
Labs 导读


Part 01 ●并发的硬件基础 ●
1.1 内存
作为并发编程一个基础硬件知识储备,首先要说的就是内存了,对于内存芯片网上喜欢将其表述为内存颗粒,是一堆MOS管的集合,在半导体称呼里面,很多MOS管组成一个半导体组(module),很多个module组成一个管芯(die),这个die即是内存颗粒,当然,更上一级即很多die组成的东西叫做晶圆(wafer)。
简单来说,每8个MOS管组成的电路可以表示一个字节,比如ASCII的‘A’,我们使用65表示,即0100 0001,那么8个MOS分别使用低-高-低-低-低-低-低-高电位即可表示字符A。
在对内存的写入和读取时,通常也是按照8个字开始作为一组进行操作,我们现在常用的CPU是64位,可以一次性处理64/8=8个字节的数据。
1.2 总线
总线的概念同我们高速公路的概念类似,就像京沪高速的存在不仅仅只是用于北京和上海之间的交通通勤,只要目的地是那个地理区间的车辆都可以行驶进入京沪高速,从而提升车辆速度节省时间。总线是计算机各种功能部件之间传送信息的公共通信干线,按照分类又地址总线、数据总线、控制总线等,他们分辨用来传输数据地址、输出以及控制信号,它是计算机中用于传递信息的公用通道。
一个CPU要操作内存的数据,也是通过总线来进行操作的。通常来说内存的读写操作不是一个CPU指令周期能完成的,在这期间如果多个程序在同时操作一个内存地址,则有各种意外的读写操作。
1.3 CPU
在单核CPU时期,硬件一次只能处理一个事情,在多任务的情况下不同的任务按需抢占CPU来执行它的代码,这里面就涉及到CPU调度工作,通常情况下,操作系统已经帮我们做了很多事,如果一个编程语言开启的并发操作是交给了操作系统的,那么调度这块不需要太关心,如果像Golang这样有自己的协程调度器,还是需要专门了解下特有的调度方式。对于多核处理器基本原理也差不多,在对于硬件的理解上也可以完全参考单核。
