
并发
多线程程序在一个cpu上调度交替时间运行
并行
多线程程序在多个cpu上同段时间运行
进程
程序执行过程,系统分配资源和调度的基本单位
线程
cpu运算调度的最小单位(KSE,Kernal Scheduling Entity),进程至少有一个主线程
协程
主线程开启的逻辑上轻量级线程,独立栈空间,共享堆空间,调度由用户空间控制。
通信模型
CSP communicating sequential process
顺序通信进程模型,使用通道收发减少协程间共享内存带来的锁开销。
share memory
共享内存进行线程间通信,需要利用内存屏障(锁)保证内存的多线程共享内存可见一致性。
线程模型
1. 用户级线程模型M:1
M个用户线程映射到1个内核线程(KSE),用户空间上进行线程管理调度
优点:
1. 用户线程切换上下文比内核线程模态切换性能更高
缺点:
1. 内核线程被某个用户线程阻塞后(如IO)会阻塞整个程序
2. 本质单内核线程,需要多进程才能充分使用多核CPU资源
2. 内核级线程模型1:1
用户线程1:1映射到内核线程(KSE),内核调度器进行管理调度
优点:
1. 多线程充分使用多核CPU资源,不会因单个用户线程阻塞影响程序
缺点:
1. 每个用户线程都需要创建一个内核线程,创建线程的开销大,性能低。
2. 多进程使用多核CPU开销大。
3. 两级线程模型M:N
M个用户线程映射到N个内核线程(KSE),用户空间上进行用户线程管理调度,内核空间由内核调度内核线程。
优点:
1. 大部分调度切换发生在用户空间,开销小性能高
2. 充分利用多核cpu,没有线程阻塞影响整个程序风险
缺点:
1. 依赖用户空间调度器优化
使用两级线程模型改进
-
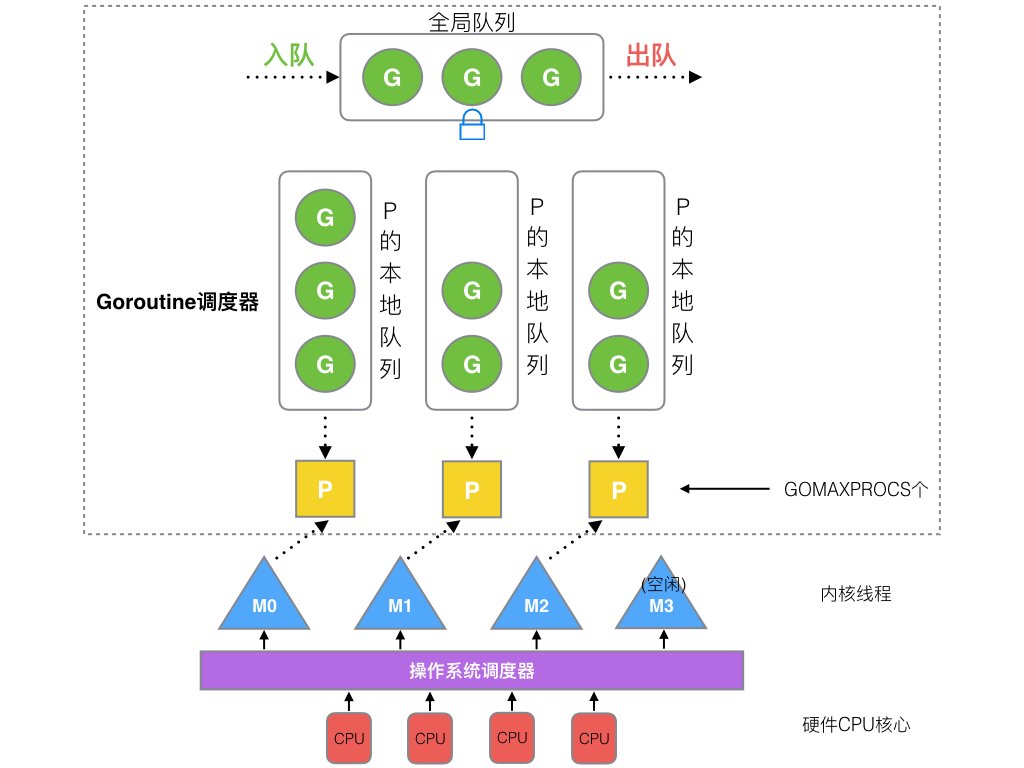
M(Main Thread): go封装的虚拟用户线程,对应1个内核线程(KSE)
- 启动程序后的编号为0的主线程M0。
- 在全局变量runtime.m0,不需要在heap分配
- 负责执行初始化调度器,启动第一个G,之后与其他M一样
- M绑定有效P,M会启动一个内核线程KSE进入调度循环,处理P管理的G。
- LRQ空,(work stealing机制),M窃取G,详见Shedule。
- G阻塞,当前M释放P进入睡眠,(hand off机制),P没有空闲M可用会创建M,新M接管P。
- 没有的P需要空闲M则回收M。
- M默认上限10000,debug.SetMaxThreads()设置,实际由P决定。
- 启动程序后的编号为0的主线程M0。
-
P(Processor):go封装的"CPU",P的数量即为协程最大并行数量
- P最大数量由GOMAXPROCS配置,默认为CPU核心数,启动程序后初始化所有P。
- 处理器
- G执行环境(Context)
- 内存分配(mcahe)
- 本地队列(LRQ) 最大256
- LRQ满则放至G的全局队列(GRQ)
-
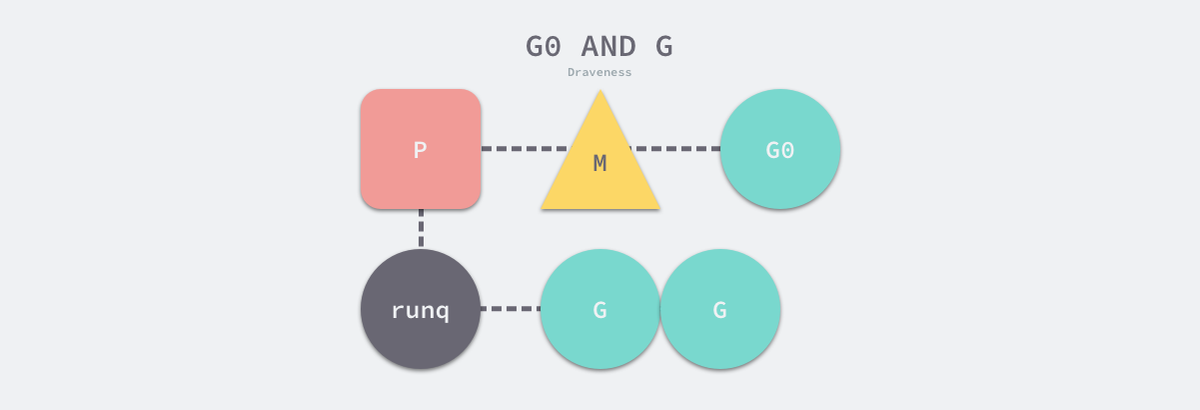
G(Goroutine):go封装的调度单元
- go func 关键字创建G
- 协程结构体
- 运行堆栈
- 状态
- 函数及参数
- G绑定P才能被调度执行
- G0是每一个启动的M第一个创建的G
-
G0深度参与调度G
-
调度或者系统调用时M切换G0,使用G0的栈空间调度
-
-
Sched:go封装的调度器
- 调度器
- G的全局队列(GRQ)
- M的全局队列
- 调度器状态
- 调度器
调度策略
GOMAXPROCS源码分析
G
详见goroutine
M
// runtime2.go/runtime.m
type m struct {
// G相关
g0 *g //持有调度栈的goroutine(深度参与M调度)
curg *g //当前M运行的用户goroutine
// P相关
p puintptr //当前M正在运行的处理器
nextp puintptr //暂存的处理器
oldp puintptr //执行系统调用之前处理器
// M相关
spinning bool // 自旋状态
// 信号处理
gsignal *g // signal-handling g
//其他字段
...
