
三、Golang的堆与栈分析
Golang的堆与栈的管理跟C++管理不太一样,包括内存的申请与释放。以及变量存储在堆上还是栈上都不由用户确定。
3.1Golang的堆内存管理
内存的管理,无非是两个问题: 1.内存是如何申请的? 2.内存是如何释放的,什么时候释放? 带着这两个问题,我们来探索。
3.1.1 堆内存的申请
发生堆内存的申请是在什么时候呢?可能不太熟悉的Golang的同学觉得是New一个对象的时候,其实不然,Golang的编译器对代码进行了优化,你New一个对象所存储的位置不一定会存储在堆上,这是Golang的内存逃逸,稍后我们细说,当你创建的对象触发了newobject()函数的时候才是真正的申请了堆内存,注意这个newobject函数是Golang的内部函数。 记下来,我们先看下Golang是如何管理这些申请的内存的。 我们先来看几个结构体,这也是Golang管理内存的基本组件 内存管理的基本单元是span,这个span是一片连续的页组成的,整数倍的页也方便管理。每个span会被按照某种尺寸切成大小相同的小内存块,而我们代码中创建的堆对象就是存储这些小内存块的,这些小内存块我们称之为object。 我们先来看看span的结构体
type mspan struct {
next *mspan // 指向下一个span
prev *mspan // 指向上一个span
list *mSpanList // For debugging. TODO: Remove.
startAddr uintptr // span的开始地址
npages uintptr // 页数
manualFreeList gclinkptr // object的list
freeindex uintptr
nelems uintptr // object个数
allocCache uint64
allocBits *gcBits
gcmarkBits *gcBits
sweepgen uint32
divMul uint16 // for divide by elemsize - divMagic.mul
baseMask uint16 // if non-0, elemsize is a power of 2, & this will get object allocation base
allocCount uint16 // 已经分配的object个数
spanclass spanClass // size class and noscan (uint8)(下文有细说)
incache bool // being used by an mcache
state mSpanState // mspaninuse etc
needzero uint8 // needs to be zeroed before allocation
divShift uint8 // for divide by elemsize - divMagic.shift
divShift2 uint8 // for divide by elemsize - divMagic.shift2
elemsize uintptr // computed from sizeclass or from npages
unusedsince int64 // first time spotted by gc in mspanfree state
npreleased uintptr // number of pages released to the os
limit uintptr // end of data in span
speciallock mutex // guards specials list
specials *special // linked list of special records sorted by offset.
}注意:
1.每一页的大小为多少呢? 我在malloc.go与sizeclasses.go中分别找到如下内容
_PageShift = 13
_PageSize = 1 << _PageShift很明显能看出来每页大小为8KB
2.我们刚才说到,每个span会按照特定的大小进行等分,那么按照多大呢,如果我遇到一个跟这些块大小不等的对象怎么办? 我们看如上的mspan的结构体中有一个字段spanclass,该字段就是我们选定的切分的大小的,那么它是直接确定的吗?其实不是,它只是一个数组的下标而已,数组中存储的内容才是我们要切分的具体大小。我在sizeclasses中找到了这个数组
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}一共67个元素,比如某个span的sizeclasses为3就代表我们切分的大小为32字节。接着刚才那个问题,如果某个object的大小不等于这个数组中的任何一个值该怎么存储,很简单,用大的object存,比如32字节的大小的object可以存储17~32字节的对象。这样会造成一定的内存浪费,但是管理起来方便。
3.那么我们该怎么选个切分大小呢? 其实是按照申请内存的时候需求来的,我们稍后详细说这个问题。
4.我们如何判定一个span占用几页呢? 实际上占用的页数与我们刚才选定的切分的大小是一一对应的,在sizeclasses.go中还有一个长度为67的数组。
var class_to_allocnpages = [_NumSizeClasses]uint8{0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 3, 2, 3, 1, 3, 2, 3, 4, 5, 6, 1, 7, 6, 5, 4, 3, 5, 7, 2, 9, 7, 5, 8, 3, 10, 7, 4}比如说,当我们选定spanclass为3时,我们要切分的大小为32字节,那么我们分配span的页数就是1。
5.我们看到span在被切分的最大切分的大小是32768字节,即为32KB,那么如果我们的对象大小大于32KB怎么办? 对于大于32KB的对象,内存管理器视其为大对象,会特殊对待,我们稍后细说
ok,我们继续,span这是我们内存管理的基本单元,那么谁管理它呢?该我们内存管理器出场了,内存管理器的也有几个组件。 我们分以下几个步骤尽可能把内存管理器说明白: 首先我们会简单介绍下这几个组件的作用,然后我们把每个组件单独分析下,最后我们再把所有组件串起来说下他们是怎么配合使用,对应上我们的内存的申请与释放的。 我们先来看看这几个组件: cache:很明显类似缓存的东西,每个P(看看Golang的协程的调度吧)都会绑定一个cache,这样就可以无锁分配,速度很快。 central:它为cache提供了切分好的span资源,当cache无合适的span资源时会从这里拿,稍后我们细说为什么会有它。 heap: 管理闲置 span,需要时向操作系统申请新内存。 我们继续一一展开来说每个组件的结构体:
1.cache
type mcache struct {
next_sample int32 //堆采样点阈值
local_scan uintptr // bytes of scannable heap allocated (没太明白?)
