
golang关键字编译之后是什么样子,会展开成什么样。
range
range其实展开本质上和普通的for循环展开是一样的。只不过边界条件的判断稍微有点不一样。
for 初始化; 判断条件; 递进 {}
只不过编译器帮你来做了判断条件和递进(旁白:还是那句话,Golang那么高级,是因为编译器帮你干了好多事)。下面分别看几个类型遇到 range 是怎么回事,最主要的抓住边界条件是啥即可。
array slice
边界条件:是否超过数组长度(len)
编译器做了什么?拿slice变量或者array变量来说。
取出连续内存元素长度(数组是静态编译就知道的,slice是从len变量里取的)
每次循环判断是否超出长度
递进
解析下这段代码就知道了
3 func main() {4 var s []int = []int{11,12,13}56 for i, n:= range s {7 println(i, n)8 }
反汇编看下:
…比较0x000000000044ec4f <+159>: mov 0x20(%rsp),%rax。// 0x20($rsp) 存的就是 len字段0x000000000044ec54 <+164>: cmp %rax,0x28(%rsp) 递进的数字index: 0x28($rsp) 和len 比较跳转分支0x000000000044ec59 <+169>: jl 0x44ec5d <main.main+173>0x000000000044ec5b <+171>: jmp 0x44ecc8 <main.main+280>// 业务逻辑递进0x000000000044ecbe <+270>: inc %rax
map
边界条件:是否还有下一个值。mapiternext -> hiter != nil
map遇到range稍微有点不一样,是通过runtime.mapiternext来获取边界值,并且判断边界值是通过这个调用是否为0来判断的。
初始化迭代器0x0000000000450157 <+487>: callq 0x40bb70 <runtime.mapiterinit>0x000000000045015c <+492>: jmp 0x45015e <main.main+494>判断是否有元素可以继续迭代0x000000000045015e <+494>: cmpq $0x0,0xb8(%rsp)0x0000000000450167 <+503>: jne 0x45016e <main.main+510> 非0,还有元素,可以继续迭代0x0000000000450169 <+505>: jmpq 0x450207 <main.main+663>. 跳出循环0x000000000045016e <+510>: mov 0xc0(%rsp),%rax业务逻辑获取到下一个值0x00000000004501fd <+653>: callq 0x40be30 <runtime.mapiternext>
channel
边界调节:是否close
对于channel是调用runtime.chanrecv1展开的,边界值是channel关闭,所以这里如果没有close,就会永远阻塞。
// 迭代开始赋值chanrecv2的参数0x000000000044ec89 <+153>: mov 0x38(%rsp),%rax0x000000000044ec8e <+158>: mov %rax,(%rsp)0x000000000044ec92 <+162>: lea 0x28(%rsp),%rax0x000000000044ec97 <+167>: mov %rax,0x8(%rsp)=> 0x000000000044ec9c <+172>: callq 0x404d60 <runtime.chanrecv2> // channel未关闭就有可能是阻塞在这里// 判读是否满足边界条件0x000000000044eca6 <+182>: mov %al,0x1f(%rsp)0x000000000044ecaa <+186>: test %al,%al // 判断是否满足边界条件close0x000000000044ecac <+188>: jne 0x44ecb0 <main.main+192>0x000000000044ecae <+190>: jmp 0x44ece4 <main.main+244>// 业务逻辑// 直接调到153开始0x000000000044ece2 <+242>: jmp 0x44ec89 <main.main+153>
// chanrecv receives on channel c and writes the received data to ep.// ep may be nil, in which case received data is ignored.// If block == false and no elements are available, returns (false, false).// Otherwise, if c is closed, zeros *ep and returns (true, false).// Otherwise, fills in *ep with an element and returns (true, true).// A non-nil ep must point to the heap or the caller's stack.func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
select
select 展开成 selectgo . 有几个需要注意的:
select运行一次其实就是调用了一次 selectgo
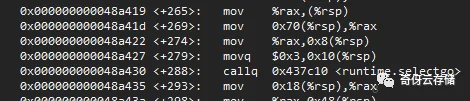
调用selectgo之前需要计算参数,表达式会计算出值
每个case传到selectgo函数里的一定是io操作;出来之后可以进行赋值操作
但是注意了,chan的io操作一定是在selectgo内部进行的
为什么能得到以上的几个结论:
因为每次selectgo调用是需要传参数的,传参数是需要构造变量的,这个时候必须计算出来。这个变量类型就是scase类型。
看selectgo的逻辑和汇编代码的生成,所有的channel io操作均在selectgo内部,涉及外部的赋值操作在外部
