高内聚低耦合。
-
合理的抽象函数,分子函数,聚类等。
例:
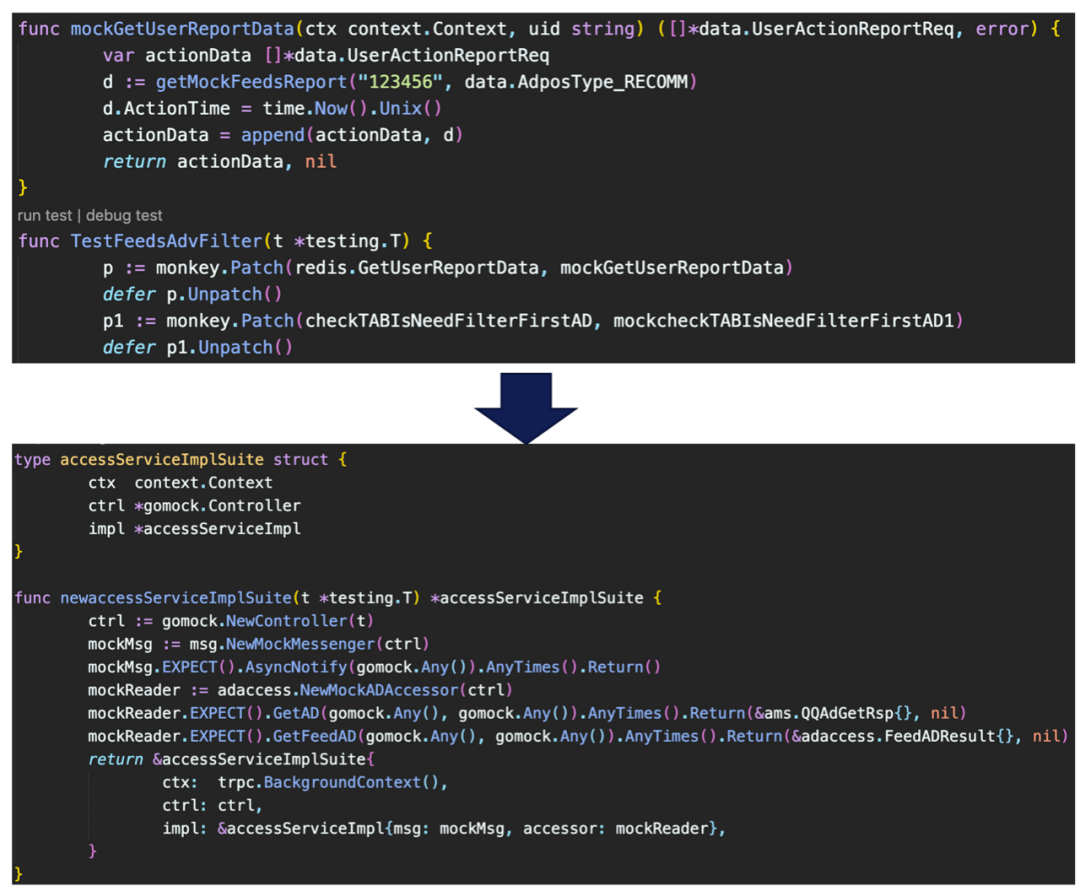
(三)不引入gomock以外的mock包
如果一定要monkey mock来对函数打桩时, 说明代码没有符合接口原则。并且Monkey mock的mock函数不可导出 在每个调用的此函数的包内单测时,都需要重新写一遍mock。
Gomock桩代码可自动生成,上层需要mock下层依赖时,只需要将mock的桩作为依赖注入即可。
(四)配置(远程配置)
现在几乎每个服务除了框架配置外,会接入远程配置(七彩石配置),读取远程配置的逻辑几乎每个服务都要重新实现一遍,因为配置的最终输出一定是一个个性化的结构体(每个服务的配置肯定都不一样),所以很难用一套代码解决,这里采用了一个包替换的方式,将出口的结构体通过引入不同的config entity定义,来实现代码的通用(仅是通用,还实现不了零copy)
-
每个服务一个远程配置。
-
远程配置为json格式(yaml一样,内部统一即可)
-
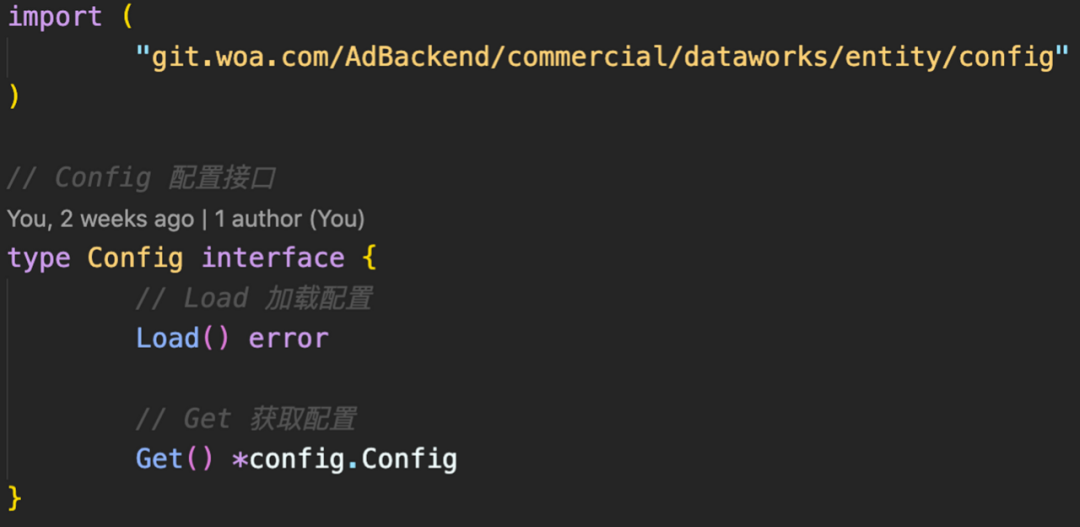
远程配置定义在entity/config包中,结构体为Config。
这样可以复用如下远程配置实现:
