
1. 准备工作
1. 安装graphviz
brew install graphviz
Note: 环境是Darwin,如果是别的操作的系统用户请自行Google查阅如何安装graphviz
2. 将$GOPATH/bin加入到$PATH
在. zshrc中export$GOPATH/bin,在Golang基础环境设置中有提及,不明白的可以参考我的配置。
3. 安装go-torch
go get github.com/uber-archive/go-torch
4. flamegraph(火焰图)
git clone git@github.com:brendangregg/FlameGraph.git
cd FlameGraph && mv flamegraph.pl $GOPATH/bin
2. 通过文件输出Profile
1. 灵活性高,可以对特定的代码片段进行调试
2. 通过手动调用runtime/pprof的API
3. 可以查看https://golang.org/pkg/runtime/pprof 文档去了解API
$GOPATH/bin路径下可以看到bin文件 pprof
4. 使用pprof做代码分析
1. 示例代码
vim $GOPATH/src/prof/prof.go
package main
import (
"log"
"math/rand"
"os"
"runtime/pprof"
"time"
)
const (
col = 10000
row = 10000
)
func fillMatrix(m *[row][col]int) {
s := rand.New(rand.NewSource(time.Now().UnixNano()))
for i := 0; i < row; i++ {
for j := 0; j < col; j++ {
m[i][j] = s.Intn(100000)
}
}
}
func calculate(m *[row][col]int) {
for i := 0; i < row; i++ {
tmp := 0
for j := 0; j < col; j++ {
tmp += m[i][j]
}
}
}
func main() {
//创建输出文件
f, err := os.Create("cpu.prof")
if err != nil {
log.Fatal("could not create CPU profile: ", err)
}
// 获取系统信息
if err := pprof.StartCPUProfile(f); err != nil { //监控cpu
log.Fatal("could not start CPU profile: ", err)
}
defer pprof.StopCPUProfile()
// 主逻辑区,进行一些简单的代码运算
x := [row][col]int{}
fillMatrix(&x)
calculate(&x)
f1, err := os.Create("mem.prof")
if err != nil {
log.Fatal("could not create memory profile: ", err)
}
// runtime.GC() // GC,获取最新的数据信息
if err := pprof.WriteHeapProfile(f1); err != nil { // 写入内存信息
log.Fatal("could not write memory profile: ", err)
}
f1.Close()
f2, err := os.Create("goroutine.prof")
if err != nil {
log.Fatal("could not create groutine profile: ", err)
}
if gProf := pprof.Lookup("goroutine"); gProf == nil {
log.Fatal("could not write groutine profile: ")
} else {
gProf.WriteTo(f2, 0)
}
f2.Close()
}
2. 代码编译
go build $GOPATH/src/prof/prof.go
ls
cpu.prof goroutine.prof mem.prof prof prof.go
3. cpu profile
./prof
go tool pprof prof cpu.prof
File: prof
Type: cpu
Time: Jul 30, 2020 at 9:11am (GMT)
Duration: 2.46s, Total samples = 1.99s (80.85%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
我们进入了pprof的交互控制台
(pprof) top
Showing nodes accounting for 1960ms, 98.49% of 1990ms total
Showing top 10 nodes out of 39
flat flat% sum% cum cum%
610ms 30.65% 30.65% 900ms 45.23% math/rand.(*Rand).Int31n