selectgo返回的是case的index,外部根据这个判断执行哪个case的逻辑
package mainfunc main() {c1 := make(chan int, 2)c2 := make(chan int, 2)c1<-1c2<-2select {case <-c1:println("1\n")case <-c2:println("2\n")}}
挑重点:
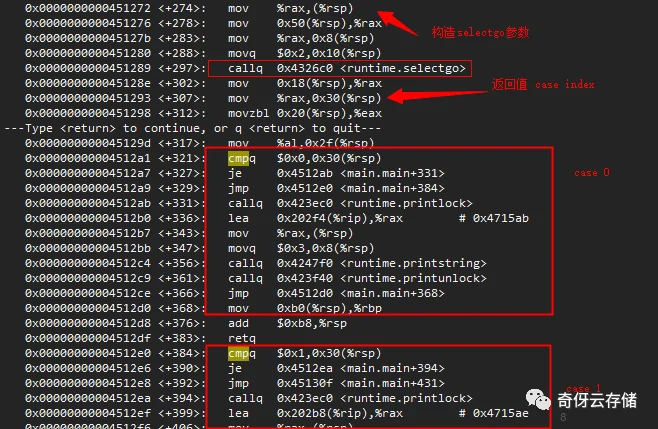
对应关系:
chan<-runtime.chansend1<-chanruntime.chanrecv1
函数
函数
函数的调用惯例
闭包到底做了什么
函数的调用惯例
所有的参数和返回值都是通过栈来传递。这个和c不同,c是前6个参数按照惯例用寄存器rdi,rsi,rdx,rcx,r8,r9. 参数溢出之后放在栈上,返回值存rax。go的传参这样设计,性能比c差点,但是复杂性大大降低。并且返回值还能统一起来,并且容易支持多参数。
闭包到底做了什么
闭包就是 带环境上下文的函数(funcval结构)。在编译的流程,有一步是专门分析变量捕捉的(分析出哪些变量会被捕捉,会和函数指针构成一个数据结构),然后才是函数编译。这样函数调用的时候,就能直接去上下文地址取变量的值了。
那么这里就要注意下,这里就有引用和值的区别,如果是和函数捆绑的是引用,那么取值的时候,就是通过反引用来取值的,修改的话也会导致这个原变量的值修改。如果是值,那么就是完全clone出来的一个变量对象。和原来的不相关。那么究竟是值,还是引用,这个要看我们业务代码怎么写,编译器才会怎么分析判断。
举个例子:
package mainfunc main () {var i int = 0for i = 0; i< 3; i++ {go func () {println(i) // 编译器捕捉分析,按照引用取值}()}}
汇编代码
000000000044ec60 <main.main.func1>:44ec60: 64 48 8b 0c 25 f8 ff mov %fs:0xfffffffffffffff8,%rcx44ec67: ff ff44ec69: 48 3b 61 10 cmp 0x10(%rcx),%rsp44ec6d: 76 42 jbe 44ecb1 <main.main.func1+0x51>44ec6f: 48 83 ec 18 sub $0x18,%rsp44ec73: 48 89 6c 24 10 mov %rbp,0x10(%rsp)44ec78: 48 8d 6c 24 10 lea 0x10(%rsp),%rbp44ec7d: 48 8b 44 24 20 mov 0x20(%rsp),%rax // 变量地址44ec82: 48 8b 00 mov (%rax),%rax // 反引用取值44ec85: 48 89 44 24 08 mov %rax,0x8(%rsp)44ec8a: e8 b1 3f fd ff callq 422c40 <runtime.printlock>44ec8f: 48 8b 44 24 08 mov 0x8(%rsp),%rax44ec94: 48 89 04 24 mov %rax,(%rsp)44ec98: e8 13 47 fd ff callq 4233b0 <runtime.printint>44ec9d: e8 1e 42 fd ff callq 422ec0 <runtime.printnl>44eca2: e8 19 40 fd ff callq 422cc0 <runtime.printunlock>44eca7: 48 8b 6c 24 10 mov 0x10(%rsp),%rbp44ecac: 48 83 c4 18 add $0x18,%rsp44ecb0: c3 retq44ecb1: e8 7a 82 ff ff callq 446f30 <runtime.morestack_noctxt>44ecb6: eb a8 jmp 44ec60 <main.main.func1>
另一个例子
package mainfunc main () {var i int = 0for i = 0; i< 3; i++ {v := igo func () {println(v). // 编译器捕捉分析,直接copy值,和func绑定。运行的时候,直接取值。}()}}
汇编
000000000044ec40 <main.main.func1>:44ec40: 64 48 8b 0c 25 f8 ff mov %fs:0xfffffffffffffff8,%rcx44ec47: ff ff44ec49: 48 3b 61 10 cmp 0x10(%rcx),%rsp44ec4d: 76 35 jbe 44ec84 <main.main.func1+0x44>44ec4f: 48 83 ec 10 sub $0x10,%rsp44ec53: 48 89 6c 24 08 mov %rbp,0x8(%rsp)44ec58: 48 8d 6c 24 08 lea 0x8(%rsp),%rbp44ec5d: e8 de 3f fd ff callq 422c40 <runtime.printlock>44ec62: 48 8b 44 24 18 mov 0x18(%rsp),%rax // 取值44ec67: 48 89 04 24 mov %rax,(%rsp)44ec6b: e8 40 47 fd ff callq 4233b0 <runtime.printint>44ec70: e8 4b 42 fd ff callq 422ec0 <runtime.printnl>44ec75: e8 46 40 fd ff callq 422cc0 <runtime.printunlock>44ec7a: 48 8b 6c 24 08 mov 0x8(%rsp),%rbp44ec7f: 48 83 c4 10 add $0x10,%rsp44ec83: c3 retq
第一个例子:用的是外面的变量,编译器假设你可能有读取,修改这个变量的值,其他人也是看的到的,那么自然是用引用的方式。
第二个例子:v是一个局部变量,每一轮循环都是新的变量值,是一个非常小的作用域。直接传值的话,没有问题,因为只有这个闭包关注这个值。

坚持思考,方向比努力更重要。关注我:奇伢云存储