}
// ------- M 初始化 ----------
// Pre-allocated ID may be passed as 'id', or omitted by passing -1.
func mcommoninit(mp *m, id int64) {
_g_ := getg()
// g0 stack won't make sense for user (and is not necessary unwindable).
if _g_ != _g_.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
mp.fastrand[0] = uint32(int64Hash(uint64(mp.id), fastrandseed))
mp.fastrand[1] = uint32(int64Hash(uint64(cputicks()), ^fastrandseed))
if mp.fastrand[0]|mp.fastrand[1] == 0 {
mp.fastrand[1] = 1
}
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + _StackGuard
}
// 添加到 allm 中,从而当它刚保存到寄存器或本地线程存储时候 GC 不会释放 g.m
mp.alllink = allm
// NumCgoCall() 会在没有使用 schedlock 时遍历 allm,等价于 allm = mp
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
//其他代码
...
}
P
// runtime2.go/runtime.p
const (
// P status 状态
// 处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空
_Pidle = iota
// 被线程 M 持有,并且正在执行用户代码或者调度器
_Prunning
// 没有执行用户代码,当前线程陷入系统调用
_Psyscall
// 被线程 M 持有,当前处理器由于垃圾回收被停止
_Pgcstop
// 当前处理器已经不被使用
_Pdead
)
// runtime2.go/runtime.p
type p struct {
// P 自身
id int32
status uint32
// M 相关
m muintptr //当前持有P的M(nil 则表示 idle)
mcache *mcache //
pcache pageCache
// G 相关
lock mutex
runqhead uint32 //本地队列头
runqtail uint32 //本地队列尾
runq [256]guintptr //P本地G队列 256 缓存友好
runnext guintptr //下一个需要执行的G 局部性原理,为了尽量保证新创建G尽量在同一个P中
//其他字段
...
}
schedt
// runtime/runtime2.go/runtime.schedt
type schedt struct {
// G相关
lock mutex
runq gQueue // 全局G队列,链表
runqsize int32
gFree struct { // 有效 dead G 的全局缓存.
lock mutex
stack gList // 包含栈的 Gs
noStack gList // 没有栈的 Gs
n int32
}
// P相关
pidle puintptr // 空闲 p 链表
npidle uint32 // 空闲 p 数量
// M相关
nmspinning uint32 // 自旋状态的 M 的数量
// 其他代码
...
}
//--------------------- 调度器启动 ---------------------
// runtime/proc.go/schedinit
func schedinit() {
// 其他代码
...
_g_ := getg() // g0
// 其他代码
...
sched.maxmcount = 10000 // 线程默认上限数
mcommoninit(_g_.m, -1) // 初始化M
// 其他代码
...
procs := ncpu // 初始化P
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
// 其他代码
...
}
//--------------------- 调度循环 ---------------------
// 1.P每61循环,尝试获取平分全局G
// 2.P尝试P的runnext局部优先获取G
// 3.P本地G尝试获取G
// 4.P尝试从全局G平分G
// 5.P尝试从网络轮询器获取G
// 6.P尝试从其他P窃取1半G到自己本地G队列
// runtime/proc.go/schedule
func schedule() {
_g_ := getg()
// 其他代码
...
top:
// 其他代码
...
var gp *g
var inheritTime bool
// 其他代码
...
if gp == nil {
// 1. 每执行61次循环看一下全局队列。为了保证公平,避免全局队列一直没有得到执行。
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
// 2. 先尝试从p的runnext和本地队列查找G
gp, inheritTime = runqget(_g_.m.p.ptr())
}
if gp == nil {
// 3. 本地g先找
// 4. 仍找不到,去全局队列中查找G
// 5. 找不到,去网络轮询器中查找G
// 6. 找不到,去其他g中窃取G
gp, inheritTime = findrunnable()
}
// 其他代码
...
//调用execute,继续调度循环
execute(gp, inheritTime)
}
//--------------------- 运行G ---------------------
// 1. 准备G的
// 2. 调度M执行
// runtime/proc.go/execute
func execute(gp *g, inheritTime bool) {
// 1. 准备G的
_g_ := getg()
_g_.m.curg = gp
gp.m = _g_.m
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
if !inheritTime {
_g_.m.p.ptr().schedtick++
}
// 其他代码
...
// 2.调度M执行
gogo(&gp.sched)
}
//--------------------- 全局队列G ---------------------
// 1.窃取G = 全局G/P+1
// 2.窃取G <= P/2 = 128
// 3.更新P的本地队列
// runtime/proc.go/globrunqget
func globrunqget(_p_ *p, max int32) *g {
assertLockHeld(&sched.lock)
if sched.runqsize == 0 {
return nil
}
// 1. 计算窃取g个数 = 全局g数量/p数量+1
n := sched.runqsize/gomaxprocs + 1
if n > sched.runqsize {
n = sched.runqsize
}
if max > 0 && n > max {
n = max
}
// 1.2 窃取g个数最大为当前g的一半即128个
if n > int32(len(_p_.runq))/2 {
n = int32(len(_p_.runq)) / 2
}
// 2. 窃取g到本地队列,返回窃取的第1个
sched.runqsize -= n
gp := sched.runq.pop()
n--
for ; n > 0; n-- {
gp1 := sched.runq.pop()
// 1.2. 更新p的本地队列
runqput(_p_, gp1, false)
}
return gp
}
//--------------------- worksteal机制 ---------------------
// 1.本地G找
// 2.全局G平分
// 3.轮询器中查找G
// 4.窃取其他P一半G
// a.4次尝试
// b.P选择使用伪随机保证公平
// c.最后一次尝试,如果发现定时器则尝试本地查找,否则进入新的调度循环
// runtime/proc.go/findrunnable
func findrunnable() (gp *g, inheritTime bool) {
_g_ := getg()
top:
_p_ := _g_.m.p.ptr()
// 其他代码
...