450ms 22.61% 53.27% 450ms 22.61% runtime.memclrNoHeapPointers
300ms 15.08% 68.34% 1460ms 73.37% main.fillMatrix
210ms 10.55% 78.89% 1160ms 58.29% math/rand.(*Rand).Intn
140ms 7.04% 85.93% 140ms 7.04% math/rand.(*rngSource).Uint64
100ms 5.03% 90.95% 240ms 12.06% math/rand.(*rngSource).Int63
50ms 2.51% 93.47% 50ms 2.51% runtime.newstack
40ms 2.01% 95.48% 40ms 2.01% main.calculate
40ms 2.01% 97.49% 290ms 14.57% math/rand.(*Rand).Int31 (inline)
20ms 1.01% 98.49% 20ms 1.01% runtime.pthread_cond_timedwait_relative_np
输入top命令,我们可以看到每一个函数的cpu使用情况。
(pprof) list fillMatrix
Total: 1.99s
ROUTINE ======================== main.fillMatrix in /users/stevenlv/codes/go/src/go_learning/code/ch46/tools/file/prof.go
300ms 1.46s (flat, cum) 73.37% of Total
. . 15:
. . 16:func fillMatrix(m *[row][col]int) {
. . 17: s := rand.New(rand.NewSource(time.Now().UnixNano()))
. . 18:
. . 19: for i := 0; i < row; i++ {
140ms 140ms 20: for j := 0; j < col; j++ {
160ms 1.32s 21: m[i][j] = s.Intn(100000)
. . 22: }
. . 23: }
. . 24:}
. . 25:
. . 26:func calculate(m *[row][col]int) {
我们可以选择任意一个函数做cpu资源消耗分析,我这里以fillMatrix为例子。可以看到执行最久的地方就是在for循环中赋值的操作
(pprof) svg
Generating report in profile001.svg
在终端输入svg指令,在当前路径下我们可以看到生成了一个名叫profile001.svg的svg图
(pprof) exit
ls
cpu.prof goroutine.prof mem.prof prof prof.go profile001.svg
使用浏览器打开profile001.svg
open profile001.svg
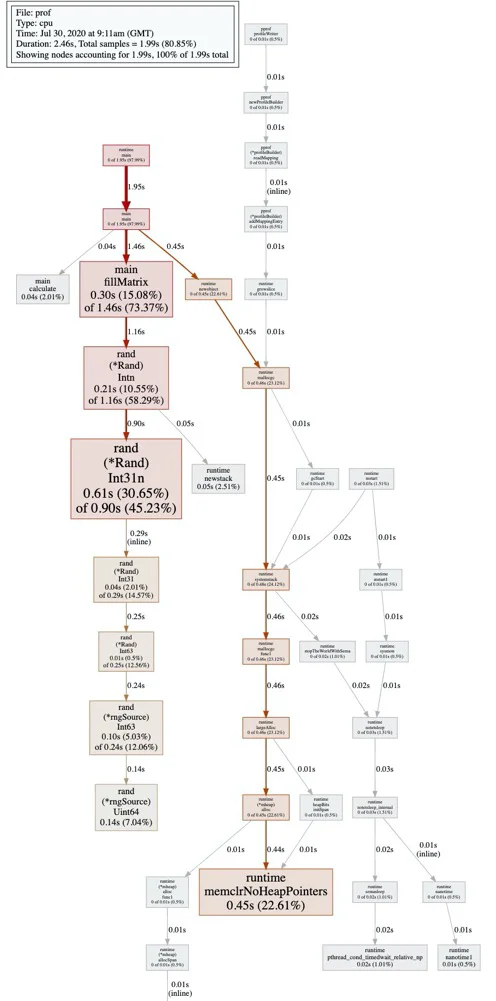
每一个函数的cpu消耗以及占用时间都在svg中表现出来。
go-torch cpu.prof
INFO[09:31:37] Run pprof command: go tool pprof -raw -seconds 30 cpu.prof
INFO[09:31:38] Writing svg to torch.svg
ls
cpu.prof goroutine.prof mem.prof prof prof.go profile001.svg torch.svg
生成火焰图之前需要用go-torch cpu.prof去生成火焰图
open torch.svg
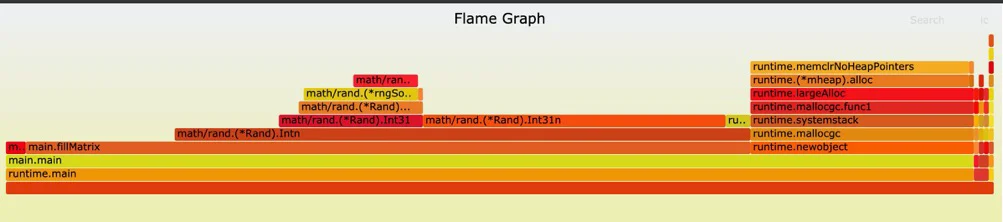
颜色越红表示cpu占用率越高,火焰图可以比较直观的看出性能指标。
4. memory profile
查看内存消耗与查看cpu消耗的步骤基本没有差别,所以这里就不重复的说一些和cpu profile一样的内容了
(pprof) top
Showing nodes accounting for 762.95MB, 100% of 762.95MB total
flat flat% sum% cum cum%
762.95MB 100% 100% 762.95MB 100% main.main
0 0% 100% 762.95MB 100% runtime.main
(pprof) list main.main
Total: 762.95MB
ROUTINE ======================== main.main in /users/stevenlv/codes/go/src/go_learning/code/ch46/tools/file/prof.go
762.95MB 762.95MB (flat, cum) 100% of Total
. . 44: log.Fatal("could not start CPU profile: ", err)
. . 45: }
