
字符的历史
1个比特可以是0,也可以是1
8个比特组成了1个字节
全部为0时,代表数字0
全部为1时,代表数字255
1个字节能代表256个数字,两个字节能代表65536个数字
更多的自己可以有更多的组合,更多的字节可以代表更多的范围,
整数可以这样表示,那么字母呢。一堆0和1怎么也算不出字母A吧
这里就需要用到编码了,我们可以用
A->映射数字65->再映射成0100 0001
要存储字符时就,就存储这个数字,要读取时,就通过映射关系找到这个字符。

像这样通过收录许多字符然后给他们一一编号,得到一个字符编号对照表。这就是字符集。
ASCII只收录了128个字母,其扩展字符集也就只有256个。后面通用字符集就出来了 Unicode 1990年开始研发,1994年正式发布。
那汉字怎么办呢,所以出现了GB2312,没有繁体字也不行,BIG5,但是还有。。。这就促成了字符和二进制的合作。但是有了字符集就万事大吉了吗?那怎么存储这个内容呢“eggo世界”
1个直接的办法就是转换成二进制,如果使用unicode字符集,拿到编号直接组合。就会拿到一大串二进制数位。问题出现了
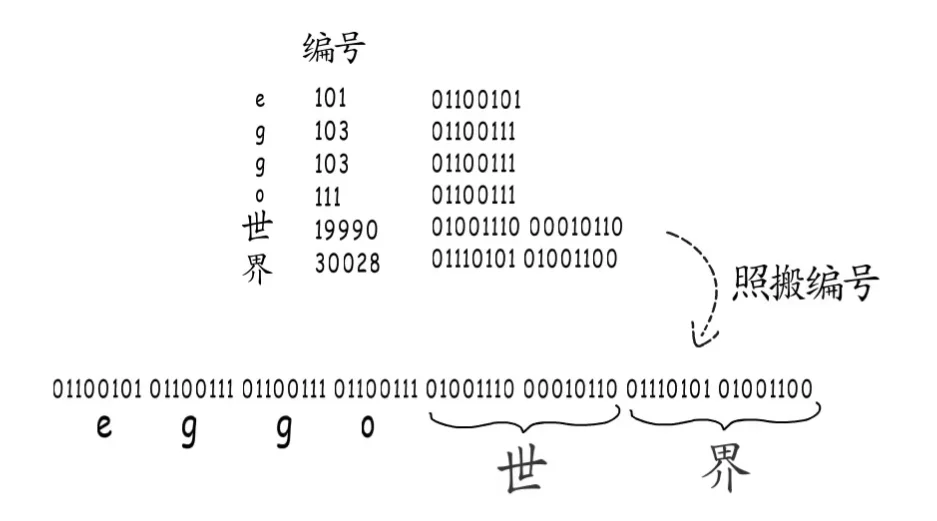
你怎么知道字符串内容要这样划分,也可以这样划分啊

所以直接编号的方式是不可行的。那能不能直接定义一个长度,统一按照一种长度来保存,位数不足,高位补0。答案是可以的,这就是定长编码。但是就会造成大量空间的浪费,比如e用00000000 00000000 00000000 0110010132位来表示,就会有很多的无效位。
定长编码不行,就用变长编码。来看一种解决方案。小编好用少字节,大编号用多字节。