// 1.本地G找
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// 2.全局G窃取
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false
}
}
// 3.轮询器中查找G
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
}
// 4.窃取其他P一半g
procs := uint32(gomaxprocs)
ranTimer := false
// If number of spinning M's >= number of busy P's, block.
// This is necessary to prevent excessive CPU consumption
// when GOMAXPROCS>>1 but the program parallelism is low.
if !_g_.m.spinning && 2*atomic.Load(&sched.nmspinning) >= procs-atomic.Load(&sched.npidle) {
goto stop
}
if !_g_.m.spinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
const stealTries = 4 // 4.1尝试4次偷取
for i := 0; i < stealTries; i++ {
stealTimersOrRunNextG := i == stealTries-1
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
if sched.gcwaiting != 0 {
goto top
}
p2 := allp[enum.position()]
if _p_ == p2 {
continue
}
// 第四次循环检查定时器
if stealTimersOrRunNextG && timerpMask.read(enum.position()) {
tnow, w, ran := checkTimers(p2, now)
now = tnow
if w != 0 && (pollUntil == 0 || w < pollUntil) {
pollUntil = w
}
if ran {
// 如果存在定时器,大概率本地有g,从新获取一次本地G
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// 没有则从新进入循环
ranTimer = true
}
}
// 4.2 p2不空闲,则窃取G
if !idlepMask.read(enum.position()) {
if gp := runqsteal(_p_, p2, stealTimersOrRunNextG); gp != nil {
return gp, false
}
}
}
}
if ranTimer {
// 重新进入调度循环
goto top
}
stop:
// 其他代码
...
}
//--------------------- 窃取g ---------------------
// runtime/proc.go/runqsteal
func runqsteal(_p_, p2 *p, stealRunNextG bool) *g {
t := _p_.runqtail
// 1. 窃取P2g到当前p本地队列
n := runqgrab(p2, &_p_.runq, t, stealRunNextG)
if n == 0 {
return nil
}
// 2. 窃取1个直接返回
n--
gp := _p_.runq[(t+n)%uint32(len(_p_.runq))].ptr()
if n == 0 {
return gp
}
// 2.1 多个需要处理锁
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
if t-h+n >= uint32(len(_p_.runq)) {
throw("runqsteal: runq overflow")
}
atomic.StoreRel(&_p_.runqtail, t+n) // store-release, makes the item available for consumption
return gp
}
//--------------------- 窃取g ---------------------
// 1. 计算窃取G数量 n = n - n/2
// 2. n = 0 如果偷取达到四次且有定时器等,尝试获取runnext
// 3. n > 当前P的G队列,溢出从新计算
// 4. 拷贝G到当前P的G队列
// runtime/proc.go/runqgrab
func runqgrab(_p_ *p, batch *[256]guintptr, batchHead uint32, stealRunNextG bool) uint32 {
for {
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with other consumers
t := atomic.LoadAcq(&_p_.runqtail) // load-acquire, synchronize with the producer
n := t - h // 计算本地队列有多少G
n = n - n/2 // 取一半的G
if n == 0 {
if stealRunNextG {
// Try to steal from _p_.runnext.
if next := _p_.runnext; next != 0 {
if _p_.status == _Prunning {
if GOOS != "windows" {
usleep(3)
} else {
osyield()
}
}
if !_p_.runnext.cas(next, 0) {
continue
}
batch[batchHead%uint32(len(batch))] = next
return 1
}
}
return 0
}
if n > uint32(len(_p_.runq)/2) { // read inconsistent h and t
continue
}
for i := uint32(0); i < n; i++ {
g := _p_.runq[(h+i)%uint32(len(_p_.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
if atomic.CasRel(&_p_.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}
}
触发调度
- 线程启动
- 协程执行结束
- 主动挂起
- 系统调用
- 协作式调度
- 系统监控
线程启动
runtime/proc.go/mstart - > runtime/proc.go/mstart1
// 线程启动时会触发此函数
// runtime/proc.go/mstart
func mstart() {
_g_ := getg()
osStack := _g_.stack.lo == 0
if osStack {
size := _g_.stack.hi
if size == 0 {
size = 8192 * sys.StackGuardMultiplier
}
_g_.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
_g_.stack.lo = _g_.stack.hi - size + 1024
}
_g_.stackguard0 = _g_.stack.lo + _StackGuard
_g_.stackguard1 = _g_.stackguard0
mstart1()
if mStackIsSystemAllocated() {
osStack = true
}
mexit(osStack)
}
// runtime/proc.go/mstart1
func mstart1() {
_g_ := getg()
if _g_ != _g_.m.g0 {
throw("bad runtime·mstart")
}
save(getcallerpc(), getcallersp())
asminit()
minit()
if _g_.m == &m0 {
mstartm0()
}
if fn := _g_.m.mstartfn; fn != nil {
fn()
}
if _g_.m != &m0 {
acquirep(_g_.m.nextp.ptr())
_g_.m.nextp = 0
}
schedule() // 触发调度循环
}
协程执行结束
runtime/proc.go/goexit0
// runtime/proc.go/goexit0
func goexit0(gp *g) {
_g_ := getg()
// 1.修改G 为_Gdead状态
casgstatus(gp, _Grunning, _Gdead)
if isSystemGoroutine(gp, false) {
atomic.Xadd(&sched.ngsys, -1)
}
// 2.清理G内容
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
_g_.m.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = 0
gp.param = nil
gp.labels = nil
gp.timer = nil
if gcBlackenEnabled != 0 && gp.gcAssistBytes > 0 {
assistWorkPerByte := float64frombits(atomic.Load64(&gcController.assistWorkPerByte))
scanCredit := int64(assistWorkPerByte * float64(gp.gcAssistBytes))
atomic.Xaddint64(&gcController.bgScanCredit, scanCredit)
gp.gcAssistBytes = 0
}
// 3.M和G解除
dropg()
if GOARCH == "wasm" { // no threads yet on wasm
gfput(_g_.m.p.ptr(), gp)
schedule() // never returns
}
if _g_.m.lockedInt != 0 {
print("invalid m->lockedInt = ", _g_.m.lockedInt, "\n")
throw("internal lockOSThread error")
}
// 4.将G放入P的缓存队列
gfput(_g_.m.p.ptr(), gp)
if locked {
if GOOS != "plan9" { // See golang.org/issue/22227.
gogo(&_g_.m.g0.sched)
} else {
_g_.m.lockedExt = 0
}
}
schedule() // 触发调度循环
}
主动挂起
runtime/proc.go/gopark - > runtime/proc.go/park_m
// runtime/proc.go/gopark
// 当前G暂停
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) {
//其他代码
...