//微小对象分配器,对于小于16字节的对象分配
//_TinySize = 16
tiny uintptr
tinyoffset uintptr
local_tinyallocs uintptr // 分配的微小对象数量
alloc [numSpanClasses]*mspan // 根据大小SpanClasses来找到对应的大小的span的指针
stackcache [_NumStackOrders]stackfreelist //栈相关,先不用关注
//GC相关
local_nlookup uintptr // number of pointer lookups
local_largefree uintptr // bytes freed for large objects (>maxsmallsize)
local_nlargefree uintptr // number of frees for large objects (>maxsmallsize)
local_nsmallfree [_NumSizeClasses]uintptr // number of frees for small objects (<=maxsmallsize)
}几个注意点的地方:
(1).我们通过结构体看到一个tiny与tinyoffset,这其实是分配器对特别小的对象进行分配的时候特别处理,稍后我们细说。
(2).我们重点关注的字段其实是alloc,它其实就是一个mspan的数组,而数组下表正好对应上我们之前说过的class_to_size数组。这也很好的解释了为什么给这个结构体其名字为cache了,假设刚开始alloc是空的,我们首次申请内存的时候,找不到对应的span,那么我们会去申请新的指定切分size的span,可能只需要用一个即可,那么下次再申请该size的对象的时候,直接从cache中获取即可。 OK,我们继续看central
type mcentral struct {
lock mutex
spanclass spanClass //size类型
nonempty mSpanList // 空闲的span的列表
empty mSpanList // 正在分配完的span或者在cache的span列表
nmalloc uint64 //从该central已经分配的总的对象个数(假设cache中的对象都分配完毕)
}这个结构体看起来就简单多了,注意:
1.spanclass字段代表什么意思呢?其实每个spanclass代表的是一种的切分方式的span,那么Golang为每种类型的span分配了一个central,这也是合理的,好管理,并且分散之后,减少了锁消耗。
2.由于多个工作线程都会访问该结构体,固然需要加锁。
3.看到这里我们也明白了,最初我们在介绍mcentral的时候,说它是为cache提供备用的span的,它这里有一个nonempty列表,该列表就是已经切好的span。我们来看下mSpanList这个结构体
type mSpanList struct {
first *mspan // first span in list, or nil if none
last *mspan // last span in list, or nil if none4.当然mcentral中的nonempty消耗光了该怎么办呢?实际上它会向heap获取闲置的span。 ok,正好我们要说heap了。话不多说,上代码
type mheap struct {
lock mutex
free [_MaxMHeapList]mSpanList // 空闲的span列表
freelarge mTreap // 空闲的超大span的列表(树堆存储)
busy [_MaxMHeapList]mSpanList // 正在使用的span列表
busylarge mSpanList // 正在使用的超大的列表
//GC相关
sweepgen uint32 // sweep generation, see comment in mspan
sweepdone uint32 // all spans are swept
sweepers uint32 // number of active sweepone calls
allspans []*mspan // 所有的span都在此数组中
spans []*mspan //虚拟页到span的映射
sweepSpans [2]gcSweepBuf
_ uint32 // align uint64 fields on 32-bit for atomics
pagesInUse uint64 // pages of spans in stats _MSpanInUse; R/W with mheap.lock
pagesSwept uint64 // pages swept this cycle; updated atomically
pagesSweptBasis uint64 // pagesSwept to use as the origin of the sweep ratio; updated atomically
sweepHeapLiveBasis uint64 // value of heap_live to use as the origin of sweep ratio; written with lock, read without
sweepPagesPerByte float64 // proportional sweep ratio; written with lock, read without
largealloc uint64 // bytes allocated for large objects
nlargealloc uint64 // number of large object allocations
largefree uint64 // bytes freed for large objects (>maxsmallsize)
nlargefree uint64 // number of frees for large objects (>maxsmallsize)
nsmallfree [_NumSizeClasses]uint64 // number of frees for small objects (<=maxsmallsize)
bitmap uintptr // Points to one byte past the end of the bitmap
bitmap_mapped uintptr
arena_start uintptr
arena_used uintptr // Set with setArenaUsed.
arena_alloc uintptr
arena_end uintptr
arena_reserved bool
_ uint32 // ensure 64-bit alignment
//我们的central在这里存储,按照numSpanClasses每一种size一个central
central [numSpanClasses]struct {
mcentral mcentral
pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte
}
spanalloc fixalloc // allocator for span*
cachealloc fixalloc // allocator for mcache*
treapalloc fixalloc // allocator for treapNodes* used by large objects
specialfinalizeralloc fixalloc // allocator for specialfinalizer*
specialprofilealloc fixalloc // allocator for specialprofile*
speciallock mutex // lock for special record allocators.
}看到heap的中全是关于span的一些字段相关,也对应到我们之前描述的heap是管理限制heap的说法。 ok,我们已经把内存管理的组件都介绍完了,下面我们开始把它们串起来。
func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)
}func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
.....
// Set mp.mallocing to keep from being preempted by GC.
mp := acquirem()
if mp.mallocing != 0 {
throw("malloc deadlock")
}
if mp.gsignal == getg() {
throw("malloc during signal")
}
//设置当前线程正在分配地址的标识
mp.mallocing = 1
//需要GC
shouldhelpgc := false
//对象的大小
dataSize := size
//获取当前线程的mcache,这个我们之前说过每个P(即工作线程)一个的。
c := gomcache()
var x unsafe.Pointer
//申请的对象的类型为空,或者对象内没有指针类型,noscan的意思也就是说不需要进行扫描
noscan := typ == nil || typ.kind&kindNoPointers != 0
//如果对象小于等于32KB,_MaxSmallSize = 32768
if size <= maxSmallSize {
//如果对象中没有指针并且对象大小小于16字节,属于微小对象,单独处理(如果有指针无法确定需要的确切的内存大小)
if noscan && size < maxTinySize {
//字节对齐,把微小对象放入一个object中,节省内存,只有object中的所有微小对象都不再使用的时候才释放object
off := c.tinyoffset
if size&7 == 0 {
off = round(off, 8)
} else if size&3 == 0 {
off = round(off, 4)
} else if size&1 == 0 {
off = round(off, 2)
}
if off+size <= maxTinySize && c.tiny != 0 {
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.local_tinyallocs++
mp.mallocing = 0
releasem(mp)
return x
}
//分配一个新的tiny span
span := c.alloc[tinySpanClass]
v := nextFreeFast(span)
if v == 0 {
v, _, shouldhelpgc = c.nextFree(tinySpanClass)
}
x = unsafe.Pointer(v)
//把16个字节分成2个8字节的数组(64位系统,最小8byte)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
if size < c.tinyoffset || c.tiny == 0 {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
} else {
//普通的小对象
var sizeclass uint8
//根据表来确定sizeclass
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]
} else {
sizeclass = size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]
}
size = uintptr(class_to_size[sizeclass])
spc := makeSpanClass(sizeclass, noscan)
//找到对应规定的span
span := c.alloc[spc]
//获取span中的一个空闲object
v := nextFreeFast(span)
//如果没有找到,则获取一个新的span
if v == 0 {
v, span, shouldhelpgc = c.nextFree(spc)
}
x = unsafe.Pointer(v)
if needzero && span.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(v), size)
}
}
} else {
//大对象内存
var s *mspan
//有大对象,则需要触发GC判断
shouldhelpgc = true
systemstack(func() {
s = largeAlloc(size, needzero, noscan)
})
s.freeindex = 1
s.allocCount = 1
x = unsafe.Pointer(s.base())
size = s.elemsize
}
//做bitmap的标记
var scanSize uintptr
if !noscan {
if typ == deferType {
dataSize = unsafe.Sizeof(_defer{})
}
heapBitsSetType(uintptr(x), size, dataSize, typ)
if dataSize > typ.size {
if typ.ptrdata != 0 {
scanSize = dataSize - typ.size + typ.ptrdata
}
} else {
scanSize = typ.ptrdata
}
c.local_scan += scanSize
}
publicationBarrier()
if gcphase != _GCoff {
gcmarknewobject(uintptr(x), size, scanSize)
}
if raceenabled {
racemalloc(x, size)
}
if msanenabled {
msanmalloc(x, size)
}
mp.mallocing = 0
releasem(mp)
if debug.allocfreetrace != 0 {
tracealloc(x, size, typ)
}
if rate := MemProfileRate; rate > 0 {
if size < uintptr(rate) && int32(size) < c.next_sample {
c.next_sample -= int32(size)
} else {
mp := acquirem()
profilealloc(mp, x, size)
releasem(mp)
}
}
if assistG != nil {
// Account for internal fragmentation in the assist
// debt now that we know it.
