
内容概要
Golang为编译型语言,需要将源代码文件编译之后才能执行。可将Golang的编译过程视为构建Golang程序的第一步,本文结合Golang编译器的源码简单介绍Golang的编译流程。
Golang的自举
Golang从1.5版本开始实现了自举,所谓Golang的自举是指用Golang本身编写Golang编译器的源码,然后将这些源码文件编译即可得到Golang的编译器。下面简单介绍一下编程语言实现自举的流程:
如果要对编程语言B实现自举,需要完成以下步骤:
- 使用A语言(A语言的编译器的实现早于B语言)编写B语言编译器的源码,使用A语言的编译器编译这些源码文件得到B语言编译器对应的可执行文件F。
- 使用B语言本身编写B语言编译器的源码,使用可执行文件F编译这些源码文件得到可执行文件T。
经过上面的2个步骤后,编程语言B就实现了自举。
本文主要参考的Golang源码版本:go1.14 linux/amd64
Golang编译器的执行流程
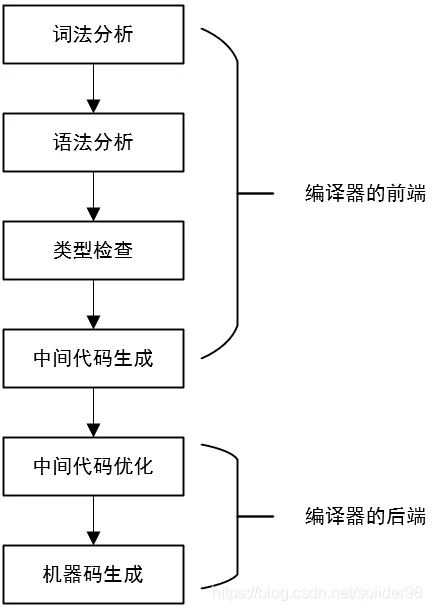
Golang的编译器源码文件位置:$GOROOT/src/cmd/compile/,入口文件:$GOROOT/src/cmd/compile/internal/main.go
调用此包编译后的文件的命令:go tool compile ..., go run ...等。
$GOROOT/src/cmd/compile/internal/main.go:
func main() {
// disable timestamps for reproducible output
log.SetFlags(0)
log.SetPrefix("compile: ")
archInit, ok := archInits[objabi.GOARCH]
if !ok {
fmt.Fprintf(os.Stderr, "compile: unknown architecture %q\n", objabi.GOARCH)
os.Exit(2)
}
gc.Main(archInit)
gc.Exit(0)
}显然主要的流程都在gc.Main中,该函数的主要功能为:通过命令行参数获取要编译的文件和配置,编译指定的文件。
$GOROOT/src/cmd/compile/internal/gc/main.go
//通过命令行参数获取要编译的文件和配置,编译指定的文件。
func Main(archInit func(*Arch)) {
... //读入命令行参数并进行相关初始化操作等
//对flag.Args()中给出的文件进行词法分析和语法分析,将每个源码文件对应的抽象语法树的根结点依次存储在xtop[0]...