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
//其他代码
...
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waittraceev = traceEv
mp.waittraceskip = traceskip
releasem(mp)
mcall(park_m)
}
// runtime/proc.go/park_m
// 1.当前G切换为Gwiting
// 2.移除G和M的关系
// 3.触发调度
func park_m(gp *g) {
_g_ := getg()
//其他代码
...
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
//其他代码
...
schedule() // 触发调度循环
}
// runtime/proc.go/goready
// g唤醒
func goready(gp *g, traceskip int) {
systemstack(func() {
ready(gp, traceskip, true)
})
}
// runtime/proc.go/ready
// 1.当前G切换为_Grunnable
// 2.放入当前运行队列中
// 3.唤醒
func ready(gp *g, traceskip int, next bool) {
//其他代码
...
status := readgstatus(gp)
_g_ := getg()
//其他代码
...
// 1.当前G切换为_Grunnable
casgstatus(gp, _Gwaiting, _Grunnable)
// 2.放入当前运行队列中
runqput(_g_.m.p.ptr(), gp, next)
// 3.唤醒
wakep()
//其他代码
...
}
系统调用
runtime/proc.go/exitsyscall -> runtime/proc.go/exitsyscall0
// runtime/proc.go/exitsyscall
//系统调用结束后会调用此函数
// 1.为当前G重新分配资源
// 2.切换调度器G0 触发 调度
func exitsyscall() {
_g_ := getg()
//其他代码
...
// 1.为当前G重新分配资源
oldp := _g_.m.oldp.ptr()
_g_.m.oldp = 0
// 1.2 如果原有P处于_Psyscall,通过wirep将G于原有处理取重新关联
// 1.3 如果没有,调度存在限制处理器会acquirp获取闲置处理器于当前G关联
if exitsyscallfast(oldp) {
//其他代码
...
_g_.m.p.ptr().syscalltick++
// We need to cas the status and scan before resuming...
casgstatus(_g_, _Gsyscall, _Grunning)
//其他代码
...
return
}
//其他代码
...
//2.如果没有合适的P 切换G0调度
mcall(exitsyscall0)
//其他代码
...
_g_.m.p.ptr().syscalltick++
_g_.throwsplit = false
}
// 如果没有合适的P 切换G0调度
// runtime/proc.go/exitsyscall0
func exitsyscall0(gp *g) {
_g_ := getg()
// 1. 切换G 为_Grunnable 状态
casgstatus(gp, _Gsyscall, _Grunnable)
// 2. 移除M和G的关联
dropg()
lock(&sched.lock)
var _p_ *p
// 3. 获取闲置处理器P
if schedEnabled(_g_) {
_p_ = pidleget()
}
// 3. 没有限制处理器则放入全局队列
if _p_ == nil {
globrunqput(gp)
} else if atomic.Load(&sched.sysmonwait) != 0 {
atomic.Store(&sched.sysmonwait, 0)
notewakeup(&sched.sysmonnote)
}
unlock(&sched.lock)
// 4. 获取成功 直接执行
if _p_ != nil {
acquirep(_p_)
execute(gp, false) // Never returns.
}
if _g_.m.lockedg != 0 {
stoplockedm()
execute(gp, false) // Never returns.
}
stopm()
schedule() // 触发调度循环
}
// runtime/proc.go/exitsyscall
// 系统调用前会运行此函数
func entersyscall() {
reentersyscall(getcallerpc(), getcallersp())
}
// runtime/proc.go/reentersyscall
// 完成系统调用准备工作
func reentersyscall(pc, sp uintptr) {
_g_ := getg()
_g_.m.locks++
_g_.stackguard0 = stackPreempt // 禁止其他M抢占
_g_.throwsplit = true // 禁止当前函数栈分裂 增长
save(pc, sp) // 保存当前程序计数器PC和栈指针SP内容
_g_.syscallsp = sp
_g_.syscallpc = pc
casgstatus(_g_, _Grunning, _Gsyscall) // 将G状态改为 _Gsyscall
//其他代码
...
_g_.m.syscalltick = _g_.m.p.ptr().syscalltick
_g_.sysblocktraced = true
pp := _g_.m.p.ptr()
pp.m = 0 // PM暂时分离
_g_.m.oldp.set(pp) // M记录旧P
_g_.m.p = 0 // M解除P
atomic.Store(&pp.status, _Psyscall) // P状态改为_Psyscall
if sched.gcwaiting != 0 {
systemstack(entersyscall_gcwait)
save(pc, sp)
}
_g_.m.locks--
}
协作式调度
runtime/proc.go/Gosched - >runtime/proc.go/gosched_m->runtime/proc.go/goschedImpl
// runtime/proc.go/Gosched
func Gosched() {
//其他代码
...
// g0
mcall(gosched_m)
}
// runtime/proc.go/gosched_m
// g0运行
func gosched_m(gp *g) {
//其他代码
...
goschedImpl(gp)
}
// runtime/proc.go/goschedImpl
// 1. 将G状态改为 _Grunnable
// 2. 移除M和G的关联
// 3. 将G放置全局队列
func goschedImpl(gp *g) {
//其他代码
...