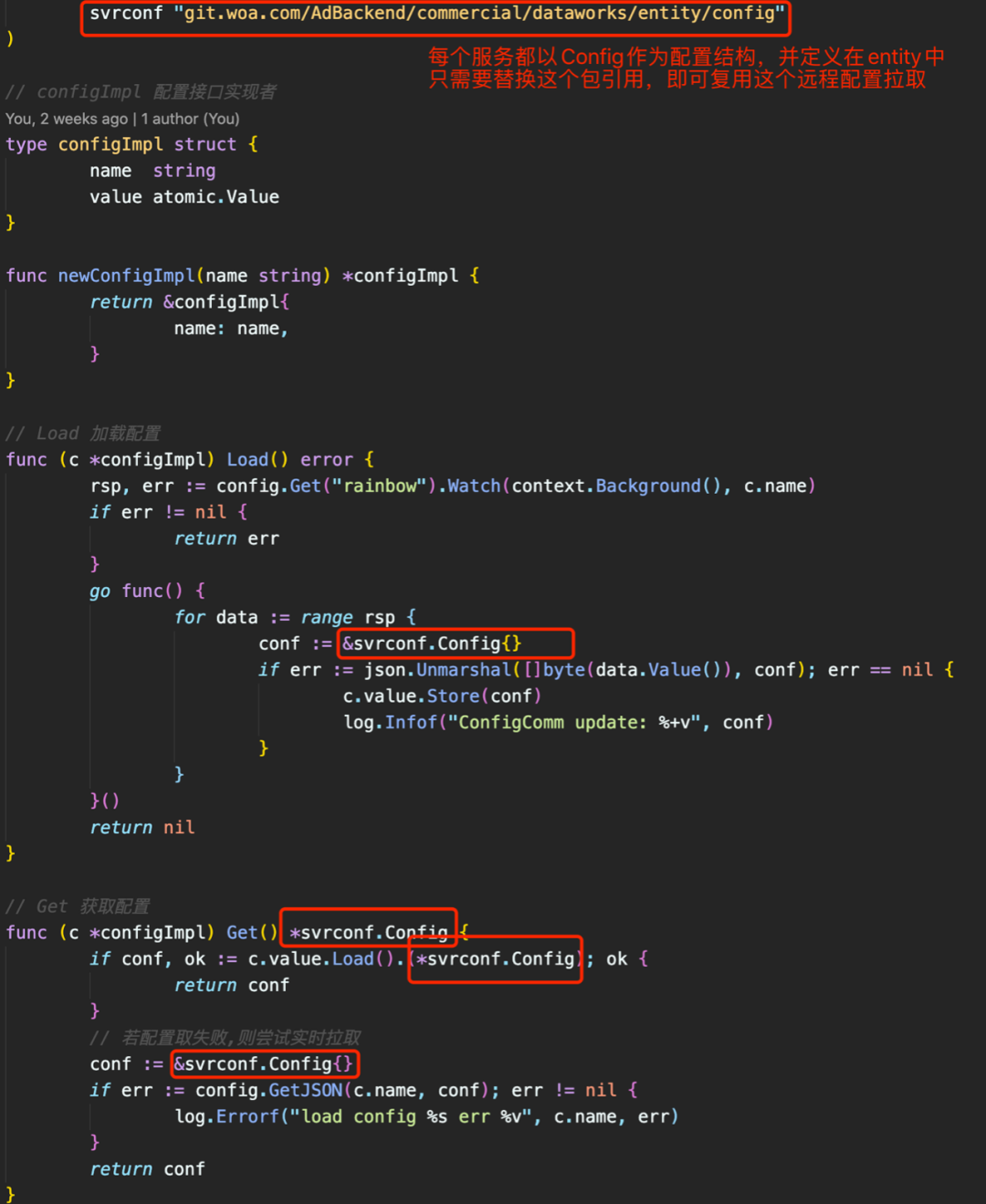
这里如果服务有多个配置:
例:这个服务是重构过的,之前没有规范,所以弄了三个不同的远程配置(实际上一个即可):
因为Get返回的结构不同,所以不同配置使用不同的接口实例来实现,每个不同结构的配置在解析时是固定的结构体,get返回也是固定的结构体,在go模板特性未支持的情况下每个不同文件的配置,以不同实现impl来完成解析, 看起来代码上有一些重复,但这样表达能保证清晰易懂,一般情况一个服务业务配置放在一个文件中。
一个服务一个配置,对于配置初始化等代码的减少,有很大的帮助。
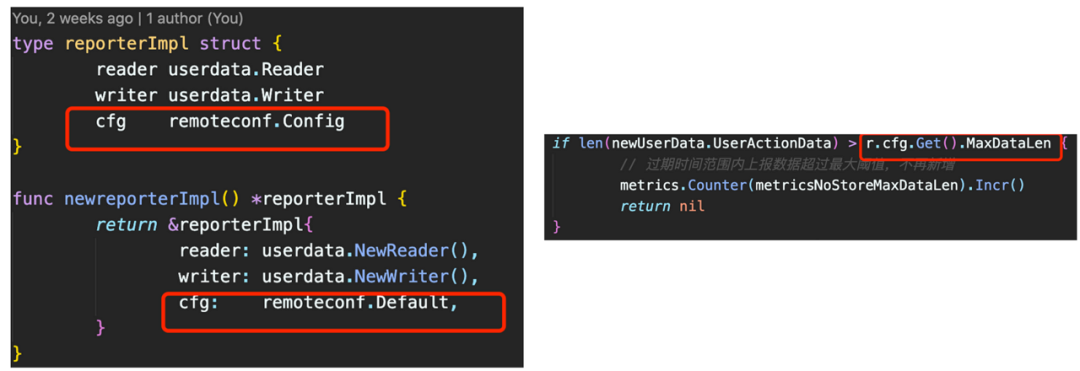
(五)配置的使用
接口化的配置很方便实现依赖注入,摒弃之前那种引入配置包,读取全局配置的方式,通过依赖注入来实现配置作用域减小,避免很多并发问题:
四、落地方法
理想很丰满现实很骨感,需求进度和代码质量的矛盾,如果要一步到位,在实践中等于一步也实行不下去。
实际情况往往是需求很紧急,并没有太多时间给开发用来设计和优化代码,所以我们希望走第一步的时候不会占用开发太多的时间,最好时间分配可以从1:9的方式开始,并且在任何阶段都可以以需求快速完成为优先(即容忍一定程度的不遵守也不会破坏整体),即一开始你可以在90%的自由度上保持你自己旧的风格,抽出10%的时间来设计,这样落实规范并不会很痛苦。