lines := parseFiles(flag.Args())
... //阶段1:遍历抽象语法树,收集常量,函数等相关的类型信息。
... //阶段2:遍历抽象语法树,处理变量的赋值。
... //阶段3:遍历抽象语法树,对函数主体进行类型检查。
//检查map的key是否合法,合法的map的key必须是可比较的。
checkMapKeys()
... //阶段4:确定变量的捕获方式。
... //阶段5:遍历抽象语法树,处理内联函数的类型。
... //阶段6:遍历抽象语法树,进行逃逸分析。
... //阶段7:遍历抽象语法树,修改闭包主体,使之正确引用捕获的变量。
... //阶段8:编译每个源码文件的顶层函数。
//使用多个Goroutine并发的编译所有函数。
compileFunctions()
... //阶段9:检查外部依赖的声明。
//进一步检查map的key是否合法。
checkMapKeys()
... //将编译的结果写入磁盘文件。
//检查是否存在某些函数的栈帧过大。
for _, large := range largeStackFrames {
if large.callee != 0 {
yyerrorl(large.pos, "stack frame too large (>1GB): %d MB locals + %d MB args + %d MB callee", large.locals>>20, large.args>>20, large.callee>>20)
} else {
yyerrorl(large.pos, "stack frame too large (>1GB): %d MB locals + %d MB args", large.locals>>20, large.args>>20)
}
}
... //输出编译期间遇到的语法错误等。
}
词法分析和语法分析
从上面的代码中可知,进行词法分析和语法分析的函数为:$GOROOT/src/cmd/compile/internal/gc路径下的parseFiles。
//对filenames中给出的文件进行词法分析和语法分析,将每个源码文件对应的抽象语法树的根结点依次
//存储在xtop[0]...,返回编译的所有文件的总行数。
func parseFiles(filenames []string) uint {
noders := make([]*noder, 0, len(filenames))
//限制并发访问的文件的个数。
sem := make(chan struct{}, runtime.GOMAXPROCS(0)+10)
for _, filename := range filenames {
p := &noder{
basemap: make(map[*syntax.PosBase]*src.PosBase),
err: make(chan syntax.Error),
}
noders = append(noders, p)
go func(filename string) {
sem <- struct{}{}
defer func() { <-sem }()
defer close(p.err)
base := syntax.NewFileBase(filename)
f, err := os.Open(filename)
if err != nil {
p.error(syntax.Error{Pos: syntax.MakePos(base, 0, 0), Msg: err.Error()})
return
}
defer f.Close()
//对文件f进行词法分析和语法分析。
p.file, _ = syntax.Parse(base, f, p.error, p.pragma, syntax.CheckBranches)
}(filename)
}
var lines uint
for _, p := range noders {
for e := range p.err {
p.yyerrorpos(e.Pos, "%s", e.Msg)
}
p.node()
lines += p.file.Lines
//值为nil,可被GC回收。
p.file = nil
if nsyntaxerrors != 0 {
errorexit()
}
// Always run testdclstack here, even when debug_dclstack is not set, as a sanity measure.
testdclstack()
}
localpkg.Height = myheight
//返回编译的所有文件的总行数。
return lines
}
从上面的源码可看出,使用机器核心数+10个Goroutine进行输入文件的词法分析和语法分析。每个单独的文件使用syntax.Parse进行词法分析和语法分析,返回得到的抽象语法树,也即每个源文件对应一个抽象语法树,切片xtop存储所有抽象语法树的根,其元素数量等于命令行参数中输入的文件个数。
$GOROOT/src/cmd/compile/internal/syntax/syntax.go:
func Parse(base *PosBase, src io.Reader, errh ErrorHandler, pragh PragmaHandler, mode Mode) (_ *File, first error) {
defer func() {
if p := recover(); p != nil {
if err, ok := p.(Error); ok {
first = err
return
}
panic(p)
}
}()
var p parser
//初始化词法分析器
p.init(base, src, errh, pragh, mode)
//定位到源码文件中的第一个token
p.next()
return p.fileOrNil(), p.first
}从上面的源码可以看出,主要的处理逻辑集中在函数fileOrNil()中。fileOrNil()返回源码文件生成的抽象语法树,具体的逻辑参见下面的注释。
$GOROOT/src/cmd/compile/internal/syntax/parser.go:
//返回p对应源码文件生成的抽象语法树
func (p *parser) fileOrNil() *File {