assistG.gcAssistBytes -= int64(size - dataSize)
}
//检查是否需要GC
if shouldhelpgc {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(gcBackgroundMode, t)
}
}
return x
}我们先来看下它的大致流程:
1.判断是否大于32KB:
a.如果小于32KB,并且是微小对象,则进行微小对象合并的操作。
b.如果是是小对象,获取一个可用的span,获取一个空闲的object即可。
2.如果是大于32KB的大对象,则直接进行大对象申请内存。
3.然后做bitmap标记,这是GC的时候使用的。
4.做垃圾回收触发检测。
ok,我们来探讨下细节问题:
1.首先是微小对象的字节对齐,是怎么个过程,我们手演算了一般

其实它就是根据你的微小对象的大小的是否为2、4、8的整数倍,然后进行对齐
2.我们发现无论是在分配微小对象还是普通小对象,都会有两个步骤:
a. nextFreeFast(span)获取span中的下一个free的object
b.如果返回为空,则调用c.nextFree(tinySpanClass)更新该cache中的span
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) {
s = c.alloc[spc]
shouldhelpgc = false
freeIndex := s.nextFreeIndex()
if freeIndex == s.nelems {
// The span is full.
if uintptr(s.allocCount) != s.nelems {
println("runtime: s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount != s.nelems && freeIndex == s.nelems")
}
//重点在这里
systemstack(func() {
c.refill(spc)
})
shouldhelpgc = true
s = c.alloc[spc]
freeIndex = s.nextFreeIndex()
}
if freeIndex >= s.nelems {
throw("freeIndex is not valid")
}
v = gclinkptr(freeIndex*s.elemsize + s.base())
s.allocCount++
if uintptr(s.allocCount) > s.nelems {
println("s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount > s.nelems")
}
return
}func (c *mcache) refill(spc spanClass) *mspan {
_g_ := getg()
_g_.m.locks++
// Return the current cached span to the central lists.
s := c.alloc[spc]
if uintptr(s.allocCount) != s.nelems {
throw("refill of span with free space remaining")
}
if s != &emptymspan {
s.incache = false
}
//从central获取一个对应规格的span
s = mheap_.central[spc].mcentral.cacheSpan()
if s == nil {
throw("out of memory")
}
if uintptr(s.allocCount) == s.nelems {
throw("span has no free space")
}
c.alloc[spc] = s
_g_.m.locks--
return s
}func (c *mcentral) cacheSpan() *mspan {
//垃圾清理
...
retry:
var s *mspan
//先去遍历空闲链表,当发现有可用资源的时候直接跳转到havespan进行使用
for s = c.nonempty.first; s != nil; s = s.next {
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {
c.nonempty.remove(s)
c.empty.insertBack(s)
unlock(&c.lock)
s.sweep(true)
goto havespan
}
if s.sweepgen == sg-1 {
continue
}
c.nonempty.remove(s)
c.empty.insertBack(s)
unlock(&c.lock)
goto havespan
}
//如果空闲链表中无可用的span,则遍历使用的链表,进行清理工作
for s = c.empty.first; s != nil; s = s.next {
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {
//需要清理,把待清理的span放到链表尾部
c.empty.remove(s)
c.empty.insertBack(s)
unlock(&c.lock)
s.sweep(true)
freeIndex := s.nextFreeIndex()
//清理后有可用的object,则直接跳转到havespan
if freeIndex != s.nelems {
s.freeindex = freeIndex
goto havespan
}
lock(&c.lock)
//清理后还没有可用object,则进行重试
goto retry
}
//正在清理,则跳过
if s.sweepgen == sg-1 {
continue
}
//如果已经都清理过,还是没有可用的span则直接退出,这里其实有一个疑问,稍后细说
break
}
if trace.enabled {
traceGCSweepDone()
traceDone = true
}
unlock(&c.lock)
//这里是重点,真正的从heap申请span
s = c.grow()
if s == nil {
return nil
}
lock(&c.lock)
//申请的span放到empty列表汇总
c.empty.insertBack(s)
unlock(&c.lock)
havespan:
....
s.incache = true
return s
}这里面我又一个疑问,在扫描empty列表的时候,如果第一个span是不需要sweep的,那么就会直接跳出循环,并没有把所有的empty扫描完。 $Rightarrow$ok,我们看到当完全没有可用的span的时候,central会调用grow从heap获取span
func (c *mcentral) grow() *mspan {
//查表获取其需要多少页
npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])