CPU通过地址总线去寻找内存地址,比如0x00004567这种,64位CPU最大能操作的地址长度为264,32位操作系统则是232,所以为什么32位CPU最大只支持4GB内存呢?来算一算232是多少(友情提示1GB=1024MB=1024*1024KB=1024*1024*1024B)。
Part 02 ●并发的软件基础●
2.1 多进程模型
多进程模型是操作系统层面进行并发的最基本模型,要理解它也较为简单,比如我们需要听歌便打开了音乐播放器,我们想玩游戏便打开了游戏用用程序,音乐播放器、游戏程序便是一个个进程,我们可以在计算机里让专门的进程负责播放声音,让专门的进程负责网络连接,让专门的进程展现游戏画面,让每个进程做自己专注的事情,互不影响,这样做的坏处便是系统开销是最大的,所有的进程都由操作系统进行管理。
2.2 多线程模型
同多进程模型一样,多线程模型在操作系统看来也属于系统层面的并发模式,到目前为止也是程序员们使用最多的一种,就像我们的音乐播放器本职工作是播放音乐,在播放音乐的同时会搜索当前歌曲的歌词并通过网络下载到计算机上,而搜索歌词并下载这块功能则是通过音乐播放器进程生成一个歌词处理线程进行处理。对于线程模型的理解可以同理解进程模型一样,每个线程也可以专注做自己的事情互不影响,这种模型的好处是系统开销比多进程模型要小一些,但是线程过多也会对操作系统有影响。
2.3 异步IO模型
这种模型的诞生源于多进程、多线程导致系统资源快速耗尽的危机,异步IO顾名思义即不会按照顺序一步一步地做事情,在某些比较耗时的事情的上时候应用的进程/线程不会去等待,而是直接执行后面的步骤,直到比较耗时的事情做完了再通知到进程/线程。这种模型的优势是可以开辟少量的线程做更多的事情,但是缺点也显而易见,由于整个应用程序的执行流程上被打散,程序员需要通过更多精力处理这种散乱的执行状态。