if trace {
defer p.trace("file")()
}
f := new(File)
f.pos = p.pos()
//博主添加的defer语句
defer func() {
if os.Getenv("ENABLED_DEBUG") == "true" {
spew.Config.Indent = "\t"
fmt.Printf("f:%v\n", spew.Sdump(f))
}
}()
//处理首行的包声明语句
if !p.got(_Package) {
p.syntaxError("package statement must be first")
return nil
}
f.PkgName = p.name()
p.want(_Semi)
//如果包声明语句存在错误, 则终止余下的语法分析流程
if p.first != nil {
return nil
}
//循环处理包导入语句
for p.got(_Import) {
f.DeclList = p.appendGroup(f.DeclList, p.importDecl)
p.want(_Semi)
}
//循环处理顶层声明语句
for p.tok != _EOF {
switch p.tok {
case _Const:
//const定义的常量
p.next() //返回源码文件中的下一个token
f.DeclList = p.appendGroup(f.DeclList, p.constDecl)
case _Type:
//type定义的类型
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.typeDecl)
case _Var:
//var定义的变量
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.varDecl)
case _Func:
p.next()
//func定义的函数
if d := p.funcDeclOrNil(); d != nil {
f.DeclList = append(f.DeclList, d)
}
default:
if p.tok == _Lbrace && len(f.DeclList) > 0 && isEmptyFuncDecl(f.DeclList[len(f.DeclList)-1]) {
//函数体的'{'和函数声明不在同一行
p.syntaxError("unexpected semicolon or newline before {")
} else {
//函数体之外的非声明语句
p.syntaxError("non-declaration statement outside function body")
}
//不断推进p.tok的进度, 直到p.tok为_Const, _Type, _Var, _Func中的某一个(更具体的参见函数advance的定义)
p.advance(_Const, _Type, _Var, _Func)
continue
}
// Reset p.pragma BEFORE advancing to the next token (consuming ';')
// since comments before may set pragmas for the next function decl.
p.pragma = 0
if p.tok != _EOF && !p.got(_Semi) {
p.syntaxError("after top level declaration")
p.advance(_Const, _Type, _Var, _Func)
}
}
// p.tok == _EOF
f.Lines = p.source.line
return f
}
//仅在dcl表示函数声明语句且函数体为空时返回true
func isEmptyFuncDecl(dcl Decl) bool {
f, ok := dcl.(*FuncDecl)
return ok && f.Body == nil
}
//不断推进p.tok的进度(对应连续调用p.next())直到p.tok为followlist和stopset的并集中元素或者为_EOF, 如果
//p.tok当前位置不是在函数内部, 则不考虑stopset集合中的元素
func (p *parser) advance(followlist ...token) {
if trace {
p.print(fmt.Sprintf("advance %s", followlist))
}
//计算使用uint64表示集合的followset
//当集合中的元素个数较少时, 使用二进制整数表示集合可提高程序的执行效率并降低内存占用.
var followset uint64 = 1 << _EOF // don't skip over EOF
if len(followlist) > 0 {
if p.fnest > 0 {
followset |= stopset
}
for _, tok := range followlist {
followset |= 1 << tok
}
}
//循环执行p.next(), 终止条件为p.tok在followset表示的集合中
for !contains(followset, p.tok) {
if trace {
p.print("skip " + p.tok.String())
}
p.next()
if len(followlist) == 0 {
break
}
}
if trace {
p.print("next " + p.tok.String())
}
}
//stopset为语句起始关键字的集合. 在出现语法错误时, (通常)不应该跳过stopset中的元素.
const stopset uint64 = 1<<_Break |
1<<_Const |
1<<_Continue |
1<<_Defer |
1<<_Fallthrough |
1<<_For |
1<<_Go |
1<<_Goto |
1<<_If |
1<<_Return |
1<<_Select |
1<<_Switch |
1<<_Type |
1<<_Var上面提到p.next()的作用是返回源码文件中的下一个Token,什么是Token?