size := uintptr(class_to_size[c.spanclass.sizeclass()])
//计算object数量
n := (npages << _PageShift) / size
//从heap申请span
s := mheap_.alloc(npages, c.spanclass, false, true)
if s == nil {
return nil
}
p := s.base()
s.limit = p + size*n
//标记bitmap,这里很有用
heapBitsForSpan(s.base()).initSpan(s)
return s
}func (h *mheap) alloc(npage uintptr, spanclass spanClass, large bool, needzero bool) *mspan {
var s *mspan
systemstack(func() {
//alloc_m获取span
s = h.alloc_m(npage, spanclass, large)
})
if s != nil {
if needzero && s.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(s.base()), s.npages<<_PageShift)
}
s.needzero = 0
}
return s
}alloc_m的代码我们就不细看了。大概的原理就是找到合适内存块,首先根据需要的页数,从该页数对应的链表中查找,如果没有,则从大的页数的链表中拿出一个,如果一直没有,则申请新快。 当申请的快的大小超过我们需要的带下,则会进行切分,把剩余的返还给heap。并且会尝试合并相邻的span。 之前我们说过的heap中的span按照1-127页数的span,超过127的就是超大的span了。 还剩一个地方,超过32KB的对象的内存的申请
func largeAlloc(size uintptr, needzero bool, noscan bool) *mspan {
// print("largeAlloc size=", size, "n")
if size+_PageSize < size {
throw("out of memory")
}
npages := size >> _PageShift
if size&_PageMask != 0 {
npages++
}
deductSweepCredit(npages*_PageSize, npages)
//直接调用alloc分配,注意这里不会放入cache进行管理
s := mheap_.alloc(npages, makeSpanClass(0, noscan), true, needzero)
if s == nil {
throw("out of memory")
}
s.limit = s.base() + size
//更新bitmap
heapBitsForSpan(s.base()).initSpan(s)
return s
}其实内存的管理的申请过程到这里已经差不多了,但是我们还需要说以下几点:
1.我们大概总结下申请内存的整个过程
a.首先根据对象计算其需要的object规格
b.在mcache中寻找对应规格的span
c.然后根据微小对象、普通小对象进行各自的分配,就是从span的manualFreeList中获取可用的object
d.如果没有可用的span,则会从mcentral中获取span
e.如果mcentral的可用span为空,则直接从mheap中获取span然后进行切分
f.最后如果mheap也没有合适的span或者更大的span,则向操作系统申请
2.golang采用的内存管理架构是tcmalloc,感兴趣的同学可以查阅资料
3.在代码过程中,我们看到在申请span的时候会更新一个叫bitmap的东西,这是干什么用的呢?以下内容来网络查询整理 实际上,在go在程序启动时会分配一块虚拟内存地址是连续的内存, 结构如下:

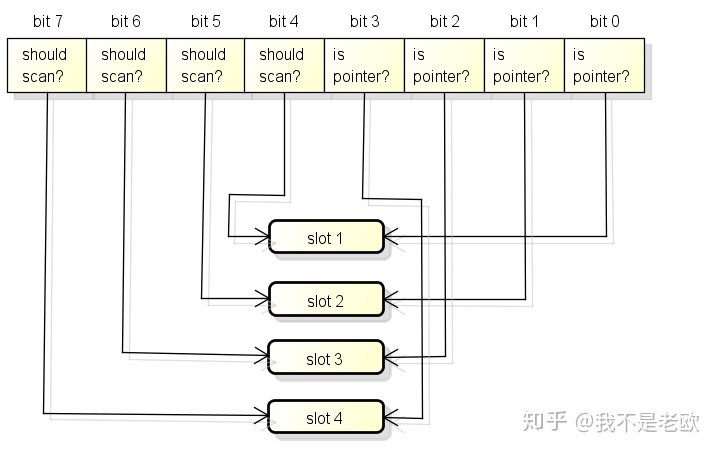
这一块内存分为了3个区域, 在X64上大小分别是512M, 16G和512G, 它们的作用如下: arena区域就是我们通常说的heap, go从heap分配的内存都在这个区域中. bitmap区域用于表示arena区域中哪些地址保存了对象, 并且对象中哪些地址包含了指针. bitmap区域中一个byte(8 bit)对应了arena区域中的四个指针大小的内存, 也就是2 bit对应一个指针大小的内存. 所以bitmap区域的大小是 512GB / 指针大小(8 byte) / 4 = 16GB. bitmap区域中的一个byte对应arena区域的四个指针大小的内存的结构如下, 每一个指针大小的内存都会有两个bit分别表示是否应该继续扫描和是否包含指针:
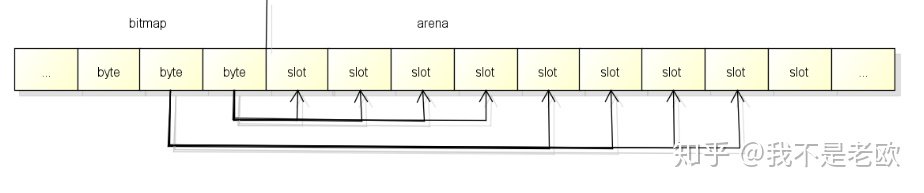
bitmap中的byte和arena的对应关系从末尾开始, 也就是随着内存分配会向两边扩展:
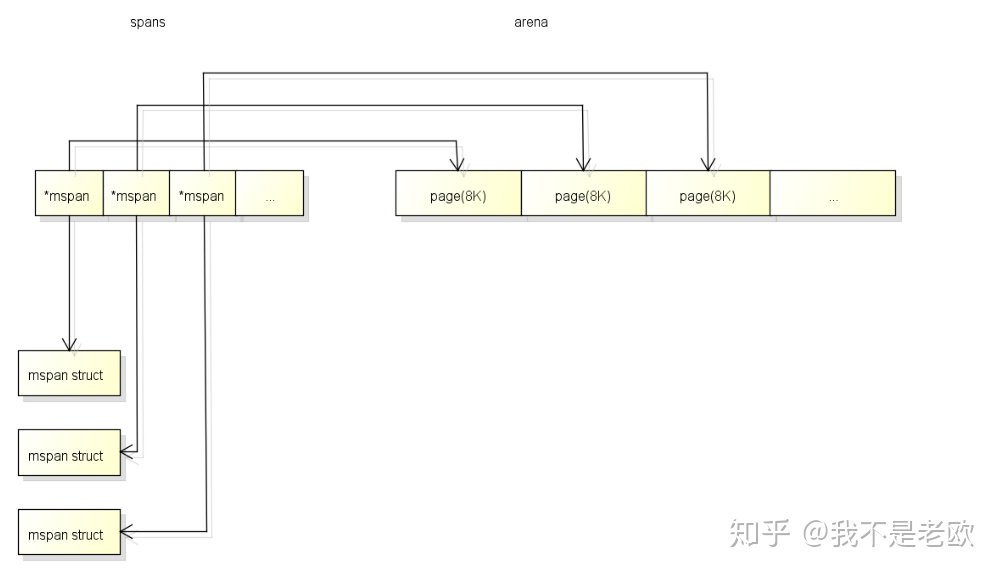
spans区域用于表示arena区中的某一页(Page)属于哪个span, 什么是span将在下面介绍. spans区域中一个指针(8 byte)对应了arena区域中的一页(在go中一页=8KB). 所以spans的大小是 512GB / 页大小(8KB) * 指针大小(8 byte) = 512MB. spans区域的一个指针对应arena区域的一页的结构如下, 和bitmap不一样的是对应关系会从开头开始:
那么问题来了, arena我们知道就是分配的内存,那么spans区域与bitmap区域的作用是什么呢? bitmap为每个对象提供4bit标记位,⽤以保存指针、GC标记等信息。创建span时,按页填充对应 spans 空间。在回收object时,只需将其地址按页对齐后就可找到所属 span。分配器还⽤此访问相邻span,做合并操作。 最后我们再来说下内存的回收与释放,因为内存的回收的触发其实就是垃圾回收,所以这里不再细说,稍后我们单独说GC的时候展开。 golang的内存回收的中心思想是:能复用的内存就尽量不要真正的释放。回收操作按照span为单位,然后去查看bitmap的标记,将object回收,然后上交给mcentral或者mheap。而我们系统监控线程sysmon会定时的检查heap的限制内存块,当限制的时间超过阈值,则会释放其关联的物理内存。
3.2Golang的协程栈管理
3.2.1分段栈与连续栈
在上文中我们曾经说过,Golang的协程栈是动态增长的,避免了栈溢出的问题。下面我们就来说明下它是如何增长的。
1.先来提一个好奇的问题,Golang的协程栈大小是无限增长吗,直到把内存消耗完? 我写了一个小程序来实验下:
package main
func main() {
main()
}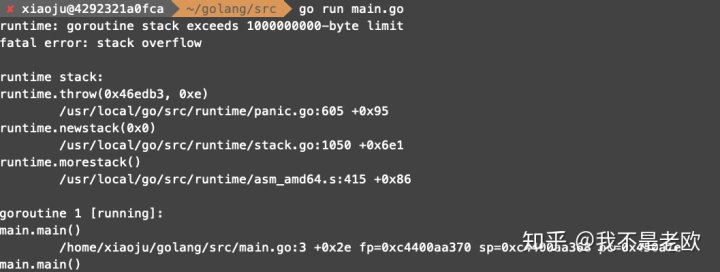
发现提示“1000000000-byte limit”,看来协程的栈大小还是有限制的,大概为953MB。