. . 46: defer pprof.StopCPUProfile()
. . 47:
. . 48: // 主逻辑区,进行一些简单的代码运算
762.95MB 762.95MB 49: x := [row][col]int{}
. . 50: fillMatrix(&x)
. . 51: calculate(&x)
. . 52:
. . 53: f1, err := os.Create("mem.prof")
. . 54: if err != nil {
(pprof)
从结果中我们可以看出内存消耗主要是在初始化二维数组的时候
示例代码中有一段注释的代码
// runtime.GC()
解开这段注释,手动执行GC回收内存,重新编译
go build prof.go
./prof
go tool pprof prof mem.prof
(pprof) top
Showing nodes accounting for 1.16MB, 100% of 1.16MB total
flat flat% sum% cum cum%
1.16MB 100% 100% 1.16MB 100% runtime/pprof.StartCPUProfile
0 0% 100% 1.16MB 100% main.main
0 0% 100% 1.16MB 100% runtime.main
(pprof) list main.main
Total: 1.16MB
ROUTINE ======================== main.main in /users/stevenlv/codes/go/src/go_learning/code/ch46/tools/file/prof.go
0 1.16MB (flat, cum) 100% of Total
. . 39: if err != nil {
. . 40: log.Fatal("could not create CPU profile: ", err)
. . 41: }
. . 42:
. . 43: // 获取系统信息
. 1.16MB 44: if err := pprof.StartCPUProfile(f); err != nil { //监控cpu
. . 45: log.Fatal("could not start CPU profile: ", err)
. . 46: }
. . 47: defer pprof.StopCPUProfile()
. . 48:
. . 49: // 主逻辑区,进行一些简单的代码运算
(pprof)
手动gc之后效果很明显,内存被回收了,从回收前的762.95MB到了现在的1.16MB
5. goroutine profile
操作步骤和上面的一样,这里不再做详细的赘述,简单的显示一下结果
go tool pprof prof goroutine.prof
File: prof
Type: goroutine
Time: Jul 30, 2020 at 3:07pm (GMT)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 2, 100% of 2 total
flat flat% sum% cum cum%
1 50.00% 50.00% 1 50.00% runtime.gopark
1 50.00% 100% 1 50.00% runtime/pprof.writeRuntimeProfile
0 0% 100% 1 50.00% main.main
0 0% 100% 1 50.00% runtime.main
0 0% 100% 1 50.00% runtime/pprof.(*Profile).WriteTo
0 0% 100% 1 50.00% runtime/pprof.profileWriter
0 0% 100% 1 50.00% runtime/pprof.writeGoroutine
0 0% 100% 1 50.00% time.Sleep
5. 通过Http输出Profile
在局部的小代码片段的场景下,可以使用上述所说的方式来调试代码,但是在生成环境中,在一直运行着的代码中如何调试代码的性能,现在就要围绕这个问题给出解决方案。即通过Http方式输出Profile,这种方式特别适合在持续运行的应用中做性能调试。
1. 使用方法
① 在应用代码中导入import _"net/http/pprof",并启动http server
② http://
③ go tool pprof http://
④ go-torch http://
2. 代码示例
package main
import (
"fmt"
"log"
"net/http"
_ "net/http/pprof"
)
func GetFibonacciSerie(n int) []int {
ret := make([]int, 2, n)
ret[0] = 1
ret[1] = 1
for i := 2; i < n; i++ {
ret = append(ret, ret[i-2]+ret[i-1])
}
return ret
}
func index(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Welcome!"))