Token是符合词法规则的字符串,词法分析器的作用就是将源码文件转换为token流,p.next()的作用就是不断获取流中的下一个元素。Golang所有的Token定义在文件:$GOROOT/src/cmd/compile/internal/syntax/tokens.go中。
下面是p.next()方法的整体结构:
$GOROOT/src/cmd/compile/internal/syntax/scanner.go
//返回源码文件对应的Token流中的下一个Token
func (s *scanner) next() {
//博主添加的defer语句
defer func() {
if os.Getenv("ENABLED_DEBUG") == "true" {
spew.Config.Indent = "\t"
fmt.Printf("s.line:%v, s.col:%v, s.tok:%v", s.line, s.col, spew.Sdump(s.tok))
}
}()
//!nlsemi为true表示将'\n'和'EOF'当做';'处理, 此情况下的'\n'不能作为空白字符处理
nlsemi := s.nlsemi
s.nlsemi = false
redo:
c := s.getr()
//跳过空白字符, ' ', '\t', '\r'和!nlsemi条件下的'\n'
for c == ' ' || c == '\t' || c == '\n' && !nlsemi || c == '\r' {
c = s.getr()
}
// token start
s.line, s.col = s.source.line0, s.source.col0
if isLetter(c) || c >= utf8.RuneSelf && s.isIdentRune(c, true) {
//处理下一个Token为关键字或自定义标识符的情况
s.ident()
return
}
switch c {
case -1:
if nlsemi {
s.lit = "EOF"
s.tok = _Semi
break
}
s.tok = _EOF
case '\n':
//将'\n'记录为分号(_Semi)
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(c)
case '"':
s.stdString()
case '`':
s.rawString()
case '\'':
s.rune()
... //省略的代码
}可以看到本人在源码中添加了一些打印语句,编译修改后的源码,得到新的Golang编译器,使用新的编译器编译下面的代码。
package test
var v1 bool
const C1 = 1
type I interface {}
type S struct {}
/*多行注释*/
//单行注释
func add(a, b int) int {
return a + b
}得到的输出如下:
s.line:1, s.col:1, s.tok:(syntax.token) package
s.line:1, s.col:9, s.tok:(syntax.token) name
s.line:1, s.col:13, s.tok:(syntax.token) ;
s.line:3, s.col:1, s.tok:(syntax.token) import
s.line:3, s.col:8, s.tok:(syntax.token) literal
s.line:3, s.col:13, s.tok:(syntax.token) ;
s.line:5, s.col:1, s.tok:(syntax.token) var
s.line:5, s.col:5, s.tok:(syntax.token) name
s.line:5, s.col:8, s.tok:(syntax.token) name
s.line:5, s.col:12, s.tok:(syntax.token) ;
s.line:7, s.col:1, s.tok:(syntax.token) const
s.line:7, s.col:7, s.tok:(syntax.token) name
s.line:7, s.col:10, s.tok:(syntax.token) =
s.line:7, s.col:12, s.tok:(syntax.token) literal
s.line:7, s.col:13, s.tok:(syntax.token) ;
s.line:9, s.col:1, s.tok:(syntax.token) type
s.line:9, s.col:6, s.tok:(syntax.token) name
s.line:9, s.col:8, s.tok:(syntax.token) interface
s.line:9, s.col:18, s.tok:(syntax.token) {
s.line:9, s.col:19, s.tok:(syntax.token) }
s.line:9, s.col:20, s.tok:(syntax.token) ;
s.line:14, s.col:1, s.tok:(syntax.token) func
s.line:14, s.col:6, s.tok:(syntax.token) name
s.line:14, s.col:9, s.tok:(syntax.token) (
s.line:14, s.col:10, s.tok:(syntax.token) name
s.line:14, s.col:11, s.tok:(syntax.token) ,
s.line:14, s.col:13, s.tok:(syntax.token) name
s.line:14, s.col:15, s.tok:(syntax.token) name
s.line:14, s.col:18, s.tok:(syntax.token) )
s.line:14, s.col:20, s.tok:(syntax.token) name
s.line:14, s.col:24, s.tok:(syntax.token) {
s.line:15, s.col:2, s.tok:(syntax.token) name
s.line:15, s.col:4, s.tok:(syntax.token) :=
s.line:15, s.col:7, s.tok:(syntax.token) name
s.line:15, s.col:9, s.tok:(syntax.token) op
s.line:15, s.col:11, s.tok:(syntax.token) name
s.line:15, s.col:12, s.tok:(syntax.token) ;
s.line:16, s.col:2, s.tok:(syntax.token) name
s.line:16, s.col:5, s.tok:(syntax.token) .
