
小结:
1、内存消耗分析 list peek 定位到函数
https://mp.weixin.qq.com/s/_LovnIqJYAuDpTm2QmUgrA
使用pprof和go-torch排查golang的性能问题
原创 felix021 felix021 2019-09-22
最近线上服务压力很大,api的p99有点扛不住。
广告业务对延时的要求普遍比较严格,有些adx设置的超时时间低至100ms,因此亟需找出性能热点。
根据对目前系统情况的估计(和metrics埋点数据),大致估计问题出在广告的正排环节。
使用 pprof 也证明了这一块确实是热点:
其中第三行 NewFilter 就是正排过滤函数。因为一些历史原因,系统里不是所有定向条件都使用了倒排,正排实现起来毕竟简单、容易理解,而一旦开了这个口子,就会有越来越多正排加进来,推测是这个原因导致了性能的逐渐衰退。
经过讨论,D同学花了一周多的时间,逐个梳理重写。在Libra(字节跳动内部的ABTest平台,参考谷歌分层实验框架方案)上开实验,平均耗时 -9%,从统计数据上来说,实验组比对照组有了显著的改进,但从最终结果上,整体的p95、p99超时都出现了进一步恶化。
这说明真正的问题不在于正排的计算,优化的思路出现了偏差。
考虑到晚高峰期间的cpu占用率也只是刚超过50%,也就是说有可能性能问题在于锁,但pprof的 block 和 mutex 都是空的,没有线索。
猜测问题有可能在日志,代码里确实用得不少。日志用的是 github.com/ngaut/logging 库,每一次调用都会用到两个全局mutex。但通过调整log level 为error级别,大幅减少了日志量,并没有看到性能的改善。
经过搜索,发现 uber 基于 pprof 开发了一个神器 go-torch,可以生成火焰图。安装好 go-torch 及依赖 FlameGraph 以后执行:
用 Chrome 打开 cpu.svg,人肉排查:
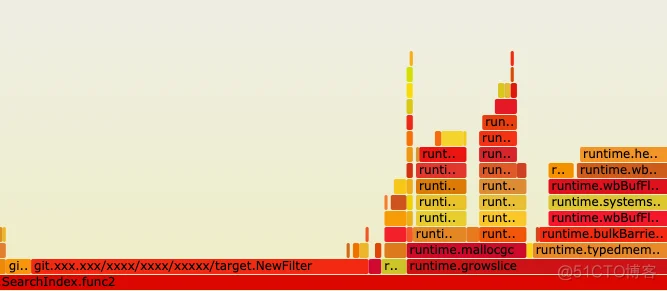
可以看到,在NewFilter旁边竟然还有一个耗时接近的 runtime.growslice ,结合实际代码(略作简化),可以推测是 slice 的初始化长度不足。
实际上最终定向后得到的广告往往在数万甚至数十万的级别,而 go 的 slice 扩容在超过1024个元素以后是1.25倍,可想而知会出现大量的内存分配和拷贝,导致性能随着广告数量的增加逐渐恶化。最近的广告数量也确实有了大幅的上升 —— 逻辑上形成了闭环。
经过优化,使用更大的初始化长度,并且使用 sync.Pool 来进一步减少内存分配,最终上线后p95和p99都下降了超过50%,效果显著。
参考文章:
golang 使用pprof和go-torch做性能分析
Go语言性能优化工具pprof文本输出的含义_梁喜健_新浪博客 http://blog.sina.com.cn/s/blog_48c95a190102xtse.html
Go语言性能优化工具pprof文本输出的含义
(2018-10-13 12:02:19)
对于广大gopher来说,pprof是做性能优化时经常会用到的一个工具,但很多刚刚入坑的开发者难免会对pprof文本输出中的某些字段感到困惑,这里不妨做一个简单的说明。以下是一段典型的pprof函数耗时的文本输出,其中前几行比较容易理解,其说明了显示出来的函数耗时总计占用了5.73s,而全部耗时为6.21秒,所以显示出来的函数耗时占总体的92.27%,其中有cum耗时小于0.03秒的67个函数耗时被丢弃而未予显示。
(pprof) top78
Showing nodes accounting for 5.73s, 92.27% of 6.21s total
Dropped 67 nodes (cum <= 0.03s)
Showing top 78 nodes out of 79
flat flat% sum% cum cum%
4.14s 66.67% 66.67% 4.14s 66.67% runtime.kevent /usr/local/go/src/runtime/sys_darwin_amd64.s
0.52s 8.37% 75.04% 0.52s 8.37% runtime.mach_semaphore_signal /usr/local/go/src/runtime/sys_darwin_amd64.s
0.34s 5.48% 80.52% 0.34s 5.48% runtime.mach_semaphore_timedwait /usr/local/go/src/runtime/sys_darwin_amd64.s
0.17s 2.74% 83.25% 0.17s 2.74% runtime.mach_semaphore_wait /usr/local/go/src/runtime/sys_darwin_amd64.s
0.13s 2.09% 85.35% 0.13s 2.09% runtime.scanstack /usr/local/go/src/runtime/mgcmark.go
0.07s 1.13% 86.47% 0.07s 1.13% runtime.memmove /usr/local/go/src/runtime/memmove_amd64.s
0.06s 0.97% 87.44% 0.06s 0.97% runtime.usleep /usr/local/go/src/runtime/sys_darwin_amd64.s
接下来的一大坨文本涉及到了这样几列字段:flat和flat%、sum%、cum和cum%,其中flat代表的是该函数自身代码的执行时长,而cum代表的是该函数自身代码+所有调用的函数的执行时长。这样解释可能不太直观,我们以下面的例子来说明,函数b由三部分组成:调用函数c、自己直接处理一些事情、调用函数d,其中调用函数c耗时1秒,自己直接处理事情耗时3秒,调用函数d耗时2秒,那么函数b的flat耗时就是3秒,cum耗时就是6秒。
func b() {
c() // takes 1s
do something directly // takes 3s
d() // takes 2s
}
至于flat%和cum%指的就是flat耗时和cum耗时占总耗时(也就是6.21秒)的百分比,而最后一个sum%指的就是每一行的flat%与上面所有行的flat%总和,代表从上到下的累计值,比如第二行的75.04%就等于第一行flat%的66.67%+本行flat%的8.37%,下面的以此类推。
https://mp.weixin.qq.com/s/4Vn1Rq82wOFiLdEmjXU0fw
go pprof与线上事故:一次成功的定位与失败的复现
原创 唐银鹏 从菜鸟到大佬 2020-05-01
FlatFlat%Sum%flat%flat%CumCum%bcdcdbflatcum
go tool pprof http://127.0.0.1:123/debug/pprof/heap
使用list命令直接可以查看到具体是哪一行分配了多少内存
list Output annotated source for functions matching regexp
pdf Outputs a graph in PDF format
peek Output callers/callees of functions matching regexp