2.ok,我们继续,我们都知道协程的创建是很廉价的,每个协程创建的时候给的协程栈大小初始值是8KB。那么问题是协程是如何发现自己的栈资源不够用了呢? golang在每个函数入口处都会嵌入一段检测代码(注意,一个协程可能会执行多个函数的喔),当代码检测到栈资源不够用的时候,就会调用morestack函数进行扩容。
3.那么来到我们最关注的话题了,golang的协程栈是如何扩容的呢? 在golang1.5之前,golang的栈扩容策略一直都是分段栈的方式,在1.5的时候连续栈代替了分段站的方式,我们一一道来,这其实是两种不同的解决问题的思想,值得我们借鉴。 分段栈: 当调用morestack的时候,函数为协程分配一段新的内存栈,然后把协程栈的信息写入新栈的栈底的struct中,并且还包括了老栈的地址,这样就把两个栈联系到一起了,然后我们重启goroutine,从导致栈空间用光的那个函数开始执行。 以上的过程大概就是“分段栈”的思想。 我们来看看这里有几个问题:
(1).首先要明确一点,新旧栈的空间是不连续的,通过新栈的栈底的struct来跟老栈连接在一起。
(2).新栈会一直用吗?不会的,在新栈的底部,golang插入了一个函数lessstack,这个函数是什么时候会执行呢?当我们执行完那个导致我们老栈用光的函数后,会回调这个lessstack函数,这个函数的作用就是查找新栈底部的那个struct,然后找到老栈的地址,使得我们的协程返回到老栈,然后再释放新栈,继续执行我们的协程即可。
(3).在第二步中,看起来我们的分段栈的思想是,给协程栈一个可以伸缩的能力,需要的时候扩一下,用完即释放。这样看起来不浪费内存,很完美的样子,但是实际上在应用的过程中出现了“hot split”的问题。其实在我们分段栈中,新栈的释放会是一个高昂的代价,那么当你的一个循环体中,正好命中了栈分裂,那么就会出现以下的情况,每次进入循环体中,就会造成栈使用光,然后申请新栈,执行完循环体再释放栈,如此代价太大了。
(4).为了解决热分裂的问题,golang团队采用了另外一种思想,当要申请新栈的时候,直接把老栈释放掉,直接全部使用新栈即可,不用在释放掉新栈了。这个时候需要把老栈的所有内容都copy到新栈中去,所以我们叫它“栈拷贝”,又叫连续栈,因为我们的栈不再是两个不连续的栈连接的,而是一次申请一个新栈,直接把老栈释放掉。 连续栈: 刚才我们也大概说了连续栈是怎么做的,那么我们这里说几个问题:
1.我们看起来栈拷贝完全解决了分段栈的热分裂问题,那么新栈的大小是多少呢?新栈的大小是老栈的2倍,当你原先的栈不够用,我直接给你换个两倍大的,而且以后你使用的空间大小又变回原来的大小时,我也不再给你释放了,你还是用这个大的即可。这样带来的一个小问题就是可能会造成空间的浪费,但是带来的性能是可观的。
2.栈拷贝真的是那么容易吗?其实不然,我们知道Golang的栈上会存储变量,那么如果程序中有些指针指向了这些变量,会出现什么问题,我们把栈都换掉了,上面的那些变量的地址肯定也变了,这样那些指针岂不是无效了。
3.对于2遇到的问题,我们该如何解决呢?好在,只有栈上的指针才能指向栈上的变量,这一点很重要。那么我们需要知道栈上的哪些变量被指针指向了,在垃圾回收中,这些指针我们是可以获取到的,等到说垃圾回收的我们细说,ok,我们知道了这些指针,当我们要进行栈拷贝的时候,直接修改这些指针指向的位置即可。
4.很不幸,有些情况下我们是无法使用栈拷贝的,因为有些Go的运行时代码用的是C写的,所以我们无法获取到这些指针的位置,所以后来Go把很多runtime进行Golang化了。当函数是用C写的时候,只能继续使用分段栈的方式。
3.2.2栈内存的申请与扩容
我们从协程的创建的开始吧
func newproc(siz int32, fn *funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
pc := getcallerpc(unsafe.Pointer(&siz))
systemstack(func() {
newproc1(fn, (*uint8)(argp), siz, 0, pc)
})
}我们看到协程床架的时候实际上调的是newproc1函数,继续看下这个函数
func newproc1(fn *funcval, argp *uint8, narg int32, nret int32, callerpc uintptr) *g {
_g_ := getg()
if fn == nil {
_g_.m.throwing = -1 // do not dump full stacks
throw("go of nil func value")
}
_g_.m.locks++ // disable preemption because it can be holding p in a local var
siz := narg + nret
siz = (siz + 7) &^ 7
if siz >= _StackMin-4*sys.RegSize-sys.RegSize {
throw("newproc: function arguments too large for new goroutine")
}
_p_ := _g_.m.p.ptr()
//这里猜测应该是协程的复用
newg := gfget(_p_)
//如果没有可用的g,则常见一个
if newg == nil {
//创建一个最小栈大小的g,我们的_StackMin=2048
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
....
return newg
}ok,我们看到当创建协程的时候,会首先从当前的p中获取一个可复用的协程,如果获取失败,则创建一个默认栈大小为2048的协程。 我们继续看malg函数
func malg(stacksize int32) *g {
newg := new(g)
if stacksize >= 0 {
//调整栈大小为2的指数倍
stacksize = round2(_StackSystem + stacksize)
systemstack(func() {
//分配栈
newg.stack = stackalloc(uint32(stacksize))
})
newg.stackguard0 = newg.stack.lo + _StackGuard
newg.stackguard1 = ^uintptr(0)
}
return newg
}这里看到有对栈大小进行调整的操作,先看下_StackSystem,它是一个const类型,我追了下它的计算公式
_StackSystem = sys.GoosWindows*512*sys.PtrSize + sys.GoosPlan9*512 + sys.GoosDarwin*sys.GoarchArm*1024发现最后等于0,看代码注释是为了不同的系统做一些特殊处理的,比如信号处理,这些操作不需要单独的堆栈,ok我们不关注这个细节了。 我们看下round2函数
func round2(x int32) int32 {
s := uint(0)
for 1<<s < x {
s++
}
return 1 << s
}ok,其实就是把取一个不大于原始数的最大的2的指数被的数,我们的默认栈大小就是2048,2KB了。接下来就开始真正的申请栈空间了,调用stackalloc
func stackalloc(n uint32) stack {
.....