// 1. 将G状态改为 _Grunnable
casgstatus(gp, _Grunning, _Grunnable)
// 2. 移除M和G的关联
dropg()
lock(&sched.lock)
// 3. 将G放置全局队列
globrunqput(gp)
unlock(&sched.lock)
schedule() // 触发调度循环
}
系统监控
- 独立M上运行
- 抢占P/G
- 触发GC
- 清理堆span
// runtime/proc.go/sysmon
// 系统监控在一个独立的 m 上运行
// 总是在没有 P 的情况下运行,因此不能出现写屏障
//go:nowritebarrierrec
func sysmon() {
lock(&sched.lock)
sched.nmsys++ // 不计入死锁的系统 m 的数量
checkdead() // 死锁检查
unlock(&sched.lock)
atomic.Store(&sched.sysmonStarting, 0)
lasttrace := int64(0)
idle := 0 // how many cycles in succession we had not wokeup somebody
delay := uint32(0)
for {
if idle == 0 { // 每次启动先休眠 20us
delay = 20
} else if idle > 50 { // 1ms 后就翻倍休眠时间
delay *= 2
}
if delay > 10*1000 { // 增加到 10ms
delay = 10 * 1000
}
usleep(delay) // 休眠
mDoFixup()
// 如果在 STW,则暂时休眠
now := nanotime()
if debug.schedtrace <= 0 && (sched.gcwaiting != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs)) {
lock(&sched.lock)
if atomic.Load(&sched.gcwaiting) != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs) {
syscallWake := false
next, _ := timeSleepUntil()
if next > now {
atomic.Store(&sched.sysmonwait, 1)
unlock(&sched.lock)
// 确保 wake-up 周期足够小从而进行正确的采样
sleep := forcegcperiod / 2
if next-now < sleep {
sleep = next - now
}
shouldRelax := sleep >= osRelaxMinNS
if shouldRelax {
osRelax(true)
}
syscallWake = notetsleep(&sched.sysmonnote, sleep)
mDoFixup()
if shouldRelax {
osRelax(false)
}
lock(&sched.lock)
atomic.Store(&sched.sysmonwait, 0)
noteclear(&sched.sysmonnote)
}
if syscallWake {
idle = 0
delay = 20
}
}
unlock(&sched.lock)
}
lock(&sched.sysmonlock)
now = nanotime()
// 需要时触发 libc interceptor
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
// 如果超过 10ms 没有 poll,则 poll 一下网络
lastpoll := int64(atomic.Load64(&sched.lastpoll))
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
list := netpoll(0) // 非阻塞,返回 Goroutine 列表
if !list.empty() {
// 需要在插入 g 列表前减少空闲锁住的 m 的数量(假装有一个正在运行)
// 否则会导致这些情况:
// injectglist 会绑定所有的 p,但是在它开始 M 运行 P 之前,另一个 M 从 syscall 返回,
// 完成运行它的 G ,注意这时候没有 work 要做,且没有其他正在运行 M 的死锁报告。
incidlelocked(-1)
injectglist(&list)
incidlelocked(1)
}
}
mDoFixup()
if GOOS == "netbsd" {
if next, _ := timeSleepUntil(); next < now {
startm(nil, false)
}
}
if atomic.Load(&scavenge.sysmonWake) != 0 {
wakeScavenger()
}
// 抢夺在 syscall 中阻塞的 P、运行时间过长的 G
if retake(now) != 0 {
idle = 0
} else {
idle++
}
// 检查是否需要强制触发 GC
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 {
lock(&forcegc.lock)
forcegc.idle = 0
var list gList
list.push(forcegc.g)
injectglist(&list)
unlock(&forcegc.lock)
}
if debug.schedtrace > 0 && lasttrace+int64(debug.schedtrace)*1000000 <= now {
lasttrace = now
schedtrace(debug.scheddetail > 0)
}
unlock(&sched.sysmonlock)
}
}
// runtime/proc.go/retake
// 抢占P
func retake(now int64) uint32 {
n := 0
// 防止 allp 数组发生变化,除非我们已经 STW,此锁将完全没有人竞争
lock(&allpLock)
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
if _p_ == nil {
continue
}
pd := &_p_.sysmontick
s := _p_.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// 如果 G 运行时时间太长则进行抢占
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
// 对于 syscall 的情况,因为 M 没有与 P 绑定,
// preemptone() 不工作
preemptone(_p_)
sysretake = true
}
}
// 对阻塞在系统调用上的 P 进行抢占
if s == _Psyscall {
// 如果已经超过了一个系统监控的 tick(20us),则从系统调用中抢占 P
t := int64(_p_.syscalltick)
if !sysretake && int64(pd.syscalltick) != t {
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
// 一方面,在没有其他 work 的情况下,我们不希望抢夺 P
// 另一方面,因为它可能阻止 sysmon 线程从深度睡眠中唤醒,所以最终我们仍希望抢夺 P
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
// 解除 allpLock,从而可以获取 sched.lock
unlock(&allpLock)
// 在 CAS 之前需要减少空闲 M 的数量(假装某个还在运行)
// 否则发生抢夺的 M 可能退出 syscall 然后再增加 nmidle ,进而发生死锁
// 这个过程发生在 stoplockedm 中
incidlelocked(-1)
if atomic.Cas(&_p_.status, s, _Pidle) { // 将 P 设为 idle,从而交于其他 M 使用
if trace.enabled {
traceGoSysBlock(_p_)
traceProcStop(_p_)
}
n++
_p_.syscalltick++
handoffp(_p_)
}
incidlelocked(1)
lock(&allpLock)
}
}
unlock(&allpLock)
return uint32(n)
}
// runtime/proc.go/preemptone
func preemptone(_p_ *p) bool {
// 检查 M 与 P 是否绑定
mp := _p_.m.ptr()
if mp == nil || mp == getg().m {
return false
}
gp := mp.curg
if gp == nil || gp == mp.g0 {
return false
}
// 将 G 标记为抢占
gp.preempt = true
// 一个 Goroutine 中的每个调用都会通过比较当前栈指针和 gp.stackgard0
// 来检查栈是否溢出。
// 设置 gp.stackgard0 为 StackPreempt 来将抢占转换为正常的栈溢出检查。
gp.stackguard0 = stackPreempt
// 请求该 P 的异步抢占
if preemptMSupported && debug.asyncpreemptoff == 0 {
_p_.preempt = true
preemptM(mp)
}
return true
}
// todo 抢占
协程 goroutine对比
-
内存上:
- 内核线程通常2MB栈内存
- 协程通常2KB内存(根据需要自动调整)。
-
调度上:
- 协程使用M:N线程模型,m个协程分配到n个内核线程上,用户态runtime均匀调度,调度切换成本低,重分利用硬件资源。
- 用户线程:内核线程KSE=1:1,由os内核调度,调度切换成本高。
状态转移
// runtime2.go/runtime.g
// defined constants
const (
// G status G状态
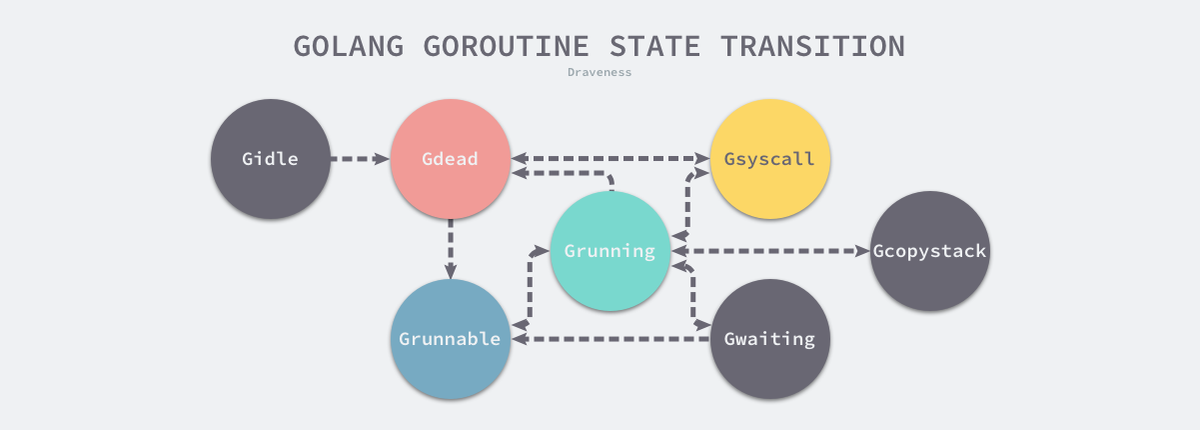
// 刚刚被分配并且还没有被初始化
_Gidle = iota // 0
// 没有执行代码,没有栈的所有权,存储在运行队列中
_Grunnable // 1
// 可以用户执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 P
_Grunning // 2
// 正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上
_Gsyscall // 3
// 由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上
_Gwaiting // 4
// _Gmoribund_unused is currently unused, but hardcoded in gdb
// scripts.
