
介绍
要搞明白 Go 语言的内存管理,就必须先理解操作系统以及机器硬件是如何管理内存的。因为 Go 语言的内部机制是建立在这个基础之上的,它的设计,本质上就是尽可能的会发挥操作系统层面的优势,而避开导致低效情况。
操作系统内存管理
其实现在计算机内存管理的方式都是一步步演变来的,最开始是非常简单的,后来为了满足各种需求而增加了各种各样的机制,越来越复杂。这里我们只介绍和开发者息息相关的几个机制。
最原始的方式
1B
CPU 在执行指令的时候,就是通过内存地址,将物理内存上的数据载入到寄存器,然后执行机器指令。但随着发展,出现了多任务的需求,也就是希望多个任务能同时在系统上运行。这就出现了一些问题:
- 内存访问冲突:程序很容易出现 bug,就是 2 或更多的程序使用了同一块内存空间,导致数据读写错乱,程序崩溃。更有一些黑客利用这个缺陷来制作病毒。
- 内存不够用:因为每个程序都需要自己单独使用的一块内存,内存的大小就成了任务数量的瓶颈。
- 程序开发成本高:你的程序要使用多少内存,内存地址是多少,这些都不能搞错,对于人来说,开发正确的程序很费脑子。
100M1M100M100M虚拟内存
虚拟内存的出现,很好的为了解决上述的一些列问题。用户程序只能使用虚拟的内存地址来获取数据,系统会将这个虚拟地址翻译成实际的物理地址。
0x0000 ~ 0xffff1G1G1M如下图所示,每个进程所使用的虚拟地址空间都是一样的,但他们的虚拟地址会被映射到主存上的不同区域,甚至映射到磁盘上(当内存不够用时)。
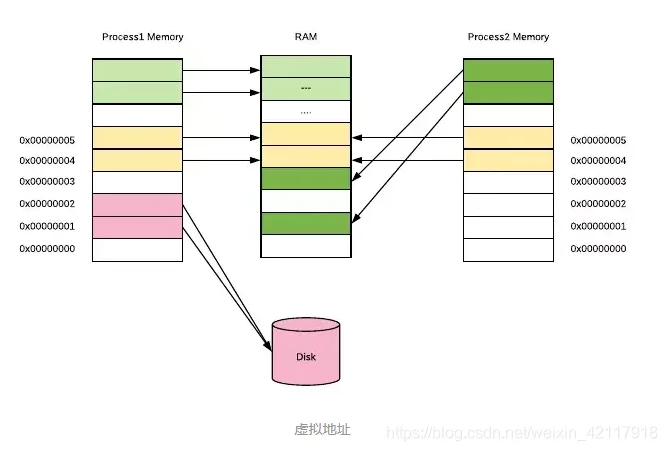
其实本质上很简单,就是操作系统将程序常用的数据放到内存里加速访问,不常用的数据放在磁盘上。这一切对用户程序来说完全是透明的,用户程序可以假装所有数据都在内存里,然后通过虚拟内存地址去访问数据。在这背后,操作系统会自动将数据在主存和磁盘之间进行交换。
虚拟地址翻译
4K4K虚拟地址 -> 物理地址页表被操作系统放在物理内存的指定位置,CPU 上有个 Memory Management Unit(MMU) 单元,CPU 把虚拟地址给 MMU,MMU 去物理内存中查询页表,得到实际的物理地址。当然 MMU 不会每次都去查的,它自己也有一份缓存叫Translation Lookaside Buffer (TLB),是为了加速地址翻译。
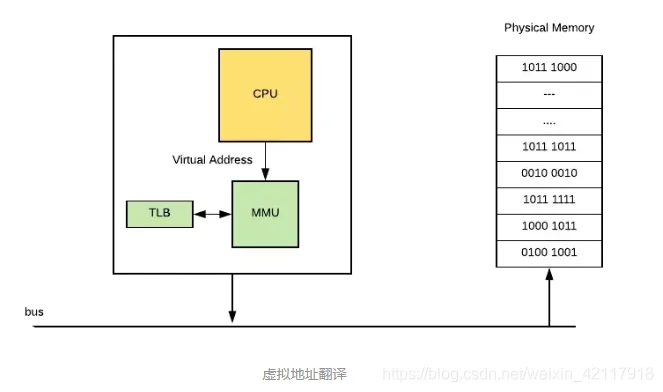
你慢慢会发现整个计算机体系里面,缓存是无处不在的,整个计算机体系就是建立在一级级的缓存之上的,无论软硬件。
让我们来看一下 CPU 内存访问的完整过程:
- CPU 使用虚拟地址访问数据,比如执行了 MOV 指令加载数据到寄存器,把地址传递给 MMU。
- MMU 生成 PTE 地址,并从主存(或自己的 Cache)中得到它。
- 如果 MMU 根据 PTE 得到真实的物理地址,正常读取数据。流程到此结束。
- 如果 PTE 信息表示没有关联的物理地址,MMU 则触发一个缺页异常。
- 操作系统捕获到这个异常,开始执行异常处理程序。在物理内存上创建一页内存,并更新页表。
- 缺页处理程序在物理内存中确定一个牺牲页,如果这个牺牲页上有数据,则把数据保存到磁盘上。
- 缺页处理程序更新 PTE。
- 缺页处理程序结束,再回去执行上一条指令(导致缺页异常的那个指令,也就是 MOV 指令)。这次肯定命中了。
内存命中率
你可能已经发现,上述的访问步骤中,从第 4 步开始都是些很繁琐的操作,频繁的执行对性能影响很大。毕竟访问磁盘是非常慢的,它会引发程序性能的急剧下降。如果内存访问到第 3 步成功结束了,我们就说页命中了;反之就是未命中,或者说缺页,表示它开始执行第 4 步了。