整体落地的步骤可以分为三个阶段(不是必要经历的,时间不紧张可以直接按标准实现来)

根据当前需求的紧急程度和个人时间安排来分阶段实践即可。
五、总结
微服务代码架构的一致性和实现规范的一致性可以带来很多好处:

其实之所以要提DDD,是因为这是个避不开的问题,但答案其实已经有了DDD是把控中大型项目的杀手锏,但使用DDD并不能使开发新项目变得更快,更方便,而是为了今后考虑,让一个庞大的系统可以更快的迭代,更新,也就是说新的项目不用太在意领域驱动设计,甚至新项目开始可以不用领域驱动设计。
DDD的优势和劣势:
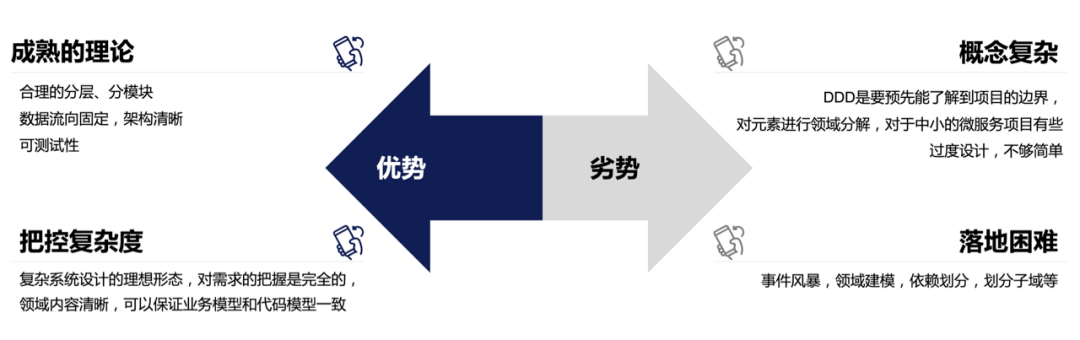
不同的业务可能面临不一样的问题,很多实践中的需求往往不是一开始就有顶层设计的大需求、大项目,甚至很多微服务还没确定自己领域内的元素,就伴随着业务死亡了,创建服务之初领域模型和边界并不清楚,一个一个接口的新服务,从一开始设计时就去事件风暴、划分元素、子域等也是不切实际的,所以越是微小的服务,越是不需要DDD。很多时候我们不得不考虑团队的新成员快速成长的问题,一个新同学或者实习生同学很难快速上手DDD,并把DDD落地到每个服务里,不能全部落地,这样就会存在不同需求服务之间的不一致性,接手同事的服务时,还是会存在理解结构的心智负担。