2.4 协程模型
协程本质上是一种由进程自身管理的线程,这种线程不交给操作系统进行管理,但是本身又真实地寄存在操作系统的线程中,系统开销极小,也避免了异步IO的散乱缺点,目前的缺点是支持这种模型的编程语言很少,存在比较早的,被大众所使用的一些编程语言因为各自的历史原因目前都没有大规模地针对这种模型进行适配,有一门比较新的编程语言——Golang对于该模型的支持还算不错。接下来我们就通过Golang的几个示例代码来看看并发编程一些具体操作。
Part 03 ●几个代码示例●
示例一
//非并发方式计算变量A从0开始累加100次,最后输出结果


示例二
//变量A从0开始累加100次,每次都由单独的协程并发进行加法操作,最后输出结果
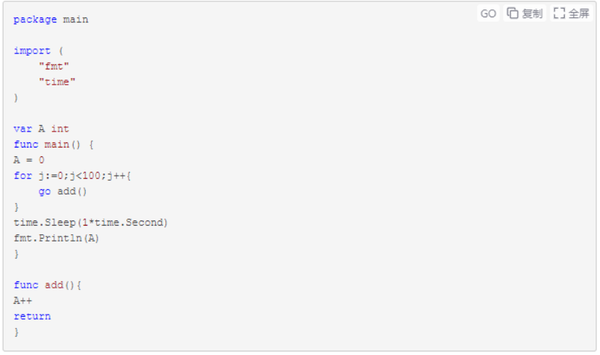
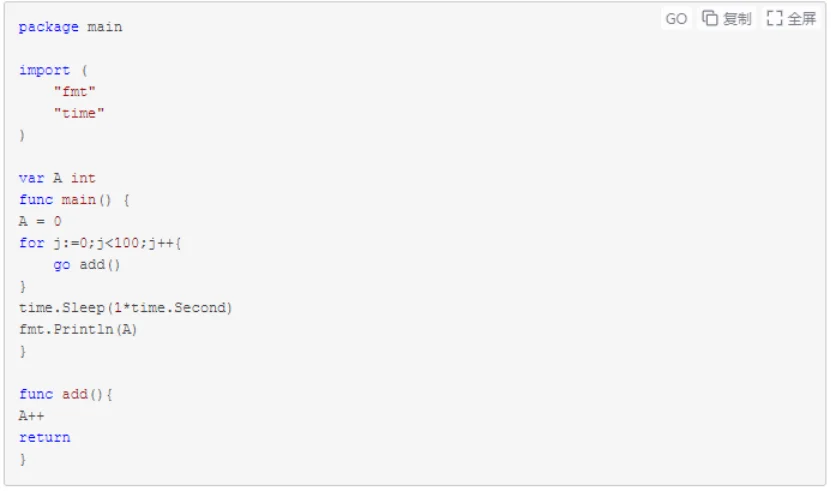
示例一个示例二都将输出什么呢:绝大多数情况下都是100。
按照正常的理解,示例二不应是1-100之间的任意数字吗,难不成go的协程还自动处理了变量抢占等一系列问题,从而使我们就完全很开心地编码了?实际上先把示例二的100改成10000再看看结果吧~
我们再看看示例三和示例四:
示例三
//非并发方式输出变量i从0-10000每次加1的循环结果


示例四
//多协程方式输出变量i从0-10000每次加1的循环结果
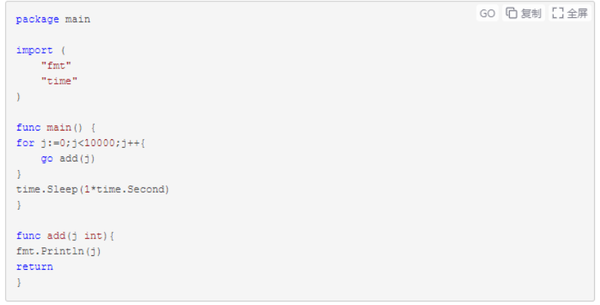
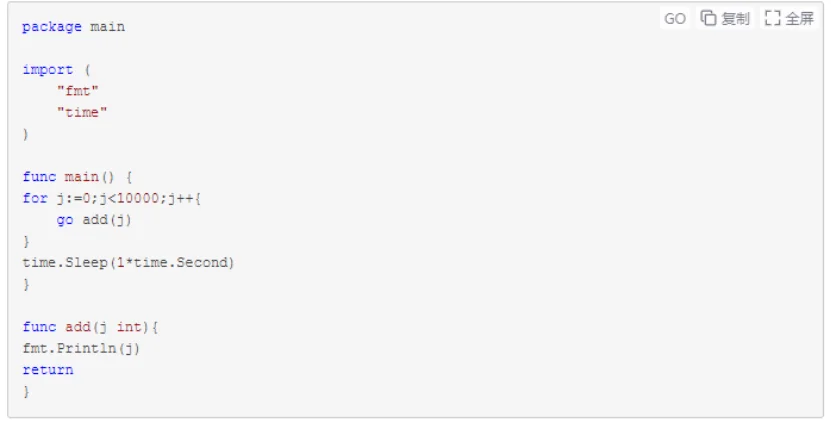
示例三是中规中矩的单协程模型,输出也不会有什么意外,而示例四大家猜猜是按照1,2,3...9999这样的顺序呢还是其他顺序输出呢?