_Gmoribund_unused // 5
// 没有被使用,没有执行代码,可能有分配的栈。可能刚被初始化或者刚退出
_Gdead // 6
// _Genqueue_unused is currently unused.
_Genqueue_unused // 7
// 栈正在被拷贝,没有执行代码,不在运行队列上
_Gcopystack // 8
// 由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒
_Gpreempted // 9
// GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在
_Gscan = 0x1000
_Gscanrunnable = _Gscan + _Grunnable // 0x1001
_Gscanrunning = _Gscan + _Grunning // 0x1002
_Gscansyscall = _Gscan + _Gsyscall // 0x1003
_Gscanwaiting = _Gscan + _Gwaiting // 0x1004
_Gscanpreempted = _Gscan + _Gpreempted // 0x1009
)
源码分析
// runtime2.go/runtime.g
// G goroutine结构体
// 存储goroutine运行数据
type g struct {
//栈相关
stack stack //当前goroutine内存范围[stack.lo,stack.hi)
stackguard0 uintptr //用于抢占式调度
//抢占调度
preempt bool // 抢占信号
preemptStop bool // 抢占时将状态修改成 `_Gpreempted`
preemptShrink bool // 在同步安全点收缩栈
//defer/panic栈
_panic *_panic // 最内侧的panic结构体链表
_defer *_defer // 最内侧的延迟函数结构体链表
//调度相关
m *m //当前goroutine占用的线程 可能为空
sched gobuf //goroutine调度相关数据,保存g的上下文
atomicstatus uint32 //goroutine的状态
goid int64 //goroutine的id
gopc uintptr //goroutine的入口函数
startpc uintptr //goroutine函数的地址
//其他字段
...
}
// runtime2.go/runtime.g.gobuf
// goroutine调度相关数据
// 调度切换上下文,栈指针和程序计数器用来保持或者恢复寄存器的值
type gobuf struct {
sp uintptr // 栈指针
pc uintptr // 运行到的程序位置
g guintptr // 持有runtine.gobuf的goroutine
ret sys.Uintreg //系统调用返回值
//其他字段
...
}
// runtime2.go/runtime.g.stack
// goroutine栈
type stack struct{
lo uintptr // 栈的下界内存地址
hi uintptr // 栈的上界内存地址
}
//-------------------------- 创建G ---------------------------
// go 关键字 映射runtime.newproc()
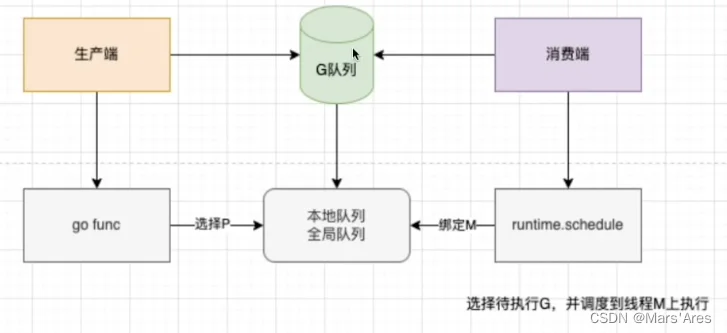
// 1.创建G
// 2.放置本地队列
// runtime/proc.go/newproc
func newproc(siz int32, fn *funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg()
pc := getcallerpc()
systemstack(func() {
// 1.创建G
newg := newproc1(fn, argp, siz, gp, pc)
_p_ := getg().m.p.ptr()
// 2.放置本地队列
runqput(_p_, newg, true)
if mainStarted {
wakep()
}
})
}
// ------------------------- 放置G ---------------------------
// 1. next为true 设置G为P的runnext
// 2. next为false 设置G为本地队列
// 2.1 如果P的本地队列没有空间则放全局队列
// runtime/proc.go/runqput
func runqput(_p_ *p, gp *g, next bool) {
if randomizeScheduler && next && fastrand()%2 == 0 {
next = false
}
// 1. next为true 设置G为P的runnext
if next {
retryNext:
oldnext := _p_.runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
gp = oldnext.ptr()
}
// 2. next为false 设置G为本地队列
retry:
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
t := _p_.runqtail
if t-h < uint32(len(_p_.runq)) {
_p_.runq[t%uint32(len(_p_.runq))].set(gp)
atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumption
return
}
// 2.1 如果P的本地队列没有空间则放全局队列
if runqputslow(_p_, gp, h, t) {
return
}
goto retry
}
// ------------------------- 全局队列放置G ---------------------------
// 1.计算放置全局队列的个数
// 2.取本地队列一半+1的G到全局队列
// runtime/proc.go/runqputslow
func runqputslow(_p_ *p, gp *g, h, t uint32) bool {
var batch [len(_p_.runq)/2 + 1]*g
// 1.计算放置全局队列的个数
// n = n /2 + 1
n := t - h
n = n / 2
if n != uint32(len(_p_.runq)/2) {
throw("runqputslow: queue is not full")
}
for i := uint32(0); i < n; i++ {
batch[i] = _p_.runq[(h+i)%uint32(len(_p_.runq))].ptr()
}
if !atomic.CasRel(&_p_.runqhead, h, h+n) { // cas-release, commits consume
return false
}
batch[n] = gp
if randomizeScheduler {
for i := uint32(1); i <= n; i++ {
j := fastrandn(i + 1)
batch[i], batch[j] = batch[j], batch[i]
}
}
// 2.取本地队列一半+1的G到全局队列
for i := uint32(0); i < n; i++ {
batch[i].schedlink.set(batch[i+1])
}
var q gQueue
q.head.set(batch[0])
q.tail.set(batch[n])
// Now put the batch on global queue.