s.line:16, s.col:6, s.tok:(syntax.token) name
s.line:16, s.col:11, s.tok:(syntax.token) (
s.line:16, s.col:12, s.tok:(syntax.token) name
s.line:16, s.col:13, s.tok:(syntax.token) )
s.line:16, s.col:14, s.tok:(syntax.token) ;
s.line:17, s.col:2, s.tok:(syntax.token) return
s.line:17, s.col:9, s.tok:(syntax.token) name
s.line:17, s.col:10, s.tok:(syntax.token) ;
s.line:18, s.col:1, s.tok:(syntax.token) }
s.line:18, s.col:2, s.tok:(syntax.token) ;
s.line:18, s.col:2, s.tok:(syntax.token) EOF
f:(*syntax.File)(0xc000320fc0)({
PkgName: (*syntax.Name)(0xc000341220)({
Value: (string) (len=4) "test",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:1:9
}
}
}),
DeclList: ([]syntax.Decl) (len=5 cap=8) {
(*syntax.ImportDecl)(0xc000073ad0)({
LocalPkgName: (*syntax.Name)(<nil>),
Path: (*syntax.BasicLit)(0xc000073b00)({
Value: (string) (len=5) "\"fmt\"",
Kind: (syntax.LitKind) 4,
Bad: (bool) false,
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:3:8
}
}
}),
Group: (*syntax.Group)(<nil>),
decl: (syntax.decl) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:3:8
}
}
}),
(*syntax.VarDecl)(0xc000068550)({
NameList: ([]*syntax.Name) (len=1 cap=1) {
(*syntax.Name)(0xc000341240)({
Value: (string) (len=2) "v1",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:5:5
}
}
})
},
Type: (*syntax.Name)(0xc000341260)({
Value: (string) (len=4) "bool",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:5:8
}
}
}),
Values: (syntax.Expr) <nil>,
Group: (*syntax.Group)(<nil>),
decl: (syntax.decl) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:5:5
}
}
}),
(*syntax.ConstDecl)(0xc0000685a0)({
NameList: ([]*syntax.Name) (len=1 cap=1) {
(*syntax.Name)(0xc0003412a0)({
Value: (string) (len=2) "C1",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:7:7
}
}
})
},
Type: (syntax.Expr) <nil>,
Values: (*syntax.BasicLit)(0xc000073e90)({
Value: (string) (len=1) "1",
Kind: (syntax.LitKind) 0,
Bad: (bool) false,
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:7:12
}
}
}),
Group: (*syntax.Group)(<nil>),
decl: (syntax.decl) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:7:7
}
}
}),
(*syntax.TypeDecl)(0xc000321040)({
Name: (*syntax.Name)(0xc0003412c0)({
Value: (string) (len=1) "I",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:9:6
}
}
}),
Alias: (bool) false,
Type: (*syntax.InterfaceType)(0xc000354060)({
MethodList: ([]*syntax.Field) <nil>,
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:9:8
}
}
}),
Group: (*syntax.Group)(<nil>),
Pragma: (syntax.Pragma) 0,
decl: (syntax.decl) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:9:6
}
}
}),
(*syntax.FuncDecl)(0xc000321080)({
Attr: (map[string]bool) <nil>,
Recv: (*syntax.Field)(<nil>),
Name: (*syntax.Name)(0xc0003412e0)({
Value: (string) (len=3) "add",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:14:6
}
}
}),
Type: (*syntax.FuncType)(0xc0003210c0)({
ParamList: ([]*syntax.Field) (len=2 cap=2) {
(*syntax.Field)(0xc000354330)({
Name: (*syntax.Name)(0xc000341300)({
Value: (string) (len=1) "a",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:14:10
}
}
}),
Type: (*syntax.Name)(0xc000341340)({