但是怎么划分字符边界呢?
第一种,编号0-127 使用0xxxxxxxx来表示,x可以去0和1,开头的0作为固定标识位
第二种,如果是128-2047 那么使用110xxxxx 10xxxxxx这种方式来表示 110和10作为固定标识位。
第三种,2048-65525 同样的使用1110xxxx 10xxxxxx 10xxxxxx三个字节来表示
来举个例子
0110 0101 0开头说明是1个字节,转换成数字就是101 再通过字符集映射就是"e"
11100100 10111000 10010110,1110开头说明是3个字节,我们转换成十进制数字就是19990,就是汉字“世”
然后字符要怎么变成二进制呢。
同样的世界的“界”,我们找到Unicode字符集中的十进制表示是30028,符合第三种情况,于是我们映射成1110xxxx 10xxxxxx 10xxxxxx,然后把编号转换成二进制01110101 01001100填入模板中。
理解GO的字符串实现
上述编码方式其实就是GO中默认的UTF8编码。
现在我们已经知道了字符串要怎么存了,需要用字符集配合编码才可以。
接下来我们看看字符串变量是什么结构。
首先我们需要起始地址,这样我们才知道数据存在内存哪里。
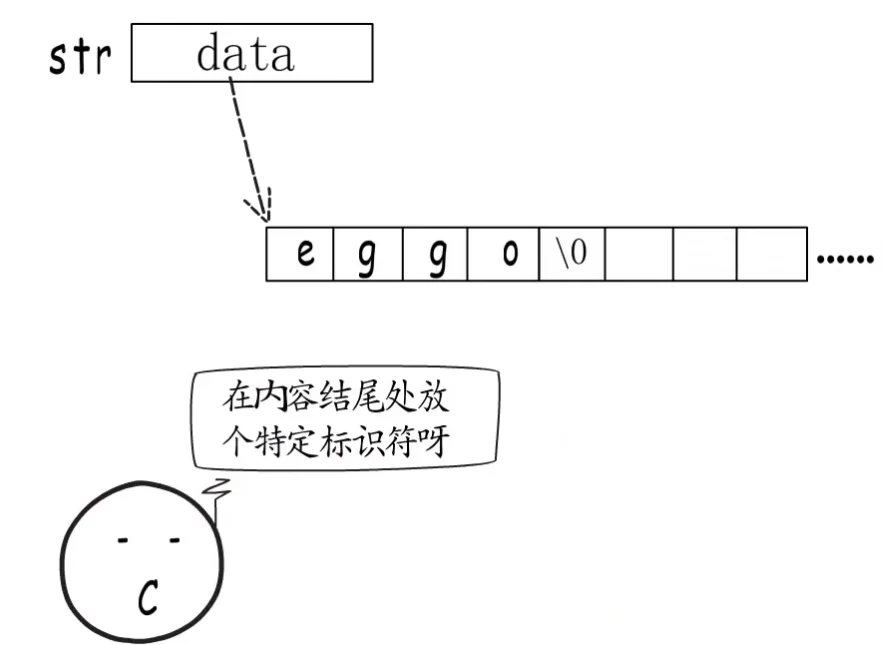
c语言说我们再内容结尾的地方放一个特定标识不就好了。C语言用的是编号为0的字符,但这就限定了我们不能再出现这个标识符了,否则就会出现不可预估的后果,所以GO没有采用这种方式,而是在地址数据的后面再添加一个长度字符,这个长度并不是字符个数(字符长度不定),而是字节数(字节是固定8位)。
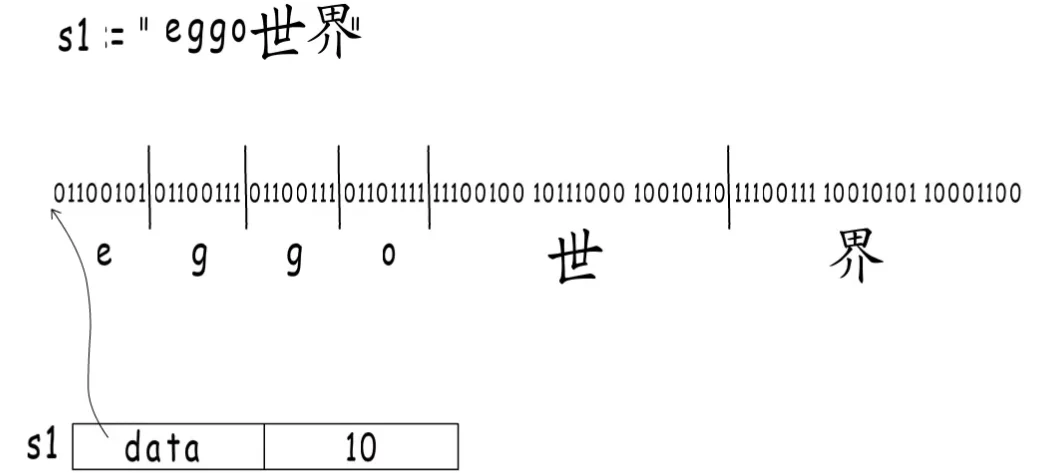
这样既可以找得到起始地址,也可以知道字符串长度,也不限制内容。
OKgo语言中的字符串变量就是以这种形式保存的。另外注意。我们可以读取字符串中的内容,但是不允许通过str[i]='o'这种形式修改字符串。
一部分原因是GO语言认为字符串内容是不会修改的,所以编译器会把这种形式的字符串分配到只读内存中。内存中,这些读,写,执行等权限为了保护程序的政策运行,但是也限制了我们不能修改只读的内容。另外字符串变量是可以共用底层字符串内容的。
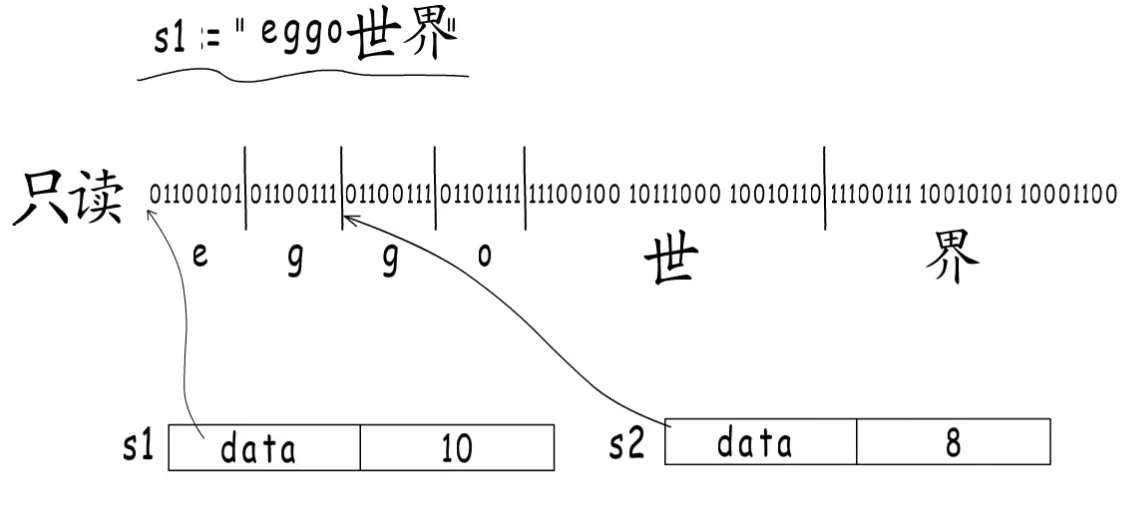
如果我们修改了s1的内容,那么s2所打印的内容也会被修改,这样的影响是不可预测的。如果非要修改,可以直接给整体变量赋新值,它存储的地址就会改变,并不会影响原来的数组。也可以把变量强制转换成slice
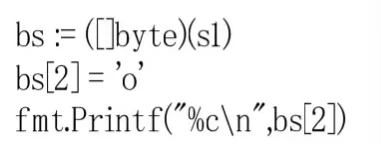
这样会为slice变量重新分配新的内存,并且会拷贝原来字符串的内容,同样可以脱离只读内存的限制。