如果实验了我们便能较为容易地得出结果,多协程模型里面的东西没有顺序性,对变量的操作也没有原子性,和多线程模型处理东西的方式几乎一样。
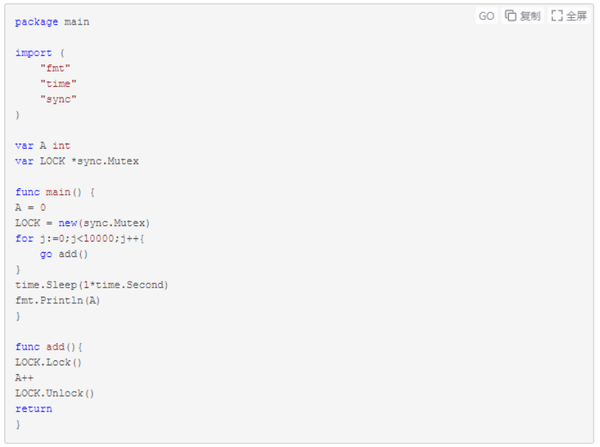
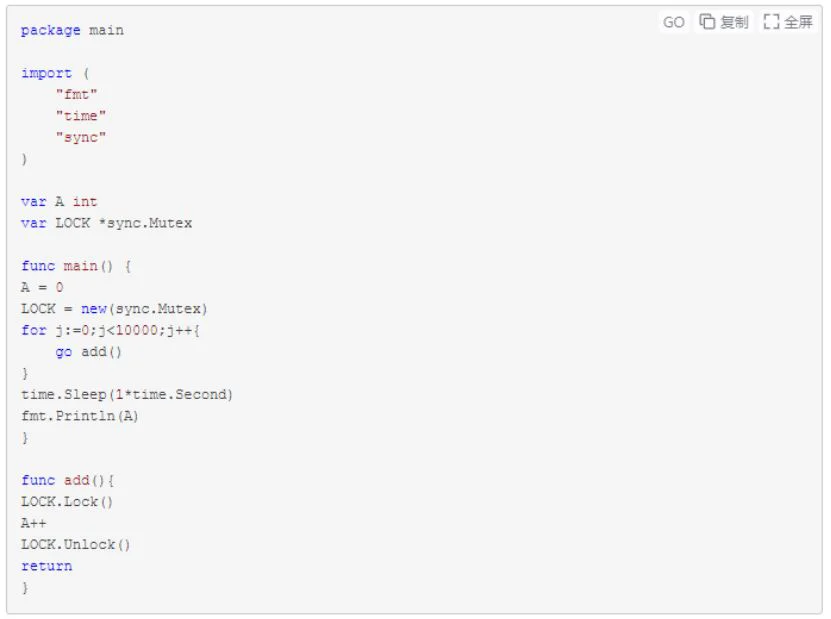
有些场景下为了保证应用程序执行有序,我们通常采用加锁的方式进行处理,如示例五。
示例五
//多协程加锁处理使之有序:
- 搬砖例子
假设在左边有三堆散乱的砖,我们需要将其从左边搬运到右边并堆放整齐,这样的一个工作我们从并发模型来看有哪些比较可执行的实现方式呢:
1、每堆砖头分配固定的人数,堆砖时为保证堆叠整齐度,采用排队的方式一个一个按先后顺序堆叠
2、拿一个人专职在左边递砖,若干人从左边的递砖人处拿砖,搬砖后在右边排队堆叠
3、左边专人递砖,右边专人堆砖,若干搬砖人只负责搬砖
这也是并发编程模型中比较常用的编程思路,在以后遇到类似开发场景也可以套用这些例子。
- 一个实际案例
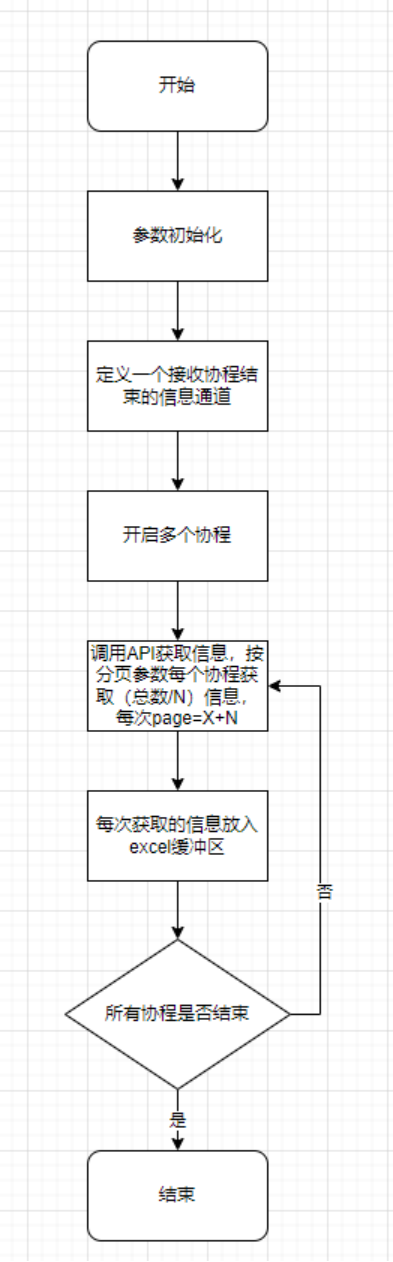
我们以一个实际的案例作为结束,这个案例是导出某云平台所属设备信息的代码,里面包含有多协程拉取数据的实例,整体的流程如下:
1.参数初始化
2.定义一个接收协程结束的信息通道
3.开启N个协程
4.协程调用API获取信息,按分页参数每个协程获取(总数/N)信息,每次page=X+N
5.每次获取的信息放入excel缓冲区
6.当最后的分页获取不到信息时向通道写入东西表示该协程任务完成
7.主进程循环获取每个协程结束的信息,直到所有协程任务完成
8.将excel缓冲区数据写入excel文件
9.结束
案例链接如下(cm-heclouds为物联网公司平台部存放开源代码的专用账户):
当然,这个案例在并发上其实还存在较大的提升空间,聪明的大家看看结合搬砖的例子来怎么提升呢。