Value: (string) (len=3) "int",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:14:15
}
}
}),
node: (syntax.node) {
pos: (syntax.Pos) main.go:14:10
}
}),
(*syntax.Field)(0xc000354420)({
Name: (*syntax.Name)(0xc000341320)({
Value: (string) (len=1) "b",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:14:13
}
}
}),
Type: (*syntax.Name)(0xc000341340)({
Value: (string) (len=3) "int",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:14:15
}
}
}),
node: (syntax.node) {
pos: (syntax.Pos) main.go:14:13
}
})
},
ResultList: ([]*syntax.Field) (len=1 cap=1) {
(*syntax.Field)(0xc0003545d0)({
Name: (*syntax.Name)(<nil>),
Type: (*syntax.Name)(0xc000341360)({
Value: (string) (len=3) "int",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:14:20
}
}
}),
node: (syntax.node) {
pos: (syntax.Pos) main.go:14:20
}
})
},
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:14:9
}
}
}),
Body: (*syntax.BlockStmt)(0xc000321100)({
List: ([]syntax.Stmt) (len=3 cap=4) {
(*syntax.AssignStmt)(0xc000321180)({
Op: (syntax.Operator) :,
Lhs: (*syntax.Name)(0xc000341380)({
Value: (string) (len=1) "c",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:15:2
}
}
}),
Rhs: (*syntax.Operation)(0xc000321140)({
Op: (syntax.Operator) +,
X: (*syntax.Name)(0xc0003413a0)({
Value: (string) (len=1) "a",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:15:7
}
}
}),
Y: (*syntax.Name)(0xc0003413c0)({
Value: (string) (len=1) "b",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:15:11
}
}
}),
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:15:9
}
}
}),
simpleStmt: (syntax.simpleStmt) {
stmt: (syntax.stmt) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:15:4
}
}
}
}),
(*syntax.ExprStmt)(0xc000341440)({
X: (*syntax.CallExpr)(0xc0003211c0)({
Fun: (*syntax.SelectorExpr)(0xc000354960)({
X: (*syntax.Name)(0xc0003413e0)({
Value: (string) (len=3) "fmt",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:16:2
}
}
}),
Sel: (*syntax.Name)(0xc000341400)({
Value: (string) (len=5) "Print",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:16:6
}
}
}),
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:16:5
}
}
}),
ArgList: ([]syntax.Expr) (len=1 cap=1) {
(*syntax.Name)(0xc000341420)({
Value: (string) (len=1) "c",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:16:12
}
}
})
},
HasDots: (bool) false,
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:16:11
}
}
}),
simpleStmt: (syntax.simpleStmt) {
stmt: (syntax.stmt) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:16:11
}
}
}
}),
(*syntax.ReturnStmt)(0xc000341480)({
Results: (*syntax.Name)(0xc0003414a0)({
Value: (string) (len=1) "c",
expr: (syntax.expr) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:17:9
}
}
}),
stmt: (syntax.stmt) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:17:2
}
}
})
},
Rbrace: (syntax.Pos) main.go:18:1,
stmt: (syntax.stmt) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:14:24
}
}
}),
Pragma: (syntax.Pragma) 0,
decl: (syntax.decl) {
node: (syntax.node) {
pos: (syntax.Pos) main.go:14:6
}
}
})
},
Lines: (uint) 18,
node: (syntax.node) {
pos: (syntax.Pos) main.go:1:1
}