后记
整体的规则描述了大概,但是实践的过程中,对于内部具体细节,函数的抽象,聚类,子模块的划分,都是经验和实践的积累,还是很考验一个人的代码功底,这点架构规范并不能给予帮助。
好的架构或者说目录设计像是垃圾分类的垃圾桶,预先设置好分类规则,垃圾就可以很轻松的进行分类,分类好的垃圾就可以变废为宝,成为可利用的资源,所以面对垃圾山一样的代码,重构时我们首先要遵循正确的架构进行垃圾分类。
虽然进行了有效的分层,但是对于logic层里面的模块拆分并不要求严格,即提供了抽象接口之后,具体实现是细节问题,随着需求的增长实际上还是面临增长之后带来复杂度关系,但由于拆分了外部调用在repo和数据实例在entity,微服务最终logic的代码并不会膨胀的很快,三层结构可以一定程度的减缓复杂度膨胀的速度,如果有一天膨胀大了,那么使用DDD进行重构可能是另一种解法。
本文是记录一下在寻求最佳的实践过程中的思考和取舍的过程,毕竟对于微服务代码架构的实践没有银弹,不存在哪一种更好的情况,只有相对容易落地和简单有效的方案才比较通用。
参考资料:
1.《架构整洁之道》
2.《tRPC-Go目录规范》
3.《go-clean-arch》