lock(&sched.lock)
globrunqputbatch(&q, int32(n+1))
unlock(&sched.lock)
return true
}
//-------------------------- 创建G ---------------------------
// 1.获取G的结构体
// a.获取空闲G
// b.创建新的G
// 2.拷贝fn argp参数到G的栈中
// 3.重置G的结构体参数。例如 指针/程序计数器/状态
// runtime/proc.go/newproc
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g {
_g_ := getg()
//其他代码
...
siz := narg
siz = (siz + 7) &^ 7
//其他代码
...
// 1. 创建G
_p_ := _g_.m.p.ptr()
// 1.1 获取空闲G
newg := gfget(_p_)
if newg == nil {
// 1.2 创建新的G
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
//其他代码
...
// 2.拷贝fn argp参数到G的栈中
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame
totalSize += -totalSize & (sys.SpAlign - 1) // align to spAlign
sp := newg.stack.hi - totalSize
spArg := sp
//其他代码
...
if narg > 0 {
memmove(unsafe.Pointer(spArg), argp, uintptr(narg))
//其他代码
...
}
// 3.重置G的结构体参数。例如 指针/程序计数器/状态
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
if _g_.m.curg != nil {
newg.labels = _g_.m.curg.labels
}
if isSystemGoroutine(newg, false) {
atomic.Xadd(&sched.ngsys, +1)
}
casgstatus(newg, _Gdead, _Grunnable)
if _p_.goidcache == _p_.goidcacheend {
_p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
_p_.goidcache -= _GoidCacheBatch - 1
_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
}
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
//其他代码
...
return newg
}
//-------------------------- 获取空闲G ---------------------------
// 从p中获取空闲G复用
// 1. 处理器P不存在空闲G且调取器存在空闲 调度器中获取空闲G到P
// 2. 获取P中空闲G
// runtime/proc.go/gfget
func gfget(_p_ *p) *g {
retry:
// 1. 调度器中获取空闲G到P
if _p_.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) {
lock(&sched.gFree.lock)
for _p_.gFree.n < 32 {
gp := sched.gFree.stack.pop()
if gp == nil {
gp = sched.gFree.noStack.pop()
if gp == nil {
break
}
}
sched.gFree.n--
_p_.gFree.push(gp)
_p_.gFree.n++
}
unlock(&sched.gFree.lock)
goto retry
}
// 2. 获取P中空闲G
gp := _p_.gFree.pop()
if gp == nil {
return nil
}
_p_.gFree.n--
if gp.stack.lo == 0 {
systemstack(func() {
gp.stack = stackalloc(_FixedStack)
})
gp.stackguard0 = gp.stack.lo + _StackGuard
} else {
if raceenabled {
racemalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)
}
if msanenabled {
msanmalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)
}
}
return gp
}
//-------------------------- 创建G ---------------------------
// 初始化G
// 1. 创建G结构体
// 2. 申请栈内存
// runtime/proc.go/malg
func malg(stacksize int32) *g {
//1. 创建G结构体
newg := new(g)
if stacksize >= 0 {
stacksize = round2(_StackSystem + stacksize)
systemstack(func() {
//2. 申请栈内存
newg.stack = stackalloc(uint32(stacksize))
})
newg.stackguard0 = newg.stack.lo + _StackGuard
newg.stackguard1 = ^uintptr(0)
*(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0
}
return newg
}
使用
//关键字go + 方法调用开启协程
go func([params ...])([values...])
//例子
//随机打印0~9
for i:=0;i<10;i++{
go func(int a){
fmt.Println(a)
}(i)
}
// 随机显示 0~9
-
先入先出队列FIFO,线程安全,锁保护。
-
channel零值为nil,使用前必须make创建。
-
双向通道可以转换为单向通道,反之不行。
| 动作\状态 | close | nil | 无缓冲未读 | 无缓冲未写 | 缓冲满了 | 缓冲未满 |
|---|---|---|---|---|---|---|
| 接收 | - | 阻塞 | 正常 | 阻塞 | 正常 | 正常 |
| 发送 | panic | 阻塞 | 阻塞 | 正常 | 阻塞 | 正常 |
| close | panic | panic | 正常读 | 零值 | 正常读 | 正常读 |
源码分析
// runtime.go/runtime.hchan
//维护协程之间通信同步队列,使用互斥锁保证同步
type hchan struct {
// chan相关
closed uint32 // channel是否关闭
elemtype *_type // channel能够收发的原属类型
// 环形buf
qcount uint //channel中元素个数
dataqsiz uint //channel中循环队列长度
buf unsafe.Pointer //channel中缓冲区数据数据指针
elemsize uint16 //channel能够收发的元素大小
sendx uint //channel中发送操作处理到的位置
recvx uint //channel中接收操作处理到的位置
lock mutex //channel锁
// G相关
recvq waitq //channel缓冲不足阻塞的接收队列(双向链表)
sendq waitq //channel缓冲不足阻塞的发送队列(双向链表)
}
// runtime.go/runtime.hchan.waitq
// 存储等待列表中的goroutine
type waitq struct {
first *sudog // 头
last *sudog // 尾
}
// runtime.go/runtime.hchan.waitq.sudog
// 双向链表
type sudog struct{
g *g // 当前G
next *sudog // 下一个G
prev *sudog // 上一个G
elem unsafe.Pointer // 指向信号
c *hchan // 当前通道
// 其他代码
...