m / n * 100%iowait大多数情况下,只要物理内存够用,页命中率不会非常低,不会出现内存颠簸的情况。因为大多数程序都有一个特点,就是局部性。
局部性就是说被引用过一次的存储器位置,很可能在后续再被引用多次;而且在该位置附近的其他位置,也很可能会在后续一段时间内被引用。
前面说过计算机到处使用一级级的缓存来提升性能,归根结底就是利用了局部性的特征,如果没有这个特性,一级级的缓存不会有那么大的作用。所以一个局部性很好的程序运行速度会更快。
CPU Cache
随着技术发展,CPU 的运算速度越来越快,但内存访问的速度却一直没什么突破。最终导致了 CPU 访问主存就成了整个机器的性能瓶颈。CPU Cache 的出现就是为了解决这个问题,在 CPU 和 主存之间再加了 Cache,用来缓存一块内存中的数据,而且还不只一个,现代计算机一般都有 3 级 Cache,其中 L1 Cache 的访问速度和寄存器差不多。
CPU --> L1 Cache --> L2 Cache --> L3 Cache --> 主存 --> 磁盘现在存储器的整体层次结构大致如下图:
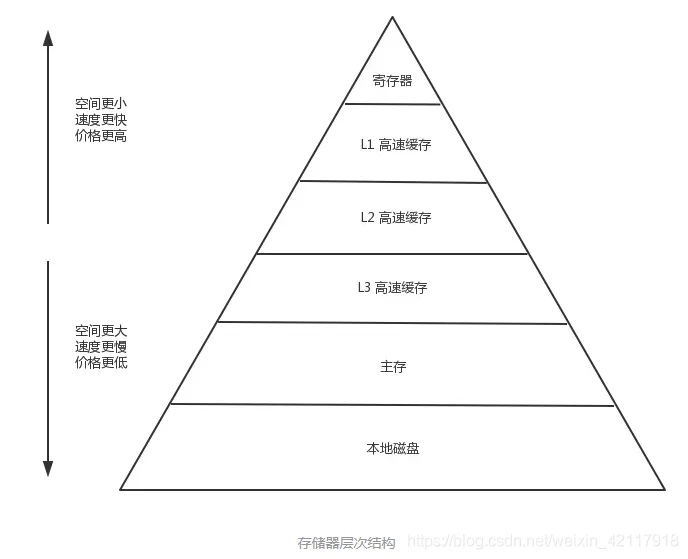
在这种架构下,缓存的命中率就更加重要了,因为系统会假定所有程序都是有局部性特征的。如果某一级出现了未命中,他就会将该级存储的数据更新成最近使用的数据。
主存与存储器之间以 page(通常是 4K) 为单位进行交换,cache 与 主存之间是以 cache line(通常 64 byte) 为单位交换的。
举个例子
让我们通过一个例子来验证下命中率的问题,下面的函数是循环一个数组为每个元素赋值。
func Loop(nums []int, step int) {
l := len(nums)
for i := 0; i < step; i++ {
for j := i; j < l; j += step {
nums[j] = 4
}
}
}
1,3,5,7,9,2,4,6,8,1010000step = 1step = 16goos: darwin
goarch: amd64
BenchmarkLoopStep1-4 300000 5241 ns/op
BenchmarkLoopStep16-4 100000 22670 ns/op
可以看出,2 种遍历方式会出现 3 倍的性能差距。这种问题最容易出现在多维数组的处理上,比如遍历一个二维数组很容易就写出局部性很差的代码。
程序的内存布局
0x0000 ~ 0xffff那最终编译出来的二进制文件,是如何被操作系统加载到内存中并执行的呢?
其实,操作系统已经将一整块内存划分好了区域,每个区域用来做不同的事情。如图:
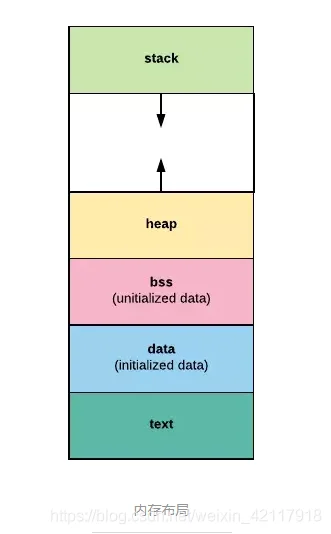
constmallocfree其实现在的操作系统,进程内部的内存区域没这么简单,要比这复杂多了,比如内核区域,共享库区域。因为我们不是要真的开发一套操作系统,细节可以忽略。这里只需要记住堆空间和栈空间即可。
- 栈空间是通过压栈出栈方式自动分配释放的,由系统管理,使用起来高效无感知。
- 堆空间是用以动态分配的,由程序自己管理分配和释放。Go 语言虽然可以帮我们自动管理分配和释放,但是代价也是很高的。
结论
局部性好的程序,可以提高缓存命中率,这对底层系统的内存管理是很友好的,可以提高程序的性能。CPU Cache 层面的低命中率导致的是程序运行缓慢,内存层面的低命中率会出现内存颠簸,出现这种现象时你的服务基本上已经瘫痪了。Go 语言的内存管理是参考 tcmalloc 实现的,它其实就是利用好了 OS 管理内存的这些特点,来最大化内存分配性能的。
参考
- 《深入理解计算机系统》