var v unsafe.Pointer
//从这里我们判断是否需要从缓存中获取栈空间
if n < _FixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > _FixedStack {
order++
n2 >>= 1
}
var x gclinkptr
c := thisg.m.mcache
//查看缓存中是否还有可用的内存
if stackNoCache != 0 || c == nil || thisg.m.preemptoff != "" || thisg.m.helpgc != 0 {
lock(&stackpoolmu)
x = stackpoolalloc(order)
unlock(&stackpoolmu)
} else {
//没有可用的,重新填充缓存
x = c.stackcache[order].list
if x.ptr() == nil {
stackcacherefill(c, order)
x = c.stackcache[order].list
}
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x)
} else {
//大内存,单独申请
var s *mspan
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
if s == nil {
s = mheap_.allocManual(npage, &memstats.stacks_inuse)
if s == nil {
throw("out of memory")
}
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}
....
return stack{uintptr(v), uintptr(v) + uintptr(n)}
}我们来分析下整个过程: 1.首先我们会判断需要申请的栈的大小
if n < _FixedStack<<_NumStackOrders && n < _StackCacheSize以linux为例,_FixedStack为2048,_NumStackOrders为4,则判断的大小伟32KB,_StackCacheSize为
_StackCacheSize = 32 * 1024也是32KB,ok,也就是说小于32KB的栈内存与大的内存的申请方式不同 2.接下来我们就看到,小于32KB的栈的申请有一个缓存的概念,这其实跟堆内存的申请很类似,我们看到它用的缓存是
c := thisg.m.mcache看到没有,用到的实际上跟我们堆的内存的缓存cache是一个。首先判断当前是否有缓存,如果没有缓存资源则直接从全局的缓存队列中分配,调用stackpoolalloc
func stackpoolalloc(order uint8) gclinkptr {
list := &stackpool[order]
s := list.first
if s == nil {
// no free stacks. Allocate another span worth.
s = mheap_.allocManual(_StackCacheSize>>_PageShift, &memstats.stacks_inuse)
if s == nil {
throw("out of memory")
}
if s.allocCount != 0 {
throw("bad allocCount")
}
if s.manualFreeList.ptr() != nil {
throw("bad manualFreeList")
}
s.elemsize = _FixedStack << order
for i := uintptr(0); i < _StackCacheSize; i += s.elemsize {
x := gclinkptr(s.base() + i)
x.ptr().next = s.manualFreeList
s.manualFreeList = x
}
list.insert(s)
}
x := s.manualFreeList
if x.ptr() == nil {
throw("span has no free stacks")
}
s.manualFreeList = x.ptr().next
s.allocCount++
if s.manualFreeList.ptr() == nil {
// all stacks in s are allocated.
list.remove(s)
}
return x
}我们来看看这函数的过程: 1.我们有一个全局的缓存池,stackpool,存储的就是不同规格的spanlist,首先我们获取对应规格的spanlist 2.如果list是空的,我们就调用allocManual申请新的span,等会我们再展开说 3.获取到list后,我们读取第一个span,然后分配manualFreeList的第一个单元给栈即可,如果manualFreeList用完了,则直接移除该span即可。 ok,我们来看下allocManual是如何申请先的span的:
func (h *mheap) allocManual(npage uintptr, stat *uint64) *mspan {
lock(&h.lock)
s := h.allocSpanLocked(npage, stat)
if s != nil {
s.state = _MSpanManual
s.manualFreeList = 0
s.allocCount = 0
s.spanclass = 0
s.nelems = 0
s.elemsize = 0
s.limit = s.base() + s.npages<<_PageShift
// Manually manged memory doesn't count toward heap_sys.
memstats.heap_sys -= uint64(s.npages << _PageShift)
}
// This unlock acts as a release barrier. See mheap.alloc_m.
unlock(&h.lock)
return s
}我们看到实际上是调用的allocSpanLocked直接从mheap获取了span。 ok,我们继续看stackpoolalloc函数,当获取完span后对其按照_StackCacheSize大小进行了切分,然后再分配栈资源。 ok,我们再回过头看下stackalloc,当cache中存在的时候,我们从stackcache中获取相应规格的stackfreelist,注意这里它没再用span的方式存储。我们来看下这stackfreelist的结构
type stackfreelist struct {
list gclinkptr // linked list of free stacks
size uintptr // total size of stacks in list
}ok,我们继续,把栈首地址指向列表的第一个元素,当为空的时候,就代表缓存列表为空,我们调用stackcacherefill进行填充,如果不为空的话,我们就更新链表的首地址到下一个元素,并更新size。 我们来看看stackcacherefill
func stackcacherefill(c *mcache, order uint8) {
if stackDebug >= 1 {
print("stackcacherefill order=", order, "n")
}
var list gclinkptr
var size uintptr
lock(&stackpoolmu)
for size < _StackCacheSize/2 {
x := stackpoolalloc(order)
x.ptr().next = list
list = x
size += _FixedStack << order
}
unlock(&stackpoolmu)
c.stackcache[order].list = list
c.stackcache[order].size = size
}我们看到实际上获取新的缓存,也是调用stackpoolalloc从全局的缓存中获取,并且这里有一个循环获取的方法,看起来是获取的大小要超过_StackCacheSize的一般,官方给出的解释是防止系统颠簸,难道是怕申请的少了,来回申请、释放?至于从全局缓存中申请调用的stackpoolalloc,这个我们之前已经看过,把它放入我们的list中。 注意: 这里有一个小的疑问,我们看到貌似栈内存的申请与堆内存的申请很相似,并且到最后都是用的mheap_这个全局的heap,那么我们知道垃圾回收的时候,只会回收堆上的内存,而我们的golang的虚拟地址实际上没有堆区与栈区的概念,他们的内存都是在arena区域,那么垃圾回收的时候怎么判断哪些span是堆哪些是栈的呢?后来追代码我发现堆申请span的时候调用的是cacheSpan函数,该函数最终调用的mcentral的grow函数,函数内部有一个更新bitmap的操作
heapBitsForSpan(s.base()).initSpan(s)但是我么的栈的申请实际上是直接调用的mheap的grow函数,它并不会标记bitmap,扫描arena应该是根据bitmap来的,另外一个是我们知道golang的垃圾回收是三色标记法,需要提前知道根对象,而且根对象是从协程栈上拿到的,那么我们怎么知道协程栈上哪些是指针呢? 首先,我们要理清楚以下几点: 1.我们看起来堆内存的申请与栈内存的申请很相似,但是实际上二者有些地方还是不同的,最终要的一点,我们的堆是为单个对象或者变量申请内存的,而我们的分配栈是为整个协程的栈申请的内存,并非为单个变量。 2.既然我们栈内存的申请并非为单个变量申请的,所以我们在这也发现不了哪些地方存储了指针。 ok,我们继续,似乎忘记了一个事情,我们之前说过栈拷贝,我们还没看源代码,现在瞅一瞅
// Called during function prolog when more stack is needed.