})上面1~50行每行对应一个Token,s.line, s.col和s.tok分别为token的起始行,列和字符串表示。
51~369行的部分为抽象语法树的结构。
52~59行为源码文件所在包的信息。
60~364行为源文件中顶层声明的信息,其中:
(1)61~79行对应源码中的语句:import "fmt"
(2)80~106行对应源码中的语句:var v1 bool
(3)107~135行对应源码中的语句:const C1 = 1
(4)136~161行对应源码中的语句:type I interface {}
(5)162~363行对应源码中的语句:
func add(a, b int) int {
c := a + b
fmt.Print(c)
return c
}至此,对Golang的词法分析和语法分析已经具备了整体的认知。
类型检查
先介绍有关类型检查的概念,静态类型检查和动态类型检查。
静态类型检查:通过对源码的分析,在程序执行之前即可确定类型的合法与否。
动态类型检查:在程序的执行过称中动态的检查类型的合法性。
Golang的编译器不仅使用静态类型检查来保证程序的类型安全,还会在编译期间引入类型信息,使程序在运行时可通过反射来获取变量的类型信息。例如空接口转换成具体类型(对应空接口的断言)时就会进行动态类型检查。
回到gc.Main()的这个函数:
$GOROOT/src/cmd/compile/internal/gc/main.go
func Main(archInit func(*Arch)) {
... //省略的代码
lines := parseFiles(flag.Args())
... //省略的代码
//阶段1:遍历抽象语法树,收集常量,函数等相关的类型信息。
timings.Start("fe", "typecheck", "top1")
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op != ODCL && op != OAS && op != OAS2 && (op != ODCLTYPE || !n.Left.Name.Param.Alias) {
xtop[i] = typecheck(n, ctxStmt)
}
}
//阶段2:遍历抽象语法树,处理变量的赋值。
timings.Start("fe", "typecheck", "top2")
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op == ODCL || op == OAS || op == OAS2 || op == ODCLTYPE && n.Left.Name.Param.Alias {
xtop[i] = typecheck(n, ctxStmt)
}
}
... //省略的代码
}静态类型检查主要体现在上面代码中的阶段1和阶段2,具体的检查逻辑在typecheck函数中,下面是typecheck函数的定义:
func typecheck(n *Node, top int) (res *Node) {
... //类型检查前的准备工作
n = typecheck1(n, top)
... //省略的代码
return n
}从typecheck的定义中可以看出类型检查主要在typecheck1函数中完成,typecheck1的主要逻辑是在一个超过1500行的switch语句中根据n.op的值执行不同的分支,下面给出typecheck1的整体结构:
//对以n为根的抽象语法树进行类型检查和相关属性修改,返回修改后的根结点
func typecheck1(n *Node, top int) (res *Node) {
... //省略的代码
switch n.Op {
... //省略的代码
case OTMAP:
ok |= ctxType
n.Left = typecheck(n.Left, ctxType)
n.Right = typecheck(n.Right, ctxType)
l := n.Left
r := n.Right
if l.Type == nil || r.Type == nil {
n.Type = nil
return n
}
if l.Type.NotInHeap() {
yyerror("go:notinheap map key not allowed")
}
if r.Type.NotInHeap() {
yyerror("go:notinheap map value not allowed")
}
setTypeNode(n, types.NewMap(l.Type, r.Type))
mapqueue = append(mapqueue, n) // check map keys when all types are settled
n.Left = nil
n.Right = nil
case OTCHAN:
ok |= ctxType
n.Left = typecheck(n.Left, ctxType)
l := n.Left
if l.Type == nil {
n.Type = nil
return n
}
if l.Type.NotInHeap() {
yyerror("chan of go:notinheap type not allowed")
}
... //省略的代码
case OMAKE:
... //省略的代码
switch t.Etype {
default:
yyerror("cannot make type %v", t)
n.Type = nil
return n
case TSLICE:
... //省略的代码
n.Op = OMAKESLICE
case TMAP:
... //省略的代码
n.Op = OMAKEMAP
case TCHAN:
... //省略的代码
n.Op = OMAKECHAN
}
... //省略的代码
}
... //省略的代码
}终点看上面代码中的case OTMAP,case OTCHAN和case OMAKE分支。
对于case OTMAP和case OTCHAN分支,终点看下面的代码:
if l.Type.NotInHeap() {
yyerror("go:notinheap map key not allowed")
}
if r.Type.NotInHeap() {
yyerror("go:notinheap map value not allowed")
}
... //省略的代码
if l.Type.NotInHeap() {
yyerror("chan of go:notinheap type not allowed")
}上面的代码表明map的key和value以及chan的elem必须是可以在堆上分配的,为何如此?这和map和chan的实现,栈的动态复制都有关系,在后面介绍到map,chan以及Golang栈的复制时会进一步介绍。
从在case OMAKE分支的代码可以看出编译器会根据参数的不同(slice,map或chan)对n.op进行更具体的替换。对于除slice,map和chan之外的类型的参数,编译器会给出错误提示"cannot make type xxx"。
中间代码生成