}
// ----------------创建通道 -----------------
使用
//声明
var ch chan int
//初始化 make(chan type,[buffer])
//buffer不存在 为无缓冲 发送和接收为同步
//buffer存在 为有缓冲 发送和接收为异步
ch :=make(chan struct{})
ch1 :=make(chan struct{},1)
var ch2 chan<-struct{}=ch //只写
var ch3 <-chan struct{}=ch //只读
//写通道数据
ch2<-struct{}{}
//读通道数据
<-ch3
//遍历通道数据
for i,ok:=range ch {
//i 为接收数据
//ok 是否还有数据
}
//关闭通道,关闭后无法写入否则panic
close(ch)
互斥锁 mutex
锁模式
- 正常模式。非公平锁,锁的初始模式
- goroutine在CAS4次后未获得锁进入锁的等待队列(FIFO)
- 被唤醒goroutine和新goroutine进行CAS争抢锁,大概率失败
- 等待队列中goroutine超过1ms没有获取锁则切换饥饿模式
- 饥饿模式。公平锁
- 释放锁的goroutine直接交给等待队列中队首goroutine
- 新goroutine直接加入等待队列队位
- 队尾goroutine获取锁或者等待时间小于1ms获取所择切换正常模式
锁状态
const (
mutexLocked = 1 << iota // 锁定
mutexWoken // 唤醒
mutexStarving // 饥饿
mutexWaiterShift = iota // 锁等待位
starvationThresholdNs = 1e6 // 1ms
)
// 互斥锁
// sync/mutex.go
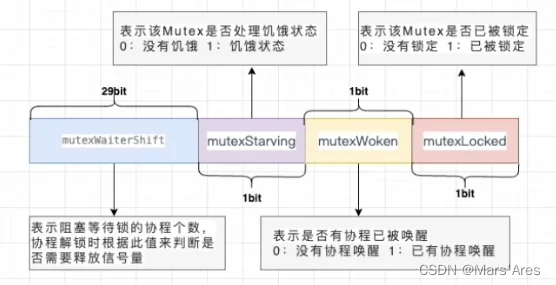
type Mutex struct {
// 29bit mutexWaiterShift 等待锁的协程数,判断是否需要释放信号量
// 1bit mutexStarving 1 表示饥饿
// 1bit mutexWoken 1 表示有协程被唤醒
// 1bit mutexLocked 1 表示锁定
state int32 // 锁状态
// 该地址是唯一的 取hash值可以在semtable中获取的semroot
// semroot中 sulog保存了g的队列
sema uint32 // 信号量
}
上锁
// sync/mutex.go
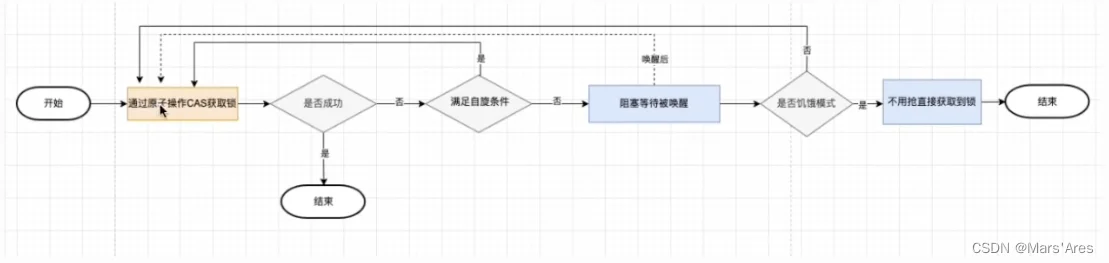
func (m *Mutex) Lock() {
// 1.获取锁
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
// 其他代码
....
return
}
// 2.锁失败
m.lockSlow()
}
// 2.锁失败后处理
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false
awoke := false
iter := 0
old := m.state
for {
// 1.符合自旋条件 且 正常模式 进行CAS自旋争抢
// 饥饿模式跳过自旋争抢
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
// 1.2.主动自旋尝试唤醒
if !awoke && old&mutexWoken == 0
&& old>>mutexWaiterShift != 0
&& atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
// 1.2.1 设置唤醒标志位
awoke = true
}
// 1.3.调用系统自旋逻辑
// 资源被锁
// cpu核数>1
// 该g自旋次数<4
// 空闲p
// 当前p本地g队列空,只有当前g
runtime_doSpin() // 30次PASE
iter++
old = m.state
continue
}
// 2.计算互斥锁状态
new := old
// 2.1 如果是正常模式,尝试标记获取锁
if old&mutexStarving == 0 {
new |= mutexLocked
}
// 2.2 如果已锁或者饥饿模式,等待位+1
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
// 2.3 如果等待超过1ms 尝试转为饥饿模式
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
// 2.4 如果之前唤醒锁 尝试重置标志位
if awoke {
// 其他代码
....
new &^= mutexWoken
}
// 3.尝试获取锁
// 获取锁成功
if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&(mutexLocked|mutexStarving) == 0 {
// 3.1 CAS获取锁成功 放行
break
}
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
// 3.2 系统通过信号量等待释放
// 等待锁的持有者唤醒
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// 3.2.1 计算等待时间释放进入饥饿模式
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
// 3.2.2 饥饿模式处理
if old&mutexStarving != 0 {
...
// 3.2.2.1 修改锁标志位
delta := int32(mutexLocked - 1<<mutexWaiterShift)
// 3.2.2.2 是否退出饥饿模式
// g的执行等待时间<1ms
// 等待队列只有当前g
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
// 获取锁失败 继续cas循环
old = m.state
}
}
// 其他代码
....
}
解锁
// sync/mutex.go
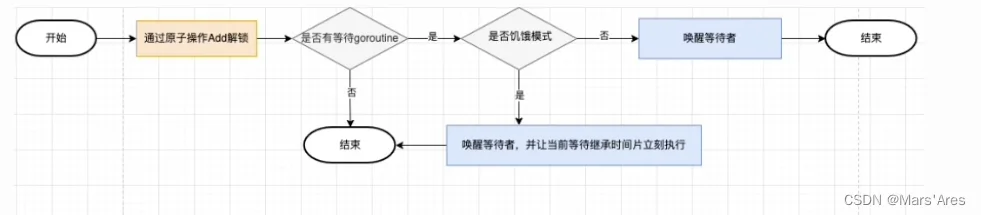
func (m *Mutex) Unlock() {
// 其他代码
...
// 1.轻松解锁
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
// 2.其他解锁逻辑
m.unlockSlow(new)
}
}
func (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
// 1. 正常模式
if new&mutexStarving == 0 {
old := new
for {
// 1.1 没有其他锁状态直接返回
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// 1.2 有等待者 移交锁的所有权和唤醒
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else {
// 2. 饥饿模式
// 尝试唤醒下一个
runtime_Semrelease(&m.sema, true, 1)
}
}
读写锁 RWMutex
待续
参考