//
// The traceback routines see morestack on a g0 as being
// the top of a stack (for example, morestack calling newstack
// calling the scheduler calling newm calling gc), so we must
// record an argument size. For that purpose, it has no arguments.
TEXT runtime·morestack(SB),NOSPLIT,$0-0
// Cannot grow scheduler stack (m->g0).
get_tls(CX)
MOVQ g(CX), BX
MOVQ g_m(BX), BX
MOVQ m_g0(BX), SI
CMPQ g(CX), SI
JNE 3(PC)
CALL runtime·badmorestackg0(SB)
INT $3
// Cannot grow signal stack (m->gsignal).
MOVQ m_gsignal(BX), SI
CMPQ g(CX), SI
JNE 3(PC)
CALL runtime·badmorestackgsignal(SB)
INT $3
// Called from f.
// Set m->morebuf to f's caller.
MOVQ 8(SP), AX // f's caller's PC
MOVQ AX, (m_morebuf+gobuf_pc)(BX)
LEAQ 16(SP), AX // f's caller's SP
MOVQ AX, (m_morebuf+gobuf_sp)(BX)
get_tls(CX)
MOVQ g(CX), SI
MOVQ SI, (m_morebuf+gobuf_g)(BX)
// Set g->sched to context in f.
MOVQ 0(SP), AX // f's PC
MOVQ AX, (g_sched+gobuf_pc)(SI)
MOVQ SI, (g_sched+gobuf_g)(SI)
LEAQ 8(SP), AX // f's SP
MOVQ AX, (g_sched+gobuf_sp)(SI)
MOVQ BP, (g_sched+gobuf_bp)(SI)
// newstack will fill gobuf.ctxt.
// Call newstack on m->g0's stack.
MOVQ m_g0(BX), BX
MOVQ BX, g(CX)
MOVQ (g_sched+gobuf_sp)(BX), SP
PUSHQ DX // ctxt argument
CALL runtime·newstack(SB)
MOVQ $0, 0x1003 // crash if newstack returns
POPQ DX // keep balance check happy
RET根据官方的解释,我们了解到跟我们之前知道的基本一致,golang会在每个函数的入口插入一段代码,用于检测是否需要扩容栈大小,如果需要的,就会调用这个函数morestack,我们看上面代码大概知道是最终调用newstack函数进行扩容。注意,这里看注释,newstack函数是运行在g0协程的栈上的。
func newstack(ctxt unsafe.Pointer) {
.....
// 两倍原先大小的栈
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
//var maxstacksize uintptr = 1 << 20 最大的栈大小1G
if newsize > maxstacksize {
print("runtime: goroutine stack exceeds ", maxstacksize, "-byte limitn")
throw("stack overflow")
}
// 修改协程状态为栈拷贝
casgstatus(gp, _Grunning, _Gcopystack)
// 重点在这里
copystack(gp, newsize, true)
if stackDebug >= 1 {
print("stack grow donen")
}
//再把状态改回来
casgstatus(gp, _Gcopystack, _Grunning)
//发起调度,继续执行
gogo(&gp.sched)
}ok,看来实际调用的函数是copystack,我们继续看
func copystack(gp *g, newsize uintptr, sync bool) {
....
//计算栈已经使用的大小
old := gp.stack
if old.lo == 0 {
throw("nil stackbase")
}
used := old.hi - gp.sched.sp
// 分配新的栈
new := stackalloc(uint32(newsize))
if stackPoisonCopy != 0 {
fillstack(new, 0xfd)
}
....
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi
//这块先不关注
ncopy := used
if sync {
adjustsudogs(gp, &adjinfo)
} else {
adjinfo.sghi = findsghi(gp, old)
ncopy -= syncadjustsudogs(gp, used, &adjinfo)
}
//现在老栈的内容拷贝到新栈上
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
//调整ctxt、defers、panics、sghi指针的位置
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
if adjinfo.sghi != 0 {
adjinfo.sghi += adjinfo.delta
}
// Swap out old stack for new one
gp.stack = new
gp.stackguard0 = new.lo + _StackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// 调整新栈上的指针
gentraceback(^uintptr(0), ^uintptr(0), 0, gp, 0, nil, 0x7fffffff, adjustframe, noescape(unsafe.Pointer(&adjinfo)), 0)
// 释放老栈
if stackPoisonCopy != 0 {
fillstack(old, 0xfc)
}
stackfree(old)
}ok,解释下代码:
1.首先计算老栈与新栈的地址差,作为调整栈基本信息的指针使用
2.接着把老栈的内容直接拷贝到新栈上
3.调整新栈上的指针
4.释放掉老栈
注意:
1.我们主要看下函数调用gentraceback进行新栈上的指针的调整,我们就不把这个函数贴出来了,太复杂(感兴趣的同学可以看源码runtime.stack.go),我们看到它传进去的一个函数adjustframe,看函数名字,它应该就是我们要找的函数。
2.我们来看下adjustframe
func adjustframe(frame *stkframe, arg unsafe.Pointer) bool {
.....
f := frame.fn
....
pcdata := pcdatavalue(f, _PCDATA_StackMapIndex, targetpc, &adjinfo.cache)
....
// 调整
size := frame.varp - frame.sp
var minsize uintptr
switch sys.ArchFamily {
case sys.ARM64:
minsize = sys.SpAlign
default:
minsize = sys.MinFrameSize
}
if size > minsize {
var bv bitvector
//注意这里是重点,把数据转成stackmap类型
stackmap := (*stackmap)(funcdata(f, _FUNCDATA_LocalsPointerMaps))
....
// Locals bitmap information, scan just the pointers in locals.
....
bv = stackmapdata(stackmap, pcdata)
size = uintptr(bv.n) * sys.PtrSize
//进行调整
adjustpointers(unsafe.Pointer(frame.varp-size), &bv, adjinfo, f)
}
// 调整本地基本指针,说实话我也不知道是什么东西
if sys.ArchFamily == sys.AMD64 && frame.argp-frame.varp == 2*sys.RegSize {
....
if debugCheckBP {
bp := *(*uintptr)(unsafe.Pointer(frame.varp))
....