}
func createFBS(w http.ResponseWriter, r *http.Request) {
var fbs []int
for i := 0; i < 1000000; i++ {
fbs = GetFibonacciSerie(50)
}
w.Write([]byte(fmt.Sprintf("%v", fbs)))
}
func main() {
http.HandleFunc("/", index)
http.HandleFunc("/fb", createFBS)
log.Fatal(http.ListenAndServe(":8081", nil))
}
3. 使用实例
1. http://:/debug/pprof/

打开浏览器输入http://
2. go tool pprof http://:/debug/pprof/profile?
go tool pprof http://localhost:8081/debug/pprof/profile
Fetching profile over HTTP from http://localhost:8081/debug/pprof/profile
Saved profile in /Users/StevenLv/pprof/pprof.samples.cpu.002.pb.gz
Type: cpu
Time: Jul 31, 2020 at 2:08am (GMT)
Duration: 30.18s, Total samples = 20.43s (67.69%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 16120ms, 78.90% of 20430ms total
Dropped 135 nodes (cum <= 102.15ms)
Showing top 10 nodes out of 101
flat flat% sum% cum cum%
7170ms 35.10% 35.10% 7190ms 35.19% runtime.usleep
1980ms 9.69% 44.79% 1980ms 9.69% runtime.pthread_kill
1490ms 7.29% 52.08% 1490ms 7.29% runtime.pthread_cond_signal
1330ms 6.51% 58.59% 5350ms 26.19% main.GetFibonacciSerie
1100ms 5.38% 63.97% 1110ms 5.43% runtime.kevent
860ms 4.21% 68.18% 860ms 4.21% runtime.pthread_cond_wait
700ms 3.43% 71.61% 700ms 3.43% runtime.procyield
520ms 2.55% 74.16% 520ms 2.55% runtime.memclrNoHeapPointers
500ms 2.45% 76.60% 500ms 2.45% runtime.nanotime1
470ms 2.30% 78.90% 970ms 4.75% runtime.sweepone
(pprof) list main.GetFibonacciSerie
Total: 24.68s
ROUTINE ======================== main.GetFibonacciSerie in /users/stevenlv/codes/go/src/go_learning/code/ch46/tools/http/fb_server.go
1.58s 6.60s (flat, cum) 26.74% of Total
. . 5: "log"
. . 6: "net/http"
. . 7: _ "net/http/pprof"
. . 8:)
. . 9:
30ms 80ms 10:func GetFibonacciSerie(n int) []int {
10ms 4.82s 11: ret := make([]int, 2, n)
. 10ms 12: ret[0] = 1
40ms 40ms 13: ret[1] = 1
230ms 230ms 14: for i := 2; i < n; i++ {
1.21s 1.36s 15: ret = append(ret, ret[i-2]+ret[i-1])
. . 16: }
60ms 60ms 17: return ret
. . 18:}
. . 19:
. . 20:func index(w http.ResponseWriter, r *http.Request) {
. . 21: w.Write([]byte("Welcome!"))
. . 22:}
在http服务进程运行的情况下,再切一个终端使用go tool pprof http://
3. go-torch http://:/debug/pprof/profile
在终端输入
go-torch http://<host>:<port>/debug/pprof/profile
INFO[02:35:22] Run pprof command: go tool pprof -raw -seconds 30 http://localhost:8081/debug/pprof/profile
INFO[02:39:23] Writing svg to torch.svg
// 在采集期间需要去请求页面,否则无法生成火焰图🔥
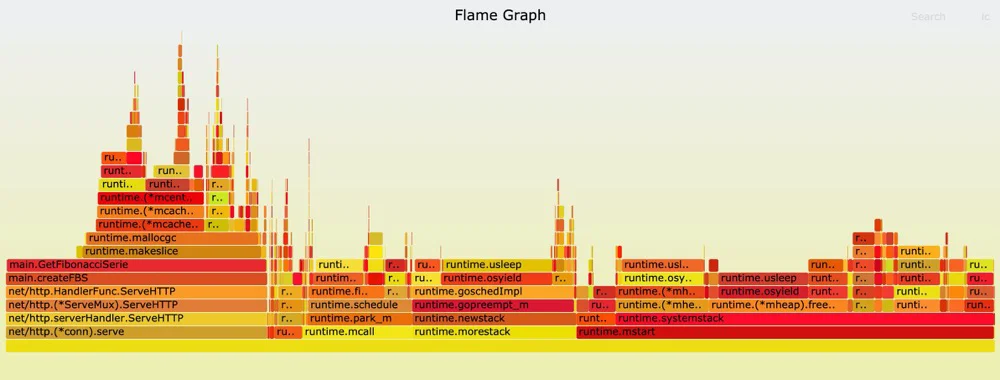
可以比较直观的看出来还是main.GetFibonacciSerie的cpu资源消耗比较大。