}
adjustpointer(adjinfo, unsafe.Pointer(frame.varp))
}
// 调整指针参数,猜测应该是栈内容的函数的指针
if frame.arglen > 0 {
var bv bitvector
if frame.argmap != nil {
bv = *frame.argmap
} else {
stackmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps))
bv = stackmapdata(stackmap, pcdata)
}
adjustpointers(unsafe.Pointer(frame.argp), &bv, adjinfo, funcInfo{})
}
return true
}ok,看到这里我们大概明白golang是如何找到栈內的指针了,根据一个stackmap类型,那么谁来更新它呢? 我们就不继续追代码了,追不动了说实话。猜测应该是创建变量的时候入栈操作,会相应的更新这个类似bigmap的东西吧。 到此,栈内存的分配基本结束了。
3.2.3栈内存释放
话不多说,直接看stackfree函数
func stackfree(stk stack) {
gp := getg()
v := unsafe.Pointer(stk.lo)
//计算栈大小
n := stk.hi - stk.lo
...
//如果是小的栈,则直接放回缓存,看起来跟分配的时候很相似
if n < _FixedStack<<_NumStackOrders && n < _StackCacheSize {
order := uint8(0)
n2 := n
for n2 > _FixedStack {
order++
n2 >>= 1
}
x := gclinkptr(v)
c := gp.m.mcache
//如果没有对应规格的缓存,则放回全局队列
if stackNoCache != 0 || c == nil || gp.m.preemptoff != "" || gp.m.helpgc != 0 {
lock(&stackpoolmu)
stackpoolfree(x, order)
unlock(&stackpoolmu)
} else {
//如果缓存满了,则调用stackcacherelease放回一部分到全局队列
if c.stackcache[order].size >= _StackCacheSize {
stackcacherelease(c, order)
}
//放到我们的本地缓存中
x.ptr().next = c.stackcache[order].list
c.stackcache[order].list = x
c.stackcache[order].size += n
}
} else {
//大的栈内存释放,还给mheap
s := mheap_.lookup(v)
if s.state != _MSpanManual {
println(hex(s.base()), v)
throw("bad span state")
}
if gcphase == _GCoff {
mheap_.freeManual(s, &memstats.stacks_inuse)
} else {
//如果正在GC,则直接放到全局的stackLarge中去
log2npage := stacklog2(s.npages)
lock(&stackLarge.lock)
stackLarge.free[log2npage].insert(s)
unlock(&stackLarge.lock)
}
}
}我们来分析下代码:
1.首先我们判断要回收的栈的大小,如果是小栈,则直接返回缓存中即可,如果是大的栈则首先是否正在进行GC,如果是怎放入到stackLarge中等待GC处理,否则直接返还给mheap
2.我们看下放回缓存的操作,如果无本地的该规格的缓存,则直接返回给全局缓存,调用stackpoolfree
func stackpoolfree(x gclinkptr, order uint8) {
s := mheap_.lookup(unsafe.Pointer(x))
if s.state != _MSpanManual {
throw("freeing stack not in a stack span")
}
if s.manualFreeList.ptr() == nil {
// s will now have a free stack
stackpool[order].insert(s)
}
x.ptr().next = s.manualFreeList
s.manualFreeList = x
s.allocCount--
if gcphase == _GCoff && s.allocCount == 0 {
stackpool[order].remove(s)
s.manualFreeList = 0
mheap_.freeManual(s, &memstats.stacks_inuse)
}
}我们看到,返还给全局的缓存后,会检测下该span是否还有已经分配的内容,如果没有并且GC结束,则返还mheap
3.如果本地有对应规格的缓存,则首先判断本地的缓存是否满了(大于_StackCacheSize),如果满了,则释放一些。
func stackcacherelease(c *mcache, order uint8) {
if stackDebug >= 1 {
print("stackcacherelease order=", order, "n")
}
x := c.stackcache[order].list
size := c.stackcache[order].size
lock(&stackpoolmu)
for size > _StackCacheSize/2 {
y := x.ptr().next
stackpoolfree(x, order)
x = y
size -= _FixedStack << order
}
unlock(&stackpoolmu)
c.stackcache[order].list = x
c.stackcache[order].size = size
}我们看到释放的方式是,首先通过调用stackpoolfree释放一半给mheap,然后再还给全局的缓存
4.ok,如果本地还没满,则直接放入本地队列即可
以上的栈释放是由谁触发的呢?实际上是由morestack触发的,我们可以回去看下在morestack的时候,会把老栈释放掉,调用的就是stackfree。那么其实还有一种情况也会触发栈的释放。
func markroot(gcw *gcWork, i uint32) {
....
switch {
case baseFlushCache <= i && i < baseData:
//这里会对该p所对应的栈缓存清掉
flushmcache(int(i - baseFlushCache))
....
case i == fixedRootFinalizers:
if work.markrootDone {
break
}
......
case i == fixedRootFreeGStacks:
if !work.markrootDone {
//此处调用了栈收缩
systemstack(markrootFreeGStacks)
}
}
}我们来看下flushmcachehi会释放掉当前P上的缓存,我们看下这个函数
func flushmcache(i int) {
p := allp[i]
if p == nil {
return
}
c := p.mcache
if c == nil {
return
}
c.releaseAll()
stackcache_clear(c)
}看到没有,释放的就是那个mcache,释放栈的是stackcache_clear(c),我们来看下
func stackcache_clear(c *mcache) {
if stackDebug >= 1 {
print("stackcache clearn")
}
lock(&stackpoolmu)
for order := uint8(0); order < _NumStackOrders; order++ {
x := c.stackcache[order].list
for x.ptr() != nil {
y := x.ptr().next
stackpoolfree(x, order)
x = y
}
c.stackcache[order].list = 0
c.stackcache[order].size = 0
}
unlock(&stackpoolmu)
}ok,很明了啦,调用的就是stackpoolfree释放的。 继续看markroot,里面还有一个操作systemstack(markrootFreeGStacks),这个函数实际上调用的是shrinkstack,我们直接追过去
func shrinkstack(gp *g) {
gstatus := readgstatus(gp)
if gstatus&^_Gscan == _Gdead {
if gp.stack.lo != 0 {
// Free whole stack - it will get reallocated
// if G is used again.
stackfree(gp.stack)
gp.stack.lo = 0
gp.stack.hi = 0
}
return
}
....
oldsize := gp.stack.hi - gp.stack.lo
//缩小为原来的1/2
newsize := oldsize / 2
if newsize < _FixedStack {
return
}
avail := gp.stack.hi - gp.stack.lo
//判断使用是否超过了1/4
if used := gp.stack.hi - gp.sched.sp + _StackLimit; used >= avail/4 {
return
}
if gp.syscallsp != 0 {
return
}
if sys.GoosWindows != 0 && gp.m != nil && gp.m.libcallsp != 0 {
return
}
if stackDebug > 0 {
print("shrinking stack ", oldsize, "->", newsize, "n")
}
//栈拷贝
copystack(gp, newsize, false)
}ok,看下这里的逻辑,如果当前栈的使用量超过1/4则不进行收缩,否则缩为原来的1/2释放空间,并进行栈拷贝。 到这里栈的管理结束了。